网易数帆云原生故障诊断系统实践与思考
Kubernetes 是一个生产级的容器编排引擎,但是 Kubernetes 仍然存在系统复杂、故障诊断成本高等问题。网易数帆旗下轻舟云原生团队在近几年的稳定性保障工作中累计了不少生产实践的经验,我们沉淀并落地了轻舟云原生故障诊断系统来帮助产品评估集群的稳定性并为用户提供优化建议。本文分享了我们在业务落地不同时期稳定性保障的实践,以及我们在集群稳定性保障层面产品化的思考,希望能够给读者朋友带来一些启发。
容器化落地早期(2018 下半年至 2019 上半年)
在 2018 年下半年,网易内部的部分业务开始逐步对应用进行容器化改造并在生产中落地。这个时期业务的使用还远谈不上云原生,很多用户是把容器当作虚拟机在用。我们团队在这个时期的主要职责包括以下几个方面:
-
保障内部 Kubernetes 集群的稳定性。
-
解决业务用户在容器化落地过程中遇到的一系列问题。
-
解决轻舟产品化初期的一系列问题。
早期面临的问题
这个时期我们面临的问题主要集中在两个方面:Kubernetes、Docker、操作系统层面的问题以及用户使用方式不合理导致的问题。
Kubernetes、Docker、操作系统层面的问题是容器化落地早期难以避免的。我们当时内部主要使用的 Kubernetes 版本是 1.11,Docker 版本是 18.06,现在社区中仍然能找到很多那个时期 Kubernetes 和 Docker 相关问题的 Issue。我们内部当时维护的操作系统是 Debian 9 和 Debian 10,而一些较强势的业务对操作系统有硬性要求,集群中的节点使用 CentOS 7 的操作系统。CentOS 7 使用的 3.10 版本内核的 Cgroups 和 Systemd 实现在容器场景下埋了非常多的坑。针对这方面的问题,我们通过内核调参以及为 Kubernetes 和 Docker 打补丁以维护内部版本的方式来避免问题。以 Kernel Memory Accounting 泄漏这个经典问题为例,我们关闭了 Kubelet 和 Docker 中相关的逻辑,并且规定 CentOS 7.7 为最低支持的版本且在启动参数中固化 cgroup.memory=nokmem 选项来规避改问题。
用户使用方式的不合理也导致了非常多问题。早期用户对 Kubernetes 管理工作负载的设计思想不是很了解,加上业务部门的成本压力,很多用户为了应用快速容器化将虚拟机的用法直接搬到了容器上来。有些不规范的实践通过 Kubernetes 提供的机制可以较好的纠正,有些严重的情况则触发了 Docker 和内核在某些特殊场景下的 Bug 影响了集群的稳定性。针对这方面的问题,我们通过为用户分析故障并给出解决方案的方式来帮助用户容器化平滑落地。例如使用探针而不是传统方法对应用进行健康检查,避免大量执行 Exec 进入容器内执行命令而引发容器终止时进程回收的问题。
早期的思考
在 2018 下半年至 2019 上半年这一时期,网易不少业务完成了生产环境大规模容器化落地并且迅速享受到了云原生技术在资源管理和成本控制层面的红利。我们团队在这一过程中积累了许多宝贵的经验,同时欠下了一些技术债:
-
忽视云原生技术布道的重要性:我们花费了大量时间帮助用户解决不当实践引起的各种问题,这些问题很多是用户可以通过看文档独立解决。但是用户对这些新技术缺少学习动力,并且新接触 Kubernetes 的同事在增长,问题似乎永远解决不完。
-
缺少团队职责的细分:落地初期许多的问题都是容器化后产生的,而大部分人对云原生技术是比较陌生的,所以很多问题最终都需要我们团队来解决。
-
不云原生的云原生落地:迫于业务成本压力,业务需要快速完成容器化改造,但是业务用户对该技术缺乏经验。在这样的背景下,我们开发了一些中间层组件帮助用户快速落地,也做了一些不是很云原生的妥协。
-
没有对集群标准化交付的规范:部分用户使用的是 CentOS 7 操作系统,我们在认识到使用该操作系统运行 Docker 的风险后仍然没有去引导用户在操作系统上的选择,并且在安装操作系统以及内核参数设置这些问题上也缺少把控。
这些技术债无法用对或错去评判,在当时的客观背景下看来是难以避免的,但是这也为我们之后的工作提供了很好的思路。
业务云原生化时期(2019 上半年至 2020 下半年)
由于早期业务在大规模容器化上尝到了甜头,许多业务开始逐步使用 Kubernetes 来编排应用,这一段时间我们管理的集群数量从原来的十多个变成了近百个。而随着 Kubernetes 的进一步推广,公司内部越来越多的人开始学习云原生技术,也有越来越多的 Operator 被部署到集群中。我们团队的职责也变得愈加多样和复杂:
