Java和C++的一些比较[Java] Excption与Error包结构,OOM和SOF1. 九种基本数据类型的大小,以及他们的封装类。
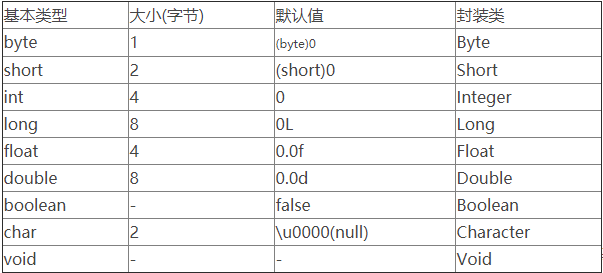
注:基本数据类型在声明时系统会自动给它分配空间,而引用类型声明时只是分配了引用空间,必须通过实例化开辟数据空间之后才可以赋值
2. Switch能否用string做参数?
JDK1.6的版本中,switch后面的括号里面只能放int类型的值,注意是只能放int类型,但是放byte,short,char类型的也可以。是因为byte,short,shar可以自动提升(自动类型转换)为int。而不能放long型和String型。JDK1.7的版本中,switch中可以使用字串String。
注:String时不能传入null作为参数,同时case语句中使用的字符串也不能为null,因为底层是通过equals和hashmap来判断的
3. equals与==的区别。
==用于判断两边的变量的值是否相等,如果是基本数据类型,就是判断他们的值是不是相等;如果==两边是对象的引用,那么指的是这两个引用是否指向同一个对象,及引用的值是否相等。
equals()是Object里的方法。在Object的equals中,就是使用==来进行比较,比较的是引用。与==不同的是,在某些Object的子类中,覆盖了equals()方法,比如String中的equals()方法比较两个字符串对象的内容是否相同。
hashCode()方法也是继承自Object,它用来获取一个对象的hash值,返回int值。Object.hashCode规定,equals()相等的对象,它们的HashCode()返回值也必须相等,否则无法与集合类结合在一起使用。(List, Set, Hashmap..)
4. Object有哪些公用方法?
Object是所有类的父类,任何类都默认继承Object。
clone
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常
equals
在Object中与==是一样的,子类一般需要重写该方法
hashCode
该方法用于哈希查找,重写了equals方法一般都要重写hashCode方法。这个方法在一些具有哈希功能的Collection中用到
getClass
final方法,获得运行时类型
wait
使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生:
1. 其他线程调用了该对象的notify方法
2. 其他线程调用了该对象的notifyAll方法
3. 其他线程调用了interrupt中断该线程
4. 时间间隔到了
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常
notify
唤醒在该对象上等待的某个线程
notifyAll
唤醒在该对象上等待的所有线程
toString
转换成字符串,一般子类都有重写,否则打印句柄
5. Java的四种引用,强弱软虚,用到的场景。
1、强引用
强引用不会被GC回收,并且在java.lang.ref里也没有实际的对应类型,平时工作接触的最多的就是强引用。
Object obj = new Object();这里的obj引用便是一个强引用。如果一个对象具有强引用,那就类似于必不可少的生活用品,垃圾回收器绝不会回收它。当内存空 间不足,Java虚拟机宁愿抛出OutOfMemoryError错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
2、软引用
如果一个对象只具有软引用,那就类似于可有可物的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只 要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。 软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中
3、弱引用
如果一个对象只具有弱引用,那就类似于可有可物的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回 收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
4、幽灵引用(虚引用)
虚引用主要用来跟踪对象被垃圾回收器回收的活动。虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列 (ReferenceQueue)联合使用。当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列中。程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。由于Object.finalize()方法的不安全性、低效性,常常使用虚引用完成对象回收前的资源释放工作。
四种引用
6. Hashcode的作用。
hashCode方法的主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。
