anaconda 怎么安装xlrd_Win10下安装通过anaconda安装Scrapy问题汇总
C:\Users\aitub>pip list
Package Version
---------------------------------- -------------------
alabaster 0.7.12
anaconda-client 1.7.2
anaconda-navigator 1.9.6
anaconda-project 0.8.3
argh 0.26.2
argon2-cffi 20.1.0
asn1crypto 1.4.0
astroid 2.4.2
astropy 4.0.1.post1
async-generator 1.10
atomicwrites 1.4.0
attrs 20.2.0
Automat 20.2.0
autopep8 1.5.4
Babel 2.8.0
backcall 0.2.0
backports.shutil-get-terminal-size 1.0.0
baostock 0.8.8
bcrypt 3.2.0
beautifulsoup4 4.9.3
bitarray 1.5.3
bkcharts 0.2
bleach 3.2.1
bokeh 2.2.1
boto 2.49.0
Bottleneck 1.3.2
brotlipy 0.7.0
certifi 2020.6.20
cffi 1.14.3
chardet 3.0.4
click 7.1.2
cloudpickle 1.6.0
clyent 1.2.2
colorama 0.4.3
comtypes 1.1.7
conda 4.8.5
conda-build 3.17.6
conda-package-handling 1.7.0
conda-verify 3.1.1
constantly 15.1.0
contextlib2 0.6.0.post1
cryptography 3.1.1
cssselect 1.1.0
cycler 0.10.0
Cython 0.29.21
cytoolz 0.11.0
dask 2.30.0
decorator 4.4.2
defusedxml 0.6.0
diff-match-patch 20200713
distributed 2.30.0
docutils 0.16
entrypoints 0.3
et-xmlfile 1.0.1
fastcache 1.1.0
filelock 3.0.12
flake8 3.8.4
Flask 1.1.2
fsspec 0.8.0
future 0.18.2
gevent 20.9.0
glob2 0.7
gmpy2 2.0.8
greenlet 0.4.17
h5py 2.10.0
HeapDict 1.0.1
html5lib 1.1
hyperlink 20.0.1
idna 2.10
imageio 2.9.0
imagesize 1.2.0
importlib-metadata 2.0.0
incremental 17.5.0
iniconfig 0.0.0
intervaltree 3.1.0
ipykernel 5.3.4
ipython 7.18.1
ipython-genutils 0.2.0
ipywidgets 7.5.1
isort 5.6.1
itemadapter 0.1.1
itsdangerous 1.1.0
jdcal 1.4.1
jedi 0.17.1
Jinja2 2.11.2
joblib 0.17.0
json5 0.9.5
jsonschema 3.2.0
jupyter 1.0.0
jupyter-client 6.1.7
jupyter-console 6.2.0
jupyter-core 4.6.3
jupyterlab 2.2.6
jupyterlab-pygments 0.1.2
jupyterlab-server 1.2.0
keyring 21.4.0
kiwisolver 1.2.0
lazy-object-proxy 1.4.3
libarchive-c 2.9
llvmlite 0.34.0
locket 0.2.0
lxml 4.5.2
MarkupSafe 1.1.1
matplotlib 3.3.1
mccabe 0.6.1
menuinst 1.4.16
mistune 0.8.4
mkl-fft 1.2.0
mkl-random 1.1.1
mkl-service 2.3.0
mock 4.0.2
more-itertools 8.5.0
mpmath 1.1.0
msgpack 1.0.0
multipledispatch 0.6.0
navigator-updater 0.2.1
nbclient 0.5.0
nbconvert 6.0.7
nbformat 5.0.7
nest-asyncio 1.4.1
networkx 2.5
nltk 3.5
nose 1.3.7
notebook 6.1.4
numba 0.51.2
numexpr 2.7.1
numpy 1.19.1
numpydoc 1.1.0
olefile 0.46
openpyxl 3.0.5
packaging 20.4
pandas 1.1.3
pandocfilters 1.4.2
paramiko 2.7.2
parsel 1.5.2
parso 0.7.0
partd 1.1.0
path 15.0.0
pathlib2 2.3.5
pathtools 0.1.2
