open源代码分析
看一下源代码:
long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode)
{
struct open_flags op;
int lookup = build_open_flags(flags, mode, &op);
struct filename *tmp = getname(filename); // 将filename从用户空间拷贝到内核空间
int fd = PTR_ERR(tmp);
if (!IS_ERR(tmp)) {
fd = get_unused_fd_flags(flags); // 获取一个可用的fd
if (fd >= 0) {
struct file *f = do_filp_open(dfd, tmp, &op, lookup);
if (IS_ERR(f)) {
put_unused_fd(fd);
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
fd_install(fd, f); // 把file和fd关联起来
}
}
putname(tmp);
}
return fd;
}
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
do_filp_open,打开一个文件,返回一个file结构体指针,do_filp_open定义在fs/namei.c
struct file *do_filp_open(int dfd, struct filename *pathname,
const struct open_flags *op, int flags)
{
struct nameidata nd;
struct file *filp;
filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_RCU);
if (unlikely(filp == ERR_PTR(-ECHILD)))
filp = path_openat(dfd, pathname, &nd, op, flags);
if (unlikely(filp == ERR_PTR(-ESTALE)))
filp = path_openat(dfd, pathname, &nd, op, flags | LOOKUP_REVAL);
return filp;
}
可以看出,真正的文件open工作,都在path_openat里面完成,path_openat的源代码如下:
static struct file *path_openat(int dfd, struct filename *pathname,
struct nameidata *nd, const struct open_flags *op, int flags)
{
struct file *base = NULL;
struct file *file;
struct path path;
int opened = 0;
int error;
// 拿到一个初始化好的file结构体
file = get_empty_filp();
if (IS_ERR(file))
return file;
file->f_flags = op->open_flag;
// 进行目录查找前的准备工作
error = path_init(dfd, pathname->name, flags | LOOKUP_PARENT, nd, &base);
if (unlikely(error))
goto out;
current->total_link_count = 0;
error = link_path_walk(pathname->name, nd);
if (unlikely(error))
goto out;
error = do_last(nd, &path, file, op, &opened, pathname);
while (unlikely(error > 0)) { /* trailing symlink */
struct path link = path;
void *cookie;
if (!(nd->flags & LOOKUP_FOLLOW)) {
path_put_conditional(&path, nd);
path_put(&nd->path);
error = -ELOOP;
break;
}
error = may_follow_link(&link, nd);
if (unlikely(error))
break;
nd->flags |= LOOKUP_PARENT;
nd->flags &= ~(LOOKUP_OPEN|LOOKUP_CREATE|LOOKUP_EXCL);
error = follow_link(&link, nd, &cookie);
if (unlikely(error))
break;
error = do_last(nd, &path, file, op, &opened, pathname);
put_link(nd, &link, cookie);
}
out:
if (nd->root.mnt && !(nd->flags & LOOKUP_ROOT))
path_put(&nd->root);
if (base)
fput(base);
if (!(opened & FILE_OPENED)) {
BUG_ON(!error);
put_filp(file);
}
if (unlikely(error)) {
if (error == -EOPENSTALE) {
if (flags & LOOKUP_RCU)
error = -ECHILD;
else
error = -ESTALE;
}
file = ERR_PTR(error);
}
return file;
}
path_init主要是进行查找前的一些准备工作,最主要的作用是设置好nameidata数据结构中path、inode字段,即查找的起点。nameidata是用于保存path walking过程中的上下文和最后的查找结果,其源代码如下:
struct nameidata {
struct path path; /* 当前搜索的目录 path里保存着dentry指针和挂载信息vfsmount */
struct qstr last; /* 下一个待处理的component。只有last_type是LAST_NORM时这个字段才有用*/
struct path root; /* 保存根目录的信息 */
struct inode *inode; /* path.dentry.d_inode */
unsigned int flags; /* 查找相关的标志位 */
unsigned seq; /* 目录项的顺序锁序号 */
int last_type; /* This is one of LAST_NORM, LAST_ROOT, LAST_DOT, LAST_DOTDOT, or LAST_BIND. */
unsigned depth; /* 解析符号链接过程中的递归深度 */
char *saved_names[MAX_NESTED_LINKS + 1]; /* 相应递归深度的符号链接的路径 */
};
path_init 返回之后 nd 中的 path 就已经设定为起始路径了,现在可以开始遍历路径了。
total_link_count 是用来记录符号链接的深度,每穿越一次符号链接这个值就加一,最大允许 40 层符号链接。接下来 link_path_walk 会带领我们走向目标,并在到达最终目标所在目录的时候停下来(最终目标需要交给另一个函数 do_last 单独处理)。下面我们就来看看这个函数是怎样一步一步接近目标的。linux_path_walk的源代码如下:
/*
* Name resolution.