为什么这么说呢?考虑一种情况,当向集合中插入对象时,如何判别在集合中是否已经存在该对象了?(注意:集合中不允许重复的元素存在)。比equals 更加有效率。
因此有人会说,可以直接根据hashcode值判断两个对象是否相等吗?肯定是不可以的,因为不同的对象可能会生成相同的hashcode值。虽然不能根据hashcode值判断两个对象是否相等,但是可以直接根据hashcode值判断两个对象不等,如果两个对象的hashcode值不等,则必定是两个不同的对象。如果要判断两个对象是否真正相等,必须通过equals方法。
也就是说对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
如果两个对象的hashcode值相等,则equals方法得到的结果未知。
在有些情况下,程序设计者在设计一个类的时候为需要重写equals方法,比如String类,但是千万要注意,在重写equals方法的同时,必须重写hashCode方法。
7. ArrayList、LinkedList、Vector的区别。
1、ArrayList、Vector、LinkedList类都是java.util包中,均为可伸缩数组。
2、ArrayList和Vector底层都是数组实现的,所以,索引数据快,删除、插入数据慢。
ArrayList采用异步的方式,性能好,属于非线程安全的操作类。(JDK1.2)
Vector采用同步的方式,性能较低,属于线程安全的操作类。(JDK1.0)
3、LinkedList底层是链表实现,所以,索引慢,删除、插入快,属于非线程安全的操作类。
ArrayList、LinkedList、Vector的区别
8. String、StringBuffer与StringBuilder的区别。
stringBuffer、StringBuilder和String一样,也用来代表字符串。String类是不可变类,任何对String的改变都 会引发新的String对象的生成;StringBuffer则是可变类,任何对它所指代的字符串的改变都不会产生新的对象.
StringBufferd支持并发操作,线性安全的,适 合多线程中使用。StringBuilder不支持并发操作,线性不安全的,不适合多线程中使用。新引入的StringBuilder类不是线程安全的,但其在单线程中的性能比StringBuffer高。
9. Map、Set、List、Queue、Stack的特点与用法。
Collection 是对象集合, Collection 有两个子接口 List 和 Set
List 可以通过下标 (1,2..) 来取得值,值可以重复
而 Set 只能通过游标来取值,并且值是不能重复的
ArrayList , Vector , LinkedList 是 List 的实现类
ArrayList 是线程不安全的, Vector 是线程安全的,这两个类底层都是由数组实现的
LinkedList 是线程不安全的,底层是由链表实现的
Map 是键值对集合
HashTable 和 HashMap 是 Map 的实现类
HashTable 是线程安全的,不能存储 null 值
HashMap 不是线程安全的,可以存储 null 值
Stack类:继承自Vector,实现一个后进先出的栈。提供了几个基本方法,push、pop、peak、empty、search等。
Queue接口:提供了几个基本方法,offer、poll、peek等。已知实现类有LinkedList、PriorityQueue等。
Map
Map是键值对,键Key是唯一不能重复的,一个键对应一个值,值可以重复。
TreeMap可以保证顺序,HashMap不保证顺序,即为无序的。
Map中可以将Key和Value单独抽取出来,其中KeySet()方法可以将所有的keys抽取正一个Set。而Values()方法可以将map中所有的values抽取成一个集合。
Set
不包含重复元素的集合,set中最多包含一个null元素
只能用Lterator实现单项遍历,Set中没有同步方法。
List
有序的可重复集合。
可以在任意位置增加删除元素。
用Iterator实现单向遍历,也可用ListIterator实现双向遍历
Queue
Queue遵从先进先出原则。
使用时尽量避免add()和remove()方法,而是使用offer()来添加元素,使用poll()来移除元素,它的优点是可以通过返回值来判断是否成功。
LinkedList实现了Queue接口。
Queue通常不允许插入null元素。
Stack
Stack遵从后进先出原则。
Stack继承自Vector。
它通过五个操作对类Vector进行扩展,允许将向量视为堆栈,它提供了通常的push和pop操作,以及取堆栈顶点的peek()方法、测试堆栈是否为空的empty方法等
用法
如果涉及堆栈,队列等操作,建议使用List
对于快速插入和删除元素的,建议使用LinkedList
如果需要快速随机访问元素的,建议使用ArrayList
参考资料:http://blog.csdn.net/Amazing7/article/details/51119893
10. HashMap和HashTable的区别。
1 HashMap不是线程安全的
