python开发基础 从入门到放弃
python学习笔记
第一章 计算机的初步认识
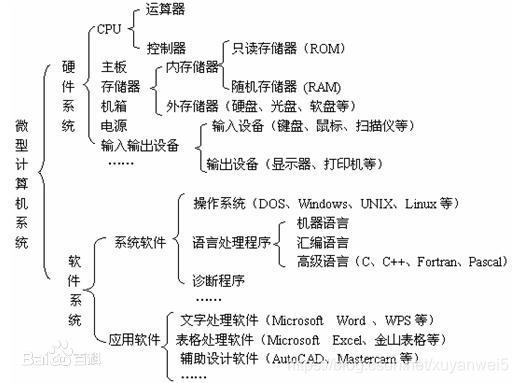
1.1计算机的组成
-
硬件:cpu ( 中央处理器. 相当于人的大脑.运算中心,控制中心),内存(临时存储数据. 优点:读取速度快。 缺点:容量小,造价高,断电即消失),硬盘(长期存储数据. 优点:容量大,造价相对低,断电不消失。 缺点:读取速度慢),主板,U盘,显卡,网卡,鼠标,显示器等
-
软件:操作系统(统一管理计算机软硬件资源的程序)包括win7.10.xp/linux(centos,ubuntu,rethat)/mac,应用软件等
1.2认识python
# ### (1)python 简介
89年开发的语言,创始人范罗苏姆(Guido van Rossum),别称:龟叔(Guido).
python具有非常多并且强大的第三方库,使得程序开发起来得心应手.
Python程序员的信仰:人生苦短,我用python!
开发方向: 机器学习人工智能 ,自动化运维&测试 ,数据分析&爬虫 ,python全栈开发
# ### (2)python 版本
python 2.x 版本,官方在 2020 年停止支持,原码不规范,重复较多
python 3.x 版本,功能更加强大且修复了很多bug,原码清晰,简单
# ### (3)编译型与解释型语言区别:
编译型:一次性,把所有代码编译成机器能识别的二进制码,在运行
代表语言:c,c++
优点: 执行速度块
缺点: 开发速度慢,调试周期长
解释型:代码从上到下一行一行解释并运行
代表语言:python,php
优点: 开发效率快,调试周期短
缺点: 执行速度相对慢
*linux 操作系统默认支持python语言,可直接使用
# ### (4)python的解释器:
(1)Cpython(官方推荐)
把python转化成c语言能识别的二进制码
(2)Jpython
把python转化成java语言能识别的二进制码
(3)其他语言解释器
把python转化成其他语言能识别的二进制码
(4)PyPy
将所有代码一次性编译成二进制码,加快执行效率(模仿编译型语言的一款python解释器)

1.2编译器/解释器/虚拟机安装
2.2.1下载
- python2.7.16(2020年不再更新)
- python3.6.8(*)
2.2.2安装
2.2.3添加环境变量
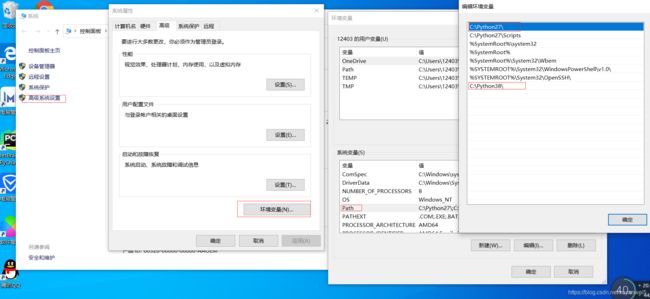
-
填入你安装的文件路径
-
开发工具:pycharms/文本编译器
2.2.4打开终端运行
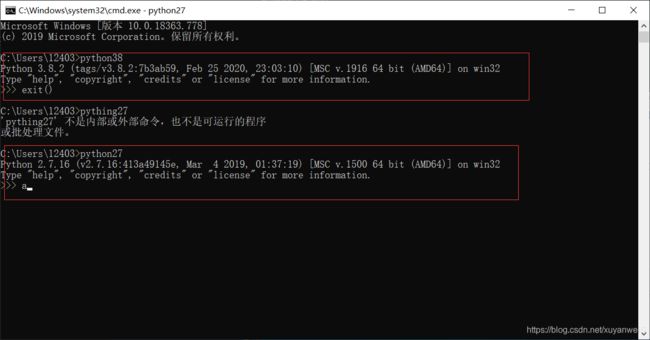
1.3python第一个脚本
-
打开电脑终端(功能键+R)
-
输入命令:解释器路径 脚本路径(.py)
print('你好')
1.4编码
1.4.1分类
-
ASCII:(python2默认编码),英文,8位表示一个元素。2**8
8位 = 一字节
-
Unicode:万国码,32位表示一个元素。2**32
32位 = 四字节
- ecs2:二字节
- ecs4:四字节
-
Utf-8:(python3默认编码),给万国码压缩,以8位为单位(*)
最少一字节,最多4字节,中文三字节
-
utf-16:
-
gbk:中文两字节
-
gb2312:中文两字节
-
单位: 8bit = 1byte
1024byte = 1KB
1024KB= 1MB
1024MB = 1GB
1024GB = 1TB
1.4.2python2解释器编码转换
修改默认解释器编码
# -*- coding :utf-8 -*-
1.4.3文件编码
- 编写文件时,要用 utf-8 格式
- 以什么编码保存就用什么编码打开
1.5解释器
#!/usr/bin/env python 在Linux中指定解释器编码
# -*- coding:utf-8 -*-
1.6输出
print(想要输出的内容)
- 特殊
- py2:print“你好”
- py3:print(“你好”)
1.7输入
input(需要输入的内容)
user_name = input('请输入用户名')
password = input("请输入密码")
#用户名和密码拼接
count = "你的用户名是" + user_name + ";你的密码是:" + password
print (count)
py版本区别
- py2:raw_input(“请输入姓名”)
- py3: input(“请输入姓名”)
1.8进制
- 二进制(计算机内部)
- 00、01、10、11、100、101···
- 八进制
- 1、2、3、4、5、6、7、10、11···
- 十进制(日常生活计算)
- 1、2、3、4、5、6、7、8、9、10、11···
- 十六进制
- 1、2、3、4、5、6、7、8、9、A、B、C、D、E、F、10、11···
1.8.1 二进制 转化成 十进制
#例: 0b10100101
'''
运算:1* 2^0 + 0* 2^1 + 1* 2^2 + 0* 2^3 + 0* 2^4 + 1* 2^5 + 0* 2^6 + 1* 2^7=
1 + 0 + 4 + 0 + 0 + 32 + 0 + 128 = 165
'''
1.8.2 八进制 转化成 十进制
#例: 0o127
'''
运算:7*8^0 + 2*8^1 + 1*8^2 = 7+16+64 = 87
'''
1.8.3 十六进制 转化成 十进制
#例: 0xff
'''
运算:15*16^0 + 15*16^1 = 255
'''
1.8.4 十进制 转化成 二进制
426 => 0b110101010
'''
运算过程: 用426除以2,得出的结果再去不停地除以2,
直到除完最后的结果小于2停止,
在把每个阶段求得的余数从下到上依次拼接完毕即可
'''
1.8.5 十进制 转化成 八进制
426 => 0o652
'''
运算过程: 用426除以8,得出的结果再去不停地除以8,
直到除完最后的结果小于8停止,
在把每个阶段求得的余数从下到上依次拼接完毕即可
'''
1.8.6 十进制 转化成 十六进制
'''
运算过程: 用426除以16,得出的结果再去不停地除以16,
直到除完最后的结果小于16停止,
在把每个阶段求得的余数从下到上依次拼接完毕
'''
1.8.7 二进制与八进制转换
'''
二进制与八进制对应关系:
八进制 二进制
0 000
1 001
2 010
3 011
4 100
5 101
6 110
7 111
'''
例:1010100101
八进制:从右向左 3位一隔开 不够三位用0补位 变成:
001 010 100 101
0o 1 2 4 5
1.8.8 二进制与十六进制转换
十六进制 二进制
0 0000
1 0001
2 0010
3 0011
4 0100
5 0101
6 0110
7 0111
8 1000
9 1001
a 1010
b 1011
c 1100
d 1101
e 1110
f 1111
例:1010100101
十六进制:从右向左 4位一隔开 不够四位用0补位 变成:
0010 1010 0101
0x2a5
1.8.9 八进制 与 十六进制的转换
先转换成二进制 再去对应转换
比如:0x2a5 转换成 1010100101 再转8进制 0o1245
1.9原码,反码,补码
# 1.原码 或 补码 都是二进制数据
原码: 二进制的表现形式
反码: 二进制码0变1,1变0叫做反码,[原码][补码]之间的转换形式.(首位符号位不取反)
补码: 二进制的存储形式
数据用[补码]形式存储
数据用[原码]形式显示
[原码] 和 [补码] 可以通过[反码]互相转化,互为取反加1
# 2.提出补码的原因
补码的提出用于表达一个数的正负(可实现计算机的减法操作)
计算机默认只会做加法,实现减法用负号: 5+(-3) => 5-3
乘法除法:是通过左移和右移 << >> 来实现
# 3.[原码]形式的正负关系:
原码特点: 第一位是1
00000000 1 表达数字正1
10000000 1 表达数字负1
# 4.[补码]形式的正负关系:
补码特点: 高位都是1
00000000 1 表达数字正1
11111111 1 表达数字负1
# 5.运算顺序:
补码 -> 原码 -> 最后人们看到的数
***进制转换的时候需要先把内存存储的补码拿出来变成原码在进行转换输出***
转换规律:
如果是一个正数: 原码 = 反码 = 补码
如果是一个负数: 原码 与 反码 之间 , 互为取反加1
原码 = 补码取反加1 给补码求原码
补码 = 原码取反加1 给原码求补码
1.9变量
变量:可以变化的量
为某个值创建一个昵称,以后在使用可直接调用
1.9.1要求
1.变量名只能包含: 字符串/数字/下划线,首字符不能是数字
2.见名知意:变量命名有意义
3.不能用python关键字
4.不能使用中文(占用内存大)
1.10注释
(1)注释的分类 : 1.单行注释 2.多行注释
# 1.单行注释 以#号开头 ,右边的所有东西都被当做说明文字 ,程序不进行编译运行。
print(‘hello world’)
# 2.多行注释 三个单引号 或 三个双引号
'''
这是第一行
这是第二行
'''
(2)注释的注意点
如果外面使用三个单引号,里面使用三个双引号,反之亦然。
(3)注释的排错性
先注释一部分代码,然后执行另外一部分,看看是否报错,逐层缩小报错范围,找到最终错误点。
1.11条件判断
- 判断数据类型 isinstance
'''
语法:
用法一
isinstance(要判断的值,要判断的类型)返回True 或者False
用法二
isinstance(要判断的值,(可能的类型1,可能类型2,..)返回True 或者False
'''
# 用法一
res = isinstance(3,int)
res= isinstance('23',tuple)
print(res)
#用法二
res = isinstance([1,3,4,6],(str,dict,set,list))
print(res)
- 代码块 : 以冒号作为开始,用于缩进来划分作用域(作用的区域,作用的范围)
- 流程控制
- 流程: 对代码执行的过程
- 控制: 对代码执行过程的一种把控
- 三大结构:
- 顺序结构: 默认代码从上到下执行
- 分支结构: 4 种(单项,多项,双项,巢状)
- 循环结构 : for while
#1.单项分支
if 条件表达式:
code
#条件成立时,返回True,执行对应代码块,反之不执行
#2. 双项分支
if 条件表达式:
code
else:
code2
#条件表达式成立,执行if 对应的代码块
#如果不成立,执行else对应代码块
#if 代码块也叫真区间
#else 代码块也叫假区间
#3. 多项分支
if 条件表达式1:
code1
elif 条件表达式2:
code2
elif 条件表达式3:
code 3
...
else:
code...
'''
如果条件一成立,返回True,执行对应代码块,反之则向下执行
如果条件二成立,返回True,执行对应代码块,反之则向下执行
...