-
缓解较大规模集群中的稳定性风险。
-
规范轻舟不同产品团队在 Kubernetes 中各个扩展点的使用。
-
集群版本管理和维护的问题。
-
解决业务用户在云原生化过程中遇到的一系列问题。
工作中常见的问题
部分集群连接的 APIServer 客户端数量超过了 4000 个,其中不乏一些用户用脚本对 Pod 资源进行全量 LIST 来获取数据。这些集群的 APIServer 消耗接近 100G 的内存以及 50 核的 CPU 算力,并且 APIServer 所在节点的网卡流量达到了 15G。针对这方面的问题,我们通过分析客户端的的业务类型找出了使用不合理的客户端并进行优化。例如某个 DaemonSet 运行的组件一开始使用了 kube-builder 进行开发且监听了全量的 Node 资源,但是实际上只需要监听本节点 Node 的资源变化,我们使用 client-go 库重写了客户端并且只关注本节点 Node 的资源变化来规避容量问题,并且向轻舟各团队说明了 APIServer 客户端实现上需要注意的事项,借此为契机来推进整体产品的稳定性提升。
轻舟产品中的一些功能实现了 Admission Webhook 进行扩展,但是轻舟当时很多已交付集群的商业化版本中并不包含 Webhook Server 的超时机制,某些 Webhook Server 会在特定场景下卡住无法返回,严重影响的集群稳定性。我们将上游版本中 Webhook 的特性 Cherry Pick 到商业化版本中,并且推动了 Admission Control 这个扩展点使用的规范化,去除了不少产品中不合理的设计和滥用。
最开始我们管理的 Kubernetes 集群并没有很多,所以管理成本是可控的。随着用户的增长,我们需要维护的 Kubernetes 集群越来越多,版本范围也越来越大,包括 1.11 到 1.17 之间的多个版本。早期我们虽然建议用户版本升级时需要进行节点下线再上线的流程,但是刚刚容器化的用户当时难以容忍应用的重建,我们承诺了节点热升级的方案,这些方案也大大增加了我们的管理成本。针对这方面的问题,我们学习了 Red Hat 维护商业化操作系统的策略,通过确定内部维护的 1.17 版本为商业化 Kubernetes 版本,我们将内部版本维护的工作控制在这几个方面:合入上游版本的 Bug 修复以及用户需要的特性对某个商业版本进行维护;标准化某个商业版本到下一个商业版本的升级方案;明确轻舟各组件与 Kubernetes 版本的兼容性矩阵来降低软件管理成本;开发并上线元集群 Operator 方案来将集群管理的工作自动化。这样我们将集群版本管理以及运维的责任都明确到相关团队以及个人,降低了 Kubernetes 集群的管理成本和潜在风险。
随着使用 Kubernetes 编排应用的用户越来越多,我们需要帮助用户解决的问题类型也越来越多,其中包含帮助用户在云原生场景下更好诊断业务应用的问题。例如用户在应用容器化之前常用的 Java 应用诊断方式难以在云原生场景下进行使用,我们开发并在产品上集成了 JVM 内存诊断管理的功能,帮助用户方便的对生产环境的 Java 应用进行诊断。
发展期的思考
在 2019 上半年至 2020 下半年这一时期,我们管理的集群数量增长到了近百个。这个时期我们的工作主要集中在解决集群运维管理的问题以及帮助用户业务更好的实现云原生化。在帮助用户的过程中我们发现了越来越多需要从机制上解决的问题:
-
因为 Kubernetes 与业务应用之间的关系较紧密,我们需要明确集群稳定性保障以及应用稳定性保障的边界以及有效的评估模型,这种责任边界的不明确带来了交付成本上的增长以及不确定性。
-
随着云原生技术的发展,用户虽然能够渐渐感受到其在标准化层面带来的优势,但是我们在帮助商业用户解决实际问题上仍然有不少工作需要进行。
-
稳定性保障工作在网易内部很早就已经积累了一定的基础,并且这些工作是由多个团队完成的。借助云原生的契机,让多个团队形成合作并将以往的经验在商业化产品中进行集成是一个新的挑战。
云原生商业化时期(2020 下半年至今)
2020 下半年开始,网易大部分互联网业务都开始在生产中使用 Kubernetes 来编排应用,我们工作的焦点开始转变为将内部沉淀的能力通过轻舟混合云产品对外进行商业化输出。
商业化中需要解决的问题
商业化场景下需要考虑的问题比在公司内管理多个集群更加复杂多样。在集群稳定性保障层面,有些问题通过报警消息就可以准确的识别,但是商业化场景下很多问题的诊断对基础设施的自动化水平提出了比较大的挑战:
-
