记录一次失败的深度学习经历之Kaggle:猫狗大战
内容导航
- 实验环境
- 基本模块
-
- 导入模块
-
- 函数:load_data
- 类型:CatsDogsDataset
- 类型:BasicModule
- 深度网络
-
- 类型:ResNet34
- 类型:AlexNet
- 训练流程
-
- 函数:train
- 结果比较
- 经验总结
实验环境
-
解释器版本: Python 3.8.5
-
操作系统: ubuntu 18.04
-
硬件型号: Xeon E7 v3,RTX 3060
-
学习框架: PyTorch 1.8.1,scikit-learn 0.24.1,torchvision 0.9.1,cuda11.2
-
数据来源: https://www.kaggle.com/c/dogs-vs-cats/data
基本模块
导入模块
import os
import sys
import random
import numpy as np
import pandas as pd
import torch
from torch.nn import functional as F
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader, ConcatDataset
from torchvision import transforms, datasets
import matplotlib.pyplot as plt
import copy
import multiprocessing
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
from pathlib import Path
from PIL import Image
函数:load_data
-
函数输入:
参数 类型 说明 path str 数据集根目录 mode str 模式(取值为"train"或者"validate"或者"test") -
函数输出: 如果模式是"test",那么只返回文件名列表,如果模式不是"test",那么返回文件名列表以及对应的标签
-
代码展示:
#定义读取数据的方式,这里只是夹在train文件夹下打好标签的数据
def load_data(path, mode):
data_list = []
label_list = []
for dirs in os.listdir(path):
if dirs == "train" and (mode == "train" or mode == "validate"):
for file in os.listdir(path + dirs):
#根据文件名,给训练集合打标签,狗是1,猫是0
if "cat" in (file.split('/')[-1]).split('.'):
label_list.append(0)
else:
label_list.append(1)
data_list.append(path + dirs + '/' + file)
return (data_list, label_list)
elif dirs == "test" and mode == "test":
#print("load test dataset")
for file in os.listdir(path + dirs):
data_list.append(path + dirs + '/' + file)
return data_list
- 评价: 这个函数的设计思路是不对数据集进行进一步的操作,比如新建文件夹,把验证集和训练集合分开,这样做的好处是本程序不用对文件系统里的图片进行IO操作,减少了程序运行的时间,此外将本程序移植到其他计算机上时,也可以直接计算。坏处是之后验证模型准确性的时候还需要创建一个数据集对象,显得有点低效和冗余,所以这里做了一个取舍,最后选择这样写了。
类型:CatsDogsDataset
-
父类: torch.utils.data.Dataset
-
初始化参数:
参数 类型 说明 path str 文件路径,取值为字符串 mode str 模式,取值为"train"或者"validate"或者"test" -
代码展示:
class CatsDogsDataset(torch.utils.data.Dataset):
def __init__(self, path, mode):
self.mode = mode
self.path = path
self.IMAGE_H = 200
self.IMAGE_W = 200
self.img_list = []
self.label_list = []
self.transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((self.IMAGE_H,self.IMAGE_W))])
self.resize = transforms.Compose([transforms.ToTensor(),
transforms.Resize((self.IMAGE_H,self.IMAGE_W))])
if self.mode == 'train':
self.img_list, self.label_list = load_data(self.path, self.mode)
self.img_list = self.img_list[0:int(len(self.img_list)*0.9)]
self.label_list = self.label_list[0:int(len(self.label_list)*0.9)]
elif self.mode == 'validate':
self.img_list, self.label_list = load_data(self.path, self.mode)
self.img_list = self.img_list[int(len(self.img_list)*0.9): -1]
self.label_list = self.label_list[int(len(self.label_list)*0.9): -1]
elif self.mode == 'test':
self.img_list = load_data(self.path, self.mode)
else:
return print('MODE ERROR!')