最后,任何条件都不成立(满足),执行else这个分支的代码块
'''
4. 巢状分支:单项,双项,多项分支的相互嵌套
# 巢状练习
youqian = False
youfang = False
youche = False
youyanzhi = False
youtili = False
if youqian == True :
if youfeng == True:
if yoyanzhi == True :
if youtili == True :
print('老娘今天要嫁给你')
else :
print('恭喜你,备胎一号')
else:
print('去韩国整整容')
else :
print('出门右拐,二路汽车')
#多项练习:对于性别的判断
gender = input('请输入性别')
if gender == '男' :
print('再见')
elif gender == '女':
print('来来来')
else :
print('好走,不送')
#双项练习:用户名和密码登录
user_name = input('请输入用户名')
password = input('请输入密码')
if user_name == 'alxe' and password == 'oldboy' :
print('欢迎登陆')
else :
print('用户名或密码错误')
第二章 运算符
2.1while循环
特点: 减少冗余的代码,提升代码的效率
语法:
while 条件表达式:
code1
1.初始化一个变量
2.写上循环的判断条件
3.自增自减的变量值
# 示例
count = 1
while True :
print(count)
count += 1
#练习:数字一到十
count = 1
while count <= 10 :
print(count)
count += 1
#练习:输入数字一到十,不含7
count = 1
while count <= 10 :
if count != 7 :
print(count)
count += 1
方法二
count = 1
while count <= 10 :
if count == 7:
pass
else:
print(count)
count += 1
- 单项循环的练习
# 1. 打印一行十个小星星
i = 0
while i <10:
print('*',end='')# 打印不换行
i +=1
# 2. 通过打印变量实现一行十个小星星
i = 0
strvar = ''
while i<10:
strvar += '*'
i += 1
print(strvar)
# 3. 打印一行十个小星星,奇数个为★,偶数个为☆
i = 0
while i < 10:
if i % 2 == 0:
print('★',end='')
else:
print('☆',end ='')
i += 1
# 4. 循环打印十行十列的小星星
i = 0
while i < 100:
if i % 10 == 9:
print()
print('*',end='')
i += 1
# 5. 一个循环打印十行十列隔列换色的小星星
i = 0
while i < 100:
if i % 2 ==0 :
print ('★',end='')
else:
print('☆',end='')
if i % 10 == 9:
print()
i += 1
# 6.循环打印十行十列换行换色的小星星
i = 0
while i < 100:
if i // 10 % 2 == 0:
print('★',end='')
else:
print('☆',end='')
if i % 10 == 9:
print()
i += 1
- 双项循环的练习
# 1.打印十行十列小星星(2个循环)
i = 0
while i < 10:
j = 0
while j < 10:
print('*',end='')
j += 1
print()
i += 1
# 2.打印十行十列小星星(隔列换色小星星,两个循环)
i = 0
while i < 10:
j = 0
while:
if j % 2 == 0:
print('★',end='')
else:
print('☆',end='')
j += 1
print()
i += 1
# 3.打印十行十列小星星(隔行换色小星星,两个循环)
i = 0
while i < 10:
j = 0
while:
if i % 2 == 0:
print('★',end='')
else:
print('☆',end='')
j += 1
print()
i += 1
# 4.99乘法表
i = 1
while i< 10:
j = 1
while j< =i :
print('%d*%d=%2d '%(i,j,i*j),end='')
j += 1
print()
i += 1
# 5.右侧显示乘法表
i = 1
while i < 10:
k = 9 - i
while k >0:
print(' ',end='')
k -= 1
j = 0
while j <= i:
print('%d*%d=%2d '%(i,j,i*j),end='')
j += 1
print()
i += 1
# 6.求吉利数字100 ~ 999 666 888 111 222 333 444 ... 123 789 567 765 432
# 方法一
i = 100
while i <1000:
strvar = str(i)
gewei = int(strvar[2])
shiwei = int(strvar[1])
baiwei = int (strvar[0])
if gewei == shiwei and shiwei == baiwei:
print(i)
elif gewei + 1 == shiwei and shiwei + 1 == baiwei
print(i)
elif gewei == shiwei +1 and shiwei == baiwei +1
print(i)
i += 1
# 方法二
i = 100
while i < 1000:
gewei = i % 10
shiwei = i // 10 % 10
baiwei = i // 100
if gewei == shiwei and shiwei == baiwei:
print(i)
elif gewei + 1 == shiwei and shiwei + 1 == baiwei
print(i)
elif gewei == shiwei +1 and shiwei == baiwei +1
print(i)
i += 1
# 7. 百钱买百鸡
"""
公鸡x 母鸡y 小鸡z
公鸡1块钱1只,母鸡3块钱一只,小鸡5毛钱一只
问: 用100块钱买100只鸡,有多少种买法?
"""
i = 0
while i < 100:
j = 0
while j < 34:
k = 0
while k <= 100:
if i + 3*j + 0.5 * k == 100 and i + j + k == 100:
print(i,j,k)
2.1.1关键字:break
- 终止当前循环
#数字一到十
count = 1
while True :
print(count)
if count == 10
break
count += 1
2.1.2关键字: continue
-
跳出当前循环,回到while条件位置。
#输入数字一到十,不含7 count = 1 while count <= 10 : if count == 7 : count += 1 continue else: print(count) count += 1
2.1.3关键字: else
- 不再满足while 条件时,else执行或条件=false
2.1.4关键字: pass
- 过(占位)
while True:
pass
2.1.5关键字: for
for 主要用于遍历数据而提出,while在遍历数据时存在局限性
for 变量 in 可迭代对象:
code1
可迭代对象(容器类型数据,range对象,迭代器)
# 遍历字符串
container = "雷霆嘎巴,ZBC,无情哈拉少"
# 遍历列表
container = ["刘鑫","刘子豪","刘子涛","晏国彰"]
# 遍历元组
container = (1,2,3,45)
# 遍历集合
container = {
"白星","高峰峰","孙志和","刘鹏","牧树人"}
# 遍历字典 (遍历字典时,只遍历键)
container = {
"ww":"伟大的人,风流倜傥","msr":"树人,伟大的人","mh":"猥琐的老男人"}
fori i in container:
print(i)
# 遍历不等长的二级容器
container = [['刘崇','毛红雷','余睿'],('张家豪','小崔')]
for i in container:
print(i)
# 变量的解包
a,b = 4,6
a,b = [6,2]
a,b = {
'a':1,'b':2}
print(a,b)
# 遍历等长的二级容器
container = [('王健林','王思聪','王夫人'),('马云','马化腾','马大姐')]
for a,b,c in container:
print(a,b,c)
2.1.6关键字: range
range(开始值,结束值,步长)结束值本身取不到,取到结束值之前的那个数
for i in range(10):
print(i)
# 只有两个值
for i in range(3,11):
print(i)
# 只有三个值
for i in range(1,10,3):
print(i) # 1,4,7
#1 (1+3)=>4 (4+3)=>7 (7+3)=>10取不到
# 倒序打印10 ~ 1
for i in range(10,0,-1):
print(i)
2.2格式化输出
name =('姓名')
do = ('在干什么:')
templat = '%s在教室,%s。 '%(name,do)
print(templat)
templat ='我是%s,年龄%d,职业%s'%('alxe',25,'it')
print(templat)
- %s : 格式化字符串(万能)
- %d : 格式化整数
- %f : 格式化浮点数
- %% : 原型化输出百分号
2.3运算符
| python运算符 | 注意点 |
|---|---|
| 算数运算符 | % 取余 , //地板除 , ** 幂运算 |
| 位运算符 | 优先级 (<<或 >> ) > & > ^ > | 5 << 1 结果:10 , 5 >> 1 结果:2 |
| 比较运算符 | == 比较两个值是否相等 != 比较两个值是否不同 |
| 身份运算符 | is 和 is not 用来判断内存地址是否相同 |
| 成员运算符 | in 或 not in 判断某个值是否包含在(或不在)一个容器类型数据当中 |
| 逻辑运算符 | 优先级 () > not > and > or |
| 赋值运算符 | a += 1 => a = a+1 |
(1) 个别运算符:
优先级最高 ** 幂运算
优先级最低 = 赋值运算符
() 括号可以提升运算优先级
(2) 整体 一元运算符 > 二元运算符
一元运算符: 同一时间,只操作一个值 - ~
二元运算符: 同一时间,操作两个值 + - * / ...
(3) 同一层级
逻辑: () > not > and > or
算数: 乘除 > 加减
位运算符: ( << >> ) > & > ^ > |
(4) 其他运算符
算数运算符 > 位运算符 > 比较运算符 > 身份运算符> 成员运算符 > 逻辑运算符
赋值运算符是最后算完进行赋值,做收尾工作的.
2.4数据的在内存中的缓存机制
2.4.1在同一文件(模块)里,变量存储的缓存机制 (仅对python3.6版本负责)
# -->Number 部分
1.对于整型而言,-5~正无穷范围内的相同值 id一致
2.对于浮点数而言,非负数范围内的相同值 id一致
3.布尔值而言,值相同情况下,id一致
4.复数在 实数+虚数 这样的结构中永不相同(只有虚数的情况例外)
# -->容器类型部分
5.字符串 和 空元组 相同的情况下,地址相同
6.列表,元组,字典,集合无论什么情况 id标识都不同 [空元组例外]
2.4.2不同文件(模块)里,部分数据驻留小数据池中 (仅对python3.6版本负责)
小数据池只针对:int,str,bool,空元祖(),None关键字 这些数据类型有效
#(1)对于int而言
python在内存中创建了-5 ~ 256 范围的整数,提前驻留在了内存的一块区域.
如果是不同文件(模块)的两个变量,声明同一个值,在-5~256这个范围里,
那么id一致.让两个变量的值都同时指向一个值的地址,节省空间。
#(2)对于str来说:
1.字符串的长度为0或者1,默认驻留小数据池
2.字符串的长度>1,且只含有大小写字母,数字,下划线时,默认驻留小数据池
3.用*号得到的字符串,分两种情况。
1)乘数等于1时: 无论什么字符串 * 1 , 都默认驻留小数据池
2)乘数大于1时: 乘数大于1,仅包含数字,字母,下划线时会被缓存,但字符串长度不能大于20
#(3)指定驻留
# 从 sys模块 引入 intern 函数 让a,b两个变量指向同一个值
from sys import intern
a = intern('大帅锅&*^^1234'*10)
b = intern('大帅锅&*^^1234'*10)
print(a is b)
#可以指定任意字符串加入到小数据池中,无论声明多少个变量,只要此值相同,都指向同一个地址空间
2.4.3 缓存机制的意义
无论是变量缓存机制还是小数据池的驻留机制,都是为了节省内存空间,提升代码效率
第三章 数据类型
# ### 数据类型分类:
(1)Number 数字类型 (int float bool complex)
(2)str 字符串类型
(3)list 列表类型
(4)tuple 元组类型
(5)set 集合类型
(6)dict 字典类型
# ### Number数字类型分类:
int : 整数类型 ( 正整数 0 负整数 )
float: 浮点数类型 ( 1.普通小数 2.科学计数法表示的小数 例:a = 3e-5 )
bool: 布尔值类型 ( 真True 和 假False )
complex: 复数类型 ( 声明复数的2种方法 ) (复数用作于科学计算中,表示高精度的数据,科学家会使用)
# ### 容器类型分类:五个
str "nihao"
list [1,2,3]
tuple (6,7,8)
set {
'a',1,2}
dict {
'a':1,'b':2}
3.1整形 (int)
- py2 : int 超出范围 转换为long类型,整形除法只保留整数部分
- py3 :int,整形除法全部保留
3.2布尔值(bool)
- 只有两个值 : Ture/False
- 转换
- 强制转换
- 十种False情况(’’,0,0j,0.0,(),set(),[].{},False,None)
- 强制转换
3.3字符串和相应方法(str)
字符串是写代码中最常见的。按Unicode编码储存。
注意 :字符串本身不可变
# ### 字符串的相关操作
# (1)字符串的拼接 +
strvar = '今天是' + '星期一'
strvar += ',今天非常开心'
print(strvar)
# (2)字符串的重复 *
strvar = '重要的事情说三遍'*3
print(strvar)
# (3) 字符串的跨行拼接
strvar = 'sddfgdsf'\
'多余的几行放在第二行显示'
print(strvar)
# (4) 字符串的索引
# 正向 0 1 2 3
strvar = '12345'
# 逆向 -4 -3 -2 -1
# (5) 字符串的切片: (切片 <=> 截取)
# 1. [开始索引:] 从开始索取到字符串的最后
strvar = '黑夜给了我黑色的眼睛,我去用它寻找光明'
res = strvar [11:]
print(strvar)
# 2. [:结束索引] 从开头截取到结束索引之前(结束索引-1)
res = strvar [:10]
print(strvar)
# 3. [开始索引:结束索引] 从开始索引截取到结束索引之前(结束索引-1)
res = strvar [8:10]
# 4. [开始索引:结束索引:间隔值] 从开始索引截取到结束索引之前按照指定间隔截取字符
# 正序
res = strvar [::3] # 0 3 6 9...
print(res)
# 倒叙
res = strvar[::-1] # -1 -2 -3 -4 ...