* This is the basic name resolution function, turning a pathname into
* the final dentry. We expect 'base' to be positive and a directory.
*
* Returns 0 and nd will have valid dentry and mnt on success.
* Returns error and drops reference to input namei data on failure.
*/
static int link_path_walk(const char *name, struct nameidata *nd)
{
struct path next;
int err;
while (*name=='/')
name++;
if (!*name)
return 0;
/* At this point we know we have a real path component. */
for(;;) {
struct qstr this;
long len;
int type;
err = may_lookup(nd);
if (err)
break;
len = hash_name(name, &this.hash);
this.name = name;
this.len = len;
type = LAST_NORM;
if (name[0] == '.') switch (len) {
case 2:
if (name[1] == '.') {
type = LAST_DOTDOT;
nd->flags |= LOOKUP_JUMPED;
}
break;
case 1:
type = LAST_DOT;
}
if (likely(type == LAST_NORM)) {
struct dentry *parent = nd->path.dentry;
nd->flags &= ~LOOKUP_JUMPED;
if (unlikely(parent->d_flags & DCACHE_OP_HASH)) {
err = parent->d_op->d_hash(parent, nd->inode,
&this);
if (err < 0)
break;
}
}
nd->last = this;
nd->last_type = type;
if (!name[len])
return 0;
/*
* If it wasn't NUL, we know it was '/'. Skip that
* slash, and continue until no more slashes.
*/
do {
len++;
} while (unlikely(name[len] == '/'));
if (!name[len])
return 0;
name += len;
err = walk_component(nd, &next, LOOKUP_FOLLOW);
if (err < 0)
return err;
if (err) {
err = nested_symlink(&next, nd);
if (err)
return err;
}
if (!can_lookup(nd->inode)) {
err = -ENOTDIR;
break;
}
}
terminate_walk(nd);
return err;
}
link_path_walk完成之后,可以认为除了路径中的最后一项,其余的部分都“走过”了,nd保存着最后一项的所在目录。do_last则处理最后的一个动作,可能伴随着文件打开的具体动作,具体就不再详述了。
遇到挂载点的处理
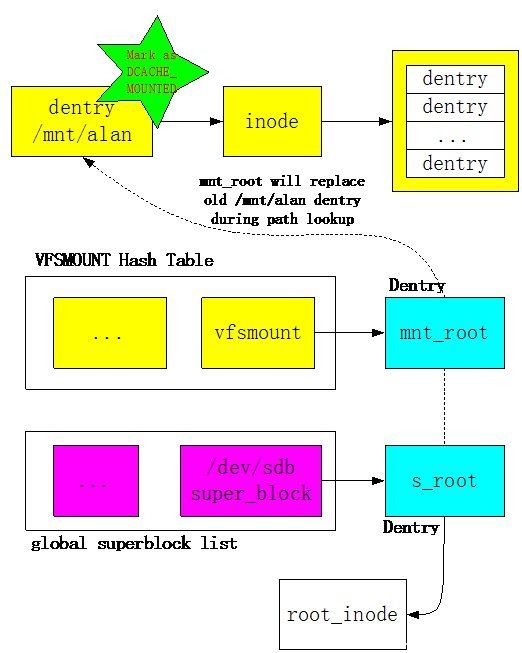
当用户输入”mount /dev/sdb /mnt/alan”命令后,Linux会解析/mnt/alan字符串,并且从Dentry Hash表中获取相关的dentry目录项,然后将该目录项标识成DCACHE_MOUNTED。一旦该dentry被标识成DCACHE_MOUNTED,也就意味着在访问路径上对其进行了屏蔽。
