Generative Image Inpainting with Contextual Attention
文章目录
- 1. Introduction
- 2. Related Work
-
- 2.1 Image Inpainting(图像修复)
- 2.2 Attention(感知模型)
- 3. Improved Generative Inpainting Network
-
- 3.1 Coarse-to-fine network architecture
- 3.2 Global and local Wasserstein GANs
- 3.3 Spatiallydiscountedreconstructionloss(空间衰减重构损失)
- 4. Image Inpainting with Contextual Attention
-
- 4.1 Contextual Attention
- 4.2 Unified Inpainting Network
- 5.参考文献
1. Introduction
基于卷积的修复方法通常可能会造成边界人造视觉,结构扭曲,纹理模糊、与周围区域不一致性的修复结果。
作者认为,这是卷积神经网络在建模远距离的上下文信息与缺失区域之间长距离相关的无效性。例如为了让一个像素被原始图片上64x64个像素所影响,那么至少需要6层的3x3的卷积核并且空洞卷积参数为2.而空洞卷积是规则对称的进行取样特征,不能去权衡哪些像素点是有用的哪些是无用的。最近有一篇文章 High-resolution image inpainting using multi-scale neural 尝试解决这个修复结果外观的矛盾,通过优化生成区域patches和图像已知的区域patches之间的纹理相似度.尽管改善了视觉效果,但是增加的图像修复推理的时间。
本文的的网络包含两个阶段,第一个阶段是一个简单的空洞卷积,通过重建损失来获取缺失区域的大致内容,在第二个阶段,嵌入了上下文注意力。上下文注意力机制的核心是使用已知的区域patches的特征作为卷积过滤器(convolutional filter)去处理生成区域的patches.上下文注意力模块还包含空间传播层来保持空间的一致性。为了为了让网络能够生成新的内容,与注意力层还有一个平行的卷积路径,这两个结果最终会合并在一起送入一个解码器中来最终获得结果。
整个网络通过重建损失和两个WGAN损失被端到端的进行训练,这两个WGAN,一个用来看全局的图片,一个用来看修复区域的patches。
总结本文的贡献:
- 提出了一个新颖的上下文注意力层来明确的注意远距离的相关的特征patches
- global and local WGANs、空间重建损失来提高训练的稳定性和速度
2. Related Work
2.1 Image Inpainting(图像修复)
现有的图像修复技术分为两个流派,一个是传统算法,其基于扩散(diffusion)或斑块(patch-based),只能提取出低维特征(low-level features)。另一个是基于学习的算法,比如训练深度卷积神经网络来预测像素值。
传统的扩散或斑块算法,通常使用变分算法(variational algorithms)或斑块相似性来将图像信息从背景区域传播到缺失区域内,这些算法在静态纹理(stationary textures)比较适用,但在处理一些非静态纹理(non-stationary textures)比如自然景观就不行了。
Simakov等人提出的基于双向斑块相似性的方法(bidirectional patch similarity-based scheme)可以更好地模拟非静态纹理,但计算量十分巨大,无法投入使用。
最近,深度学习和基于GAN的方法在图像修复领域很有前途,初始的研究是将卷积网络用于图像去噪、小区域的图像修复。内容编码器(Context Encoder)首先被用于训练大面积图像修复的深度神经网络。它使用GAN的损失值加上2-范数(MSE)作为重建损失值(reconstruction loss)来作为目标函数。
更进一步的研究,比如Iizuka等人提出了利用全局和局部的判别器(Discriminator)来作为GAN的对抗损失,全局判别器用于判定整幅图像的语义一致性,局部判别器专注于小块生成区域的语义,以此来保证修复出的图像的高度一致性。
此外,Iizuka等人还使用了扩展卷积(dialated convolutions)的方式来替代内容编码器的全连接层,这两种方法的目标都是为了提高输出神经元(output neurons)的感受野的大小。
与此同时,还有多项研究专注于人脸的图像生成修复。例如Yeh等人通过在缺失区域的周围寻找一种编码,来尝试解码来获得完整的图像。Li等人引入了额外的人脸完整度作为损失值来训练网络。然而这些方法通常都需要图像的后续处理,来修复缺失区域边界上的色彩一致性(color coherency)。