print(res)
# 5. [:]或[::] 截取所有字符串
res = [:]
res = [::]
print(res)
- upper 所有字母大写
- isupper 判断是否都是大写
- lower 所有字母小写
- islower 判断是否都是小写
- casefold 更牛逼小写
# 字符串大小写转换
value = "alex,SB"
new_value = value.upper()
new_value = value.lower()
print(value,new_value)
########验证码示例##########
check_code = 'dfIS'
new_code = input('请输入验证码%s:'%(check_code))
if check_code.lower() == new_code.lower():
print('验证成功')
else:
print('验证失败')
- swapcase 字母大小写互换
- count 统计字符串中某个元素的数量
- find 查照某个元素第一次出现的索引位置(未找到返回-1)
strvar = "oh Father this is my Favorate dog"
res = strvar.find("F")
res = strvar.find("F",4)
res = strvar.find("Fav",5,10) # 结束索引本身取不到,取到之前的那个值
print(res)
-
isdecimal 判断是否是纯数字
v1 = '1' v2 = v1.isdecimal() print(v2) -
strip 去除空白、制表符、换行符
-
rstrip:去除右空白
-
lstrip:去除左空白
v = ' alex ' print(v.strip()) v = ' alexe ' print(v.strip(al)) v = ' alex\n' print(v.strip())
-
-
replace('替换的内容,'要替换的内容‘) 替换
-
split(‘根据什么分割’) 将字符串根据什么切割成列表
- .rsplit(’ ',1) 右分割
-
startswith(’ ') 是否以什么为开头
-
endwith(’ ') 是否以什么为结尾
-
ljust 填充字符串,原字符居左 (默认填充空格)
-
rjust 填充字符串,原字符居右 (默认填充空格)
-
center 填充字符串,原字符居中 (默认填充空格)
-
encode 编码转换
date = '你好' # 将‘你好’转换成二进制 content = date.encode('utf-8') -
join(’ ') 将某元素插入列表中去拼接成字符
-
capitalize 字母首字母大写
-
title 每个首字母大写
-
format 字符串格式化
# ### 字符串的格式化
# (1) 顺序传参
strvar = "{}向{}开了一枪,银弹而亡".format('王帆','王盼盼')
print(res)
# (2) 索引传参
strvar = '考试时{1},游戏时{0}'.format{
'唯唯诺诺','重拳出击'}
print(strvar)
# (3)关键字传参
strvar = '{who2}甩了一个飞吻,{who1}神魂颠倒'.format(who1='刘彩霞',who2='马生平')
print(strvar)
# (4)容器类型数据(列表或元组)传参
strvar = '{1[2]}向{0[0]}抛了一个媚眼,鼻血直冒,流血不止'.format(['空想群','朝臣光','宋云杰'],('李亚','孙志和','温子曰)'
print(strvar)
# format 当中,不能使用逆向下标,不识别
strvar = '{group1[2]}向{group2[-1]}抛了一个媚眼,鼻血直冒,流血不止'.format(group1=['空想群','朝臣光','宋云杰'],group2=('李亚','孙志和','温子曰)'
# 如果容器是字典 ,直接写键值,不需要加上引号
strvar = '{group1[kxq]}向{0[0]}抛了一个媚眼,鼻血直冒,流血不止'.format(group={
'kxq:'空想群','ccg':'朝臣光','syj':'宋云杰'},('李亚','孙志和','温子曰)'
print(strvar)
# (5)format的填充符号的使用
'''
^ 原字符串居中
> 原字符串居右
< 原字符串居左
{who:*^10}
who : 关键字参数
* : 要填充的字符
^ : 原字符串居中
10 : 总长度 = 原字符长度 + 填充字符长度
'''
strvar = '{who:*^10}在{where:>>10},{do:!<10}'.format(who='刘鹏',where='电影院',do='看电影')
print(strvar)
# (6) 进制转换等特殊符号的使用(:d :f :s :,)
# :d 整型占位符(要求类型必须是整型)
strvar = '刘子豪昨天买了{:d}个花露水'.format(100)# 100.5 error
print(strvar)
# :2d 占用两位,不够那空格来补,默认居右
strvar =''刘子豪昨天买了{
:2d}个花露水'.format(2)
# < > ^ 调整对应位置
strvar =''刘子豪昨天买了{
:<2d}个花露水'.format(2)
strvar =''刘子豪昨天买了{
:^3d}个花露水'.format(2)
print(strvar)
# :f 浮点型占位符 (要求类型必须是浮点型)
strvar ='刘鑫毕业时,找到的工作薪资是{:f}'.format(2.4)
# :3f 小数保留两位
strvar ='刘鑫毕业时,找到的工作薪资是{:3f}'.format(2.4352)
print(strvar)
# :s 字符串占位符 (要求类型必须是字符串)
strvar = '{:s}'.format{
'今天天气不错,万里无云'}
print(strvar)
# :, 金钱占位符
strvar = '{:,}'.format(123456)
print(strvar)
# 综合案例
strvar = '同学们毕业后的平均年薪是{:.1f},可以在北京买{:d}套房,感觉{:s}'.format(600000.34,1,'棒极了')
print(strvar)
3.4列表(list)
列表是有序可变的。
user = ['李白','杜甫','王勃']
-
修改
# 参考:列表的相关操作 user = ['李白','杜甫','王勃'] user[1]='大哥' print('user') -
append():列表追加元素
user = ['李白','杜甫','王勃'] user.append('傻子') -
insert( ) :指定位置插入元素
-
extend( ) : 循环插入每一个元素
-
count( ): 某个元素在列表中出现的次数
-
remove: 指定元素进行删除,如果多个,默认第一个
-
pop( ):指定位置删除,默认最后一位。
-
clear( ) : 清空
-
reverse( ) : 反转
-
sort ( ) : 从小到大
- sort(reverse=False): 从大到小
-
列表嵌套
user = [123,Ture,[1,2,4],4,"fage","风格"] user[2][2] = 2
3.5元组 (tuple)
元组是有序不可变的
user = ('李白','杜甫','王勃',)
-
无独有功能
-
可以嵌套
#练习题 v1 = 1 v2 = (1) v3 = (1,) print(type(v1),type(v2),type(v3)) <class 'int'> <class 'int'> <class 'tuple'>
3.6集合(set)
可变,无序的,不可重复的
v = {
1,3,5,23,14169,2608295}
#空集合
v = set{
}
- add( ): 添加
- discard( ): 指定删除,不存在不报错
- pop ( ) :随机删除数据
- remove( ) : 指定删除
- update( ) :批量添加
- intersection( ):交集 同 &
- union( ) : 并集 同 |
- difference( ) : 差集 同 -
- symmetric_difference( ) :对称差集(同补集) ^
- issubset( ) : 判断是否是子集 <
- issuperset( ) :判断是否是父集 >
- isdisjoint( ): 判断是否不相交 相交返回False
- 集合嵌套不能包含list、set、dict
- 冰冻集合
# frozenset 可强转容器类数据边为冰冻集合
lst1 = ["王闻",18,"男性","爱好:跑步"]
fz1 = frozenset(lst1)
lst2 = ("王闻","地址:包头","买一辆特斯拉9.9包邮")
fz2 = frozenset(lst2)
print(fz1 , type(fz1))
print(fz2 , type(fz2))
# 不能够在冰冻集合当中添加或者删除元素
# fz1.add(123) error
# 只能 交叉并补
print(fz1 & fz2)
print(fz1 - fz2)
3.7字典(dict)
帮助用户表示一个事务的信息(事物的多个属性)。
字典是无序的,py3.6之后有序。
data = {
name:'alex',age:18,gender:'男'}#键值
-
keys( ) : 获取字典中的所有键组成新的可迭代对象
-
values( ) : 获取字典中所有的值组成新的可迭代对象
-
items( ) : 获取字典中所有的键值对组成元组,组成新的可迭代对象
-
fromkeys: 使用一组键和默认值创建字典
-
get( ):同索引,无返回none
-
clear(): 清空字典
-
update: 批量更新
- 可以修改值,键不能修改;如果不存在就增加
-
pop( ):删除键,键值对一起删除
-
poptiem:删除最后一个键值对
#字符串转换字典 date = "k1|v1,k2|v2,k3|v3" info = { } for i in date.split(","): a,b = i.split("|") info[a] = b print(info)
3.8公共功能
-
len(): 字符串长度(排除:int、bool)
-
索引[]:获取指定位置的子元素(排除:int、bool、set)(字典为键)
#判断输入内容有多少数字 text = input('请输入内容:') count = 0 val = 0 while count <= len(text)-1: lon = text[count] if lon.isdecimal():# 判断真假 val += 1 count += 1 print(val)-
切片[ : ]: 获取范围取指定位置的子元素(排除:int、bool、dict、set)
-
步长[ : : ] : 按照一定间隔获取指定位置的子元素(排除:int、bool、dict、set)
#字符串反转 name = 'alxe' new_name = name[ : : -1] -
for in 循环:(排除:int、bool)(字典为键)
# 判断输入内容中的数字个数 text = input('请输入内容:') count = 0 val = 0 for i in text: if i.isdecimal() == True : val += 1 count += 1 print(val)user = ['李白','杜甫','王勃'] for i in user: for e in i : print(e) -
del :删除(排除:int、bool、str、tuple、set)
-
v1 =[1,2,4,5]
v2 = v1
v3 = v1
v1 =[1,]
# v1 =[1,]
# v2 = [1,2,4,5]
# v3 = [1,2,4,5]
v1 = 'alex'
v2 = v1
v1.upper()
# v1 = ALEX
# v2 = 'alex'
v1 =[1,2,4,5]
v2 = v1
v1.append(3)
print(v1,v2)
# v1 = v2
v1 = [1,2,4,]
v2 = v1
v1[0] = [5,6,4,3]
print(v1,v2)
#[[5, 6, 4, 3], 2, 4] [[5, 6, 4, 3], 2, 4]
v1 = [1,3]
v2 = [1,2,v1]
v1[0] = 2
print(v1,v2)
#[2, 3] [1, 2, [2, 3]]
info_list = []
info = {
}
for i in range(10):
info['user'] = i
info_list.append(info)
print(info, info_list)
# info ={'user': 9}
# info_list =[{'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}, {'user': 9}]
info_list = []
for i in range(10):
info = {
}
info['user'] = i
info_list.append(info)
print(info, info_list)
# info_list = [{'user': 0}, {'user': 1}, {'user': 2}, {'user': 3}, {'user': 4}, {'user': 5}, {'user': 6}, {'user': 7}, {'user': 8}, {'user': 9}]
# info ={'user': 9}
3.9强制转换
当2个不同类型的数据进行运算的时候,默认向更高精度转换
数据类型精度从低到高: bool int float complex
# -->Number部分
int : 整型 浮点型 布尔类型 纯数字字符串
float: 整型 浮点型 布尔类型 纯数字字符串
complex: 整型 浮点型 布尔类型 纯数字字符串 (复数)
bool: ( 容器类型数据 / Number类型数据 都可以 )
# -->容器类型部分
str: ( 容器类型数据 / Number类型数据 都可以 )
list: 字符串 列表 元组 集合 字典
tuple: 字符串 列表 元组 集合 字典
set: 字符串 列表 元组 集合 字典 (注意:相同的值,只会保留一份)
dict: 使用 二级列表,二级元组,二级集合(里面的容器数据只能是元组)
3.9.1字典和集合的注意点
# ###哈希算法
#定义:
把不可变的任意长度值计算成固定长度的唯一值,这个值可正可负,可大可小,但长度固定
该算法叫哈希算法(散列算法),这个固定长度值叫哈希值(散列值)
#特点:
1.计算出来的值长度固定且该值唯一
2.该字符串是密文,且加密过程不可逆
#用哈希计算得到一个字符串的用意?
例如:比对两个文件的内容是否一致?
例如:比对输入的密码和数据库存储的密码是否一致
#字典的键和集合中的值都是唯一值,不可重复:
为了保证数据的唯一性,
用哈希算法加密字典的键得到一个字符串。
用哈希算法加密集合的值得到一个字符串。
如果重复,他们都是后面的替换前面的。自动去重
#版本:
3.6版本之前都是 字典和集合都是无序的
3.6版本之后,把字典的字面顺序记录下来,当从内存拿数据的时候,
根据字面顺序重新排序,所以看起来像有序,但本质上无序
可哈希数据:
可哈希的数据 :Number(int float bool complex) str tuple
不可哈希的数据 : list set dict
3.9深浅拷贝
浅拷贝:只拷贝第一层
深拷贝:拷贝嵌套层次中的所有可变类型
1.capy.capy(): 浅拷贝
2. capy.deepcapy():深拷贝
- str/int/bool:深浅拷贝相同
- list/set/dict
- 不含嵌套时深浅拷贝相同
- 浅拷贝只拷贝第一层,深拷贝所有数据(可变)
v1 = [1,3,5,6]
import copy
v2 = copy.copy(v1)
print(id(v1),id(v2))
v3 = copy.deepcopy(v1)
print(id(v1),id(v3))
第四章 文件操作
4.1 文件操作
f = open('E:\log.txt#要打开的文件路径',mode='r/w/a#读/写/追加',encoding='utf-8#文件原来写入的编码')
content = fi.read()# 读取文件内容
f.write # 写入内容
print(content)
f.close() #关闭文件
# 示例一 用于文字的写入
f = open('a.txt',mode='w',encoding='utf-8')
f.write('你好') #将‘你好’转换成二进制写入到文件
f.close()
# 示例二 用于图片、音频、未知编码
f = open('a.txt',mode='wb')
date = '你好' # 将‘你好’转换成二进制
content = date.encode('utf-8') # 将字符串按照utf-8编码转换成二进制
f.write(content) # 将二进制写入到文件
f.close()
# 示例一
f = open('a.txt',mode='r',encoding='utf-8')
# 将二进制按照encoding编码转换
date = f.read()
f.close()
print(date)
# 示例二
f = open('a.txt',mode='rb')
# 直接读取二进制数据
date = f.read()
f.close()
print(date)
4.2模式:
-
r/w/a(只读只写字符串)
-
r+/w+/a+(可读可写字符串)
-
rb/wb/ab(只读只写二进制)
-
r+/w+/a+(可读可写二进制) a+模式会强制把 光标移到文件的最后.