在云原生场景下,用户需要行之有效的手段对业务应用进行排障。例如用户需要在某个报警触发时分析堆的使用状况而不是等到 OOM 发生后才能进行排查。
-
某些问题的诊断需要采集一些信息,而这些信息具有一定时效性并且采集成本较高,将这些诊断分析流程自动化可以大大提高产品的售后能力。
-
虽然 APM 和监控能够解决一部分可观测性问题,但是经验告诉我们很多用户业务问题的根本原因是在系统这一层面发现的,可能是基础设施层抖动或者系统设置不合理导致的。我们需要结合用户或轻舟 APM 中的数据与系统层面的数据来打造可落地的故障诊断体系。
如何提高 Kubernetes 集群稳定性保障体系的自动化能力,并借助云原生标准化将多个技术领域内已有的保障能力进行集成是我们团队重点思考的问题。
网易轻舟云原生故障诊断系统的设计
为了解决上述问题,我们团队设计并实现了轻舟云原生故障诊断系统来解决故障现场保留不易、售后技术支持成本高、产品稳定性评估难等问题。发生故障时,一次售后技术支持流程大致如下:
-
故障发生后用户进行简单的排查,发现难以定位问题。
-
用户联系售后技术支持同事上报故障。
-
技术支持同事通过研发同事提供的 FAQ 文档指导用户获取信息。
-
技术支持同事根据 FAQ 文档对问题进行解答。
-
问题较复杂,技术支持同事拉入研发同事进行介入。
-
研发同事向技术支持同事和用户沟通获取有效的上下文信息。
-
研发同事获取用户环境权限并进行故障诊断。(某些用户环境有比较严格的安全限制,研发同事需要去用户现场进行故障诊断。)
-
研发同事发现导致故障的原因,输出排查结论以及解决方案。(有时问题复杂度较高或者故障现场没有保留,研发同事难以定位问题。)
-
技术支持同事负责与用户沟通并给出解决方案。(故障难以定位的情况下需要说服用户。)
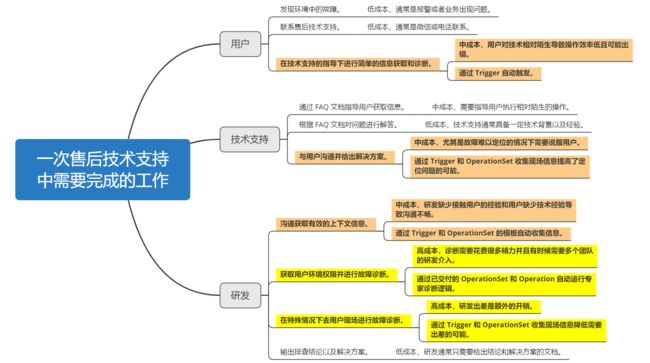
在这样的一次流程中涉及到用户、技术支持、研发三个角色,每个角色完成的工作以及工作成本大致如下:
-
用户
-
发现环境中的故障。(低成本,通常是报警或者业务出现问题。)
-
联系售后技术支持。(低成本,通常是微信或电话联系。)
-
在技术支持的指导下进行简单的信息获取和诊断。(中成本,用户对技术相对陌生导致操作效率低且可能出错。)
-
-
技术支持
-
通过 FAQ 文档指导用户获取信息。(中成本,需要指导用户执行相对陌生的操作。)
-
根据 FAQ 文档对问题进行解答。(低成本,技术支持通常具备一定技术背景以及经验。)
-
与用户沟通并给出解决方案。(中成本,尤其是故障难以定位的情况下需要说服用户。)
-
-
研发
-
沟通获取有效的上下文信息。(中成本,研发缺少接触用户的经验和用户缺少技术经验导致沟通不畅。)
-
获取用户环境权限并进行故障诊断。(高成本,诊断需要花费很多精力并且有时候需要多个团队的研发介入。)
-
在特殊情况下去用户现场进行故障诊断。(高成本,研发出差是额外的开销。)
-
输出排查结论以及解决方案。(低成本,研发通常只需要给出结论和解决方案的文档。)
-
这样的一次流程中主要的成本都是由技术支持和研发承担的。作为服务提供方,如果我们能够在这个服务形态下实现一个系统来提高整个流程的自动化程度并且降低上述中高成本工作所带来的开销,那么对轻舟商业化输出的能力无疑是一个巨大的提升。
设计与实现
通过定义 Operation、OperationSet、Trigger 和 Diagnosis 对象,我们对整个稳定性保障流程中不同角色需要处理的问题进行了抽象。整个系统由 Master 和 Agent 组成,并且从 APIServer、Prometheus、Elasticsearch 等组件获取可观测性指标数据以触发一次故障诊断,部署架构如下所示:
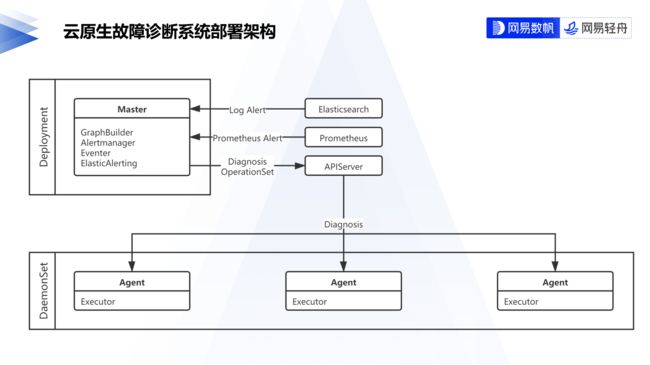
网易轻舟云原生故障诊断系统部署架构
Operation 对象
Operation 描述了一个诊断操作以及将其注册到故障诊断系统的方式。一个负责获取 Golang 性能剖析数据的诊断操作可以通过下述 Operation 进行注册:
apiVersion: diagnosis.netease.com/v1kind: Operationmetadata:annotations:description: This operation manages actions to profile go programs.maitainer: APM Teamname: go-profilerspec:processor: # 注册处理故障诊断请求的服务器,如果未定义服务器的 IP 和 Port 则为故障诊断系统 Agent 内置的处理器。path: /processor/goprofiler # 故障诊断系统 Agent 会请求该路径来触发故障诊断。scheme: http # 故障诊断系统 Agent 向该服务器发送 HTTP 请求。timeoutSeconds: 60 # 故障诊断系统 Agent 等待该服务器返回诊断结果的超时时间为 60 秒。