HashMap是map接口的子类,是将键映射到值的对象,其中键和值都是对象,并且不能包含重复键,但可以包含重复值。HashMap允许null key和null value,而hashtable不允许。
2 HashTable是线程安全。
HashMap是Hashtable的轻量级实现(非线程安全的实现),他们都完成了Map接口,主要区别在于HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
11. HashMap和ConcurrentHashMap的区别,HashMap的底层源码。
Hashmap本质是数组加链表。根据key取得hash值,然后计算出数组下标,如果多个key对应到同一个下标,就用链表串起来,新插入的在前面。
ConcurrentHashMap:在hashMap的基础上,ConcurrentHashMap将数据分为多个segment,默认16个(concurrency level),然后每次操作对一个segment加锁,避免多线程锁的几率,提高并发效率。
HashMap和ConcurrentHashMap的区别,HashMap的底层源码。
12. TreeMap、HashMap、LindedHashMap的区别。
共同点:
HashMap,LinkedHashMap,TreeMap都属于Map;Map 主要用于存储键(key)值(value)对,根据键得到值,因此键不允许键重复,但允许值重复。
不同点:
1.HashMap里面存入的键值对在取出的时候是随机的,也是我们最常用的一个Map.它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度。在Map 中插入、删除和定位元素,HashMap 是最好的选择。
2.TreeMap取出来的是排序后的键值对。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。
3. LinkedHashMap 是HashMap的一个子类,如果需要输出的顺序和输入的相同,那么用LinkedHashMap可以实现. (应用场景:购物车等需要顺序的)
13. Collection包结构,与Collections的区别。
Collection是集合类的一个顶级接口,其直接继承接口有List与Set
而Collections则是集合类的一个工具类/帮助类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作。
Collection是个java.util下的接口,它是各种集合结构的父接口。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection
1、Collection是集合类的顶级接口;
2、实现接口和类主要有Set、List、LinkedList、ArrayList、Vector、Stack、Set;
Collections
1、是针对集合类的一个帮助类,提供操作集合的工具方法;
2、一系列静态方法实现对各种集合的搜索、排序、线程安全化等操作;
3、服务于Java的Collection的框架;
14. try catch finally,try里有return,finally还执行么?
1、不管有木有出现异常,finally块中代码都会执行;
2、当try和catch中有return时,finally仍然会执行;
3、finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,返回的值都不会改变,任然是之前保存的值),所以函数返回值是在finally执行前确定的;
4、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
15. Excption与Error包结构。OOM你遇到过哪些情况,SOF你遇到过哪些情况。

Android的OOM(Out Of Memory)
当内存占有量超过了虚拟机的分配的最大值时就会产生内存溢出(VM里面分配不出更多的page)。
一般出现情况:加载的图片太多或图片过大时、分配特大的数组、内存相应资源过多没有来不及释放。
解决方法:
①在内存引用上做处理
软引用是主要用于内存敏感的高速缓存。在jvm报告内存不足之前会清除所有的软引用,这样以来gc就有可能收集软可及的对象,可能解决内存吃紧问题,避免内存溢出。什么时候会被收集取决于gc的算法和gc运行时可用内存的大小。
②对图片做边界压缩,配合软引用使用
③显示的调用GC来回收内存
Android内存管理之道
SOF (堆栈溢出 StackOverflow)
StackOverflowError 的定义:
当应用程序递归太深而发生堆栈溢出时,抛出该错误。
因为栈一般默认为1-2m,一旦出现死循环或者是大量的递归调用,在不断的压栈过程中,造成栈容量超过1m而导致溢出。
栈溢出的原因:
递归调用
大量循环或死循环
全局变量是否过多
数组、List、map数据过大
[Java] Excption与Error包结构,OOM和SOF
16. Java面向对象的三个特征与含义。
面向对象的三个特征与含义
17. Override和Overload的含义去区别。
方法的重写(Overriding)和重载(Overloading)是Java多态性的不同表现。