-
字符串转二进制:
date = '你好' content = date.encode('utf-8') -
二进制转字符串:
date = b'\xe4\xbd\xa0\xe5\xa5\xbd' content = date.dencode('utf-8') -
read
f = open('a.txt',mode='r',encoding='utf-8') date = f.read(1)# 一个字节 f.close() print(date)f = open('a.txt',mode='r') date = f.read(3)# 一个字节 f.close() print(date) -
write
f = open('a.txt',mode='w',encoding='utf-8') f.write('你好') f.close()f = open('a.txt',mode='w') date = '你好'.encoding('utf-8') f.write(date) f.close() print(date) -
seek(光标字节位置)
f = open('a.txt',mode='r',encoding='utf-8') f.seel(1) date = f.read(1)# 一个字节 f.close() print(date) -
tell :获取光标的字节位置
f = open('a.txt',mode='r',encoding='utf-8') f.read(1)# 一个字节 date = f.tell() f.close() print(date) -
flush:把内存中的数据刷到硬盘中
f = open('a.txt',mode='r',encoding='utf-8') while Ture val = input('请输入:') f.write(val) f.flush() v.close() -
readable: 判断文件的对象是否可读
-
writeable : 判断文件的对象是否可写
-
readline : 读取一行文件内容
-
writelines :将内容是字符串的可迭代性数据写入文件中 参数:内容为字符串类型的可迭代数据
'''
参数 > 当前行字符总个数 => 以当前读取
参数 < 当前行字符数总个数 => 以参数的大小来读取字符的个数
默认readline 读取一行
'''
'''
with open('ceshi7.txt',mode='r+',encoding='utf-8')
res =fp.readline(10000)
print(res)
文件对象fp也可以是一个迭代对象
在遍历文件对象的时候,默认一次拿一行
for i in fp:
print(i)
# 在读取所有内容
with open('ceshi7.txt',mode=r+',encoding='utf-8')
#先读取一行
res = fp.readline()
# 判断是不是空
while res :
print(res)
res = fp.readline()
'''
-truncate 把要截取的字符串提取出来.然后清空内容将提取的内容重新写到文件中(字节)
-
关闭文件
with open('a.txt',mode='r',encoding='utf-8') as f1: f1.write() -
文件修改
# 示例一 with open('a.txt',mode='r',encoding='utf-8') as f1: date = f1.read() new_date = date.replace('x','y') with open('a.txt',mode='w',encoding='utf-8') as f2: date = f2.write(new_date) # 示例二 大文件修改 f1 = open('a.txt',mode='r',encoding='utf-8') f2 = open('b.txt',mode='w',encoding='utf-8') #with open('a.txt',mode='r',encoding='utf-8') as f1 and open('b.txt',mode='w',encoding='utf-8') as f2 for line in f1: new_line = line.replace('x','y') f2.write(new_line) f1.close() f2.close()
第五章 函数
5.1三元运算:(三目运算)
v = 前 if 条件 else 后
5.2函数
- 性质:将N行代码拿到别处并给他起个名字,以后通过名字就可以找到这段代码并执行
- 应用场景:
- 代码重复执行
- 代码量特别多可以选择通过函数进行代码分割。
5.3函数的基本结构
函数: 功能(包裹一部分代码,实现某一个功能,达成某个目的)
特点 : 可以反复调用,提高代码的复用性,提高开发效率,便于维护
#函数的定义
def 函数名():
#函数内容
pass
#函数的执行
函数名()
#示例一
def f():
pass
f()
#示例二
def f2(a):
pass
f2(a)
#示例三
def f3(a):
return None
v = f3(a)
#示例四
def f4(a1,a2)
return a1 + a2
v2 = f3(x,y)
[[#函数的命名
字母数字下划线,首字母不能用数字
严格区分大小写,且不能使用关键字
函数命名有意义,且不能使用中文哦
驼峰式命名: (1)大驼峰:每个单词的首字符大写(类:面向对象)
mycar =>Mycar myseek => MyDesk
(2)小驼峰: 除了第一个单词的首字母小写之外,剩下都是大写
mycar => myCar mydesk => myDesk
my_car
#列表求和
def get_sum():
info = [11,22,33,44,55]
content = 0
for i in info:
content = content + i
print(content)
get_sum()
5.4函数的参数
#位置传参 默认传参
def f(a1,a2):
print(a1,a2)
f(1,2)
#关键字传参
def f(a1,a2):
print(a1,a2)
f(a1=1,a2=2)
#俩者可以混和使用,位置传参在前
# 默认函数
def f(a1,a2=2):
print(a1,a2)
f(1)
# 万能参数
def func(*args,**kwargs):
...
func(1,34,5...) # (tuple,dict)
def f(aa):# 形参
y = [1,3,5,4]
print(y[aa])
f(s) #实参
############练习#############
# 计算列表中所有元素的和
def get_list_sum(d):
content = 0
for i in d:
content = content + i #content += i
print(content)
get_list_sum([1,2,3,4,5,6,])
# 将俩个列表拼接起来
def join_lise(v1,v2):
result = []
result.extend(v1)
result.extend(v2)
print(result)
join_list([134,536,42],[48,3,5,6])
5.5函数返回值
- 容器类型数据,
- 类和函数也可以返回
- return 1,2,3 等价于 return (1,2,3) 返回元组
- 默认返回 None
def func(arg):
# ...
return #默认返回None,并终止函数。
val = func(dfa)
#计算用户输入字符中包含'A'的个数,并将a*'你干啥'写入a.txt文件中
def func(a):
content = 0
for i in a:
if i == 'A':
content += 1
return content
def odj(b):
if bool(b)== False:
return False
with open(a.txt,mode='w',encoding='utf-8') as f1:
f.write(b)
return True
count = input('>>>')
sum_content = func(count)
write_odj = sum_content*'你干啥'
date = odj(write_odj)
# result = print('写入成功') if date else print('写入失败')
if date:
print('写入成功')
else:
print('写入失败')
#计算列表中有多少个是数字,并打印出来有多少个数字
# 方法一
def get_list(a):
count = 0
for i in a:
if type(i) == int:
count += 1
date = '列表中有%d个数字'%(count)
return date
content = get_list([1,3,4,'w','rwa',1,4,6,7,'sfdsf'])
print(content)
# 计算一个列表中偶数索引位置的数据构成另外一个列表,并返回
#方法一
def new_list(f1):
info = []
content = 0
for i in f1:
if content % 2 == 0:
info.append(i)
content += 1
return info
result = new_list([1,2,3,4,5,6,7,])
print(result)
#方法二
def new_list2(f1):
info = []
for i in range(0,len(f1)):
if i % 2 == 0:
info.append(f1[i])
return info
result = new_list2([1,2,3,4,5,6,7])
print(result)
#方法三 ***
def new_list3(f1):
v = fi[: : 2]
return v
new_list3(f1)
#读取文件,将文件构造成指定格式,并返回
'''
a.log文件
alxe|123|18
erisc|utuf|19
目标结构
a : ['alxe|123|18', 'erisc|utuf|19']
b :[['alxe','123','18'],['erisc','utuf','19']]
c : [{'name':'alxe','pwd':'123','age':'18'},
{'name':'erisc','pwd':'utuf','age':'19'}
]
'''
####a:
def func():
with open('a.log',mode='r',encoding='utf-8')as f1:
count = f1.read()
date = count.split('\n')
return date
func()
####b:
def func():
with open('a.log',mode='r',encoding='utf-8')as f1:
count = f1.read()
content = []
for i in count.split('\n'):
content.append(i.split('|'))
return content
result = func()
print(result)
####c:
def func():
with open('a.log',mode='r',encoding='utf-8')as f1:
count = f1.read()
content = []
info = {
}
for i in count.split('\n'):
a,b,c = i.split('|')
info['name'] = a
info['pwd'] = b
info['age'] = c
content.append(info)
return content
result = func()
print(result)
5.6作用域
- py文件为全局作用域
- 函数为局部作用域,数据为自己所有,别的访问不到
- 局部变量: 在函数定义的变量(局部命名空间)
- 全局变量: 在函数外部定义的或者使用global在函数内部定义(全局命名空间)
- 作用域: 作用的范围
- 局部变量作用域: 在函数的内部
- 全局变量作用域: 横跨整个文件
生命周期:
内置变量>全局变量>局部变量
- 作用域: 作用的范围
- 相关函数
- global
- nonlocal
#使用global在函数内部修改全局变量
d =100
def func():
global d
d =133
func()
print(d)
#nonlocal 修改局部变量
def outer():
a =100
def inner():
nonlocal a
a = 200
print(a)
inner()
print(a)
outer()
5.7函数的嵌套
def func():
v = 'alex'
def inner()
print(v)
inner()
func()
5.8函数的小高级
# 函数的赋值
def func():
print(123)
v1 = func()
func()
v1()
#函数可以作为变量
def func():
print(123)
func_list = [func,func,func]
func_list[0]()
func_list[1]()
func_list[2]()
# 函数可以当成参数传递
def func(arg);
arg()
def show():
pint(123)
func(show)
# 面试题
def func():
print('话费')
def func2():
print('语音')
def func3():
print('人工')
def func4():
print('套餐')
info = {
'f1':func,
'f2':func2,
'f3':func3
'f4':func4
}
choice = input('请选择功能')
function_name = info.get(choice)
if function_name:
function_name()
else:
print('输入错误')
5.8.2 lambda表达式(匿名函数)
# 用于表达简单的函数
def func(a1,a2):
return a1+a2
# 可以简写为
func1 = lambda a1,a2:a1+a2
func = lambda : 100
func1 = lambda*1:*1*10
func2 = lambda*args,**kwargs:len(arg) + len(kwargs)
#练习题
user_list = []
func = lambda x: user_list.append(x)
v1 = func('alex')
print(v1) # None
print(user_list) #['alex']
5.9内置函数
-
自定义函数
-
内置函数
-
len 长度
-
open 打开文件
-
print
-
range
-
type
-
input
-
eval 将字符串当作python代码执行
-
exec 将字符串当作python代码执行(更牛逼)慎用
-
repr 不转义字符输出字符串 同r
-
hash 生成哈希值
-
编码相关
-
chr 将十进制数字转换unicode编码中的对应字符串ord
-
a = chr(33)
print(a)
- ord将Unicode编码中的对应字符串转换为十进制数字
a = ord('中')
print(a)
# 应用验证码
import random #随机数
date = []
for i in range(5):
v = random.randint(65,90)
date.append(chr(v))
print(''.join(date))
-
高级内置函数
- map 循环每个元素(第二个值),然后让每个元素执行函数(第一个参数),将每个函数执行结果保存到列表,并返回。
# 每个元素增加100 v1 = [1,2,3,4,] result = map(lambda x: x+100, v1) # 第二参数必须是可迭代类型 print(result) # py3为内存地址,py3直接打印- filter 筛选过滤元素 当前数据 Ture保留 False 舍弃 :返回迭代器
# 提取列表中的整数 v1 = [22,44,11,'s','d',425] result = filter(lambda x: type(x) == int,v1) print(list(result))- reduce 集中运算返回一个结果:先把iterable的前两位拿出来,拿到函数中做运算,把计算的结果和iterable中的第三个元素拿到函数中运算,依次类推
import functools v1 = [2,3,5] def func(x,y): return x+y result = functools.reduce(func,v1) print(result) # 方法二 result = functools.reduce(lambda x, y: x+y, v1) print(result) -
数学相关
-
abs 绝对值
-
flaot 浮点型
-
max 最大值
-
min 最小值
-
sum 求和
-
pow( y,x)y的x次方
-
round (,x)保留x位小数(四舍五入)
-
divod 相除得商和余数
-
-
进制转换相关
-
bin 将十进制转换成二进制 b··
-
oct 将十进制转换成八进制 o··
-
int 将其他进制转换成十进制
int(x,base=2/8/16) -
hex 将十进制转换成十六进制 h··
-
# 一个字节等于8位
# IP:198.162.11.175 --->10101010,10001000,.........
############面试题###############
#将IP = '198.162.11.175'转换成二进制,全部连接起来再转换成十进制
IP = '198.162.11.175'
new_list = IP.split('.')
date = []
for i in new_list:
v = bin(int(i))
if len(v) == 10:
date.append(v[2:])
else:
v1 = str((10 - len(v))*0)+ v[2:]
date.append(v1)
result = ''.join(date)
print(int(result,base=2))
5.10函数的中高级
-
函数可以做返回值
-
作为参数转递
def func(): print(1) def bar(): return func v = bar() v()
5.10.1 闭包
-
闭包:如果内函数使用了外函数的局部变量,并且外函数把内函数返回出来的过程,叫做闭包里面的内函数是闭包函数
-
目的:为函数创建一段内存区域(内部变量自己使用),并为其维护数据,以后执行方便使用。(应用场景:装饰器,SQLAchermy源码)
-
特征:内函数使用了外函数的局部变量,那么该变量与闭包函数发生绑定,延长该变量的生命周期
-
闭包的意义:闭包可以优先使用外函数中的变量,并对闭包中的值起到了封装保护的作用.外部无法访问.