Operation 的后端是一个实现诊断操作逻辑 HTTP 服务器,不同诊断操作由不同团队各自维护。Operation 对象主要解决了以下问题:
-
标准化了诊断操作集成到产品的接口,Operation 只需要处理标准格式的 JSON 数据。
-
为不同团队故障诊断的工作划分了责任边界,各团队可以根据需要负责处理的问题场景实现专业的故障诊断逻辑。
-
SRE 或者技术支持在管理诊断操作时不需要理解其内部实现细节。
-
原先积累的基础设施层技术保障能力能够以较低的改造成本接入到 Kubernetes 环境中。
OperationSet 对象
OperationSet 定义了故障诊断的工作流,其中包含表示诊断过程状态机的有向无环图。一次收集 Dockerd 和 Containerd 信息的工作流可以通过下述 OperationSet 表示:
apiVersion: diagnosis.netease.com/v1kind: OperationSetmetadata:annotations:description: This operation set collects debugging information for dockerd and containerd.maitainer: Kubernetes Teamname: docker-debuggerspec:adjacencyList: # 表示诊断工作流的有向无环图。- id: 0 # 第一个顶点表示诊断的开始,不包含任何操作。to:- 1- id: 1 # 第二个顶点执行获取 Docker 元信息的操作。operation: docker-info-collectorto:- 2- id: 2 # 第三个顶点执行获取 dockerd goroutine 的操作。operation: dockerd-goroutine-collectorto:- 3- id: 3 # 第四个顶点执行获取 containerd goroutine 的操作。operation: containerd-goroutine-collectorto:- 4- id: 4 # 第五个顶点执行将节点置为不可调度的操作。operation: node-cordonstatus:paths: # 记录有向无环图中所有的诊断路径,故障诊断系统 Agent 会按顺序执行诊断路径。- - id: 1operation: docker-info-collector- id: 2operation: dockerd-goroutine-collector- id: 3operation: containerd-goroutine-collector- id: 4operation: node-cordonready: true # 控制器是否已根据 .spec.adjacencyList 字段生成最新的 .status.paths 字段。
Trigger 对象
Trigger 描述如何通过外部消息来源触发一次诊断。一次复杂的故障诊断通常是由报警触发的,而报警的来源可能是监控系统、APM 系统或者日志。利用 KubeletPlegDurationHigh 报警触发收集 Dockerd 和 Containerd 信息的工作流的 Trigger 如下所示:
apiVersion: diagnosis.netease.com/v1kind: Triggermetadata:annotations:description: This trigger collects debugging information for dockerd and containerd on alert KubeletPlegDurationHigh firing.maitainer: Kubernetes Teamname: kubelet-pleg-duration-highspec:operationSet: docker-debugger # 触发后运行 docker-debugger 中定义的工作流。sourceTemplate: # 用于创建诊断的来源模板。prometheusAlertTemplate: # 利用 Prometheus 报警来创建诊断。regexp: # 触发诊断的 Prometheus 报警正则表达式。alertName: KubeletPlegDurationHigh # 触发诊断的 Prometheus 报警为 KubeletPlegDurationHigh。nodeNameReferenceLabel: node # Prometheus 报警中 node 标签的值是运行诊断的节点名。
