python3解析库lxml
阅读目录
1、python库lxml的安装
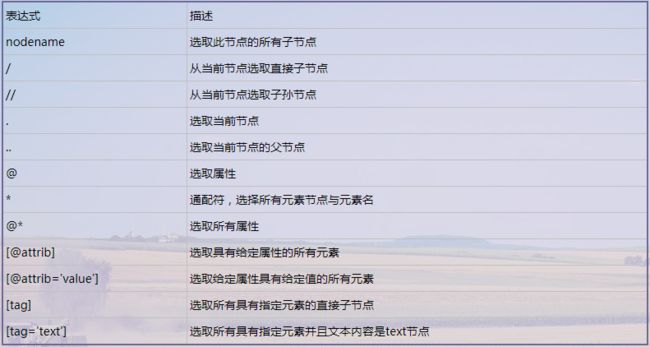
2、XPath常用规则
- 读取文本解析节点
- 读取HTML文件进行解析
- 获取所有节点
- 获取子节点
- 获取父节点
- 属性匹配
- 文本获取
- 属性获取
- 属性多值匹配
- 多属性匹配
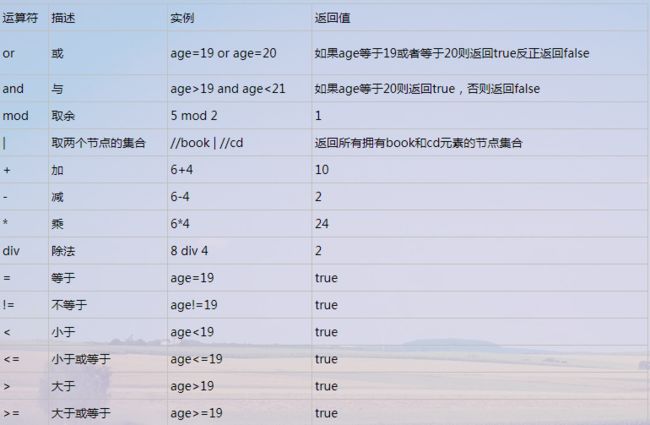
- XPath中的运算符
- 按序选择
- 节点轴选择
- 案例应用:抓取TIOBE指数前20名排行开发语言
lxml是python的一个解析库,支持HTML和XML的解析,支持XPath解析方式,而且解析效率非常高
XPath,全称XML Path Language,即XML路径语言,它是一门在XML文档中查找信息的语言,它最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
XPath的选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以用XPath来选择
XPath于1999年11月16日成为W3C标准,它被设计为供XSLT、XPointer以及其他XML解析软件使用,更多的文档可以访问其官方网站:https://www.w3.org/TR/xpath/
大家如果对Python有兴趣的话关注我点个赞呗。同时我也整理了一些Python的资料提供给大家:Python编程交流QQ群:535686202
1、python库lxml的安装
windows系统下的安装:
#pip安装
pip3 install lxml
#wheel安装
#下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
pip3 install lxml-4.2.1-cp36-cp36m-win_amd64.whl
linux下安装:
yum install -y epel-release libxslt-devel libxml2-devel openssl-devel
pip3 install lxml
验证安装:
$python3
>>>import lxml
2、XPath常用规则
(1)读取文本解析节点
from lxml import etree
text='''
'''
html=etree.HTML(text) #初始化生成一个XPath解析对象
result=etree.tostring(html,encoding='utf-8') #解析对象输出代码
print(type(html))
print(type(result))
print(result.decode('utf-8'))
#etree会修复HTML文本节点
(2)读取HTML文件进行解析
from lxml import etree
html=etree.parse('test.html',etree.HTMLParser()) #指定解析器HTMLParser会根据文件修复HTML文件中缺失的如声明信息
result=etree.tostring(html) #解析成字节
#result=etree.tostringlist(html) #解析成列表
print(type(html))
print(type(result))
print(result)
#
b'\n \n \n - first item
\n - second item
\n - third item
\n - fourth item
\n - fifth item \n
\n \n'
(3)获取所有节点
返回一个列表每个元素都是Element类型,所有节点都包含在其中
from lxml import etree
html=etree.parse('test',etree.HTMLParser())
result=html.xpath('//*') #//代表获取子孙节点,*代表获取所有
print(type(html))
print(type(result))
print(result)
#
[, , , , , , , , , , , , , ]
如要获取li节点,可以使用//后面加上节点名称,然后调用xpath()方法
html.xpath('//li') #获取所有子孙节点的li节点
(4)获取子节点
通过/或者//即可查找元素的子节点或者子孙节点,如果想选择li节点的所有直接a节点,可以这样使用
result=html.xpath('//li/a') #通过追加/a选择所有li节点的所有直接a节点,因为//li用于选中所有li节点,/a用于选中li节点的所有直接子节点a
(5)获取父节点
我们知道通过连续的/或者//可以查找子节点或子孙节点,那么要查找父节点可以使用..来实现也可以使用parent::来获取父节点
from lxml import etree
from lxml.etree import HTMLParser
text='''
'''
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//a[@href="link2.html"]/../@class')
result1=html.xpath('//a[@href="link2.html"]/parent::*/@class')
print(result)
print(result1)
#
['item-1']
['item-1']
(6)属性匹配
在选取的时候,我们还可以用@符号进行属性过滤。比如,这里如果要选取class为item-1的li节点,可以这样实现:
from lxml import etree
from lxml.etree import HTMLParser
text='''
'''
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//li[@class="item-1"]')
print(result)
(7)文本获取
我们用XPath中的text()方法获取节点中的文本
from lxml import etree