def func(name): def inner(): print(name) return inner v1 = func('alex') v1()# 练习一 name = 'alex' def base(): print(name) def func(): name = 'eric' base() func() # alex # 练习二 name = 'alex' def func(): name = 'eric' def base(): print(name) base() func() # eric # 练习三 name = 'alex' def func(): name = 'eric' def base(): print(name) return base date = func() date() # eric#################面试题################ info = [] def func(): print(item) for item in range(10): info.append(func) info[0]() # 9 info = [] def func(i) def inner(): print(i) return inner for item in range(10): info.append(func(item)) info[0]() info[1]() info[3]() # 0 1 3
5.11装饰器
- 在不改变原函数内部代码的基础上,在函数执行前后添加功能。
def func(arg):
def inner():
print('before')
v = arg()
print('after')
return v
return inner()
def new_func():
print('sdf')
return 890
new_func = func()
new_func()
#示例一
'''
v = new_func()
print(v)
'''
# 示例二
'''
v = func(new_func)
result = v
print(result)
'''
# 示例三
'''
new_func = func()
new_func()
'''
# sdf 890
def func(arg):
def inner():
print('before')
v = arg()
print('after')
return v
return inner()
# 第一步,执行函数并将下面的函数参数传递
# 第二步。将函数的返回值重新赋值给下面的函数名
@func
def new_func():
print('sdf')
return 890
v = new_func()
print(v)
- 基本格式
def 外层函数(参数):
def 内层函数(*args,**kwargs):
return 参数(*args,**kwargs)
return 内层函数
@外层函数
def func():
pass
func()
5.12推导式
-
列表推导式
-
格式
v = [val for val in Iterable} # (1) 单循环推推导式 lst = [i*3 for i in lst] print(lst) #(2)带有判断条件的单循环推导式 lst = [i for i in lst if i % 2 == 1] print(lst) #(3) 双循环推导式 lst = [i + j for i in lst1 for j in lst2] print(lst) #(4) 带有判断条件的多循环推导式 lst = [ i + j for i in lst1 for j in lst2 if lst1.index(i) == lst2.index(j) ] print(lst)
-
-
集合推导式
v = {
val for val in Iterable}
- 字典推导式
v = {
k:v for k,v in Iterable}
'''
字典推导式方法枚举:enumerate(iterable,start=0)
功能:枚举,将索引号和iterable中的值,一个一个拿出来配对组成元组放入迭代器中 返回迭代器
参数:
iterable: 可迭代性数据 (常用:迭代器,容器类型数据,可迭代对象range)
start: 可以选择开始的索引号(默认从0开始索引)
返回值:迭代器
'''
lst = ["东邪","西毒","南帝","北丐"]
dic = {
k:v for k,v in enumerate(lst,start=1) }
print(dic)
'''
zip(iterable,...)配对
功能:将多个iterable中的值,一个一个拿到配对组成元组放入到迭代器中 返回迭代器
特征:如果找不到配对的元素,会自动舍弃
'''
迭代器
概念:能被next调用,并不断返回下一个值的对象
特征:不依赖索引,而是通过next指针迭代所有数据,一次只取一个值,大大节省空间
dir :获取类型对象中的所有成员
__tier__方法来判断是否是可迭代数据
__next__方法来判断是否是迭代器
可迭代数据不一定是迭代器:迭代器一定是可迭代数据
调用迭代器:next
一个一个调用,单项不可逆
重置迭代器:iter(迭代器)
数据类型: Iterator 迭代器 Iterable 可迭代对象:
from collections import Iterator,Iterable # 导入模块 res = isinstance(it,Iterator/iterable) 判断真假
5.13 迭代器
- 概念:能被next调用,并不断返回下一个值的对象
- 特征:不依赖索引,而是通过next指针迭代所有数据,一次只取一个值,大大节省空间
- dir :获取类型对象中的所有成员
__tier__方法来判断是否是可迭代数据
__next__方法来判断是否是迭代器 - 可迭代数据不一定是迭代器:迭代器一定是可迭代数据
- 调用迭代器:next,一个一个调用,单项不可逆
- 重置迭代器:iter(迭代器)
- 数据类型: Iterator 迭代器 Iterable 可迭代对象:
from collections import Iterator,Iterable # 导入模块
res = isinstance(it,Iterator/iterable) 判断真假
5.13.2 生成器
- 生成器的本质是迭代器,允许自定义逻辑的迭代器
- 与迭代器的区别:迭代器本身是系统内置的,重写不了,而生成器是用户自定义的,可以重写迭代逻辑
- 创建方式
# 推导式加括号
# 生成器函数 里面含有yield
# yield类似于return
共同点:执行返回值
不同点: yield每次返回时,会记住上次的执行位置,继续向下执行,而return 直接终止函数,每次从头调用
yield from 将一个可迭代对象变成一个迭代器返回
send
与next的区别:next只能取值,send可以取值,可以发送值
send 第一个不能给yield传值,默认None,最后一个yield接受不到send的发送值
5.14 递归函数
-
递归是一去一回的过程,调用函数时,会开辟栈帧空间,函数执行结束之后,会释放栈帧空间,就是不停的开辟和释放栈帧空间的过程,每次开辟栈帧空间,都是独立的一份,其中的资源不共享.(每次调用函数时,在内存中都会单独开辟一个空间,配合函数运行,这个空间叫做栈帧空间)
-
触发回的过程
1.当最后一层栈帧空间全部执行结束的时候,会触底反弹,回到上一层空间的调用处
2.遇到return,会触底反弹,回到上一层空间的调用处 -
写递归时,必须给与递归跳出的条件,否则会发生内存溢出,蓝屏死机的情况.
如果递归层数过多,不推荐使用递归.
# (1) 用递归计算n的阶乘
def jiecheng(n):
if n <= 1:
return 1
return n*jiecheng(n-1)
res = jiecheng(5)
print(res)
'''
尾递归
自己调用自己,并且非表达式
计算的结果要在参数当中完成.
尾递归无论调用多少次函数,都只占用一份空间,但是目前cpython不支持.
'''
def jiecheng(n,endval):
if n <= 1:
return endval
return jiecheng(n-1,endval*n)
res = jiecheng(5,1)
print(res)
第六章 模块
6.1模块(类库)
模块分类:内置模块 /第三方模块/自定义模块
模块 : 类似于py文件或文件夹,注意py2文件中必须有_ inint _.py文件
导入模块:
- import模块 模块. 函数()
- from 模块 import 函数 从…导入…
- from模块 import 函数 as 别名 给导入模块起别名方便调用
- from模块 import * 导入模块全部函数
- 可以设置范围
all=[想要运行的模块名]
- 可以设置范围
- –name-- 魔术属性 如果当前文件时直接运行的,返回__main__
如果当前文件时间接导入的,返回当前文件名(模块名)
6.2 os模块
-
system 在python中执行系统命令
os.system('inconfig') 调用网络信息
-
popen 执行系统命令,返回对象,通过热爱的方法读出字符串,防止报错
-
listdir 获取指定文件夹中所有内容的名称列表
os.listdir('.') 当前文件目录 os.listdir('. .') 上一级文件目录 -
getcwd 获取当前文件所在的默认路径 (单纯的路径)
- file 获取路径加文件
-
chdir 修改当前文件工作的默认路径
-
mknod 创建文件
-
remove 删除文件
-
mkdir 创建文件夹
-
rename 重命名
-
rmdir 删除文件夹
-
makedirs 递归创建文件夹
-
removedirs 递归删除文件夹(文件夹为空)
-
name 获取系统标识
- linux,mac —> posix
- windows —> nt
-
sep 获取路径分隔符
- linux,mac —> /
- windows —> \
6.2.2 os.path 部分
- basename 获取文件名部分
- dirname 获取路径部分
- split 将路径才分成单独的文件部分和路径部分组成元组
- join 将多个路径和文件组成新的路径 可以自动通过不同的系统添加斜杠
- getsize 获取文件大小
- isdir 检测路径是否是文件夹
- isfile 检测路径是否是文件
- islink 检测路径是否是一个连接
- getctime 文件创建时间 linux权限的修改时间(返回时间戳)
- getmtime 获取文件最后一次修改时间(返回时间戳)
- geiatime 获取文件最后一次的访问的时间(返回时间戳)
- exists 检测指定的路径是否存在
- isabs 检测路径是否是绝对路径
- abspath 将相对路径转化位绝对路径
#计算文件大小
import os
pathvar = "/mnt/hgfs/python31_gx/day19/ceshi100"
def func(pathvar):
size = 0
lst = os.listdir(pathvar)
for i in lst:
pathnew =os.path.join(pathvar,i)
if os.path.isfile(pathnew):
size +=os.path.getsize(pathnew)
else:
size+=func(pathvar)
return size
res =func(pathvar)
print(res)
6.3 shutil模块
- copyfileobj 复制文件只复制文件内容
- copyfile 只复制文件内容
- copystat 复制文件所有状态信息,不复制文件内容
- copymode 仅复制文件权限
- copy 复制文件内容和权限
- copy2 复制文件所有信息
- copytree 拷贝文件夹所有内容(递归拷贝)
- rmtree 删除当前文件夹及所有内容(递归删除)
- move 移动文件或者文件夹
# 压缩文件
shutil.make_archive('名称','格式','目录')
#解压文件
shutil.unpaxk_archive('文件名',extract_dir=r'解压到',format='')
6.4math 数学模块 (结果一般为浮点型)
- ceil 向上取整操作
- floor 向下取整操作
- pow 计算一个值的次方
- sqrt 平方开根
- fabs 绝对值
- modf 将一个值拆分成整数和小数形成元组
- copysign 将参数第二数值的正负数拷贝给第一个
- fsum 将一个容器类数据惊醒求和运算
- pi 圆周率 Π
- grd 求两个数字的最大公约数
6.5 random 随机模块
- random 获取随机0~1的小数
- randrange 随机获取指定范围内的整数
- uniform 回去指定范围内的随机小数
- choice 随机获取序列中的值(多选一)
- sample 随机获取序列中的值(多选多)
- shuffle 随机打乱序列中的值
6.6json 模块序列化
-
概念:大多数编程语言都能识别的数据格式,字符串类型
- 把不能够直接储存的数据变得可储存,这个过程叫做序列化
- 反序列化:把文件中的文件数据拿出来,回复称原来的数据类型
- 在文件中存储的数据只能是字符串或者字节流,不能是其他数据类型
-
dumps 序列化字符串
-
loads 反序列化成原来的数据类型
-
一种特殊的字符串 (序列化)
v1 = ['a','adf',1,43,{ 'df':'v3'}] import json v2 = json.dumps(v1)# 序列化 v3 = json.loads(v1)# 反序列化-
如果包含中文
v1 = ['a','adf',1,43,{ 'df':'v3'}] import json v2 = json.dumps(v1,ensure_ascii=False) #想保留中文格式 -
写入目标文件
v1 = ['a','adf',1,43,{ 'df':'v3'}] import json with open('x.txt',mode='w',encoding='utf_8') as f1 v2 = json.load(f1) close(f1)
-
6.7pickle 序列化模块
- 概念:python自己的序列化 ,类型位字节流,可以序列化一切类型
-
pickle模块可以序列化一切数据类型
dumps 可以序列化一切数据
loads 反序列化
dump 把对象序列化写入到文件
load把文件对象中的内容拿出反序列化- 和json的区别:
json序列化之后的数据是str,所有编程语言都识别,但仅限于(int,str,float,bool,list,tuple,dict.None) 数据类型,json不能连续load,只能一次性拿出所有数据,广泛性更强; pickle 序列化之后的数据是bytes,所有数据都可以转化, 但仅限于python之间的存储传输,pickle可以连续load.多套数据放到一个文件
6.8 压缩模块
1.zip
- 压缩文件
import zipfile
#(1)创建压缩包
zf = zipfile.ZipFile('要压缩的文件名','w',ZIP_DEFLATED)
#(2)把文件写入压缩包
zf.write('路径','别名')
#(3)关闭压缩包
zf.close()
- 解压文件
import zipflie
#(1)打开压缩包
zf = zipfile.ZipFile('要打开的压缩文件名'.'r')
#(2)解压文件
#解压单个文件
zf.extarct('文件名','解压后的名字')
#解压所有文件
zf.extractall("解压后的名字")
(3) 关闭压缩包
zf.close()
- 追加文件
with zipfile.ZipFile('压缩文件名','a',zipfile.ZIP_GEFLATED) as zf:
zf.write('文件路径','文件名')
- 查看压缩包
with zipfile.ZipFile('文件名','r',zipflie.ZIPFILETED) as zf:
lst = zf.namelist()
print(lst)
2.tar
-
格式包含
- tar
- tar.gz
- tar.bz2 (最小)
-
压缩文件
import tarflie
#(1)创建压缩包
tf = tarfile.open('要压缩的文件名','w',encoding='utf-8')
#(2)把文件写入压缩包
tf.add('路径','别名')
#(3)关闭压缩包
tf.close()
- 解压文件
import tarflie
#(1)打开压缩包
tf = tarfile.open('要打开的压缩文件名'.'r')
#(2)解压文件
#解压单个文件
tf.extarct('文件名','解压后的名字')
#解压所有文件
tf.extractall("解压后的名字")
(3) 关闭压缩包
tf.close()
- 追加文件
with tarfile.open('压缩文件名','a',encoding='utf-8') as tf:
tf.add('文件路径','文件名')
- 查看压缩包
with zipfile.ZipFile('文件名','r',encoding='utf-8') as tf:
lst = tf.getnames()
print(lst)
#如何处理tarfile不能再已经压缩过的包重追加内容的问题
imort os
path = os.getcwd()
pathvar1 =os.path.join(path.'要追加的文件名)
pathvar2 = os.path.join(path,要解压的文件名)
with tarfile.open(pathvar1,'r',encodin ='utf-8') as tf:
tf.extractall(pathvar2)
mybin = "cp -a /添加到的新路径 " + pathvar2
os.system(mybin)
lst = os.listdir(pathvar2)
with tarfile.open(pathvar1,'w:bz2',encoding='utf-8') as tf:
for i in lst:
if i != 'echo':
pathnew = os.path.join(pathvar2,i)
tf.add(pathnew,i)
6.9 time 时间模块
- time 获取本地时间戳
- localtime 获取本地时间元组(参数是时间戳,默认当地时间)
- mktime 通过元组获取时间戳(参数是时间元组)
- ctime 获取本地时间字符串 (参数是时间按戳,默认当地时间)
- strftime 格式化时间字符串(格式化字符串,时间元组)
- strptime 将时间字符串通过指定格式提取到时间元组中(时间字符串,格式化时间字符串)
- sleep 程序睡眠
import time
#模拟进度条
for i in range(51):
if i > 1:
i = 1
# 打印对应的#号效果
strvar = "#" * int(i)
# %% => %
print("\r[%-50s] %d%%" % (strvar,int(i)) , end="" )
6.10 re 正则表达式
1.findall 把符合正则表达式存在中列表返回
- 字符组[ ] 必须从字符组列举出来的字符当中提取
- 预定义字符集
- \d 匹配数字
- \D 匹配非数字
- \w 匹配字母数字下滑线
- \W 匹配非字母数字下滑线
- \s 匹配任意空白符
- \S 匹配任意非空白符
- \n 匹配换行符
- \t 匹配制表符
- 多个字符匹配
- ? 匹配0个或1个
- + 匹配一个或多个
- * 匹配0个或多个
- {m,n} 匹配m个到n个
- . 匹配任意字符,除了换行符\n
- 贪婪匹配 默认向更多次匹配
- 非贪婪匹配 默认向更少次数匹配 在量词后接?
