《统计学习方法》部分课后习题解答
习题3.2
利用例题3.2构造的kd树求出点 x = ( 3 , 4.5 ) T x=(3,4.5)^T x=(3,4.5)T的最近邻点
- 从根节点出发,因为 x ( 1 ) < 7 x^{(1)}<7 x(1)<7, 所以进入左孩子一侧,又因为 x ( 2 ) > 4.5 x^{(2)}>4.5 x(2)>4.5,所以选定叶节点 ( 4 , 7 ) (4,7) (4,7)作为“当前最近点”,开始递归。
- 向上回退到 ( 4 , 7 ) (4,7) (4,7)的父节点 ( 5 , 4 ) (5,4) (5,4),设其为当前节点,因为父节点离 x x x更近一些,所以更新"当前最近点"为 ( 5 , 4 ) (5,4) (5,4)。
- 因为父节点 ( 5 , 4 ) (5,4) (5,4)生成的超平面 x ( 2 ) = 4 x^{(2)}=4 x(2)=4 与以 x = ( 3 , 4.5 ) x=(3,4.5) x=(3,4.5)为圆心,以 17 2 \frac{\sqrt{17}}{2} 217为半径的圆有交点,所以还需要判断当前节点的左孩子 ( 2 , 3 ) (2,3) (2,3)是不是更近。
- 因为左子树中只有一个节点,所以可以直接判断得知,需要更新“当前最近点”为 ( 2 , 3 ) (2,3) (2,3),此时距离为 13 2 \frac{\sqrt{13}}{2} 213,然后回到父节点 ( 5 , 4 ) (5,4) (5,4),把当前节点设为更高一层的 ( 7 , 2 ) (7,2) (7,2)。
- 因为 ( 7 , 2 ) (7,2) (7,2)更远,所以不更新“当前最近点”。
- 因为 ( 7 , 2 ) (7,2) (7,2)形成的超平面 x ( 1 ) = 7 x^{(1)}=7 x(1)=7与以 ( 2 , 3 ) (2,3) (2,3)为圆心,以 13 2 \frac{\sqrt{13}}{2} 213为半径的圆没有交点,所以当前节点的右子树不用进行检测。
- 因为 ( 7 , 2 ) (7,2) (7,2)已经是根节点了,所以结束搜索,得到最近邻点是 ( 2 , 3 ) (2,3) (2,3)。
习题3.3
参照算法3.3,写出输出为x的k近邻的算法
令算法3.3得到的函数为
a p p r o x _ n o d e = N N ( k d _ t r e e , n o d e ) approx\_node = NN(kd\_tree, node) approx_node=NN(kd_tree,node)
即输入一个kd树以及目标点 x x x,就会输出一个最近的节点 a p p r o x _ n o d e approx\_node approx_node,此外还需要调用之前的算法3.2来构造kd树,
t r e e = k d _ t r e e ( d a t a s e t ) tree = kd\_tree(dataset) tree=kd_tree(dataset)
下面就用这两个函数,写出能得到k个最近的节点的函数 K N N KNN KNN,
#输入:目标点x,最近邻的数量k,数据集T
#输出:k个T中的节点
def KNN(dataset T, int k, node x):
node_list = []
tree = kd_tree(T)
for i in range(1,k+1):
approx_node = NN(tree)
node_list.append(approx_node)
if node.depth != 1:
tree.approx_node.x[1] = inf
else:
tree.approx_node.x[2] = inf
return node_list
这个函数的想法就是重复调用k次 N N NN NN函数,因为重新建立kd树的计算复杂度为 O ( N ) O(N) O(N),而每次查找的平均计算复杂度仅为 O ( log N ) O(\log{N}) O(logN),所以为了不重新建树,需要更改树本身的结构来代替,方法是每次找到的最近邻点加入到一个待输出的列表中,然后更改最近邻点的坐标,使其距离目标点充分远,不会影响下一次最近邻点的选择。
习题4.1
用极大似然估计法,推出朴素贝叶斯法中的概率估计公式 ( 4.8 ) (4.8) (4.8)以及公式 ( 4.9 ) (4.9) (4.9)
证明公式 ( 4.8 ) (4.8) (4.8):
假设先验概率为
p = P ( Y = c k ) p=P(Y=c_k) p=P(Y=ck)
一共经抽样得到 n n n个样本点,每次抽样的结果是独立同分布的,分别为 y 1 , y 2 , ⋯ , y n y_1,y_2,\cdots,y_n y1,y2,⋯,yn其中符合 y = c k y=c_k y=ck的样本点有 m m m个,那么根据二项分布,可以求得似然概率为