patsy 0.5.1
pep8 1.7.1
pexpect 4.8.0
pickleshare 0.7.5
Pillow 7.2.0
pip 20.2.3
pkginfo 1.5.0.1
pluggy 0.13.1
ply 3.11
prometheus-client 0.8.0
prompt-toolkit 3.0.7
psutil 5.7.2
py 1.9.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycodestyle 2.6.0
pycosat 0.6.3
pycparser 2.20
pycrypto 2.6.1
pycurl 7.43.0.6
PyDispatcher 2.0.5
pydocstyle 5.1.1
pyflakes 2.2.0
Pygments 2.7.1
PyHamcrest 2.0.2
pylint 2.6.0
PyMySQL 0.9.3
PyNaCl 1.4.0
pyodbc 4.0.0-unsupported
pyOpenSSL 19.1.0
pyparsing 2.4.7
pypiwin32 223
pyreadline 2.1
pyrsistent 0.17.3
PySocks 1.7.1
pytest 0.0.0
pytest-runner 5.2
python-dateutil 2.8.1
python-jsonrpc-server 0.4.0
python-language-server 0.35.1
pytz 2020.1
PyWavelets 1.1.1
pywin32 227
pywin32-ctypes 0.2.0
pywinpty 0.5.7
PyYAML 5.3.1
pyzmq 19.0.2
QDarkStyle 2.8.1
QtAwesome 1.0.1
qtconsole 4.7.7
QtPy 1.9.0
queuelib 1.5.0
regex 2020.9.27
requests 2.24.0
rope 0.18.0
Rtree 0.9.4
ruamel-yaml 0.15.87
scikit-image 0.16.2
scikit-learn 0.23.2
scipy 1.5.2
seaborn 0.11.0
Send2Trash 1.5.0
service-identity 18.1.0
setuptools 50.3.0.post20201006
simplegeneric 0.8.1
singledispatch 3.4.0.3
six 1.15.0
snowballstemmer 2.0.0
sortedcollections 1.2.1
sortedcontainers 2.2.2
soupsieve 2.0.1
Sphinx 3.2.1
sphinxcontrib-applehelp 1.0.2
sphinxcontrib-devhelp 1.0.2
sphinxcontrib-htmlhelp 1.0.3
sphinxcontrib-jsmath 1.0.1
sphinxcontrib-qthelp 1.0.3
sphinxcontrib-serializinghtml 1.1.4
sphinxcontrib-websupport 1.2.4
spyder 4.1.5
spyder-kernels 1.9.4
SQLAlchemy 1.3.19
statsmodels 0.12.0
sympy 1.6.2
tables 3.5.2
tblib 1.7.0
terminado 0.9.1
testpath 0.4.4
threadpoolctl 2.1.0
toml 0.10.1
toolz 0.11.1
tornado 6.0.4
tqdm 4.50.2
traitlets 5.0.4
typed-ast 1.4.1
typing-extensions 3.7.4.3
ujson 4.0.0
unicodecsv 0.14.1
urllib3 1.25.10
w3lib 1.21.0
watchdog 0.10.3
wcwidth 0.2.5
webencodings 0.5.1
Werkzeug 1.0.1
wheel 0.35.1
widgetsnbextension 3.5.1
win-inet-pton 1.1.0
win-unicode-console 0.5
wincertstore 0.2
wrapt 1.11.2
xlrd 1.2.0
XlsxWriter 1.3.6
xlwings 0.20.7
xlwt 1.3.0
yapf 0.30.0
zict 2.0.0
zipp 3.3.0
zope.event 4.4
zope.interface 5.1.2
2)安装Scrapy
可以看到Scrapy并不在其中,继续用Conda命令或Pip命令安装Scrapy
C:\Users\aitub>conda install scrapy
Collecting package metadata: failed
CondaHTTPError: HTTP 000 CONNECTION FAILED for url
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
ConnectionError(ReadTimeoutError("HTTPSConnectionPool(host='mirrors.tuna.tsinghua.edu.cn', port=443): Read timed out."))