- \b 边界符
- ^ 匹配字符串必须以…的开始
- $ 匹配字符串必须以…结尾
- () 优先显示括号里的内容
- ?: 取消优先显示括号里的内容
- | 或 (长的在前短的在后)
2.search
- 按照正则表达式,把第一次匹配到的内容返回出来,返回的是对象,能够把匹配到的结果和分组当中的内容显示在同一个界面当中
- 对象.group 返回的是匹配到的结果
- 对象.groups 返回的是括号分组里面的内容
- 如果匹配不到内容,返回的是None ,无法调用group 或者groups方法的
3.其他引用
- 反向引用 \1代表引用第一个括号内容,\2 代表反向引用第二括号内容
- 命名分组:(?P<组名>正则表达式)给这个组起一个名字,(?P=组名) 引用之前组的名字,把该组名匹配到的内容放到当前位置
4.正则函数
- search 通过正则匹配出第一个对象返回,通过group/groups取出对象
返回匹配到的内容,第一个就返回
返回分组里面的内容,类型是元组 - match 验证用户输入的内容,当search函数里面的正则表达式前面加上^ 等价于 math的用法
- split 切割
strvar = "alex|xboyww&wusir%ritian"
res = re.split("[|&%]",strvar)
print(res)
- sub 替换
"""sub(正则,要替换的字符,原字符串[,次数])"""
strvar = "alex|xboyww&wusir%ritian"
res = re.sub("[|&%]","-",strvar)
print(res)
strvar = "alex|xboyww&wusir%ritian"
res = re.sub("[|&%]","-",strvar,2)
print(res)
# subn 替换 (用法和sub一样,区别在于返回的是元组 (结果,次数) )
strvar = "alex|xboyww&wusir%ritian"
res = re.subn("[|&%]","-",strvar)
res = re.subn("[|&%]","-",strvar,1)
print(res)
- finditer 匹配字符串中对应的内容,返回迭代器
from collections import Iterator , Iterable
strvar = "jkasdfjkadfjk1234asfj2342kfa"
it = re.finditer("\d+",strvar)
print(isinstance(it,Iterator))
- compile 指定一个统一的匹配规则
"""
正常情况下,正则表达式编译一次,执行一次.
如果想要编译一次,多次使用的话,使用compile
compile 可以编译一次,终身受益.节省系统的资源
"""
strvar = "jksdjdfsj72343789asdfaj234"
pattern = re.compile("\d+")
print(pattern)
lst = pattern.findall(strvar)
print(lst)
obj = pattern.search(strvar)
print(obj.group())
# ### 正则表达式修饰符
# re.I 使匹配对大小写不敏感
strvar = "72347923489
"
pattern = re.compile(r"(.*?)
",flags=re.I)
obj = pattern.search(strvar)
print(obj)
print(obj.group())
# re.M 使每一行都能够单独匹配(多行),影响 ^ 和 $
strvar = """72347923489
72347923489
72347923489
"""
pattern = re.compile("^<.*?>(?:.*?)<.*?>$",flags=re.M)
lst = pattern.findall(strvar)
print(lst)
# re.S 使 . 匹配包括换行在内的所有字符
strar = """give
1234234234mefive
"""
pattern = re.compile("(.*?)mefive",flags=re.S)
obj = pattern.search(strar)
print(obj)
print(obj.group())
6.11其他模块
-
加密指定字符串
import hashlib def get_md5(date): obj = hashlib.md5('sfer345613'.encode('utf-8')) obj.update(date.encode('utf-8')) result = obj.hexdigest() return result val = get_md5('123') print(val) -
密码不显示
import getpass pwd = getpass.getpass('请输入密码') -
时间
UTC/GMT :世界时间/格林威治时间
本地时间 :本地时间
from datetime import datetime # import datetime v = datetime.now()# 本地时间 v2 = datetime.utcnow()# 获取UTC时间 # datetime格式转换成字符串 val = v1.strftime('%Y-%m-%d %H:%M:%S') #字符串转换成datetime v3 = datetime。strptime('2020-11-31','%Y-%m-%d') # 时间加减 v2 = v1 + timedelte(days=30) -
异常处理
try: val = input('请输入数字:') num = int(val) except Exception as e: print('操作异常')
第七章 面向对象
7.1面向对象的程序开发
# 1.类的定义
class MyClass():
pass
#2.类的实例化
obj =MyClass
- 基本结构
class 类名:
#成员属性
res = '....'
def func():
#成员方法
#类的命名 : 驼峰式
7.2面向对象的三大特征
1.封装
- 概念:对类中成员属性和方法的保护,控制外界对内部成员的访问,修改,删除等操作
- python对成员的保护分为两个等级
私有的: private
在本类内部可以访问,类的外部不可以访问.(python中 属性或者方法前面加上两个下划线__)
公有的: public
在本类的内部和外部都可以访问.
- 公有属性可以在内外都可调用,私有属性只能在内部直接调用
- 访问私有对象方法
- 调用私有成员(不推荐),调用私有属性成员时名字前加上_类名
- 类和对象公有方法,间接找到私有成员,将调用私有成员和方法的命令写道公有方法中,间接找到私有成员
1.1类和对象的相关操作
- 调用对象的方法
对象.成员属性
对象.成员方法 - 在类外添加对象成员的方法
# 1.无参方法
def dahuangfeng():
print("变形! 我是大黄蜂~")
obj.dahuangfeng = dahuangfeng
obj.dahuangfeng()
# 2.有参方法
# 1.基础版
def qingtianzhu(name):
print("请我叫我一柱擎天,简称{}".format(name))
obj.qingtianzhu = qingtianzhu
obj.qingtianzhu("擎天柱")
# 2.升级版
def qingtianzhu(obj,name):
print("请我叫我一柱擎天,简称{},颜色是{}".format(name,obj.color))
obj.qingtianzhu = qingtianzhu
obj.qingtianzhu(obj,"擎天柱")
# 3.究极版 (即使调用类外动态创建的方法,也让系统自己传递obj对象本身)
'''在类外调用自定义方法时,系统不会自动传递obj对象参数'''
import types
def qingtianzhu(obj,name):
print("请我叫我一柱擎天,简称{},颜色是{}".format(name,obj.color))
# MethodType(方法,对象) 把哪个方法和哪个对象绑定到一起,形成绑定方法
obj.qingtianzhu = types.MethodType(qingtianzhu,obj)
obj.qingtianzhu("擎天柱")
- 调用类的方式
类.成员属性
类.成员方法
类中的无参方法只能用类调用 - 类外添加类成员的方法
# 1.无参方法
def fangxiangpan():
print("改造方向盘的方法")
MyCar.fangxiangpan = fangxiangpan
MyCar.fangxiangpan()
# 2.有参方法
def fadongji(engin):
print("动力引擎改成{}".format(engin))
MyCar.fadongji = fadongji
MyCar.fadongji("三缸发动机")
# 3.lambda 表达式
MyCar.luntai = lambda name : print("使用{}的轮胎".format(name))
MyCar.luntai("米其林")
- 类和对象的区别: 对象可以调用类中的成员属性可方法,反过来,类不可以,对象没有修改删除类的权力,类中的无参数函数,对象不可调用
- 删除成员或方法
del 类.方法/成员
del 对象 方法/成员(对象中的)
2.继承
-
单继承:一个类继承另一个类
-
如果一个类继承另一个类,该类叫做子类,被继承叫做父类
class Man(): pass class Human(Man): pass -
多继承:一个类继承多个类
class Man():
pass
class Woman():
pass
class Children(Man,Woman):
pass
- super () 只调用父类的相关公有成员,不会调用本类成员,调用方法时,只调用绑定方法,默认传递参数时本类参数self
- super和self的区别
self调用成员时,先找自己的类是否有该成员,没有在找父类
super() 在调用成员时,只调用父类相关成员 - 菱形继承(钻石继承)
class Human():
pass
class Man(Human):
pass
class woman(Human):
pass
class Children(Man,Human):
pass
#类.mro() 解决复杂的多继承调用顺序关系 返回列表 按照顺序依次调用
#issubclass 判断子父关系
#isinstance 应用在对象和类之间 判断类型
3.单态,多态
- 多态:不同的子类对象,调用相同的父类方法,产生不同的执行结果
class Soldier():
def attack(self):
pass
def back(self):
pass
# 陆军
class Army(Soldier):
def attack(self):
print("[陆军]搏击,ufc,无限制格斗,太极,八卦,占星,制作八卦符")
def back(self):
print("[陆军]白天晨跑10公里,也行800百公里")
# 海军
class Navy(Soldier):
def attack(self):
print("[海军]潜泳水下30个小时,手捧鱼雷,亲自送到敌人的老挝,炸掉敌人的碉堡")
def back(self):
print("[海军]每小时在海底夜行800公里,游的比鲨鱼还快")
# 空军
class AirForce(Soldier):
def attack(self):
print("[空军]空中夺导弹,手撕飞机,在空中打飞机,精准弹幕")
def back(self):
print("[空军]高中跳伞,落地成盒")
# 实例化陆军对象
army_obj = Army()
# 实例化海军对象
navy_obj = Navy()
# 实例化空军对象
af_obj = AirForce()
lst = [army_obj,navy_obj,af_obj]
strvar = """
1.所有兵种开始攻击训练
2.所有兵种开始撤退训练
3.空军练习攻击,其他兵种练习撤退
"""
print(strvar)
num = input("将军请下令,选择训练的种类")
for i in lst:
if num == "1":
i.attack()
elif num == "2":
i.back()
elif num == "3":
if isinstance(i,AirForce):
i.attack()
else:
i.back()
else:
print("将军~ 风太大 我听不见~")
break
- 单态
#一个类,无论实例化多少个对象,都有且只有1个
#优点:节省内存空间,提升执行效率,针对于不要额外对该对象添加成员的场景(比如:mysql增删改查)
# (1) 基本语法
class SingleTon():
__obj = None
def __new__(cls):
if cls.__obj is None:
# 把创建出来的对象赋值给私有成员__obj
cls.__obj = object.__new__(cls)
return cls.__obj
4.魔术方法
- _init_ 构造方法
'''
触发时机:实例化对象,初始化的时候触发
功能:为对象添加成员
参数:参数不固定,至少一个self参数
返回值:无
'''
# (1) 基本语法
class MyClass():
def __init__(self):
print("初始化方法被触发")
# 为当前对象self 添加成员 name
self.name = "袁伟倬"
obj = MyClass()
print(obj.name)
# (2) 带有多个参数的构造方法
class MyClass():
def __init__(self,name):
# self.成员名 = 参数
self.name = name
obj = MyClass("宋云杰") # 在实例化对象时候,给构造方法传递参数
print(obj.name)
- _new_
'''
触发时机:实例化类生成对象的时候触发(触发时机在__init__之前)
功能:控制对象的创建过程
参数:至少一个cls接受当前的类,其他根据情况决定
返回值:通常返回对象或None
'''
# (1)基本语法
class MyClass2():
pty = 100
obj2= MyClass2()
class MyClass():
def __new__(cls):
print(cls)
# 类.方法(自定义类) => 借助父类object创建MyClass这个类的对象
obj = object.__new__(cls)
# (1) 借助父类object创建自己类的一个对象
# return obj
# (2) 返回其他类的对象
# return obj2
# (3) 不返回任何对象
return None
obj = MyClass()
print(obj)
# print(obj.pty)
# (2) __new__ 触发时机快于构造方法
"""
__new__ 用来创建对象
__init__ 用来初始化对象
先创建对象,才能在初始化对象,所以__new__快于__init__
"""
class Boat():
def __new__(cls):
print(2)
return object.__new__(cls)
def __init__(self):
print(1)
obj = Boat()
# (3) __new__ 和 __init__ 参数一一对应
# 单个参数的情况
class Boat():
def __new__(cls,name):
return object.__new__(cls)
def __init__(self,name):
self.name = name
obj = Boat("友谊的小船说裂开就裂开")
print(obj.name)
- _del_ 析构方法
'''
触发时机:当对象被内存回收的时候自动触发[1.页面执行完毕回收所有变量 2.所有对象被del的时候]
功能:对象使用完毕后资源回收
参数:一个self接受对象
返回值:无
'''
import os
class ReadFile():
def __new__(cls,filename):
if os.path.exists(filename):
return object.__new__(cls)
else:
return print("该文件是不存在的")
def __init__(self,filename):
# 打开文件
self.fp = open(filename,mode="r+",encoding="utf-8")
def readcontent(self):
# 读取文件
return self.fp.read()
def __del__(self):
# 关闭文件
self.fp.close()
obj = ReadFile("属性_反射.md")
- _str_/_repr_
'''
触发时机: 使用print(对象)或者str(对象)的时候触发
功能: 查看对象
参数: 一个self接受当前对象
返回值: 必须返回字符串类型
'''
class Cat():
gift = "小猫咪会卖萌求猫粮,小猫咪抓老鼠"
def __init__(self,name):
self.name = name
def __str__(self):
return self.cat_info()
def cat_info(self):
return "小猫咪的名字是{},小猫咪{}元".format(self.name,5000)
# __repr__ = __str__
tom = Cat("汤姆")
# 方法一. print(对象)
# print(tom)
# 方法二. str(对象)
res = str(tom)
print(res)
- _call_
'''
触发时机:把对象当作函数调用的时候自动触发
功能: 模拟函数化操作
参数: 参数不固定,至少一个self参数
返回值: 看需求
'''
# (1) 基本用法
class MyClass():
a = 1
def __call__(self):
print("call魔术方法被触发了")
obj = MyClass()
obj()
# (2) 模拟内置int 实现相应的操作
import math
class MyInt():
def calc(self,num,sign=1):
# 去掉左边多余的0
strvar = num.lstrip("0")
# 为了防止都是0 ,如果去掉之后为空,返回0
if strvar == "":
return 0
# 正常情况下,执行存数字字符串变成数字 , 在乘上相应的符号,得出最后的结果
return eval(strvar) * sign
def __call__(self,num):
if isinstance(num , bool):
if num == True:
return 1
elif num == False:
return 0
elif isinstance(num,int):
return num
elif isinstance(num,float):
# 方法一
"""
strvar = str(num)
lst = strvar.split(".")
