区块链技术探究——IPFS与Filecoin
最近在研究区块链的相关技术和应用,提到区块链落地项目就不得不提一下可以全球唯一落地并有应用价值的项目——IPFS,与之对应的货币——Filecoin。
本文从技术角度来讲述IPFS理论原理,稍微简述一下Filecoin,大部分资料来自于官网,不会提供挖矿教程,拒绝炒币,从我做起。
1. 一些概念
在讲述之前,首先要介绍一些概念,这些概念能让我们IPFS设计的初衷与思想。
1.1 地址寻址vs内容寻址
去中心化web和中心化web很关键的区别之一就是各自的定位和获取数据的方法不同,以某人让你找一本书为例,简单描述两者区别:
- A会告诉这边书在xxx街道xxx图书馆3楼xx号书架4层上面;
- B会直接这本书的ISBN号为ISBN-XXXXXXXX;
A会告诉你这本书在哪个地址,而B会告诉这边书的编号是什么,至于具体怎么找的就是你自己的事情了;
A这种方式广泛应用于现在的互联网中,例如https://www.puppies.com/beagle.jpg这种形式的URL就很常见,会在某个服务器上面检索beagle.jpg文件。而B这种方式会把内容做一个唯一标识,减少重复内容的文件的存储。如果你学习过计算机密码学相关知识,就会自然的想到哈希(hash),这种转换映射能让文件有个唯一标识,例如bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi是beagle.jpg的哈希值,而告诉你了这个hash值,你就可以在这个web中获取到这文件,至于具体通过什么方式获取?获取效率如何?是不是所有人都可以获取这个文件呢?这就是下面我面要介绍的IPFS所要解决的问题了。
2. IPFS
让我们先来看看官网的IPFS的定义:
IPFS(InterPlanetary File System) is a distributed system for storing and accessing files, websites, applications, and data
IPFS(星际文件系统)是面向全球的存储和获取文件、网站、应用和数据的分布式系统。
首先前缀听起来很高大上——星际,看来公司野心很大哟~~。IPFS的出现是为了取代http,并且核心的设计目标就是去中心化,可以在不受组织管理的任何地方下载一个文件,有了1.1中内容寻址基础知识,我们带着疑问来探究IPFS是如何运作的:
- Q1:怎么标识数据的内容?——A: CID
- Q2:具有数据结构的数据怎么编码?——A: IPLD
- Q3:结构化数据(列表、词典和目录)怎么标识?——A: Merkle DAGs
- Q4:知道了CID,如何在网络中寻找并下载?——A: Libp2p
2.1 CID(content identifier)
首先我们先来看看第一个问题: Q1:怎么标识数据的内容?
2.1.1 哈希映射
CID是内容的标识符,它不会指明这个内容存储在哪边,如图2.1.1.1所示,CID使用了一个密码算法把数据集合或者一个文件映射成为一个固定大小的字节,这边隐射通常是哈希摘要或者简称哈希。

这种加密算法必须满足一下特性:
- 幂等性:相同输入总是输出相同的哈希值;
- 不相关性:输入中微小的改变会产生完全不同的哈希值;
- 不可逆性:根据哈希值不能重新构造数据;
- 唯一性:映射所产生的哈希值是唯一的;
2.1.2 CID构成
CID的构成是一步一步演变的,我们直接说结论,二进制CID的构成如图2.1.2.1所示:

换成文字描述如:
- cid-version:CID的版本号,目前只有
0和1; - multicodec: 指示这个数据的编解码方式是什么,不同的数据有不同的编码方式,这些所有的值在这个表,编解码的值是
IPLD中的值,例如上图的DAG-PB就是其中之一,在2.2中我们会提到IPLD的含义; - multihash-algorithm:采用的哈希算法,常见的哈希算法是
sha2-256,实际的值是18-0x12(十六进制),所有哈希算法的code在这个表中 - multihash-length:哈希值的长度,例如
sha2-256算法的所产生的哈希值为256位,也就是32字节。
以上就是CID的内容组成,由于二进制的CIDs不利用阅读和传播,所以需要一种算法来把二进制串变成可打印的字符串,相信大家也猜了,这种算法就是Base系列编码,所以同样我们也需要一个前缀来表明使用的Base编码算法,如图2.1.2.2所示:

Multbase前缀只会存在于字符串形式的CID中,让我们来看看2个字符串形式的CID,如图2.1.2.3所示:

- 第一样例是
CIDv0版本,因为它以Qm.....开头。所有以Qm开头的哈希值都是采用Base58btc编码的CIDv0版本的CID; - 第二样例开始字符是
b,代表着采用base32编码,默认情况下,大多数IPFS的应用都会使用这种编码;
完整的base编码列表在这个表
2.1.3 CID样例
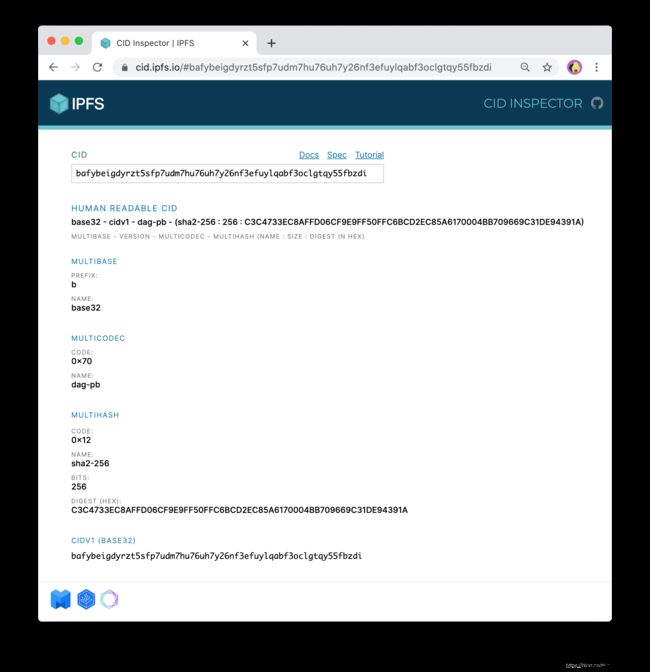
官方提供了工具来查看CID的组成,首先我们看看CIDv0版本的样例:
QmbWqxBEKC3P8tqsKc98xmWNzrzDtRLMiMPL8wBuTGsMnR(可以直接点进链接查看),如图2.1.3.1所示:

CIDv1版本的样例:bafybeigdyrzt5sfp7udm7hu76uh7y26nf3efuylqabf3oclgtqy55fbzdi,如图2.1.3.2所示:
2.2 IPLD(InterPlanetary Linked Data)
接着,我们来看第二个问题: Q2:具有数据结构的数据怎么编码?
2.1章节所讲的CID解决的是一块数据(Block)的标识问题,一个文件或者数据可以由多个块(Blocks)组成,一般来说,数据都是有特定数据结构,也就是结构化数据,特定的数据有了对应的结构才能被解析,包括不同的文件、协议数据等,而IPFS能指向任何的数据,包括程序中的数据。而数据可以由子数据组成,子数据也可以由IPFS所表示,我们直接看一段官方代码样例:
const createPerson = name => Block.encoder({
name }, 'json')
const createGalaxy = async () => {
const mikeal = await createPerson('Mikeal Rogers').cid()
const eric = await createPerson('Eric Myhre').cid()
const volker = await createPerson('Volker Mische').cid()
const elon = await createPerson('Elon Musk').cid()
const galaxy = {
americans: [ eric, mikeal, elon ],
inAmerica: [ mikeal ],
onEarth: [ mikeal, eric, volker ],
onMars: [ elon ]
}
const block = Block.encoder(galaxy, 'dag-cbor')
const cid = await block.cid()
console.log(cid.toString())
}
createGalaxy()
- 首先在我们看一下
createPerson函数,这里面调用了Block.encoder方法来创建了json形式的block; - 然后看一下
createGalaxy函数,这个函数创建了一个对象,这个对象使用了multicodec值为dag-cbor的编解码方式,对我们之前生成的pesron块进行了分类,并指向了相关数据; - 最后看一下这个对象的内容,里面存储的都是指向了具体person的数据,也就是各个person的CID。
{
americans: [ Hash(0003), Hash(0001), Hash(0004) ],
inAmerica: [ Hash(0001) ],
onEarth: [ Hash(0001), Hash(0002), Hash(0003) ],
onMars: [ Hash(0004) ]
}
有了IPLD,我们可以对任何数据进行编解码,数据之间可以相互引用,比较常用的multicodec的有如下,具体可以参考之前提到过的表格:
- git
- bitcoin
- json
- dag-pb
- dag-cbor
- eth
- …
2.3 Merkle DAGs(Directed acyclic graphs)
一般来说一个文件系统除了文件本身以外,还有目录、列表等,自然而然就引出了第三问题Q3:结构化数据(列表、词典和目录)怎么标识?,如图2.3.1为例,下面讲述IPFS如何使用DAGs来表示这种结构:

2.3.1 Merkle DAGs原理
Merkle DAGs其实就是DAGs(Directed acyclic graphs),也就是有向无环图,一个无回路的有向图,文件系统中目录和文件就是有向无环图的具体实例。
在前面的知识我们可以知道CID可以标识一个节点,那通过边来构建节点之间的关联来组成有向无环图。这种特殊的有向无环图被称为Merkle DAGs,之所以使用此方式命名是因为用来纪念首先提出这种结构的研究人员。
构建图2.3.1所述结构的文件需要如下步骤:第一步是构建叶子节点的文件,如图2.3.1.1所示:

每个节点由两部分组成,并对数据进行哈希生成对应的CID:
- filename:文件名称;
- content:文件内容,图片的具体内容;
第二步开始构建中间节点,如图2.3.1.2所示:

相对于叶子节点,中间节点缺少了内容,而有孩子1和孩子2,指向连个2叶子节点.
第三步自下而上构建全部节点,如图2.3.1.3所示:

至此,这个有向无环图完成构建,值得注意的是构建的时候要自下而上构建,任何节点的更改都会导致它的祖先节点生发变更。
2.3.2 Merkle DAGs特性
采用Merkle DAGs有以下三点特性,同样也是优点:
- 可验证性:获得数据以后可以校验对应的
CID,验证内容是否已经被篡改。同时,我们每个节点的CID的值取决于其子节点的CID,所以任意子节点的更改都会导致根节点的CID的值更改。 - 可分发性:大文件或者大文件目录的数据存储可以分发到不同提供者下,现在集中式的数据中心的文件通常是放在同一个服务上面的,而上述例子中5个叶子节点完全可以由5个机器来提供数据。
- 删除重复数据:这个特性也好理解,例如上述图中
baf...7的目录名为cats,我们想要改成dogs的话,只要对baf...7节点进行更改,而不需要重新创建baf...4和baf...5节点。
在2.2 IPLD章节中其实也使用Merkle DAGs来描述数据。两者相辅相成,共同构建了数据生态系统的数据交换基础。
2.3.3 Merkle DAGs实例
打开参考资料5的工具,我们传入一个图片文件(大小约为76KB),选择分块大小为16384 byte(16KB),那么它的Merkle DAGs如图2.3.3.1所示:

不同的分块大小都会组成不同的有向无环图,大家可以尝试一下。
2.4 Libp2p
讲完了数据的编码和结构表示,最后讲一下实际数据的查找和传输,就是第四个问题Q4:知道了CID,如何在网络中寻找并下载?
Distributed hash tables (DHTs)提供了哪些网络节点拥有这个CID,DHT是key-value形式的数据库,每个网络节点都会存储一部分的DHT,所以需要完整遍历所有在IPFS网络中的机器节点。
Libp2p是IPFS生态系统的一个项目,这个项构建了DHT并处理机器节点之间的通信,当然这个项目也可以用于其他分布式系统中。
一旦知道了CID的位置,也就是哪个机器节点存储了这个内容的块,那么需要再次使用DHT来查询对应机器节点的具体IP或者路由。最后Libp2p就会想这些机器节点发送块数据获取请求。
Libp2p是P2P通信的基础,它涵盖了传输、标识、安全、路由、内容发现、消息通知等。在这里就不过多展开,有兴趣可以查询参考资料6.
3. Filecoin和IPFS
在讲Filecoin之前,我们先来看看IPFS的缺陷,目前IPFS已经部署到公网上面,但是公网上的机器节点是不稳定的,不能保证拥有数据的机器节点每时每刻都在线。这时候就需要Filecoin提供的机制来保证存储服务的稳定性。
Filecoin网络中的节点都是IPFS中节点,两者同时使用IPLD数据编码和Libp2p网络通信,但是Filecoin的节点不参与公网IPFS的DHT中。两者结合使用用途如下:
- 使用IPFS内容寻址:通常数据都会存储在自己的IPFS机器节点上,IPFS节点数据通常是热数据,不能保证数据一直可用。
- 使用Filecoin数据持久化,
Filecoin使用经济激励措施来保证数据的持久化,采取的措施如下:- 客户与旷工进行存储数据交易,
Filecoin网络会验证矿工是否正确存储了数据,这些交易会设计到小额的付款; - 不遵守协议规则的矿工会被收到惩罚;
- 旷工分为存储矿工和检索矿工,内容检索服务可以由存储矿工直接提供,也可以由专门的检索矿工提供;
- 客户与旷工进行存储数据交易,
Filecoin这个数字货币和比特币一样也在随着市场的需求而发生价值波动,个人认为Filecoin这个数字货币相对来说实际应用价值还是很高的。
4. IPFS的应用
- 分享/贩卖文件;
- 版本控制;
- 信息交换,例如聊天室等
- 大数据并行分析;
- 利用IPFS构建地图;
- 基于IPFS的虚拟现实;
- 构建CDN网络;
- 降低存储成本;
- 区块链应用
- …
IPFS应用已经趋于成熟,有很多网站和应用都已经开始使用IPFS,大家可下载IPFS Desktop客户端来进行尝试,在这里不过多展开了。
6. 参考资料
[1] IPFS官网
[2] Filecoin官网
[3] ProtoSchool-里面有很多概念的教程,强烈推荐
[4] Thinking in data structures
[5] DAGs工具
[6] Libp2p文档
注意大部分参考资料需要外网才能看哟~