重写(Overriding)是父类与子类之间多态性的一种表现,而重载(Overloading)是一个类中多态性的一种表现。如果在子类中定义某方法与其父类有相同的名称和参数,我们说该方法被重写 (Overriding) 。子类的对象使用这个方法时,将调用子类中的定义,对它而言,父类中的定义如同被"屏蔽"了。如果在一个类中定义了多个同名的方法,它们或有不同的参数个数或有不同的参数类型或有不同的参数次序,则称为方法的重载(Overloading)。不能通过访问权限、返回类型、抛出的异常进行重载。
1. Override 特点
1、覆盖的方法的标志必须要和被覆盖的方法的标志完全匹配,才能达到覆盖的效果;
2、覆盖的方法的返回值必须和被覆盖的方法的返回一致;
3、覆盖的方法所抛出的异常必须和被覆盖方法的所抛出的异常一致,或者是其子类;
4、方法被定义为final不能被重写。
5、对于继承来说,如果某一方法在父类中是访问权限是private,那么就不能在子类对其进行重写覆盖,如果定义的话,也只是定义了一个新方法,而不会达到重写覆盖的效果。(通常存在于父类和子类之间。)
2.Overload 特点
1、在使用重载时只能通过不同的参数样式。例如,不同的参数类型,不同的参数个数,不同的参数顺序(当然,同一方法内的几个参数类型必须不一样,例如可以是fun(int, float), 但是不能为fun(int, int));
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
4、重载事件通常发生在同一个类中,不同方法之间的现象。
5、存在于同一类中,但是只有虚方法和抽象方法才能被覆写。
其具体实现机制:
overload是重载,重载是一种参数多态机制,即代码通过参数的类型或个数不同而实现的多态机制。 是一种静态的绑定机制(在编译时已经知道具体执行的是哪个代码段)。
override是覆盖。覆盖是一种动态绑定的多态机制。即在父类和子类中同名元素(如成员函数)有不同 的实现代码。执行的是哪个代码是根据运行时实际情况而定的。
18. Interface与abstract类的区别。
abstract类
1、抽象类不能被实例化,实例化的工作应该交由它的子类来完成,它只需要有一个引用即可。
2、抽象方法必须由子类来进行重写。
3、只要包含一个抽象方法的抽象类,该方法必须要定义成抽象类,不管是否还包含有其他方法。
4、抽象类中可以包含具体的方法,当然也可以不包含抽象方法。
5、子类中的抽象方法不能与父类的抽象方法同名。
6、abstract不能与final并列修饰同一个类。
7、abstract 不能与private、static、final或native并列修饰同一个方法。
接口
1、个Interface的方所有法访问权限自动被声明为public。确切的说只能为public,当然你可以显示的声明为protected、private,但是编译会出错!
2、接口中可以定义“成员变量”,或者说是不可变的常量,因为接口中的“成员变量”会自动变为为public static final。可以通过类命名直接访问:ImplementClass.name。
3、接口中不存在实现的方法。
4、实现接口的非抽象类必须要实现该接口的所有方法。抽象类可以不用实现。
5、不能使用new操作符实例化一个接口,但可以声明一个接口变量,该变量必须引用(refer to)一个实现该接口的类的对象。可以使用 instanceof 检查一个对象是否实现了某个特定的接口。例如:if(anObject instanceof Comparable){}。
6、在实现多接口的时候一定要避免方法名的重复。
Interface与abstract类的区别
19. Static class 与non static class的区别。
Static class
1、用static修饰的是内部类,此时这个
内部类变为静态内部类;对测试有用;
2、内部静态类不需要有指向外部类的引用;
3、静态类只能访问外部类的静态成员,不能访问外部类的非静态成员;
non static class
1、非静态内部类需要持有对外部类的引用;
2、非静态内部类能够访问外部类的静态和非静态成员;
3、一个非静态内部类不能脱离外部类实体被创建;
4、一个非静态内部类可以访问外部类的数据和方法;
20. java多态的实现原理。
java多态实现原理
深入理解JAVA多态原理
21. 实现多线程的两种方法:Thread与Runable。
Java有两种方式实现多线程,第一个是继承Thread类,第二个是实现Runnable接口。他们之间的联系:
1、Thread类实现了Runable接口。
2、都需要重写里面Run方法。
他们之间的区别“
1、实现Runnable的类更具有健壮性,避免了单继承的局限。
2、Runnable更容易实现资源共享,能多个线程同时处理一个资源。
Thread与Runnable两种多线程方式
22. 线程同步的方法:sychronized、lock、reentrantLock等。
线程同步的方法:sychronized、lock、reentrantLock等总结分析
23. 锁的等级:方法锁、对象锁、类锁。
java synchronized关键字的用法以及锁的等级:方法锁、对象锁、类锁
24. 写出生产者消费者模式。
生产者消费者模式-Java实现