return eval(lst[0])
"""
# 方法二
"""
if num >= 0:
return math.floor(num)
else:
return math.ceil(num)
"""
return math.floor(num) if num >= 0 else math.ceil(num)
elif isinstance(num,str):
if (num[0] == "+" or num[0]== "-") and num[1:].isdecimal():
if num[0] == "+":
sign = 1
else:
sign = -1
return self.calc(num[1:],sign)
elif num.isdecimal():
return self.calc(num)
else:
return "老铁,这个真算不了"
myint = MyInt()
# myint(5) => 5
# myint(3.14) => 3
res = myint(True)
print(res)
- _bool_
'''
触发时机:使用bool(对象)的时候自动触发
功能:强转对象
参数:一个self接受当前对象
返回值:必须是布尔类型
'''
"""
类似的还有如下等等(了解):
__complex__(self) 被complex强转对象时调用
__int__(self) 被int强转对象时调用
__float__(self) 被float强转对象时调用
...
"""
class MyClass():
def __bool__(self):
return False
obj = MyClass()
res = bool(obj)
print(res)
- _add_ 魔术方法 (与之相关的_radd_ 反向加法)
'''
触发时机:使用对象进行运算相加的时候自动触发
功能:对象运算
参数:二个对象参数
返回值:运算后的值
'''
'''
类似的还有如下等等(了解):
__sub__(self, other) 定义减法的行为:-
__mul__(self, other) 定义乘法的行为:
__truediv__(self, other) 定义真除法的行为:/
...
'''
class MyClass1():
def __init__(self,num):
self.num = num
# 对象在加号+的左侧时,自动触发
def __add__(self,other):
# print(self)
# print(other)
return self.num + other # return 10 + 7 = 17
# 对象在加号+的右侧时,自动触发
def __radd__(self,other):
# print(self)
# print(other)
return self.num * 2 + other
# 第一种
a = MyClass1(10)
res = a + 7
print(res)
# 第二种
b = MyClass1(5)
res = 20 + b
print(res)
# 第三种
res = a+b
print(res)
- _len_
'''
触发时机:使用len(对象)的时候自动触发
功能:用于检测对象中或者类中成员的个数
参数:一个self接受当前对象
返回值:必须返回整型
'''
'''
类似的还有如下等等(了解):
__iter__(self) 定义迭代容器中的元素的行为
__reversed__(self) 定义当被 reversed() 调用时的行为
__contains__(self, item) 定义当使用成员测试运算符(in 或 not in)时的行为
...
'''
# len(obj) => 返回类中自定义成员的个数
class MyClass():
pty1 = 1
pty2 = 2
__pty3 = 3
pyt3 =10
pty100 = 90
def func1():
pass
def __func2():
pass
def __func3():
pass
def __len__(self):
lst = []
dic = MyClass.__dict__
# 方法一
"""
# print(MyClass.__dict__)
# print(object.__dict__)
dic = MyClass.__dict__
for i in dic:
if not(i.startswith("__") and i.endswith("__")):
lst.append(i)
return len(lst)
"""
# 方法二
lst = [i for i in dic if not(i.startswith("__") and i.endswith("__"))]
return len(lst)
obj = MyClass()
print(len(obj))
- 与类相关的魔术属性
- _dict_ 获取对象或类的内部成员结构
- _doc_ 获取对象或类的内部文档
- _name_ 获取类名函数名
- _class_ 获取当前对象所属的类
- __bases__获取一个类直接继承的所有父类,返回元组
7.3装饰器
# ### 装饰器
"""
装饰器 : 为原函数去扩展新功能,用新函数去替换旧函数
作用 : 在不改变原代码的前提下,实现功能上的扩展
符号 : @(语法糖)
"""
# 1.装饰器的基本用法
def kuozhan(func):
def newfunc():
print("厕所前,蓬头垢面")
func()
print("厕所后,精神抖擞")
return newfunc
def func():
print("我是宋云杰")
func = kuozhan(func) # func = newfunc
func() # newfunc()
# 2.@符号的使用
"""
@符号作用:
(1) 可以自动把@符号下面的函数当成参数传递给装饰器
(2) 把新函数返回,让新函数去替换旧函数,以实现功能上的扩展(基于原函数)
"""
def kuozhan(func):
def newfunc():
print("厕所前,牛头马面")
func()
print("厕所后,黑白无常")
return newfunc
@kuozhan
def func():
print("我是高雪峰")
func()
# 3.装饰器的嵌套
print("<===============================>")
def kuozhan1(func):
def newfunc():
print("厕所前,人模狗样1")
func()
print("厕所后,斯文败类2")
return newfunc
def kuozhan2(func):
def newfunc():
print("厕所前,洗洗手3")
func()
print("厕所后,簌簌口4")
return newfunc
@kuozhan2
@kuozhan1
def func():
print("我是葛龙0")
func()
# 4.用装饰器扩展带有参数的原函数
print("<========================>")
def kuozhan(func):
def newfunc(who,where):
print("厕所前,萎靡不振")
func(who,where)
print("厕所后,兽性大发")
return newfunc
@kuozhan
def func(who,where):
print("{}在{}解手".format(who,where))
func("孙致和","鸟窝")
# 5.用装饰器扩展带有参数和返回值的原函数
print("<========================>")
def kuozhan(func):
def newfunc(*args,**kwargs):
print("厕所前,饥肠辘辘")
res = func(*args,**kwargs)
print("厕所后,酒足饭饱")
return res
return newfunc
@kuozhan
def func(*args,**kwargs):
lst = []
dic = {
"gaoxuefeng":"高雪峰","sunzhihe":"孙致和","gelong":"戈隆"}
# 解手的地点遍历出来
for i in args:
print("拉屎的地点:",i)
for k,v in kwargs.items():
if k in dic:
strvar = dic[k] + "留下了" + v + "黄金"
lst.append(strvar)
return lst
lst = func("电影院","水下",gaoxuefeng = "15g",sunzhihe = "15顿",gelong="15斤")
print(lst)
# 6.用类装饰器来拓展原函数
print("<========================>")
class Kuozhan():
def __call__(self,func):
return self.kuozhan2(func)
def kuozhan1(func):
def newfunc():
print("厕所前,老实巴交")
func()
print("厕所后,咋咋乎乎")
return newfunc
def kuozhan2(self,func):
def newfunc():
print("厕所前,唯唯诺诺")
func()
print("厕所后,重拳出击")
return newfunc
# 方法一
""""""
obj =Kuozhan()
@Kuozhan.kuozhan1
def func():
print("厕所进行中....")
# func()
# 方法二
@Kuozhan() # @obj => obj(func)
def func():
print("厕所进行中....")
func()
# 7.带有参数的函数装饰器
def outer(num):
def kuozhan(func):
def newfunc1(self):
print("3")
func(self)
print("4")
def newfunc2(self):
print("1")
func(self)
print("2")
if num == 1:
return newfunc1
elif num == 2:
return newfunc2
elif num == 3:
# 把func3方法变成属性
return "我是女性"
return kuozhan
class MyClass():
@outer(1) # => (1) kuozhan(func1) => newfunc1 (2) 发动技能做替换 func1 = newfunc1
def func1(self):
print("向前一小步,文明一大步")
@outer(2) # => (2) kuozhan(func2) => newfunc2 (2) 发动技能做替换 func2 = newfunc2
def func2(self):
print("来也冲冲,去也冲冲")
@outer(3) # => (3) kuozhan(func3) => "我是女性" (2) 发动技能做替换 func3 = "我是女性"
def func3(self):
print("尿道外面,说明你短")
obj = MyClass()
obj.func1() # <=> newfunc1
obj.func2()
# obj.func3() error
print(obj.func3)
print(MyClass.func3)
# 8.带有参数的类装饰器
class Kuozhan():
money = "贵族厕所,每小时1000元,贵族厕所欢迎您来,欢迎您再来"
def __init__(self,num):
self.num = num
def __call__(self,cls):
if self.num == 1:
return self.newfunc1(cls)
elif self.num == 2:
return self.newfunc2(cls)
def ad(self):
print("贵族茅厕,茅厕中的百岁山")
def newfunc1(self,cls):
def newfunc():
# 为当前cls这个类,添加属性
cls.money = Kuozhan.money
# 为当前cls这个类,添加方法
cls.ad = Kuozhan.ad
return cls()
return newfunc
def newfunc2(self,cls):
def newfunc():
# 判断run成员是否在类当中
if "run" in cls.__dict__:
# 调用类中的方法,得到对应的返回值
res = cls.run()
# 把返回值重新赋值到run属性上
cls.run = res# cls.run = "亢龙有悔"
return cls()
return newfunc
# 参数1
@Kuozhan(1)
class MyClass():
def run():
return "亢龙有悔"
obj = MyClass()
print(obj.money)
obj.ad()
# 参数2
@Kuozhan(2)
class MyClass():
def run():
return "亢龙有悔"
obj = MyClass()
print(obj.run)
7.4面向对象中的方法
- 普通方法:有参或者无参,如果是无参,只能类来调用
- 绑定方法:(1) 绑定到对象(自动传递对象参数) (2) 绑定到类(自动传递类参数)
- 静态方法: 无论是对象还是类,都可以调用此方法,而不会默认传递任何参数;
class Cat():
name = "tom"
# 普通方法
def mai_meng():
print("小猫会卖萌")
# 绑定方法(对象)
def attack(self):
print("小猫会卅(sua)人")
# 绑定方法(类)
@classmethod
def youmi(cls):
print(cls)
print("可以放大招,伤害最高")
# 静态方法
@staticmethod
def jump(a,b,c,d,e):
print("小猫会上树,抓老鼠")
obj = Cat()
# 普通方法 (无参方法只能类调用)
Cat.mai_meng()
# obj.mai_meng() error
# 绑定方法(对象)
obj.attack()
Cat.attack(obj)
# 绑定方法(类)
"""对象和类都可以调用绑定到类的方法 推荐使用类来调用"""
Cat.youmi()
obj.youmi()
# print(obj.__class__)
# 静态方法
obj.jump()
Cat.jump()
7.5 property
"""
property 可以把方法变成属性使用
作用: 控制属性的获取,修改,删除等操作
变向的增加成员的安全性,可以通过自定义的逻辑进行控制
自动触发 : 要求名字相同,同一个名字
获取@property
设置@属性名.setter
删除@属性名.deleter
"""
# 写法一
class MyClass():
def __init__(self,name):
self.name = name
@property
def username(self):
# return self.name
pass # 不获取
@username.setter
def username(self,val):
# 在触发时:val = 朴飘乐 self就是本对象
# self.name = val
pass # 不设置
@username.deleter
def username(self):