可以看到超时错误,但是源已经换成了清华源了,为什么呢?可能是使用国内源时的问题,打开C:\Users\aitub\.condarc文件,其内容如下:
ssl_verify: true
show_channel_urls: true
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/
- defaults
删除掉默认路径,并且使用http协议进行连接,即将该文件内容修改为:
ssl_verify: true
show_channel_urls: true
channels:
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/
- http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/
之后再次运行conda install scrapy,输入完成执行该命令后,会进行环境检查.稍等一会:
 接着环境监测完成,需要确认继续,输入y
接着环境监测完成,需要确认继续,输入y
输入y并回车后,自动下载所需文件,等其自动安装。
 最后,全部组件安装完成后,会有done的标记:
最后,全部组件安装完成后,会有done的标记:
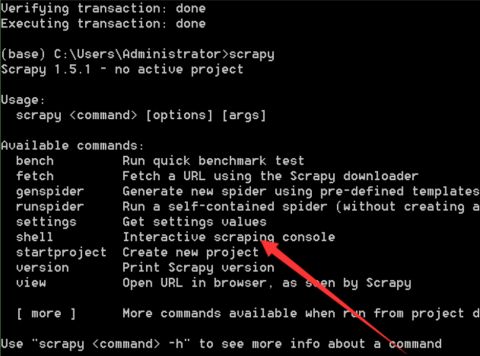
三、运行Scrapy
在命令窗口中运行scrapy:
C:\Users\aitub>scrapy
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\Scripts\scrapy-script.py", line 6, in
from scrapy.cmdline import execute
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\__init__.py", line 12, in
from scrapy.spiders import Spider
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\spiders\__init__.py", line 10, in
from scrapy.http import Request
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\http\__init__.py", line 11, in
from scrapy.http.request.form import FormRequest
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\http\request\form.py", line 16, in
from scrapy.utils.response import get_base_url
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\utils\response.py", line 10, in
from twisted.web import http
File "C:\ProgramData\Anaconda3\lib\site-packages\twisted\web\http.py", line 102, in
from twisted.internet import interfaces, protocol, address
File "C:\ProgramData\Anaconda3\lib\site-packages\twisted\internet\address.py", line 101, in
@attr.s(hash=False, repr=False, eq=False)
TypeError: attrs() got an unexpected keyword argument 'eq'
报错的原因是attrs的版本不够,解决方法:
C:\Users\aitub>pip install attrs==19.2.0 -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
再次运行scrapy:
C:\Users\aitub> scrapy
Scrapy 2.3.0 - no active project
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
四、创建scrapy工程
在命令窗口中,跳转到工程目录,并运行scrapy startproject test:
(base) PS C:\Users\aitub> d:
(base) PS D:\> cd projects
(base) PS D:\projects> scrapy startproject test
New Scrapy project 'test', using template directory 'C:\ProgramData\Anaconda3\lib\site-packages\scrapy\templates\project', created in:
D:\projects\test
You can start your first spider with:
cd scrapyTest
scrapy genspider example example.com
创建完毕,会生成以下目录结构:
test/
scrapy.cfg #配置文件
test/ # Python工程模块,开发的代码放在其中
__init__.py
items.py # 工程项目定义文件
middlewares.py # 项目中间件文件
pipelines.py # 项目管道文件
settings.py # 项目设置文件
spiders/ # 放置蜘蛛集的文件夹
__init__.py
之后就可以在工程目录的spiders文件夹下创建蜘蛛文件了,此处先创建一个名为quotes_spider.py的空文件,并在其中拷贝以下代码:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
存盘后即可在命令行中运行该蜘蛛:
(base) PS D:\projects> cd test
(base) PS D:\projects\test> scrapy crawl quotes
2020-10-15 19:50:57 [scrapy.utils.log] INFO: Scrapy 2.3.0 started (bot: test)
2020-10-15 19:50:57 [scrapy.utils.log] INFO: Versions: lxml 4.5.2.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Python 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1h 22 Sep 2020), cryptography 3.1.1, Platform Windows-10-10.0.14393-SP0
2020-10-15 19:50:57 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-10-15 19:50:57 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'test',
'NEWSPIDER_MODULE': 'test.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['test.spiders']}
2020-10-15 19:50:57 [scrapy.extensions.telnet] INFO: Telnet Password: 8b9e0010831287d7
2020-10-15 19:50:58 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
Unhandled error in Deferred:
2020-10-15 19:50:58 [twisted] CRITICAL: Unhandled error in Deferred:
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 192, in crawl
return self._crawl(crawler, *args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 196, in _crawl
d = crawler.crawl(*args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\twisted\internet\defer.py", line 1613, in unwindGenerator
return _cancellableInlineCallbacks(gen)
File "C:\ProgramData\Anaconda3\lib\site-packages\twisted\internet\defer.py", line 1529, in _cancellableInlineCallbacks _inlineCallbacks(None, g, status)
--- ---
File "C:\ProgramData\Anaconda3\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 87, in crawl
self.engine = self._create_engine()
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 101, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\core\engine.py", line 69, in __init__
self.downloader = downloader_cls(crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\core\downloader\__init__.py", line 83, in __init__
self.middleware = DownloaderMiddlewareManager.from_crawler(crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\middleware.py", line 53, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\middleware.py", line 35, in from_settings