P ( y 1 , ⋯ , y n ) = p m ⋅ ( 1 − p ) n − m P(y_1,\cdots,y_n)=p^m\cdot (1-p)^{n-m} P(y1,⋯,yn)=pm⋅(1−p)n−m
为了要让 P ( y 1 , ⋯ , y n ) P(y_1,\cdots,y_n) P(y1,⋯,yn)的值最大,需要对 p p p求导,得到下式
d P d p = m p m − 1 ( 1 − p ) n − m − ( n − m ) p m ( 1 − p ) n − m − 1 = p m − 1 ( 1 − p ) n − m − 1 ( m − n p ) \frac{dP}{dp}=mp^{m-1}(1-p)^{n-m}-(n-m)p^m (1-p)^{n-m-1}\\ =p^{m-1}(1-p)^{n-m-1}(m-np) dpdP=mpm−1(1−p)n−m−(n−m)pm(1−p)n−m−1=pm−1(1−p)n−m−1(m−np)
所以当 p = m n p=\frac{m}{n} p=nm时,函数取得最大值,因为
m = ∑ i = 1 n I ( y i = c k ) = p [ ∑ i = 1 n I ( y i ≠ c k ) + ∑ i = 1 n I ( y i = c k ) ] = p n m = \sum_{i=1}^{n}I(y_i=c_k)=p[\sum_{i=1}^{n}I(y_i\neq c_k)+\sum_{i=1}^{n}I(y_i = c_k)]=pn m=i=1∑nI(yi=ck)=p[i=1∑nI(yi=ck)+i=1∑nI(yi=ck)]=pn
所以
P ( Y = c k ) = p = ∑ i = 1 n I ( y = c k ) n P(Y=c_k)=p=\frac{\sum_{i=1}^{n}I(y=c_k)}{n} P(Y=ck)=p=n∑i=1nI(y=ck)
证明公式 ( 4.9 ) (4.9) (4.9):
假设条件概率为
p = P ( X ( j ) = a j l ∣ Y = c k ) p=P(X^{(j)}=a_{jl}|Y=c_k) p=P(X(j)=ajl∣Y=ck)
一共经抽样得到 N N N个样本点,分别为 x 1 , x 2 , ⋯ , x N x_1,x_2,\cdots,x_N x1,x2,⋯,xN,对应的输出分别为 y 1 , y 2 , ⋯ , y N y_1,y_2,\cdots,y_N y1,y2,⋯,yN,其中符合条件 Y = c k Y=c_k Y=ck的样本点有 n n n个,那么 n n n可以用如下等式表示
n = ∑ i = 1 N I ( x i ) n=\sum_{i=1}^{N}I(x_i) n=i=1∑NI(xi)
假设它们第 j j j个分量是独立同分布的,上述 n n n个样本点中一共有 m m m个满足 X ( j ) = a j l X^{(j)}=a_{jl} X(j)=ajl,那么根据二项分布,可以求得事件 ( X ( j ) = a j l ∣ Y = c k ) (X^{(j)}=a_{jl}|Y=c_k) (X(j)=ajl∣Y=ck)似然概率为
P ( y 1 , ⋯ , y N ) = p m ⋅ ( 1 − p ) n − m P(y_1,\cdots,y_N)=p^m\cdot (1-p)^{n-m} P(y1,⋯,yN)=pm⋅(1−p)n−m
为了要让 P ( y 1 , ⋯ , y n ) P(y_1,\cdots,y_n) P(y1,⋯,yn)的值最大,需要对 p p p求导,得到下式
d P d p = m p m − 1 ( 1 − p ) n − m − ( n − m ) p m ( 1 − p ) n − m − 1 = p m − 1 ( 1 − p ) n − m − 1 ( m − n p ) \frac{dP}{dp}=mp^{m-1}(1-p)^{n-m}-(n-m)p^m (1-p)^{n-m-1}\\ =p^{m-1}(1-p)^{n-m-1}(m-np) dpdP=mpm−1(1−p)n−m−(n−m)pm(1−p)n−m−1=pm−1(1−p)n−m−1(m−np)
所以当 p = m n p=\frac{m}{n} p=nm时,函数取得最大值,又因为
m = ∑ i = 1 N I ( y i = c k ) = p ( ∑ i = 1 N I ( y i = c k ) + ∑ i = 1 N I ( y i ≠ c k ) ) = p N m = \sum_{i=1}^{N}I(y_i=c_k)=p(\sum_{i=1}^{N}I(y_i=c_k)+\sum_{i=1}^{N}I(y_i\neq c_k))=pN m=i=1∑NI(yi=ck)=p(i=1∑NI(yi=ck)+i=1∑NI(yi=ck))=pN
所以