def __getitem__(self, item):
if self.mode == 'train':
img = Image.open(self.img_list[item])
img = self.transform(img)
label = self.label_list[item]
return img, torch.LongTensor([label])
elif self.mode == 'test':
img = Image.open(self.img_list[item])
img = np.array(img)[:, :, :3]
return self.resize(img)
elif self.mode == 'validate':
img = Image.open(self.img_list[item])
img = self.resize(img)
print(type(img))
label = self.label_list[item]
return self.resize(img), torch.LongTensor([label])
else:
print("MODE ERROR!")
def __len__(self):
if self.mode == "train":
return len(self.label_list)
elif self.mode == "validate":
return len(self.label_list)
-
成员方法:
方法 参数 说明 _getitem_(index) index:int 函数被之后的子类调用,根据下表index,以张量的形式,返回预处理过的图片 _len_() 无 函数为子类对象返回数据集样本数量,保证可以正确读取数据,不会下标越界 -
评价: 构建这个数据集类目的有两个,第一个是预处理图片,因为打开数据集发现每张图片的尺寸都是不一样的,所以需要对原先的数据进行预处理,至少需要把图片调整成同样的大小,使得输入向量的维度是统一的;第二是为之后当成参数传入用于加载一个batch数量数据的函数torch.utils.data.Dataloader,提供接口,还要保证不会越界。以上两点都体现在重载的两个函数上。
类型:BasicModule
- 父类: torch.nn.Module
class BasicModule(nn.Module):
def __init__(self):
super(BasicModule,self).__init__()
self.model_name=str(type(self))
def load(self, path):
self.load_state_dict(t.load(path))
def save(self, name=None):
if name is None:
prefix = 'checkpoints/' + self.model_name + '_'
name = time.strftime(prefix + '%m%d_%H:%M:%S.pth')
t.save(self.state_dict(), name)
return name
- 评价: 作为之后两个深度神经网络的基类,定义了加载已经训练好的神经网络参数的办法,同样也定义了导出神经网络参数的办法,方便之后进行模型之间的比较。
深度网络
类型:ResNet34
- 父类: BasicModule
- 初始化参数: 分类种类数量,默认为2
- 代码展示:
class ResNet34(BasicModule):
def __init__(self, num_classes=2):
super(ResNet34, self).__init__()
self.model_name = 'resnet34'
self.pre = nn.Sequential(
nn.Conv2d(3, 64, 7, 2, 3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 1))
self.layer1 = self._make_layer( 64, 128, 3)
self.layer2 = self._make_layer( 128, 256, 4, stride=2)
self.layer3 = self._make_layer( 256, 512, 6, stride=2)
self.layer4 = self._make_layer( 512, 512, 3, stride=2)
self.fc = nn.Linear(512, num_classes)
def initialize_weights():
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.kaiming_uniform_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_uniform_(m.weight.data, mode='fan_in', nonlinearity='relu')
# m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
initialize_weights()