# print("删除方法被触发...")
# del self.name
pass # 不删
obj = MyClass("朴一生")
# 获取属性
print(obj.username)
# 设置属性
obj.username = "朴飘乐"
# 获取属性
print(obj.username)
# 删除属性
del obj.username
# 获取属性
print(obj.username)
# 写法二
class MyClass():
def __init__(self,name):
self.name = name
# 获取方法
def get_username(self):
return self.name
# pass # 不获取
# 设置方法
def set_username(self,val):
self.name = val
# pass # 不获取
# 删除方法
def del_username(self):
# del self.name
pass
# property(获取方法,设置方法,删除方法)
username = property(get_username,set_username,del_username)
obj = MyClass("朴仁猛")
# 获取操作
print(obj.username) # 自动触发get_username方法
# 设置操作
obj.username = "pdd" # 自动触发set_username方法
# 获取操作
print(obj.username)
# 删除操作
del obj.username # 自动触发del_username方法
# 获取操作
print(obj.username)
7.6异常处理
- 异常处理
IndexError :超出索引范围
KeyError:字典中查找一个不存在的关键字
NameError:尝试访问一个不存在的变量
IndentationError:缩进错误
AttributeError:尝试访问未知的对象属性
StopIteration:迭代器没有跟多的值
AssertionError: 断言语句(assert)失败 - 异常处理语法
(1)try:
可能会出先异常的代码
except:
出现异常执行代码
(2)except + 异常错误类 特指发生在这类异常错误时,要执行的分支
其他写法:
(3)try … finally… 不论正确与否,都执行finally后的代码
(4)try … except … else… 如果没异常执行else后的代码
(5)for/while … else 当循环遇到break终止时,不执行else - 主动抛出异常 raise
基本语法:
try:
raise (BasseException)
except (BaseException):
pass
第八章 数据库
mysql命令
-
mysql -u用户名 -p密码 -h地址ip
-
\p exit 退出
-
select user()查询当前用户
-
set password = password(‘123456’) 设置密码
-
ifconfig|ipconfig 查询网络连接状态(Linux|windows)
-
创建
- create user ‘用户名’@‘地址’ identified by ‘密码’ :创建根据ip设置某个用户和密码
- create user ‘用户名’@’%’ identified by ‘密码’ :所有ip都可以登录到服务器数据库中
- create database 数据库名 charset utf8 :创建数据库
- user 数据库名 操作数据表 选择数据库
- create table 表名(id int,name char) 创建数据表
- insert into 表名(id,name) values(1,‘asdboy’) 数据表中插入数据
- insert into values(2,‘xboy2’),(3,'xboy3) … 插入多条数据 默认插入
- insert into 表名(name) values(‘xboy5’) 指定单个插入数据
-
查看
-
show databases 查看数据库
-
show create database 数据库名 :产看创建的数据库
-
show tables 产看所有数据表
-
show creat table 表名 :查看建表语句
-
desc 表名 查看表结构
-
select * from 表名 查看数据表中所有数据
-
select id from 表名 产看一项数据
-
-
-
-
改变
- alter database 数据库名 charset gbk : 更改数据库编码
- alter table 表名 modify name char(5) 改变数据类型
- alter table 表名 change name newname char(4) 字段名和类型一起变
- alter table 表名 add age int 添加字段
- alter table 表名 drop column age 删除字段 列
- alter table 表名 rename 新名 改表名
- update 表名 set name =‘veror’ where id = 1 根据where 条件更换数据 不写where会全部更换
- concat 拼接任意长度的字符串
- alter database 数据库名 charset gbk : 更改数据库编码
-
删除
-
drop database 数据库名 删除数据库
-
drop table 表名 删除数据表
-
delete from 表名 where id =1 删除指定数据
-
delete from 表名 删除所有数据
-
truncate table 表名 删除数据 重置id
-
-
-
-
flush privileges 刷新权限
-
show grants for ‘用户’@‘ip’ 查询某个用户的权限
- select 查看权限
- insert 插入权限
- update 更新权限
- delete 删除权限
- drop 删除权限
- * 所有权限
常见的数据类型
- 整型
- tinyint 一字节 有符号(-128~127) 无符号 (unsigned) (0~225)yo
- int 四字节 有符号(-21亿~21亿左右) 无符号 (unsigned) (0~23亿左右)
- 浮点型
- float 单精度(255,30)
- double 双精度(255,30)
- decimal 金钱类型 ,使用字符串形式保存小数
- 字符串
- char 字符长度255个
- varchar 字符长度21845个 (总字节数不超过65535)
- char(11)定长 固定开辟11个字符长度的空间
- varchar(11)变长 最多开辟11个字符长度的空间
- text 文本类型 论文,小说,文章…
- enum 枚举 :从列出来的数据中选一个
- set 集合: 从列出的数据当中选多个(自动去重)
- 时间
- date YYY-MM-DD 年月日
- time HH:MM:SS 时分秒
- year YYYY 年份
- datetime YYY-MM-DD HH:MM:SS 年月日 时分秒
- show now() 获取时间
约束
- 对进行编辑的数据进行类型上的限制
- unsigned 无符号
- not null 不为空
- 添加/删除
- alter table 表名 modify 字段 类型 not null
- alter table 表名 modify id int
- 添加/删除
- default 设置默认值
- zerofill 零填充(配合整型int使用)
- auto_increment 自增加一 配合主键使用或unique进行自增
- unique 唯一约束,数据唯一不重复
- 索引:相当字典的目录,通过索引加快查询速度
- UNI 唯一索引 允许插入NULL空值
- PRI主键索引 非空且唯一 在一个表只能有一个主键
- MUL 普通索引
- not null +unique 显示 PRI 联合在一起表达一种唯一性
- 添加/删除
- alter table 表名 add unique(字段)
- alter table 表名 drop index(字段)
- primary key 主键,标记数据的唯一特征(唯一且不为空)
- 添加/删除
- alter table 表名 primary key(字段)
- alter table 表名 primary key
- 添加/删除
- foreign key 外键,把多张表通过一个关联字段字段联合在一起,(这个字段可以外加键)
- 添加/删除
- alter table 表名 add foreign key(classid) references 表名(字段)
- alter table 表名 drop foreign key 字段
- 添加/删除
存储引擎
- 存储数据的结构方式
- show engines 查看所有的存储引擎
- 表级锁:修改表时会自动上锁,其他用户无法修改,不能高并发
- 行级锁: 当修改表中的一条数据,当前数据会被锁定,其他数据可以被更改,速度快,高并发
- 事务处理: 执行sql 语句时必须所有操做全部成功,最终提交数据,否则数据回滚,回dao刚开始没操作的那个状态
- begin 开始事务
- commit 提交数据
- rollback 回滚数据
- MuISAM 支持表级锁(5.6版本前默认存储引擎)
- InnoDB 事务处理 行级锁 外键 (5.6版本前默认存储引擎)
- MEMORY 把数据放在内存中,做一个临时的缓存
- BLACKHOLE 黑洞产生binglog 日志,不产生真实数据用来同步主从数据库的数据,场景发生在多服务器集群中(一主一从,一主多从,主数据库:增删改 从数据库:查)
单表查询
- select … from …
- where 对表中的数据进行过滤筛选
- = > < !=
- and or not
- between and 查询区间
- in 在什么范围内
- 模糊查询 like % _
- like ‘%a’ 匹配以a结尾的字符串
- like ‘a%’ 匹配以a开头的任意长度的字符串
- like ‘%a%’ 匹配含有a字母的任意长度的字符
- like ‘_a’ 个数是两个字符,必须以a结尾
- like ‘a_’ 个数一共是3个字符,必须以a开头
- concat 拼接字段 concat_ws (拼接符号,参数1,参数…) 按照字符拼接字段
- max 最大值
- min 最小值
- avg 平均值
- sum 总和
- group by 子句 分组分类
- by 后面搜什么 select 就搜什么
- having 数据在分组之后,进行二次数据过滤,一般是配合group by 使用,分组之后过滤
- order by 排序,按照什么字段进行排序
- asc 升序:从小到大(默认)
- desc 降序:从大到小
- limit 限制查询条数(数据分页)
- limit m,n 代表从第几条数据进行查询,0代表第一条,n代表第几条
多表查询
- 内连接: (inner join) 两表或者多表满足条件的所有数据查询的出来(两表之间的共有数据)
- 两表查询: select 字段 from 表1 inner join 表2 on 必要的关联的条件
- 多表查询: select 字段 from 表一 inner join 表2 on 必要的关联的条件1 inner join 表3 on 必要的关联条件
- as 起别名
- 外连接
- 左连接(左联查询 left join ) 左表为主 右表为辅 完整查询左表 右表没有填充null
- 右连接(左联查询 right join ) 左表为主 右表为辅 完整查询右表 左表没有填充null
- 全连接
- 表一 union 表二
子查询
- sql语句当中又嵌套了另外一条sql语句,用()括号抱起, 一般应用在from 字符后面(表达一张表),where 子句后面(表达一个条件) , 查询速度从快到慢 : 单表查询 -> 联表速度 -> 子查询
- exists 内层sql 能够查询到数据返回True 外层sql 执行查询语句
- 内层sql 不能查到数据,返回False 外层 sql 不执行查询语句
- 子查询可以单独作为临时数据表,临是数据,临时字段 ,一般用在from where select 子句后面,可以通过查询出来的临时数据和另外的表做一次联表,变成根大的表
Python中操作mysql
-
基本语法
(1)创建连接 import pymysql conn = pymysql.conncet(host='127.0.0.1',user ='root',password='123456', database ='数据库名') (2) 执行游标对象(该对象可以操作数据库增删改查) cursor = conn.sorsor() (3)执行sql语句 sql = 'select * from employee' res = cursor.exrcute(sql) (4) 获取数据 fetchone 获取一条数据 res = cursor.fetchone() res = coursor.fetchone() (5)释放游标对象 cursor.close() (6)关闭连接 conn.close() -
sql注入攻击
#(1)创建一张表 import pymysql user = input('请输入用户名:>>>').strip() pwd = input('请输入密码:>>>').strip() conn = pymysql.connect(host='127.0.0.1',user ='root',password='123456', database ='数据库名') coursor = conn.cursor() sql = 'select * from usr_pwd where ussername = '%s' and pasaword = '%s'' %(user,pwd) res = crusor.executte(sql) if res : print('登陆成功后') else: print('登陆失败') cursor.close() conn.close() ''' 输入时: 任意字符' or 1=1 -- 任意字符 # -- 后面的字符串都会被注释掉, 前面账号虽然是错的 但是 2=2是真的 短路绕开了账号和密码的判断; ''' (2) 使用预处理,提前对sql 语句中的特殊符号进行处理 import pymysql user = input('请输入用户名:>>>').strip() pwd = input('请输入密码:>>>').strip() conn = pymysql.connect(host='127.0.0.1',user ='root',password='123456', database ='数据库名') coursor = conn.cursor() sql = 'select * from usr_pwd where ussername = %s and pasaword = %s' res = crusor.executte(sql,(user,pwd)) if res : print('登陆成功后') else: print('登陆失败') cursor.close() conn.close() -
python操作mysql 增删改查
# pymysql 操作事务处理时,需要commit 提交数据,才会变化,否则rollback.恢复到最初状态 conn.commit() 提交数据 conn.rollback() 回滚数据 excute 一次插入一条 excutemany 一次插入多条import pymysql conn = pymysql.connect(host="127.0.0.1",user="root",password="123456",database="db0826") # 查询数据,默认是元组,可以设置返回的类型为字典 pymysql.cursors.DictCursor cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # cursor=pymysql.cursors.DictCursor #增 sql = 'insert into t1(first_name,last_name,age,sex,money) values(%s,%s,%s,%s,%s)' res = coursor.ececute(sql ,("宋","云杰",30,0,15000)) print(cursor.lastrowid) # 获取最后插入这条数据的id号(针对单跳数据插入) res = cursor.executemany(sql[ ("高","云峰",50,1,16000) , ("戈","隆",80,1,17000) , ("袁","伟倬",120,0,130000) , ("刘","欣慰",150,0,18000) ]) # 针对于多条数据搜最后的id的可以通过倒叙查询id sql = 'select id from t1 order by id desc limit 1' res = cursor.execute(sql) # 获取最后一个id号 print(res) # 删 sql = 'delete from t1 where id = %s' res = cursor.ececult(sql,(3,)) print(res) # 改 sql = 'undate t1 set first_name = %s where id = %s' res = cursor.ececute(sql,('王',4)) print(res) # 查 # fetchone fetchmany fetchall 都是基于上一条数据往下查询 sql = 'select * from t1' res = cursor.execute(sql) print(res)# 总条数 #(1) 获取一条数据fetchone # {'id': 4, 'first_name': '王', 'last_name': '云杰', 'age': 30, 'sex': 0, 'money': 15000.0} res = cursor..fetchone() print(res) #(2) 获取多条数据fetchmany data = cursor.fetchmany() # 默认搜索的是一条数据 date = cursor.fetchmany(3) print(date) """ [ {'id': 6, 'first_name': '高', 'last_name': '云峰', 'age': 50, 'sex': 1, 'money': 16000.0}, {'id': 7, 'first_name': '戈', 'last_name': '隆', 'age': 80, 'sex': 1, 'money': 17000.0}, {'id': 8, 'first_name': '袁', 'last_name': '伟倬', 'age': 120, 'sex': 0, 'money': 130000.0} ] """ for i in data: first_name = row['first_name'] last_name =row['last_name'] age = row['age'] if row['sex'] ==o: sex = '女性' else: sex ='男性' money = row['money'] print("姓:{},名:{},年龄:{},姓名:{},收入:{}".format(first_name,last_name,age,sex,money)) # (3) 获取所有数据(fetchall) data = corsor.fetchall() print(data) #(4) 自定义搜所查询的位置 sql = 'select * from t1 where id >=20' res = cursor.fechone() print(res) # 往前滚 cursor.scroll(-2,mode="relative") res = cursor.fetchone() print(res) # 绝对滚动,, 永远基于第一条数据的位置进行移动 cursor.scroll(0,mode="absolute") print(cursor.fetchone()) cursor.scroll(1,mode="absolute") print(cursor.fetchone()) cursor.scroll(3,mode="absolute") print(cursor.fetchone()) # 往前滚没有数据,超出范围error """ cursor.scroll(-1,mode="absolute") print(cursor.fetchone()) """ # 在进行增删改查时,必须提交数据,才会产生影响. conn.commit() cursor.close() conn.close()
导出数据库
第一部: 先退出数据库
第二部: 切换到对应的路径
mysqldump -uroot -p db0824 > db0824.sql
第三部:
导出所有内容
mysqldump -uroot -p db0824 > db0824.sql
导出单个表
mysqldump -uroot -p db0824 t1 > t1.sql
导入数据库
第一步 : 先创建一个空的数据库
第二部 : 找到sql对应文件目录
第三部 : source 路径/文件
use 数据库
source D:\db0824.sql