P ( X ( j ) = a j l ∣ Y = c k ) = p = ∑ i = 1 N I ( x i j = a j l , y i = c k ) ∑ i = 1 N I ( y i = c k ) P(X^{(j)}=a_{jl}|Y=c_k)=p=\frac{\sum_{i=1}^{N}I(x_i^{j}=a_{jl},y_i=c_k)}{\sum_{i=1}^{N}I(y_i=c_k)} P(X(j)=ajl∣Y=ck)=p=∑i=1NI(yi=ck)∑i=1NI(xij=ajl,yi=ck)
习题5.1
根据表5.1所给的训练数据集,利用信息增益比(C4.5算法)生成决策树
首先分别以 A 1 A_1 A1, A 2 A_2 A2, A 3 A_3 A3, A 4 A_4 A4,表示年龄,有工作,有房子,信贷情况,整个数据集记为 D D D
第一轮
根据定义5.3, 可以计算出数据集 D D D关于每个特征 A A A的值的熵
H A 1 ( D ) = 1.584 H A 2 ( D ) = 0.918 H A 3 ( D ) = 0.971 H A 4 ( D ) = 1.566 H_{A_1}(D) = 1.584 \\ H_{A_2}(D) = 0.918 \\ H_{A_3}(D) = 0.971 \\ H_{A_4}(D) = 1.566 HA1(D)=1.584HA2(D)=0.918HA3(D)=0.971HA4(D)=1.566
然后再根据例5.2得到的如下信息增益,
g ( D , A 1 ) = 0.083 g ( D , A 2 ) = 0.324 g ( D , A 3 ) = 0.420 g ( D , A 4 ) = 0.363 g(D,A_1) = 0.083 \\ g(D,A_2) = 0.324 \\ g(D,A_3) = 0.420 \\ g(D,A_4) = 0.363 g(D,A1)=0.083g(D,A2)=0.324g(D,A3)=0.420g(D,A4)=0.363
从而得到关于每个特征的信息增益比
g R ( D , A 1 ) = 0.052 g R ( D , A 2 ) = 0.353 g R ( D , A 3 ) = 0.433 g R ( D , A 4 ) = 0.232 g_R(D,A_1) = 0.052 \\ g_R(D,A_2) = 0.353 \\ g_R(D,A_3) = 0.433 \\ g_R(D,A_4) = 0.232 gR(D,A1)=0.052gR(D,A2)=0.353gR(D,A3)=0.433gR(D,A4)=0.232
从而选择 A 3 A_3 A3作为根节点,令所有满足 A 3 = y e s A_3= yes A3=yes的数据为 D 1 D_1 D1,令所有满足 A 3 = n o A_3 = no A3=no的数据为 D 2 D_2 D2,因为 D 1 D_1 D1中所有的数据均属于同一类,所以不用继续递归了,而 D 2 D_2 D2中数据不是同一类,所以需要第二轮递归再进一步分类。
第二轮
再来计算数据集 D 2 D_2 D2关于其余每个特征的 A A A的值的熵
H A 1 ( D 2 ) = 1.530 H A 2 ( D 2 ) = 0.918 H A 4 ( D 2 ) = 0.340 H_{A_1}(D_2) = 1.530 \\ H_{A_2}(D_2) = 0.918\\ H_{A_4}(D_2) = 0.340 HA1(D2)=1.530HA2(D2)=0.918HA4(D2)=0.340
再计算信息增益
g ( D 2 , A 1 ) = 0.251 g ( D 2 , A 2 ) = 0.918 g ( D 2 , A 4 ) = 0.474 g(D_2,A_1) = 0.251\\ g(D_2,A_2) = 0.918\\ g(D_2,A_4) = 0.474 g(D2,A1)=0.251g(D2,A2)=0.918g(D2,A4)=0.474
从而得到关于每个特征的信息增益比
g R ( D 2 , A 1 ) = 0.164 g R ( D 2 , A 2 ) = 1.000 g R ( D 2 , A 4 ) = 0.340 g_R(D_2,A_1) = 0.164\\ g_R(D_2,A_2) = 1.000\\ g_R(D_2,A_4) = 0.340 gR(D2,A1)=0.164gR(D2,A2)=1.000gR(D2,A4)=0.340
选择信息增益比最大的特征 A 2 A2 A2作为节点的特征,发现两个分支形成的数据集 D 21 D_{21} D21和 D 22 D_{22} D22里的元素都属于同一类别,所以递归结束。
最终结果
习题5.2
已知如下表所示的训练数据,试用平方误差损失准则生成一个二叉回归树
x 1 x_1 x1 x 2 x_2 x2 x 3 x_3 x3 x 4 x_4 x4 x 5 x_5 x5 x 6 x_6 x6 x 7 x_7 x7 x 8 x_8 x8 x 9 x_9 x9 x 10 x_{10} x10 4.50 4.75 4.91 5.34 5.80 7.05 7.90 8.23 8.70 9.00