研发通过定义诊断流程的 OperationSet 和在问题出现时触发诊断的 Trigger 实现了多个中高成本工作的自动化,轻舟产品的整体售后能力得到了增强:
-
用户不需要在技术支持的指导下进行简单的信息获取和诊断。
-
研发不需要沟通获取有效的上下文信息。
-
大多数场景下研发可以避免获取用户环境权限并进行故障诊断等步骤。
Diagnosis 对象
Diagnosis 是用于管理某个诊断的 API 对象,其中包含了诊断工作流运行的状态。一个表示收集 Dockerd 和 Containerd 信息的 Diagnosis 如下所示:
apiVersion: diagnosis.netease.com/v1kind: Diagnosismetadata:annotations:trigger: kubelet-pleg-duration-highoperationSet: docker-debuggername: kubelet-pleg-duration-high.fc76dbd98namespace: defaultspec:nodeName: pri3-k8s1210.jd.163.org # 执行故障诊断的节点,该字段根据 Trigger 的 .spec.sourceTemplate.prometheusAlertTemplate.nodeNameReferenceLabel 设置。operationSet: docker-debugger # 运行的工作流,该字段根据 Trigger 的 .spec.operationSet 设置。status:checkpoint: # 记录当前诊断执行操作的检查点,与 OperationSet 的 .status.paths 一致。nodeIndex: 4pathIndex: 0conditions: # 记录当前诊断的状况。- lastTransitionTime: "2021-04-27T07:52:24Z"message: Diagnosis is accepted by agent on node pri3-k8s1210.jd.163.orgreason: DiagnosisAcceptedstatus: "True"type: Accepted- lastTransitionTime: "2021-04-27T07:52:27Z"message: Diagnosis is completedreason: DiagnosisCompletestatus: "True"type: CompleteoperationResults: # 记录诊断运行的结果。"1": # 记录 Docker 元信息请求的结果。operation: docker-info-collectorresult: '{"ID":"LJM3:UWWT:L6L3:J6RJ:QRB2:NPMT:FXNC:WA6A:S2AN:JNKV:XE6V:HL7C","Containers":167,"ContainersRunning":88,"ContainersPaused":0,"ContainersStopped":79,"Images":80,"Driver":"overlay2","DriverStatus":[["Backing Filesystem","\u003cunknown\u003e"],["Supports d_type","true"],["Native Overlay