text='''
'''
html=etree.HTML(text,etree.HTMLParser())
result=html.xpath('//li[@class="item-1"]/a/text()') #获取a节点下的内容
result1=html.xpath('//li[@class="item-1"]//text()') #获取li下所有子孙节点的内容
print(result)
print(result1)
(8)属性获取
使用@符号即可获取节点的属性,如下:获取所有li节点下所有a节点的href属性
result=html.xpath('//li/a/@href') #获取a的href属性
result=html.xpath('//li//@href') #获取所有li子孙节点的href属性
(9)属性多值匹配
如果某个属性的值有多个时,我们可以使用contains()函数来获取
from lxml import etree
text1='''
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[@class="aaa"]/a/text()')
result1=html.xpath('//li[contains(@class,"aaa")]/a/text()')
print(result)
print(result1)
#通过第一种方法没有取到值,通过contains()就能精确匹配到节点了
[]
['第一个']
(10)多属性匹配
另外我们还可能遇到一种情况,那就是根据多个属性确定一个节点,这时就需要同时匹配多个属性,此时可用运用and运算符来连接使用:
from lxml import etree
text1='''
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[@class="aaa" and @name="fore"]/a/text()')
result1=html.xpath('//li[contains(@class,"aaa") and @name="fore"]/a/text()')
print(result)
print(result1)
#
['second item']
['second item']
(11)XPath中的运算符
(12)按序选择
有时候,我们在选择的时候某些属性可能同时匹配多个节点,但我们只想要其中的某个节点,如第二个节点或者最后一个节点,这时可以利用中括号引入索引的方法获取特定次序的节点:
from lxml import etree
text1='''
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[contains(@class,"aaa")]/a/text()') #获取所有li节点下a节点的内容
result1=html.xpath('//li[1][contains(@class,"aaa")]/a/text()') #获取第一个
result2=html.xpath('//li[last()][contains(@class,"aaa")]/a/text()') #获取最后一个
result3=html.xpath('//li[position()>2 and position()<4][contains(@class,"aaa")]/a/text()') #获取第一个
result4=html.xpath('//li[last()-2][contains(@class,"aaa")]/a/text()') #获取倒数第三个
print(result)
print(result1)
print(result2)
print(result3)
print(result4)
#
['第一个', '第二个', '第三个', '第四个']
['第一个']
['第四个']
['第三个']
['第二个']
这里使用了last()、position()函数,在XPath中,提供了100多个函数,包括存取、数值、字符串、逻辑、节点、序列等处理功能
(13)节点轴选择
XPath提供了很多节点选择方法,包括获取子元素、兄弟元素、父元素、祖先元素等,示例如下:
from lxml import etree
text1='''
'''
html=etree.HTML(text1,etree.HTMLParser())
result=html.xpath('//li[1]/ancestor::*') #获取所有祖先节点
result1=html.xpath('//li[1]/ancestor::div') #获取div祖先节点
result2=html.xpath('//li[1]/attribute::*') #获取所有属性值
result3=html.xpath('//li[1]/child::*') #获取所有直接子节点
result4=html.xpath('//li[1]/descendant::a') #获取所有子孙节点的a节点
result5=html.xpath('//li[1]/following::*') #获取当前子节之后的所有节点
result6=html.xpath('//li[1]/following-sibling::*') #获取当前节点的所有同级节点
#
[, , , ]
[]
['aaa', 'item']
[]
[]
[, , , , , ]
[, , ]
(14)案例应用:抓取TIOBE指数前20名排行开发语言
#!/usr/bin/env python
#coding:utf-8
import requests
from requests.exceptions import RequestException
from lxml import etree
from lxml.etree import ParseError
import json
def one_to_page(html):
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
}
try:
response=requests.get(html,headers=headers)