因为数据集的输入变量 x i x_i xi是标量,所以直接扫描切分点,把样本点递归分成若干区间,具体的分化情况如下图所示
习题5.3
证明CART剪枝算法中,当 α \alpha α确定时,存在唯一的最小子树 T α T_{\alpha} Tα使损失函数 C α ( T ) C_{\alpha}(T) Cα(T)最小
先证明存在性:
因为给定的数据集通过算法得到的生成树是确定的,所以所有可能的子树数量是有限的,所以一定存在若干子树,使得损失函数 C α ( T ) C_{\alpha}(T) Cα(T)是其中最小的,存在性得证
再证明唯一性:
在 α \alpha α确定的情况下,假设存在两棵不同的 T T T的子树 P P P和 Q Q Q,使得损失函数均是最小的,即
C α ( P ) = C α ( Q ) C_{\alpha}(P)=C_{\alpha}(Q) Cα(P)=Cα(Q)
首先证明:根据CART剪枝算法的规则, P P P和 Q Q Q至少各有一处叶结点互不相同。
假设命题不成立,那么 P P P和 Q Q Q存在了包含关系,不妨设对于叶结点 t t t,有 t ∈ P t\in P t∈P但是 t ∉ Q t \notin Q t∈/Q,这是不可能的,因为选择剪枝的时候,需要满足
C α ( T t ) < C α ( t ) C_{\alpha}(T_t) < C_{\alpha}(t) Cα(Tt)<Cα(t)
从而不满足损失函数相等的条件,假设不成立。
再来证明:在 P P P和 Q Q Q至少各有一处叶结点互不相同的情况下,两棵子树均不是最优的。
假设 P P P中有结点 p p p满足 p ∉ Q p \notin Q p∈/Q,并且 Q Q Q中有结点 q q q满足 q ∉ P q \notin P q∈/P,那么根据剪枝的规则,可得
C α ( T p ) > C α ( p ) C α ( T q ) > C α ( q ) C_{\alpha}(T_p) > C_{\alpha}(p) \\ C_{\alpha}(T_q) > C_{\alpha}(q) Cα(Tp)>Cα(p)Cα(Tq)>Cα(q)
否则剪枝不会发生,所以存在 T T T的子树 M M M满足 q ∉ M q\notin M q∈/M并且其余叶结点与 P P P一样,那么 M M M比 P P P的损失函数更小,从而也比 Q Q Q的损失函数更小,假设不成立,从而原命题得证。
习题6.2
写出逻辑斯蒂回归模型学习的梯度下降算法
假设给定的数据集为 X = { x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) } X=\{x^{(1)},x^{(2)},\cdots,x^{(m)}\} X={ x(1),x(2),⋯,x(m)},对应的标签为 Y = { y ( 1 ) , y ( 2 ) , ⋯ , y ( m ) } Y=\{y^{(1)},y^{(2)},\cdots,y^{(m)}\} Y={ y(1),y(2),⋯,y(m)},
其中 x ( i ) = ( x 1 ( i ) , ⋯ , x n − 1 ( i ) , 1 ) ∈ R n x^{(i)}=(x_1^{(i)},\cdots,x_{n-1}^{(i)},1) \in R^n x(i)=(x1(i),⋯,xn−1(i),1)∈Rn, y ( i ) ∈ { 0 , 1 } y^{(i)} \in \{0,1\} y(i)∈{ 0,1},特别需要说明的是,这里把常数项放到了数据集里,所以最后一个分量都是 1 1 1,需要学习的参数记为 ω = ( ω 1 , ω 2 , ⋯ , ω n ) \omega = (\omega_1,\omega_2,\cdots,\omega_n) ω=(ω1,ω2,⋯,ωn)。根据书本第93页的推导可知,对数似然函数为
L ( ω ) = ∑ i = 1 m [ y ( i ) ( ω ⋅ x ( i ) ) − log ( 1 + exp ( ω ⋅ x ( i ) ) ) ] L(\omega) = \sum_{i=1}^{m}[y^{(i)}(\omega \cdot x^{(i)})-\log(1+\exp{(\omega \cdot x^{(i)})})] L(ω)=i=1∑m[y(i)(ω⋅x(i))−log(1+exp(ω⋅x(i)))]
需要对 L ( ω ) L(\omega) L(ω)求偏导数
∇ L ( ω ) = ( ∂ L ∂ ω 1 , ⋯ , ∂ L ∂ ω n ) \nabla L(\omega) = (\frac{\partial L}{\partial \omega_1},\cdots,\frac{\partial L}{\partial \omega_n}) ∇L(ω)=(∂ω1∂L,⋯,∂ωn∂L)
其中