Diff","true"]],"SystemStatus":null,"Plugins":{"Volume":["local"],"Network":["bridge","host","ipvlan","macvlan","null","overlay"],"Authorization":null,"Log":["awslogs","fluentd","gcplogs","gelf","journald","json-file","local","logentries","splunk","syslog"]},"MemoryLimit":true,"SwapLimit":false,"KernelMemory":true,"CpuCfsPeriod":true,"CpuCfsQuota":true,"CPUShares":true,"CPUSet":true,"IPv4Forwarding":true,"BridgeNfIptables":true,"BridgeNfIp6tables":true,"Debug":false,"NFd":497,"OomKillDisable":true,"NGoroutines":392,"SystemTime":"2021-04-27T16:29:29.283405124+08:00","LoggingDriver":"json-file","CgroupDriver":"cgroupfs","NEventsListener":0,"KernelVersion":"4.15.0-142-generic","OperatingSystem":"Ubuntu 18.04.3 LTS","OSType":"linux","Architecture":"x86_64","IndexServerAddress":"https://index.docker.io/v1/","RegistryConfig":{"AllowNondistributableArtifactsCIDRs":[],"AllowNondistributableArtifactsHostnames":[],"InsecureRegistryCIDRs":["127.0.0.0/8"],"IndexConfigs":{"docker.io":{"Name":"docker.io","Mirrors":["https://docker.mirrors.ustc.edu.cn/"],"Secure":true,"Official":true}},"Mirrors":["https://docker.mirrors.ustc.edu.cn/"]},"NCPU":4,"MemTotal":11645624320,"GenericResources":null,"DockerRootDir":"/data","HttpProxy":"","HttpsProxy":"","NoProxy":"","Name":"pri3-k8s1210.jd.163.org","Labels":[],"ExperimentalBuild":false,"ServerVersion":"19.03.8","ClusterStore":"","ClusterAdvertise":"","Runtimes":{"runc":{"path":"runc"}},"DefaultRuntime":"runc","Swarm":{"NodeID":"","NodeAddr":"","LocalNodeState":"inactive","ControlAvailable":false,"Error":"","RemoteManagers":null},"LiveRestoreEnabled":false,"Isolation":"","InitBinary":"docker-init","ContainerdCommit":{"ID":"7ad184331fa3e55e52b890ea95e65ba581ae3429","Expected":"7ad184331fa3e55e52b890ea95e65ba581ae3429"},"RuncCommit":{"ID":"dc9208a3303feef5b3839f4323d9beb36df0a9dd","Expected":"dc9208a3303feef5b3839f4323d9beb36df0a9dd"},"InitCommit":{"ID":"fec3683","Expected":"fec3683"},"SecurityOptions":["name=apparmor","name=seccomp,profile=default"],"Warnings":["WARNING: No swap limit support"]}'"2": # 记录 dockerd goroutine 的文件服务器访问地址。operation: dockerd-goroutine-collectorresult: '10.180.156.129:30100/dockerd-goroutine/pri3-k8s1210.jd.163.org/goroutine-stacks-2021-04-27T155225+0800.log'"3": # 记录 containerd goroutine 的文件服务器访问地址。