body=response.text #获取网页内容
except RequestException as e:
print('request is error!',e)
try:
html=etree.HTML(body,etree.HTMLParser()) #解析HTML文本内容
result=html.xpath('//table[contains(@class,"table-top20")]/tbody/tr//text()') #获取列表数据
pos = 0
for i in range(20):
if i == 0:
yield result[i:5]
else:
yield result[pos:pos+5] #返回排名生成器数据
pos+=5
except ParseError as e:
print(e.position)
def write_file(data): #将数据重新组合成字典写入文件并输出
for i in data:
sul={
'2018年6月排行':i[0],
'2017年6排行':i[1],
'开发语言':i[2],
'评级':i[3],
'变化率':i[4]
}
with open('test.txt','a',encoding='utf-8') as f:
f.write(json.dumps(sul,ensure_ascii=False) + '\n') #必须格式化数据
f.close()
print(sul)
return None
def main():
url='https://www.tiobe.com/tiobe-index/'
data=one_to_page(url)
revaule=write_file(data)
if revaule == None:
print('ok')
if __name__ == '__main__':
main()
#
{'2018年6月排行': '1', '2017年6排行': '1', '开发语言': 'Java', '评级': '15.368%', '变化率': '+0.88%'}
{'2018年6月排行': '2', '2017年6排行': '2', '开发语言': 'C', '评级': '14.936%', '变化率': '+8.09%'}
{'2018年6月排行': '3', '2017年6排行': '3', '开发语言': 'C++', '评级': '8.337%', '变化率': '+2.61%'}
{'2018年6月排行': '4', '2017年6排行': '4', '开发语言': 'Python', '评级': '5.761%', '变化率': '+1.43%'}
{'2018年6月排行': '5', '2017年6排行': '5', '开发语言': 'C#', '评级': '4.314%', '变化率': '+0.78%'}
{'2018年6月排行': '6', '2017年6排行': '6', '开发语言': 'Visual Basic .NET', '评级': '3.762%', '变化率': '+0.65%'}
{'2018年6月排行': '7', '2017年6排行': '8', '开发语言': 'PHP', '评级': '2.881%', '变化率': '+0.11%'}
{'2018年6月排行': '8', '2017年6排行': '7', '开发语言': 'JavaScript', '评级': '2.495%', '变化率': '-0.53%'}
{'2018年6月排行': '9', '2017年6排行': '-', '开发语言': 'SQL', '评级': '2.339%', '变化率': '+2.34%'}
{'2018年6月排行': '10', '2017年6排行': '14', '开发语言': 'R', '评级': '1.452%', '变化率': '-0.70%'}
{'2018年6月排行': '11', '2017年6排行': '11', '开发语言': 'Ruby', '评级': '1.253%', '变化率': '-0.97%'}
{'2018年6月排行': '12', '2017年6排行': '18', '开发语言': 'Objective-C', '评级': '1.181%', '变化率': '-0.78%'}
{'2018年6月排行': '13', '2017年6排行': '16', '开发语言': 'Visual Basic', '评级': '1.154%', '变化率': '-0.86%'}
{'2018年6月排行': '14', '2017年6排行': '9', '开发语言': 'Perl', '评级': '1.147%', '变化率': '-1.16%'}
{'2018年6月排行': '15', '2017年6排行': '12', '开发语言': 'Swift', '评级': '1.145%', '变化率': '-1.06%'}
{'2018年6月排行': '16', '2017年6排行': '10', '开发语言': 'Assembly language', '评级': '0.915%', '变化率': '-1.34%'}
{'2018年6月排行': '17', '2017年6排行': '17', '开发语言': 'MATLAB', '评级': '0.894%', '变化率': '-1.10%'}
{'2018年6月排行': '18', '2017年6排行': '15', '开发语言': 'Go', '评级': '0.879%', '变化率': '-1.17%'}
{'2018年6月排行': '19', '2017年6排行': '13', '开发语言': 'Delphi/Object Pascal', '评级': '0.875%', '变化率': '-1.28%'}
{'2018年6月排行': '20', '2017年6排行': '20', '开发语言': 'PL/SQL', '评级': '0.848%', '变化率': '-0.72%'}
大家如果对Python有兴趣的话关注我点个赞呗。同时我也整理了一些Python的资料提供给大家:Python编程交流QQ群:535686202