∂ L ∂ ω i = x i ( i ) y − ω i exp { w 1 x 1 ( i ) + ⋯ + w n x n ( i ) } 1 + exp { w 1 x 1 ( i ) + ⋯ + w n x n ( i ) } \frac{\partial L}{\partial \omega_i}=x^{(i)}_iy-\frac{\omega_i\exp\{w_1x^{(i)}_1+\cdots+w_nx^{(i)}_n\}}{1+\exp\{w_1x^{(i)}_1+\cdots+w_nx^{(i)}_n\}} ∂ωi∂L=xi(i)y−1+exp{ w1x1(i)+⋯+wnxn(i)}ωiexp{ w1x1(i)+⋯+wnxn(i)}
从而通过设置步长 α \alpha α,终止迭代阈值eps,可以设计如下算法
- 设定迭代起点 x x x初值
- 根据上面写出来的公式,得到对应位置的梯度值 ω \omega ω
- 根据迭代步长算出新的梯度算出下个迭代点 x = x + α ω x = x + \alpha \omega x=x+αω
- 判断 α ∣ ω ∣ < e p s \alpha|\omega|< eps α∣ω∣<eps是否成立,成立则结束,否则返回第二步
习题7.1
比较感知机的对偶形式与线性可分支持向量机的对偶形式。
对于给定的数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),\cdots,(x_N,y_N)\} T={ (x1,y1),(x2,y2),⋯,(xN,yN)}
其中 x i ∈ R n , y i ∈ { − 1 , 1 } x_i \in R^n, y_i \in \{-1,1\} xi∈Rn,yi∈{ −1,1}, i = 1 , 2 , ⋯ , N i=1,2,\cdots,N i=1,2,⋯,N,最后学习到的平面
ω ⋅ x + b = 0 \omega \cdot x+b=0 ω⋅x+b=0
的参数,在两个算法的对偶形式中,有如下不同的计算方法:
感知机的对偶形式
ω = ∑ i = 1 N α i y i x i b = ∑ i = 1 N α i y i \omega=\sum_{i=1}^{N}\alpha_iy_ix_i \\ b = \sum_{i=1}^{N}\alpha_iy_i ω=i=1∑Nαiyixib=i=1∑Nαiyi
其中的 α = ( α 1 , ⋯ , α N ) \alpha=(\alpha_1,\cdots,\alpha_N) α=(α1,⋯,αN),对于 ∀ i ∈ { 1 , 2 , ⋯ , N } \forall i \in \{1,2,\cdots,N\} ∀i∈{ 1,2,⋯,N},都有
y i ( ∑ j = 1 N α i y j x j ⋅ x i + b ) ≤ 0 y_i(\sum_{j=1}^{N}\alpha_iy_jx_j \cdot x_i+b) \leq 0 yi(j=1∑Nαiyjxj⋅xi+b)≤0
线性可分支持向量机的对偶形式
ω = ∑ i = 1 N α i y i x i b = y 1 − ∑ i = 1 N α i y 1 ( x i ⋅ x j ) \omega=\sum_{i=1}^{N}\alpha_iy_ix_i \\ b = y_1 - \sum_{i=1}^{N}\alpha_iy_1(x_i \cdot x_j) ω=i=1∑Nαiyixib=y1−i=1∑Nαiy1(xi⋅xj)
其中的 α = ( α 1 , ⋯ , α N ) \alpha=(\alpha_1,\cdots,\alpha_N) α=(α1,⋯,αN)是通过求解
arg min α ( 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i ) \mathop{\arg\min}\limits_{\alpha} ( \frac{1}{2}\sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_j(x_i\cdot x_j)-\sum_{i=1}^{N}\alpha_i) αargmin(21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)−i=1∑Nαi)
得到的,还要满足额外的约束条件 a i ≥ 0 a_i \geq 0 ai≥0, ∀ i ∈ { 1 , ⋯ , N } \forall i \in \{1,\cdots,N\} ∀i∈{ 1,⋯,N},并且
∑ i = 1 N α i y i = 0 \sum_{i=1}^{N}\alpha_iy_i = 0 \\ i=1∑Nαiyi=0
习题7.2
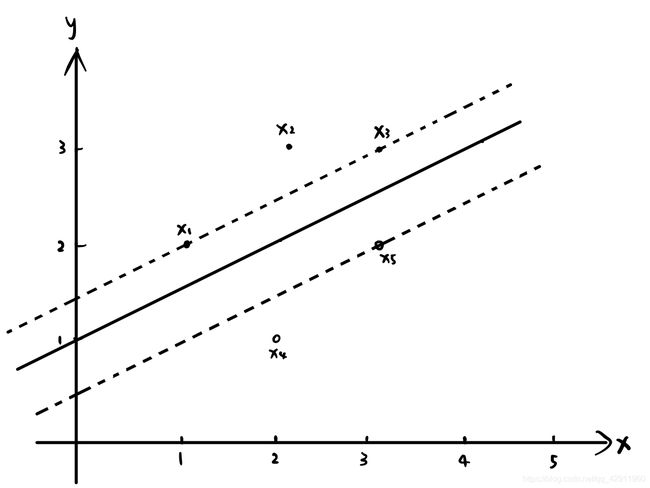
已知正例点 x 1 = ( 1 , 2 ) T x_1=(1,2)^T x1=(1,2)T, x 2 = ( 2 , 3 ) T x_2=(2,3)^T x2=(2,3)T, x 3 = ( 3 , 3 ) T x_3=(3,3)^T x3=(3,3)T,负例点 x 4 = ( 2 , 1 ) T x_4=(2,1)^T x4=(2,1)T, x 5 = ( 3 , 2 ) T x_5=(3,2)^T x5=(3,2)T,试求最大间隔分离超平面和分类决策函数,并在图上画出分离超平面,间隔边界及支持向量。