def _make_layer(self, inchannel, outchannel, block_num, stride=1):
shortcut = nn.Sequential(
nn.Conv2d(inchannel,outchannel,1,stride, bias=False),
nn.BatchNorm2d(outchannel))
layers = []
layers.append(ResidualBlock(inchannel, outchannel, stride, shortcut))
for i in range(1, block_num):
layers.append(ResidualBlock(outchannel, outchannel))
return nn.Sequential(*layers)
def forward(self, x):
x = x.float()
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.avg_pool2d(x, 7)
x = x.view(x.size(0), -1)
x = self.fc(x)
return F.softmax(x,dim=1)
- 网络结构:
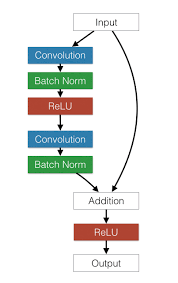
类型:AlexNet
- 父类: BasicModule
- 初始化参数: 分类种类数量,默认为2
- 代码展示:
class AlexNet(BasicModule):
def __init__(self, num_classes=2):
super(AlexNet, self).__init__()
self.model_name = 'alexnet'
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 5 * 5, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def initialize_weights():
for m in self.modules():
if isinstance(m, nn.Conv2d):
torch.nn.init.xavier_normal_(m.weight.data)
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
torch.nn.init.kaiming_uniform_(m.weight.data, mode='fan_in', nonlinearity='relu')
# m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
initialize_weights()
def forward(self, x):
x = x.float()
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
- 网络结构:

训练流程
函数:train
-
函数输入:
参数 类型 说明 Model torch.nn.Module的派生类 存储神经网络结构和参数 dataset torch.utils.data.Dataset的派生类 存储训练数据的位置 val_dataset torch.utils.data.Dataset的派生类 存储验证数据的位置 optimizer torch.optim中的类 存储反向传播算法及参数 criterion torch.nn中的类 存储损失函数 batch int 存储批处理的规模 epochs int 存储进行批处理的次数 -
函数输出: 含有每个eporch结束之后模型在验证集上的正确率的列表
-
代码展示:
def train(model, dataset, val_dataset, optimizer, criterion, batch_size, epochs): # 调用父类的cuda()方法,用GPU加速运算 model = model.cuda() # 记录训练图片数量 eporch_acc = [] num_threads = multiprocessing.cpu_count() for epoch in range(epochs): cnt = 0 img_label = list(zip(dataset.img_list,dataset.label_list)) random.shuffle(img_label) dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True) print("<<<<<<< enter epoch {0} >>>>>>>>>".format(epoch+1)) for img, label in dataloader: # 将数据放置在PyTorch的Variable节点中,并送入GPU中作为网络计算起点 img, label = Variable(img).cuda(), Variable(label).cuda() out = model(img) predict = torch.max(out,1)[1].tolist() fact = label.tolist() loss = criterion(out.squeeze(), label.squeeze()) # 