mw = create_instance(mwcls, settings, crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\utils\misc.py", line 156, in create_instance
instance = objcls.from_crawler(crawler, *args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\downloadermiddlewares\robotstxt.py", line 36, in from_crawler
return cls(crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\downloadermiddlewares\robotstxt.py", line 32, in __init__
self._parserimpl.from_crawler(self.crawler, b'')
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\robotstxt.py", line 124, in from_crawler
o = cls(robotstxt_body, spider)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\robotstxt.py", line 116, in __init__
from protego import Protego
builtins.ModuleNotFoundError: No module named 'protego'
2020-10-15 19:50:58 [twisted] CRITICAL:
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 87, in crawl
self.engine = self._create_engine()
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\crawler.py", line 101, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\core\engine.py", line 69, in __init__
self.downloader = downloader_cls(crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\core\downloader\__init__.py", line 83, in __init__
self.middleware = DownloaderMiddlewareManager.from_crawler(crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\middleware.py", line 53, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\middleware.py", line 35, in from_settings
mw = create_instance(mwcls, settings, crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\utils\misc.py", line 156, in create_instance
instance = objcls.from_crawler(crawler, *args, **kwargs)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\downloadermiddlewares\robotstxt.py", line 36, in from_crawler
return cls(crawler)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\downloadermiddlewares\robotstxt.py", line 32, in __init__
self._parserimpl.from_crawler(self.crawler, b'')
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\robotstxt.py", line 124, in from_crawler
o = cls(robotstxt_body, spider)
File "C:\ProgramData\Anaconda3\lib\site-packages\scrapy\robotstxt.py", line 116, in __init__
from protego import Protego
ModuleNotFoundError: No module named 'protego'
这是因为Anaconda中并没有安装protego库,protego是一个纯python robots.txt解析器,支持现代约定。要安装protego,只需使用conda install protego命令即可。(上述过程同scrapy的安装,不再赘述)
安装完毕后再次运行蜘蛛:
(base) PS D:\projects\test> scrapy crawl quotes
2020-10-15 19:57:18 [scrapy.utils.log] INFO: Scrapy 2.3.0 started (bot: test)
2020-10-15 19:57:18 [scrapy.utils.log] INFO: Versions: lxml 4.5.2.0, libxml2 2.9.10, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Python 3.7.1 (default, Dec 10 2018, 22:54:23) [MSC v.1915 64 bit (AMD64)], pyOpenSSL 19.1.0 (OpenSSL 1.1.1h 22 Sep 2020), cryptography 3.1.1, Platform Windows-10-10.0.14393-SP0
2020-10-15 19:57:18 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2020-10-15 19:57:18 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'test',
'NEWSPIDER_MODULE': 'test.spiders',
'ROBOTSTXT_OBEY': True,
'SPIDER_MODULES': ['test.spiders']}
2020-10-15 19:57:18 [scrapy.extensions.telnet] INFO: Telnet Password: 50224b740c6bd55d
2020-10-15 19:57:18 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2020-10-15 19:57:18 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2020-10-15 19:57:18 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2020-10-15 19:57:18 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2020-10-15 19:57:18 [scrapy.core.engine] INFO: Spider opened
2020-10-15 19:57:18 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-10-15 19:57:18 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-10-15 19:57:19 [scrapy.core.engine] DEBUG: Crawled (404) (referer: None)
2020-10-15 19:57:19 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2020-10-15 19:57:19 [quotes] DEBUG: Saved file quotes-1.html
2020-10-15 19:57:20 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2020-10-15 19:57:20 [quotes] DEBUG: Saved file quotes-2.html
2020-10-15 19:57:20 [scrapy.core.engine] INFO: Closing spider (finished)
2020-10-15 19:57:20 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 693,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 5639,
'downloader/response_count': 3,
'downloader/response_status_count/200': 2,
'downloader/response_status_count/404': 1,
'elapsed_time_seconds': 1.673699,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2020, 10, 15, 11, 57, 20, 197258),
'log_count/DEBUG': 5,
'log_count/INFO': 10,
'response_received_count': 3,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/404': 1,
'scheduler/dequeued': 2,
'scheduler/dequeued/memory': 2,
'scheduler/enqueued': 2,
'scheduler/enqueued/memory': 2,
'start_time': datetime.datetime(2020, 10, 15, 11, 57, 18, 523559)}
2020-10-15 19:57:20 [scrapy.core.engine] INFO: Spider closed (finished)
到工程目录test下可以看到保存到本地的两个quotes-1.html、quotes-2.html文件,成功!