2.2 Attention(感知模型)
3. Improved Generative Inpainting Network
3.1 Coarse-to-fine network architecture
第一个粗阶段,利用重建损失修复出缺失区域的大概轮廓,第二个阶段在第一个阶段修复图面的基础上,进行两个分支的卷积,其中一个分支的卷积路径上加上Context Attention,最后将两个分支的卷积结果合并在一起,利用重建损失和GAN损失,进行修复。此外,在对图像进行鉴别时,作者发现,将全图特征和局部特征分开进行鉴别比将二者concatenation后进行鉴别的效果好。
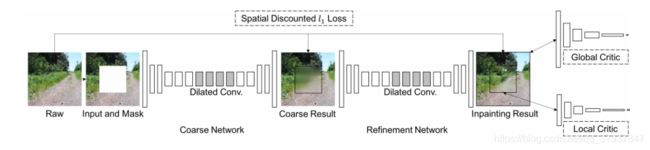
整个网络的输入和输出和Iizuka的网络设定是一样的,也就是说,生成网络的输入是一张带有白色mask的图像,以及一个用于表示mask区域的二进制串,输出是一张完整的图像。作者配对(pair)了输入的图像和对应的二进制mask,这样就可以处理任意大小、任意位置、任意形状的mask了。
网络的输入是带有随机矩形缺失区域的256x256图像,训练后的模型可以接受包含多个孔洞的任意大小的图像。
在图像修复任务中,感受野的大小决定了修复的质量,Iizuka等人通过使用扩张卷积(dilated convolution)来增大感受野,为了进一步增大感受野,作者提出了粗细网络的概念。
粗网络(Coarse network)仅仅使用使用重构损失进行训练,而细网络(Refinement network)使用重构损失+两个GAN损失进行训练。
直观上,细网络比带有缺失区域的图像看到的场景更完整(译者注:因为粗网络已经修复了一部分),因此编码器比粗网络能更好地学习特征表示。这种二阶段(two-stage)的网络架构类似于残差学习(residual learning)或是深度监督机制(deep supervision)。
为了提高网络的训练效率以及减少参数的数量,作者使用了窄而深(thin and deep)的网络,在layer的实现方面,作者对所有layer的边界使用了镜像填充(mirror padding),移除了批归一化(batch normalization),原因是作者发现批归一化会降低修复的图像色彩的一致性。此外,作者使用了ELUs来替代ReLU,通过对输出卷积核的值的裁剪(clip the output filter values)来替代激活函数tanh或是sigmoid。另外,作者发现将全局和局部的特征表示分开,而不是合并到一起(Iizuka的网络合并到一起了),能够更好地对GAN进行训练。
3.2 Global and local Wasserstein GANs
先前的修复文章大都使用DCGAN进行图像修复,本文的作者提出了WGAN-PG的修改版本,通过在第二阶段在全局鉴别器和局部鉴别器中使用WGAN-GP,来增强全局和局部的一致性。
3.3 Spatiallydiscountedreconstructionloss(空间衰减重构损失)
对于图像修复问题,一个缺失区域可能会有多种可行的修复结果。一个可行的修复结果可能会和原始图像差距很大,如果使用原始图像作为唯一的参照标准(ground truth),计算重构损失(reconstruction loss)时就会误导卷积网络的训练过程。直观上来说,在缺失区域的边界上修复的结果的歧义性(ambiguity),要远小于中心区域(译者注:这里的意思是边界区域的取值范围要比中心区域小)。这与强化学习中的问题类似。当长期奖励(long-term rewards)有着很大的取值范围时,人们在采样轨迹(sampled trajectories)上使用随着时间衰减的奖励(译者注:随着时间的流逝,网络得到的奖励会越来越小)。受这一点的启发,作者提出了空间衰减重构损失。
即:随着像素点越靠近中心位置,权重越来越小,以此来减小中心区域的权值,使计算损失值时,不会因为中心结果和原始图像差距过大,从而误导训练过程
具体的做法是使用一个带有权值的mask M,在M上,每一点的权值由γl来计算,其中γ被设定为0.99,l是该点到最近的已知像素点的距离(1-范数)。
这种掩码的构造方式如下:
def spatial_discounting_mask(config):
"""Generate spatial discounting mask constant.
Spatial discounting mask is first introduced in publication:
Generative Image Inpainting with Contextual Attention, Yu et al.