误差反向传播 loss.backward() # 优化采用设定的优化方法对网络中的各个参数进行调整 optimizer.step() optimizer.zero_grad() cnt += 1 # 打印一个batch size的训练结果 if cnt%20 == 0: print('Sample {0}, train_loss {1}'.format(cnt*batch_size, loss/batch_size)) del img del label acc_out = validate(model, val_dataset) eporch_acc.append(acc_out) print("<<<< enter epoch {0} is over with final result {1} >>>>".format(epoch+1, acc_out)) torch.save(model.state_dict(), './model.weight') return eporch_acc -
思路: 总体流程是先将Dataset里储存的数据位置用dataloader读进来,形成一个可以迭代的数据类型,然后进行向前传播得到预测结果,将结果与正确结果进行比较,然后误差进行向后传播,每训练3200张图片输出一次损失函数值,查看一下运行情况,如此循环若干次,最后把训练得到的模型保存到本地,可供下次调用。
结果比较
下面比较AlexNet和ResNet两个深度神经网络在猫狗二分类问题上的表现,由于算力有限,所以这里的比较都是基于eporch=10的。优化器选择Adam,验证集训练集为一九开,batch_size=64。第一个版本的训练器运行结果是下面这样的,纵坐标是准确率,横坐标是eporch的值
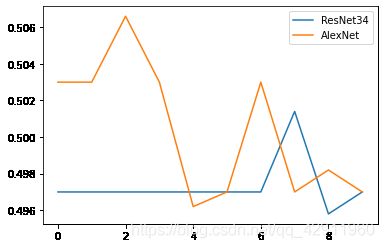
AlexNet比ResNet略好一些,但是总体来说两个模型的结果都非常不理想,在之后几个eporch内性能没有任何提升,我仔细回顾了一下代码,觉得问题可能出在没有将存储数据位置的列表打乱造成的,因为这样有可能造成将同样的数据以同样的顺序反复读取然后训练的情况,于是加入shuffle函数,在进行一次测试,发现结果如下
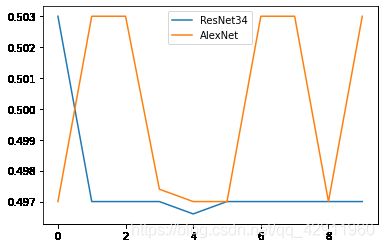
结果依然不是很理想,还需要进一步调整。然后我又想到数据集中存在很多不够典型的样本点,所以为了进一步增强模型,我又改进了预处理的过程,原先仅仅将图片缩放成200$\times$200大小,现在在训练集上加入如随机高斯模糊、水平翻转、颜色偏移等操作,验证集为了仿真测试集,还是只保留调整大小这一个操作,然后再尝试一次
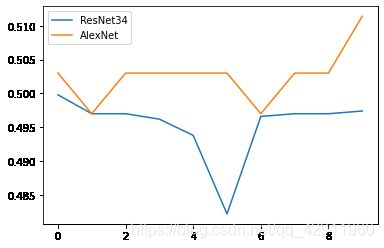
在程序运行的过程中,我发现尽管ResNet的损失函数是在缓慢下降的,但是验证集上的精确度却没有明显改变,说明可能存在过拟合的现象;AlexNet的情况略好一些,但是也在50%上下,由于算力和时间有限,不能测试更多的eporch了。我还尝试了在全链接层上进行初始化操作,选择的初始化函数是Kaiming_uniform_,结果如下
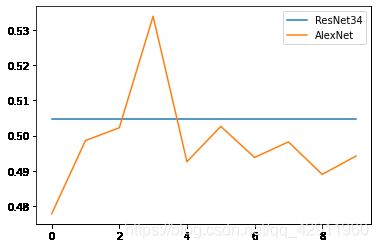
不清楚什么原因,ResNet在验证集上的准确率一直不变,而AlexNet的正确率甚至低于50%。最后我将一起运用预处理和初始化两个操作,结果如下
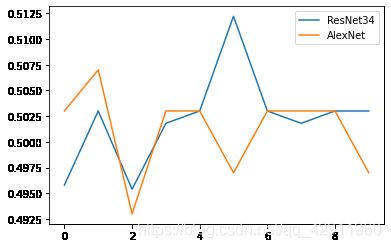
之前展示的代码均为最终版本。
经验总结
-
深度学习程序的总体运行步骤是先把数据位置读到一个Dataset的派生类里,并且在这个类里重载两个虚函数。然后在train函数里写清楚训练的过程,先后是通过dataloader生成一个可以迭代的对象,以batch_size的规模放进神经网络,然后通过optimizer进行反向传播以更新参数。在具体构造model时,有两个函数特别重要:初始化函数__init__里定义模型如何构造的,从卷积层转换到全链接层时要输入正确的维数;forward函数,则是将所有定义的模块按照特定的方式组合起来。model和train函数应该是相互独立的,更改任何一个都不会对另一个造成影响,否则修改起来很麻烦。
-
对于大数据集,Pytorch提供的内存清除机制不够智能,自己对反复调参几次显存就会溢出,所以解决方案是显式地调用del函数,当图片处理完毕,结束循环的时候,要及时清理内存,但是也要注意不能把循环外存储结果的列表也删了。
-
权重初始化对于模型也有影响,不同的迭代起点会影响收敛情况,不过感觉影响也不是很大,具体使用哪个初始化方法需要实验测试才能知道。
-
图像预处理时用到的torchvision.transforms模块高版本不能向下兼容,很多网上的代码用的是旧版本,所以一直报错,最好的办法是阅读官方文档,而且还要对应当前的版本,还有就是直接看源代码,不能迷信网上别人的代码,即使他们能跑通,放在自己这里也不一定可以成功,而且有些变换还有类型转换的问题,比如Normailize,使用起来尤其麻烦。
-
尽管使用的两个模型都在业界非常有名,但是我还是不能够取得理想的效果,我觉得这些深度学习模型的泛化能力可能有很强的局限性,如果不给出具体的参数,同样的模型在同样的数据集也可能跑出截然不同的效果。