按照最大间隔法,根据训练数据集构造约束最优化问题:
min ω , b ω 1 2 + ω 2 2 2 \min_{\omega,b} \frac{\omega_1^2+\omega_2^2}{2} ω,bmin2ω12+ω22
使得
ω 1 + 2 ω 2 + b ≥ 1 2 ω 1 + 3 ω 2 + b ≥ 1 3 ω 1 + 3 ω 2 + b ≥ 1 − 2 ω 1 − ω 2 − b ≥ 1 − 3 ω 1 − 2 ω 2 − b ≥ 1 \omega_1+2\omega_2+b\geq 1 \\ 2\omega_1+3\omega_2+b\geq 1 \\ 3\omega_1+3\omega_2+b\geq 1 \\ -2\omega_1 - \omega_2 - b\geq 1 \\ -3\omega_1-2\omega_2-b\geq 1 ω1+2ω2+b≥12ω1+3ω2+b≥13ω1+3ω2+b≥1−2ω1−ω2−b≥1−3ω1−2ω2−b≥1
计算得当 ω = ( 1 , − 2 ) \omega=(1,-2) ω=(1,−2), b = 2 b=2 b=2时,目标函数取到最小值,所得的超平面为
x − 2 y + 2 = 0 x-2y+2=0 x−2y+2=0
即为下图中的实线,位于边界上的点是支持向量
习题7.3
线性支持向量机还可以定义为以下形式:
min ω , b , ξ ∣ ∣ ω ∣ ∣ 2 + C ∑ i = 1 N ξ i 2 \min_{\omega,b,\xi}\frac{||\omega||}{2}+C\sum_{i=1}^{N}\xi_i^2 ω,b,ξmin2∣∣ω∣∣+Ci=1∑Nξi2
使得
y i ( ω ⋅ x i + b ) ≥ 1 − ξ i , i = 1 , 2 , ⋯ , N ξ i ≥ 0 , i = 1 , 2 , ⋯ , N y_i(\omega \cdot x_i+b)\geq 1-\xi_i,\quad i=1,2,\cdots,N \\ \xi_i\geq0 ,\quad i=1,2,\cdots,N yi(ω⋅xi+b)≥1−ξi,i=1,2,⋯,Nξi≥0,i=1,2,⋯,N
试求其对偶形式。
定义拉格朗日函数
L ( w , b , ξ , α , β ) = ∥ w ∥ 2 2 + C ∑ i = 1 N ξ i 2 + ∑ i = 1 N α i ( 1 − ξ i − y i ( w ⋅ x i + b ) ) − ∑ i = 1 N β i ξ i L(w,b,\xi, \alpha, \beta) = \frac{\|w\|^2}{2} + C \sum_{i=1}^N \xi_i^2 + \sum_{i=1}^N \alpha_i (1-\xi_i-y_i (w \cdot x_i + b)) - \sum_{i=1}^N \beta_i \xi_i L(w,b,ξ,α,β)=2∥w∥2+Ci=1∑Nξi2+i=1∑Nαi(1−ξi−yi(w⋅xi+b))−i=1∑Nβiξi
分别对 w , b , ξ w,b,\xi w,b,ξ求偏导数
{ ∇ ξ L = 2 C ξ i − α i − β i = 0 ∇ w L = w − ∑ i = 1 N α i y i x i = 0 ∇ b L = − ∑ i = 1 N α i y i = 0 \left \{ \begin{array}{l} \displaystyle \nabla_{\xi} L = 2C \xi_i - \alpha_i - \beta_i = 0 \\ \displaystyle \nabla_w L = w - \sum_{i=1}^N \alpha_i y_i x_i = 0 \\ \displaystyle \nabla_b L = -\sum_{i=1}^N \alpha_i y_i = 0 \\ \end{array} \right. ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧∇ξL=2Cξi−αi−βi=0∇wL=w−i=1∑Nαiyixi=0∇bL=−i=1∑Nαiyi=0
从而可以化简为
{ ξ i = 1 2 C ( α i + β i ) ∑ i = 1 N α i y i = 0 w = ∑ i = 1 N α i y i x i \left \{ \begin{array}{l} \displaystyle \xi_i = \frac{1}{2C}(\alpha_i + \beta_i) \\ \displaystyle \sum_{i=1}^N \alpha_i y_i = 0 \\ \displaystyle w = \sum_{i=1}^N \alpha_i y_i x_i \end{array} \right. ⎩⎪⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎪⎧ξi=2C1(αi+βi)i=1∑Nαiyi=0w=i=1∑Nαiyixi