Args:
config: Config should have configuration including HEIGHT, WIDTH,
DISCOUNTED_MASK.
Returns:
tf.Tensor: spatial discounting mask
"""
gamma = config['spatial_discounting_gamma']#论文中设置为0.99
height, width = config['mask_shape']
shape = [1, 1, height, width]
if config['discounted_mask']:
mask_values = np.ones((height, width))
for i in range(height):
for j in range(width):
mask_values[i, j] = max(
gamma ** min(i, height - i),
gamma ** min(j, width - j))#实际上是根据像素值离边界值最小的距离来计算的
mask_values = np.expand_dims(mask_values, 0)
mask_values = np.expand_dims(mask_values, 0)
else:
mask_values = np.ones(shape)
spatial_discounting_mask_tensor = torch.tensor(mask_values, dtype=torch.float32)
if config['cuda']:
spatial_discounting_mask_tensor = spatial_discounting_mask_tensor.cuda()
return spatial_discounting_mask_tensor
近似的权重衰减方法在其他人的研究中也被提到了(例如Pathak等人的研究),在修复大面积缺失区域的时候,这种带衰减的损失值在提高修复质量上将更有效。通过上述提升的方法,作者的生成修复网络有着比Iizuka的网络更快的收敛速度,结果也更精确。此外也不需要图像的后续处理了。
4. Image Inpainting with Contextual Attention
卷积神经网络通过一层层的卷积核,很难从远处区域提取图像特征,为了克服这一限制。作者考虑了感知机制(attention mechanism)以及提出了内容感知层(contextual attention layer)。在这一部分,作者首先讨论内容感知层的细节,然后说明如何将它融入生成修复网络中。
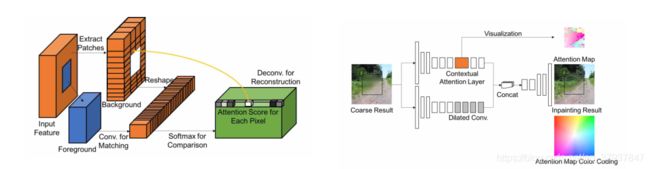
4.1 Contextual Attention
内容感知层学习的内容是:应该借鉴图像已知区域的何处来修复图像的缺失区域?
这个层是可微分的,应该可以在深度模型和全卷积网络中进行训练。
-
Match and attend(匹配和选取)
作者想解决的问题是:在背景区域中匹配缺失区域的特征。
首先在背景区域中提取3x3的patch,作为卷积核,为了匹配前景(缺失的区域)patch,使用标准的化内积(余选相似度)来测量,然后用softmax来为每个背景斑块计算权值,最后选取出一个最好的斑块,并反卷积出前景区域。对于反卷积过程中的重叠区域(overlapped pixels)取平均值。
-
Attention propagation
(比较难懂)
为了进一步保持图像的一致性,作者使用了感知传播。思想是对前景区域做偏移,可能对应和背景区域做相同的偏移,实现方式是使用单位矩阵作为卷积核,从而做到对图像的偏移。作者先做了左右传播,然后再做上下传播。从而得到新的感知分数(attention score)。该方法有效的提高了修复的结果,以及在训练过程中提供了更丰富的梯度。
3.Memory efficiency
假设在128x128的图像中有个64x64的缺失区域作为输入,那么从背景区域提取出的卷积核个数是12288个(3x3大小)。这可能会超过GPU的显存限制。
为了克服这一问题,作者介绍两种方法:
1)在提取背景斑块时添加步长参数来减少提取的卷积核个数;2)在卷积前降低前景区域(缺失区域)的分辨率,然后在感知传播后提高感知图(attention map)的大小。
4.2 Unified Inpainting Network
为了将感知网络嵌入到第二阶段的修复网络中,作者在第二阶段的修复结构上提出了两个平行的分支。结构看上图,下面那个分支通过扩张卷积()来修复缺失区域的内容,而上面那个分支则关注提取感兴趣的背景区域。最后将两个分支的输出,cancat一起到一个解码器中,反卷积出最后的结果。
训练步骤:

5.参考文献
1.2018Generative Image Inpainting with Contextual Attention
2.https://www.cnblogs.com/bingmang/p/10000992.html