在mount /dev/sdb设备上的ext3文件系统时,内核会创建一个该文件系统的superblock对象,并且从/dev/sdb设备上读取所有的superblock信息,初始化该内存对象。Linux内核维护了一个全局superblock对象链表。s_root是superblock对象所维护的dentry目录项,该目录项是该文件系统的根目录。即新mount的文件系统内容都需要通过该根目录进行访问。在mount的过程中,VFS会创建一个非常重要的vfsmount对象,该对象维护了文件系统mount的所有信息。Vfsmount对象通过HASH表进行维护,通过path地址计算HASH值,在这里vfsmount的HASH值通过“/mnt/alan”路径字符串进行计算得到。Vfsmount中的mnt_root指向superblock对象的s_root根目录项。因此,通过/mnt/alan地址可以检索VFSMOUNT Hash Table得到被mount的vfsmount对象,进而得到mnt_root根目录项。
遍历模式
Path walking目前有两种模式:ref-walk和rcu-walk:
- ref-walk is the traditional[*] way of performing dcache lookups using d_lock to serialise concurrent modifications to the dentry and take a reference count on it. ref-walk is simple and obvious, and may sleep, take locks, etc while path walking is operating on each dentry.
也就是说,ref-walk通过引用计数和锁来保证遍历过程中dentry的稳定性。而且可能会进行比较耗时的操作。而rcu-walk则尝试在不在锁的情况下完成walk动作。怎么不加锁?这是由rcu机制来保证的,具体可以参考rcu的实现。
在路径查找的过程中,会尝试先用rcu-walk来查找,如果无法成功(返回特定的错误码),那么内核会再尝试老老实实地用ref-walk。在ref-walk的过程中,内核也会先尝试在dcache里查找,如果找不到,才会考虑从硬盘中读取数据,可见内核总是想办法利用缓存来把性能优化到极致。
什么时候rcu-walk会切换到ref-walk呢?例如:
- 在遍历的过程中发现dentry或者vfsmount有变化(某些情况下会重试,某些情况下会切换)
- 发现数据不在cache中(可能要调用具体文件系统的接口去硬盘中读数据,所以会耗时)
关于RCU这种pathname lockup方式,可以参考这里。简单地说,就是RCU+计数,在开始遍历之前,将vfsmount,dentry的当前状态保存下来(一个计数),然后在遍历后,检查一下这个状态(计数)是否还跟之前的一样,如果一样,则认为状态是稳定的,遍历是有效的,如果不一样,那么可能在遍历的过程中发生了一些变化,那么就要重试遍历,或者切换到ref-walk模式。
对于符号链接的处理见https://lwn.net/Articles/650786/,暂时不再深入。
另外,学习Path walking最好方式,不是直接看源代码,而是先看文档,尤其是随着Linux源代码中一起分发的源代码中的文档。
阅读open源代码的过程,给我最大的启示,并不是具体如何来遍历路径,而是一种思维模式,一种把无锁、缓存运用到极限的思维模式。对于以后写其它的程序,非常有用。
参考资料
《深入分析Linux内核源代码》
走马观花: Linux 系统调用 open 七日游(一)
http://www.linuxjournal.com/article/7124?page=0,0
Pathname lookup in Linux:这篇文章描述了路径查找的过程,会让你更加理解路径遍历的过程。
RCU-walk: faster pathname lookup in Linux
A walk among the symlinks