解得对拉格朗日函数中的 ω \omega ω和 ξ \xi ξ做变量替换,得到新的形式
L ( α , β ) = − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) + ∑ i = 1 N α i − 1 4 C ∑ i = 1 N ( α i + β i ) 2 L(\alpha,\beta)=-\frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j y_i y_j (x_i \cdot x_{j})+\sum_{i=1}^N \alpha_i-\frac{1}{4C}\sum_{i=1}^N(\alpha_i+\beta_i)^2 L(α,β)=−21i=1∑Nj=1∑Nαiαjyiyj(xi⋅xj)+i=1∑Nαi−4C1i=1∑N(αi+βi)2
那么对偶问题就是求解
arg min α , β L ( α , β ) \mathop{\arg\min}\limits_{\alpha,\beta}L(\alpha,\beta) α,βargminL(α,β)
还要满足额外的约束条件 a i ≥ 0 a_i \geq 0 ai≥0, ∀ i ∈ { 1 , ⋯ , N } \forall i \in \{1,\cdots,N\} ∀i∈{ 1,⋯,N},并且
∑ i = 1 N α i y i = 0 \sum_{i=1}^{N}\alpha_iy_i = 0 i=1∑Nαiyi=0
习题7.4
证明内积的正整数幂函数:
K ( x , z ) = ( x ⋅ z ) p K(x,z)=(x \cdot z)^p K(x,z)=(x⋅z)p
是正定核函数,这里 p p p是正整数, x , z ∈ R n x,z \in \mathbb{R^n} x,z∈Rn
用数学归纳法证明:对于 ∀ α = ( α 1 , ⋯ , α n ) T \forall \alpha=(\alpha_1,\cdots,\alpha_n)^T ∀α=(α1,⋯,αn)T,
当 p = 1 p=1 p=1时,因为 α T ( x ⋅ x ) α ≥ 0 \alpha^T(x \cdot x)\alpha \geq 0 αT(x⋅x)α≥0,当且仅当 α = 0 \alpha=0 α=0取等号,根据定理7.5,结论显然成立,
当 p = k p=k p=k时,假设结论成立,即存在函数 ϕ k \phi_k ϕk使得
K ( x , z ) = ϕ k ( x ) ⋅ ϕ k ( z ) K(x,z) = \phi_k(x) \cdot \phi_k(z) K(x,z)=ϕk(x)⋅ϕk(z)
那么当 p = k + 1 p=k+1 p=k+1时,
K ( x , z ) = ( x ⋅ z ) k + 1 = ϕ k ( x ) ϕ k ( z ) ( x ⋅ z ) K(x,z) = (x\cdot z)^{k+1} = \phi_k(x)\phi_k(z) (x\cdot z) K(x,z)=(x⋅z)k+1=ϕk(x)ϕk(z)(x⋅z)
令映射函数由以下形式变换得到
ϕ k ( x ) = ( f 1 ( x ) , f 2 ( x ) , ⋯ , f n ( x ) ) T \phi_k(x) = (f_1(x),f_2(x),\cdots,f_n(x))^T ϕk(x)=(f1(x),f2(x),⋯,fn(x))T
那么构造
ϕ k + 1 ( x ) = ( x 1 f 1 ( x ) , x 2 f 2 ( x ) , ⋯ , x n f n ( x ) ) T \phi_{k+1}(x) = (x_1f_1(x),x_2f_2(x),\cdots,x_nf_n(x))^T ϕk+1(x)=(x1f1(x),x2f2(x),⋯,xnfn(x))T
其中
x = ( x 1 , x 2 , ⋯ , x n ) T x=(x_1,x_2,\cdots,x_n)^T x=(x1,x2,⋯,xn)T
于是就有
K ( x , z ) = ϕ k + 1 ( x ) ⋅ ϕ k + 1 ( z ) K(x,z) = \phi_{k+1}(x)\cdot\phi_{k+1}(z) K(x,z)=ϕk+1(x)⋅ϕk+1(z)
从而当 p = k + 1 p=k+1 p=k+1时,结论也成立,命题得证
习题8.1
某公司招聘职员考察身体、业务能力、发展潜力这3项。身体分为合格0、不合格1两级,业务能力和发展潜力分为上1、中2、下3三级。分类为合格1、不合格-1两类。已知10个人的数据,如下表所示
