TensorFlow 2——VGG卷积神经网络
目录
- 引言
- VGG 网络结构
- VGG 模型构建
- Fashion-MNIST 分类
引言
选择经典卷积神经网络结构 VGG 作为示例,完成 Fashion-MNIST 时尚物品分类任务。此外还将了解如何使用预训练模型进行迁移学习。
VGG 网络结构
VGG 采用了卷积神经网络结构,分为分为如下图所示的 VGG16 和 VGG19。
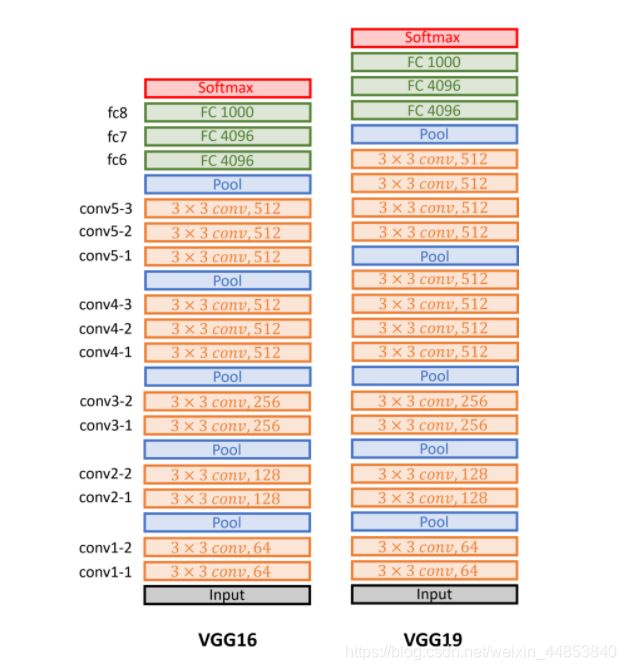
二者在结构上区别不大,只是 VGG19 更深一些,效果略好于 VGG16。为了减少训练时间,本次实验尝试构建 VGG16 网络。结构图从下往上看,VGG 总共包含 12 个卷积层,5 个池化层,以及 3 个全连接层。VGG 的特点在于卷积层和池化层均采用相同的卷积核( 3×3 )和池化核参数( 2×2 )。同时,网络由多个卷积池化单元块组成,具体来说就是若干个卷积层加上一个池化层组合。
VGG 模型构建
首先,使用 Keras 顺序模型来构建 VGG16 网络。之前的顺序模型使用过程中,我们是先使用 tf.keras.Sequential()定义一个顺序模型空结构,然后使用 add 操作向其中添加层。对于复杂的网络结构,你也可以取消 add 操作,直接将网络层以列表的形式罗列在顺序模型中即可。
import tensorflow as tf
model_vgg = tf.keras.Sequential([
tf.keras.layers.Conv2D(64, (3, 3), input_shape=(224, 224, 3), padding='same', activation='relu'),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same'),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same',),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same',),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same',),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(512, (3, 3), activation='relu', padding='same',),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dense(1000, activation='softmax')
])
model_vgg.summary()
通过model.summary() 输出模型详情:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
conv2d_3 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 56, 56, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv2d_5 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
conv2d_6 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 28, 28, 256) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
conv2d_8 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
conv2d_9 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 14, 14, 512) 0
_________________________________________________________________
conv2d_10 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_11 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
conv2d_12 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 4096) 102764544
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_2 (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
Fashion-MNIST 分类
VGG 本身是为 ImageNet 分类任务设计,ImageNet 是一个包含数万张图片的大型基准数据集,总共有 1000 个目标输出。不过由于 ImageNet 数据集体积太大,我们选择一个较小的 Fashion-MNIST 时尚物品分类数据集,包含 70,000 张图片,其中训练集为 60,000 张 28x28 像素灰度图像,测试集为 10,000 同规格图像,总共 10 类时尚物品标签。
下面,我们使用 TensorFlow 直接加载该数据集。读取数据之后,由于是灰度图像,可以直接除以 255 进行归一化(归一化是一个很常用的处理步骤,能够在一定程度上提高梯度下降法求解最优解的速度,也能够改善最终的分类准确度).