25. ThreadLocal的设计理念与作用。
ThreadLocal的设计理念与作用
ThreadLocal的设计与使用(原理篇)
26. ThreadPool用法与优势。
【Java高级】ThreadPool用法与优势
线程池ThreadPoolExecutor使用简介
27. Concurrent包里的其他东西:ArrayBlockingQueue、CountDownLatch等等。
java.util.concurrent包分成了三个部分,分别是java.util.concurrent、java.util.concurrent.atomic和java.util.concurrent.lock。内容涵盖了并发集合类、线程池机制、同步互斥机制、线程安全的变量更新工具类、锁等等常用工具。
BlockingQueue接口定义了一种阻塞的FIFO queue,每一个BlockingQueue都有一个容量,让容量满时往BlockingQueue中添加数据时会造成阻塞,当容量为空时取元素操作会阻塞。
ArrayBlockingQueue是一个由数组支持的有界阻塞队列。在读写操作上都需要锁住整个容器,因此吞吐量与一般的实现是相似的,适合于实现“生产者消费者”模式。
ArrayBlockingQueue和LinkedBlockingQueue的使用
CountDownLatch是JAVA提供在java.util.concurrent包下的一个辅助类,可以把它看成是一个计数器,其内部维护着一个count计数,只不过对这个计数器的操作都是原子操作,同时只能有一个线程去操作这个计数器,CountDownLatch通过构造函数传入一个初始计数值,调用者可以通过调用CounDownLatch对象的cutDown()方法,来使计数减1;如果调用对象上的await()方法,那么调用者就会一直阻塞在这里,直到别人通过cutDown方法,将计数减到0,才可以继续执行。
什么时候使用CountDownLatch
28. wait()和sleep()的区别。
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
sleep()方法导致了程序暂停执行指定的时间,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。在调用sleep()方法的过程中,线程不会释放对象锁。而且sleep()只能自己到点了醒来,不能被唤醒。
wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池,准备获取对象锁进入运行状态。
sleep和wait区别
java sleep和wait的区别的疑惑
29. foreach与正常for循环效率对比。
需要循环数组结构的数据时,建议使用普通for循环,因为for循环采用下标访问,对于数组结构的数据来说,采用下标访问比较好。
需要循环链表结构的数据时,一定不要使用普通for循环,这种做法很糟糕,数据量大的时候有可能会导致系统崩溃。
Java for循环和foreach循环的性能比较
30. Java IO与NIO。
NIO vs IO之间的理念上面的区别(NIO将阻塞交给了后台线程执行)
IO是面向流的,NIO是面向缓冲区的
Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方;
NIO则能前后移动流中的数据,因为是面向缓冲区的
IO流是阻塞的,NIO流是不阻塞的
Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。NIO可让您只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。
非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
选择器
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
Java NIO 与 IO之间的区别
Java NIO与IO的区别和比较
Java NIO系列教程(十二) Java NIO与IO
31. 反射的作用与原理。
Java反射的作用
反射(一)----原理机制和基本运用
32. 泛型常用特点,List能否转为List。
java泛型详解
Java技术----Java泛型详解
Java总结篇系列:Java泛型
33. 解析XML的几种方式的原理与特点:DOM、SAX、PULL。
三种高效解析xml方式
34. Java与C++对比。
Java和C++的一些比较
35. Java1.7与1.8新特性。
jdk1.7和jdk1.8区别
36. 设计模式:单例、工厂、适配器、责任链、观察者等等。
23种设计模式全解析
设计模式 | 菜鸟教程
37. JNI的使用。
Java中JNI的使用详解第一篇:HelloWorld
呕心沥血Android studio使用JNI实例
Java里有很多很杂的东西,有时候需要你阅读源码,大多数可能书里面讲的不是太清楚,需要你在网上寻找答案。
推荐书籍:《java核心技术卷I》《Thinking in java》《java并发编程》《effictive java》《大话设计模式》
参考
几道常问的题
面试中的一些问题——JAVA(一)