1 2 3 4 5 6 7 8 9 10 身体 0 0 1 1 1 0 1 1 1 0 业务能力 1 3 2 1 2 1 1 1 3 2 发展潜力 3 1 2 3 3 2 2 1 1 1 分类 -1 -1 -1 -1 -1 -1 1 1 -1 -1 假设若分类器为决策树桩。用AdaBoost算法学习一个强分类器。
假设身体为 X ∈ { 0 , 1 } \mathcal{X}\in\{0,1\} X∈{ 0,1},业务能力为 Y ∈ { 1 , 2 , 3 } \mathcal{Y}\in\{1,2,3\} Y∈{ 1,2,3},发展潜力为 Z ∈ { 1 , 2 , 3 } \mathcal{Z}\in\{1,2,3\} Z∈{ 1,2,3},输入变量为
t = ( t 1 , t 2 , t 3 ) ∈ ( X , Y , Z ) t=(t_1,t_2,t_3) \in (\mathcal{X},\mathcal{Y},\mathcal{Z}) t=(t1,t2,t3)∈(X,Y,Z)
有如下三个决策树桩:
G 1 ( t ) = { 1 , t 1 = 1 − 1 , t 1 = 0 G 2 ( t ) = { 1 , t 2 = 1 − 1 , t 2 ≠ 1 G 3 ( t ) = { 1 , t 3 = 1 − 1 , t 3 ≠ 1 G_1(t)=\left\{ \begin{aligned} 1 &, &t_1=1\\ -1 &, &t_1=0 \\ \end{aligned} \\ \right. G_2(t)=\left\{ \begin{aligned} 1 &, &t_2=1\\ -1 &, &t_2\neq1 \\ \end{aligned} \right.\\ G_3(t)=\left\{ \begin{aligned} 1 &, &t_3=1\\ -1 &, &t_3\neq1 \\ \end{aligned} \right. G1(t)={ 1−1,,t1=1t1=0G2(t)={ 1−1,,t2=1t2=1G3(t)={ 1−1,,t3=1t3=1
从而可以算出对应的分类误差率 e 1 = 0.4 e_1=0.4 e1=0.4, e 2 = 0.3 e_2=0.3 e2=0.3, e 3 = 0.3 e_3=0.3 e3=0.3,从而可以算出每个弱分类器的系数
α 1 = 0.585 α 2 = 0.611 α 3 = 0.611 \alpha_1=0.585\\ \alpha_2=0.611\\ \alpha_3=0.611 α1=0.585α2=0.611α3=0.611
那么所得的强分类器为
G ( t ) = 0.585 G 1 ( t ) + 0.611 G 2 ( t ) + 0.611 G 3 ( t ) G(t) = 0.585G_1(t)+0.611G_2(t) + 0.611G_3(t) G(t)=0.585G1(t)+0.611G2(t)+0.611G3(t)
验证可知分类误差率 e = 0.2 e=0.2 e=0.2。
习题8.2
比较支持向量机、AdaBoost、逻辑斯蒂回归模型的学习策略与算法
-
支持向量机
学习策略:对于线性可分的数据集,求解目标超平面,让此超平面能正确分类所有样本点,并且离最近样本点的距离是所有超平面中最小的;对于线性不可分的数据集,给每一组数据加上一个松弛变量,在这个宽松的意义下,求解超平面让此超平面能正确分类所有样本点,让平面系数向量的模和宽松系数向量的模达到最小值。两个算法都是通过求解拉格朗日对偶问题求解的。学习算法:序列最小最优化算法,对于给定的数据集 T T T、精度 ϵ \epsilon ϵ、核函数 K K K,目标是求对偶问题的解 α \alpha α,算法具体是先将 α \alpha α初始化为 0 0 0,然后只选择两个变量,固定其余变量,求得最优解并更新 α \alpha α,检验停机条件在 ϵ \epsilon ϵ的误差范围内是否成立,不成立重新选两个变量进行循环,成立就结束循环,通过 α \alpha α得到超平面参数 ω \omega ω、 b b b。
-
AdaBoost
学习策略:极小化加法模型指数损失,提高前一轮分类器错误分类的样本权重,同时降低错误率高的分类器权重,进而将所有若分类器乘以对应的权重做线性组合,输出结果。学习算法:前向分步加法算法,对于给定的数据集合 T T T以及基函数集 { b ( γ , x ) } \{b(\gamma,x)\} { b(γ,x)},先初始化一个分类函数,然后通过极小化损失函数得到新的参数,加到之前一轮的函数上,如此循环若干次,把同时求解所有参数转化成逐个求解,每次求出当前意义下最优化的参数。
-
Logistic回归
学习策略:Logistic回归模型是以似然函数为目标的最优化问题,通过迭代算法求解,学习到的最优模型应该是所有可能概率模型中,熵最大的那个。
学习算法:改进的迭代尺度算法,思想是假设最大熵模型当前的参数向量是 ω \omega ω,然后找到一个参数 δ \delta δ,使得模型的对数似然函数增大,持续循环直到找到最大值。