import tensorflow as tf
import numpy as np
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
# 对特征进行归一化处理
X_train = X_train / 255
X_test = X_test / 255
# 对标签进行独热编码
y_train = np.eye(10)[y_train]
y_test = np.eye(10)[y_test]
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# 输出如下
# ((60000, 28, 28), (10000, 28, 28), (60000, 10), (10000, 10))
可以看到,训练集的形状为 28×28 ,这也是 Fashion-MNIST 默认图像尺寸。我们可视化训练集第一个样本查看:
from matplotlib import pyplot as plt
%matplotlib inline
plt.imshow(X_train[0], cmap=plt.cm.gray)
但是VGG16 一开始是为 ImageNet 任务设计,输入形状 input_shape=(224, 224, 3)(其中,224 代表图片尺寸,3 表示彩色图片的 RGB 通道)。而 Fashion-MNIST 图片的默认尺寸是 28,且由于是灰度图像只有 1 个通道。
此外,VGG 默认是对 ImageNet 数据集完成 1000 类图像的分类预测,而 Fashion-MNIST 却只有 10 个类别。所以,我们需要修改网络结构如下:
model_mnist = tf.keras.Sequential([
tf.keras.layers.Conv2D(64, (3, 3), input_shape=(28, 28, 1), padding='same', activation='relu'),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu', padding='same'),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same'),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu', padding='same',),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same',),
tf.keras.layers.Conv2D(256, (3, 3), activation='relu', padding='same',),
tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dense(4096, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model_mnist.summary()
修改时去除了网络中最后两个卷积池化单元。首先,因为输入尺寸变小,原完整网络已不再适应,会出现尺寸报错。此外,原 VGG 网络太深,训练时需要耗费数小时,所以降低了网络复杂度。接下来,我们编译模型并开始训练过程。由于指定输出尺寸为 (28, 28, 1),所以还需要通过 reshape 操作向原始数据中补充一个通道维度。
# 对图像形状进行处理,增加一个通道维度
X_train = tf.reshape(X_train, [-1, 28, 28, 1])
X_test = tf.reshape(X_test, [-1, 28, 28, 1])
X_train.shape, X_test.shape, y_train.shape, y_test.shape
# 编译模型
model_mnist.compile(optimizer=tf.optimizers.Adam(),
loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
history = model_mnist.fit(X_train, y_train, epochs=3, batch_size=32,
validation_data=(X_test, y_test))
随着训练迭代,模型的分类准确度会稳步提升。
上方采用的策略是数据基本不变,修改网络结构。实际上,也可以完整沿用 VGG 网络结构,修改数据尺寸以配合网络输入。为了能够输入 VGG16,需要对图像进一步处理。首先,需要拓展尺寸到 224,此外复制灰度通道让其变成 RGB 图像。TensorFlow 提供了完善的图像预处理 API,可以在 tf.image 模块下找到。
# 对图像进行 Resize 操作,变为 224 尺寸
X_train_demo = tf.image.resize(X_train[:100], (224, 224))
X_test_demo = tf.image.resize(X_test[:100], (224, 224))
# 将单通道灰度图像转换为 3 通道 RGB 图像
X_train_demo = tf.image.grayscale_to_rgb(X_train_demo)
X_test_demo = tf.image.grayscale_to_rgb(X_test_demo)
X_train_demo.shape, X_test_demo.shape
# 输出结果:
# (TensorShape([100, 224, 224, 3]), TensorShape([100, 224, 224, 3]))
由于 tf.image.resize 操作会消耗大量内存,为了避免环境内存报错,上方只示例处理了 100 条数据。此时,输入样本的尺寸就满足 VGG 网络要求了,变成了 (224, 224, 3)。