operation: containerd-goroutine-collectorresult: '10.180.156.129:30100/containerd-goroutine/pri3-k8s1210.jd.163.org/containerd-goroutine-2021-04-27T155225+0800.log'"4": # 记录将节点置为不可调度的处理结果。operation: node-cordonresult: 'node/pri3-k8s1210.jd.163.org cordoned'phase: Succeeded # 记录当前诊断的状态。startTime: "2021-04-27T07:52:24Z"succeededPath: # 执行成功的诊断路径。- id: 1operation: docker-info-collector- id: 2operation: dockerd-goroutine-collector- id: 3operation: containerd-goroutine-collector- id: 4operation: node-cordon
一次售后技术支持中需要完成的工作
Master
Master 负责管理 Operation、OperationSet、Trigger 和 Diagnosis 对象。当 OperationSet 创建后,Master 会进行合法性检查并基于用户定义生成有向无环图,所有的诊断路径被更新至 OperationSet 的状态中。
Master 会校验 Diagnosis 的 PodReference 或 NodeName 是否存在,如果 Diagnosis 中只定义了 PodReference,则根据 PodReference 计算并更新 NodeName。Master 会查询被 Diagnosis 引用的 OperationSet 状态,如果被引用的 OperationSet 异常,则标记 Diagnosis 失败。Diagnosis 可以由用户直接手动创建,也可以通过配置 Prometheus、Event 或 Elasticsearch 消息模板自动创建。Master 由下列部分组成:
-
GraphBuilder 根据 OperationSet 中定义的顶点生成有向无环图并计算出所有的诊断路径。
-
Alertmanager 接收 Prometheus 报警并根据 Trigger 中定义的模板创建 Diagnosis 对象。
-
Eventer 接收 Kubernetes Event 并根据 Trigger 中定义的模板创建 Diagnosis 对象。
-
ElasticAlerting 接收 Elasticsearch 报警并根据 Trigger 中定义的模板创建 Diagnosis 对象。
Agent
Agent 负责实际诊断的执行并内置多个常用诊断操作。当 Diagnosis 创建后,Agent 会根据 Diagnosis 引用的 OperationSet 执行诊断工作流,诊断工作流是包括多个诊断操作的集合。Agent 组件由下列部分组成:
-
Executor 负责执行诊断工作流。Diagnosis 引用的 OperationSet 状态中包含表示诊断工作流的有向无环图和所有的诊断路径。诊断路径表示诊断过程中的排查路径,通过执行某个诊断路径中每个顶点 Operation 的诊断操作可以对问题进行排查。如果某个诊断路径的所有诊断操作均执行成功,则该次诊断被标记为成功。如果所有诊断路径均执行失败,则该次诊断被标记为失败。
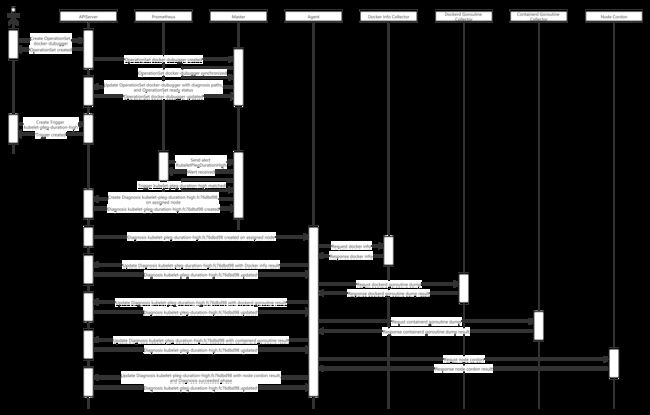
KubeletPlegDurationHigh 报警触发诊断时序图
总结
从早期的容器化落地到现在的云原生商业化,我们思考问题的核心一直是帮助用户切实解决云原生落地过程中的痛点。网易轻舟云原生故障诊断系统提供了一套框架来帮助产品打造可靠的稳定性保障体系,通过团队的努力我们提升了帮助用户的效率并降低了管理成本,让用户真正享受到了云原生技术红利的同时也让我们未来可以走的更远。
作者介绍
黄久远,网易数帆资深开发工程师,专注于云原生以及分布式系统等领域,参与了网易云音乐、网易新闻、网易严选、考拉海购等多个用户的大规模容器化落地以及网易轻舟容器平台产品化工作,主要方向包括集群监控、智能运维体系建设、Kubernetes 以及 Docker 核心组件维护等。当前主要负责网易轻舟云原生故障诊断系统的设计、开发以及产品商业化工作。