【Python实战】爬取豆瓣排行榜电影数据(含GUI界面版)
项目简介
这个项目源于大三某课程设计。平常经常需要搜索一些电影,但是不知道哪些评分高且评价人数多的电影。为了方便使用,就将原来的项目重新改写了。当做是对爬虫技术、可视化技术的实践了。主要是通过从排行榜和从影片关键词两种方式爬取电影数据。
配置说明
-
打开http://chromedriver.storage.googleapis.com/index.html,根据自己的操作系统下载对应的chromedriver
-
打开当前面目录下的getMovieInRankingList.py,定位到第59行,将
executable_path=/Users/bird/Desktop/chromedriver.exe修改成你自己的chromedriver路径 -
打开pycharm,依次安装以下包
-
pip install Pillow
-
pip install selenium
功能截图
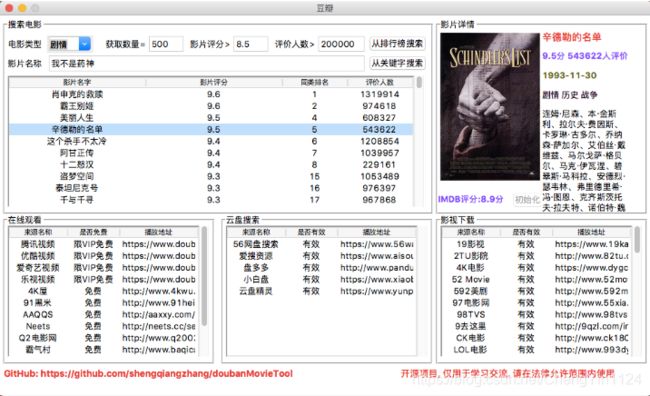
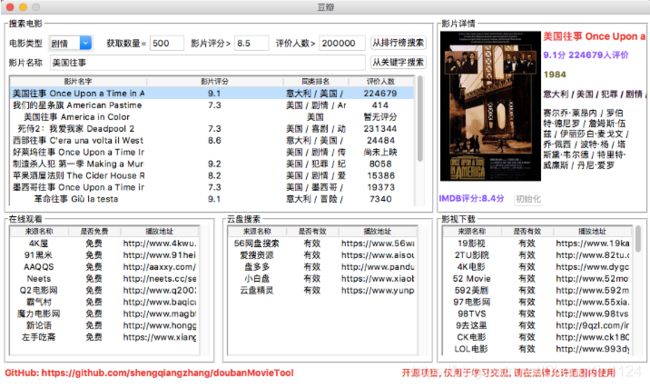
包含功能
- 根据关键字搜索电影
- 根据排行榜(TOP250)搜索电影
- 显示IMDB评分及其他基本信息
- 提供多个在线视频站点,无需vip
- 提供多个云盘站点搜索该视频,以便保存到云盘
- 提供多个站点下载该视频
- 等待更新
存在问题
目前没有加入反爬虫策略,如果运行出现403 forbidden提示,则说明暂时被禁止,解决方式如下:
-
加入cookies
-
采用随机延时方式
-
采用IP代理池方式(较不稳定)


代码:
# -*- coding:utf-8 -*-
from uiObject import uiObject
# main入口
if __name__ == '__main__':
ui = uiObject()
ui.ui_process()
# -*- coding:utf-8 -*-
from ssl import _create_unverified_context
from json import loads
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import tkinter.messagebox
import urllib.request
import urllib.parse
movieData = ' [' \
'{"title":"纪录片", "type":"1", "interval_id":"100:90"}, ' \
' {"title":"传记", "type":"2", "interval_id":"100:90"}, ' \
' {"title":"犯罪", "type":"3", "interval_id":"100:90"}, ' \
' {"title":"历史", "type":"4", "interval_id":"100:90"}, ' \
' {"title":"动作", "type":"5", "interval_id":"100:90"}, ' \
' {"title":"情色", "type":"6", "interval_id":"100:90"}, ' \
' {"title":"歌舞", "type":"7", "interval_id":"100:90"}, ' \
' {"title":"儿童", "type":"8", "interval_id":"100:90"}, ' \
' {"title":"悬疑", "type":"10", "interval_id":"100:90"}, ' \
' {"title":"剧情", "type":"11", "interval_id":"100:90"}, ' \
' {"title":"灾难", "type":"12", "interval_id":"100:90"}, ' \
' {"title":"爱情", "type":"13", "interval_id":"100:90"}, ' \
' {"title":"音乐", "type":"14", "interval_id":"100:90"}, ' \
' {"title":"冒险", "type":"15", "interval_id":"100:90"}, ' \
' {"title":"奇幻", "type":"16", "interval_id":"100:90"}, ' \
' {"title":"科幻", "type":"17", "interval_id":"100:90"}, ' \
' {"title":"运动", "type":"18", "interval_id":"100:90"}, ' \
' {"title":"惊悚", "type":"19", "interval_id":"100:90"}, ' \
' {"title":"恐怖", "type":"20", "interval_id":"100:90"}, ' \
' {"title":"战争", "type":"22", "interval_id":"100:90"}, ' \
' {"title":"短片", "type":"23", "interval_id":"100:90"}, ' \
' {"title":"喜剧", "type":"24", "interval_id":"100:90"}, ' \
' {"title":"动画", "type":"25", "interval_id":"100:90"}, ' \
' {"title":"同性", "type":"26", "interval_id":"100:90"}, ' \
' {"title":"西部", "type":"27", "interval_id":"100:90"}, ' \
' {"title":"家庭", "type":"28", "interval_id":"100:90"}, ' \
' {"title":"武侠", "type":"29", "interval_id":"100:90"}, ' \
' {"title":"古装", "type":"30", "interval_id":"100:90"}, ' \
' {"title":"黑色电影", "type":"31", "interval_id":"100:90"}' \
']'
class getMovieInRankingList:
# typeId 电影类型, movie_count 欲获取的该电影类型的数量, rating 电影的评分, vote_count 电影的评价人数
def __init__(self):
chrome_options = Options()
chrome_options.add_argument('--headless') # 设置为无头模式,即不显示浏览器
chrome_options.add_argument(
'user-agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"') # 设置user=agent
chrome_options.add_experimental_option('excludeSwitches',['enable-automation']) # 此步骤很重要,设置为开发者模式,防止被各大网站识别出来使用了Selenium
chrome_options.add_experimental_option("prefs",{"profile.managed_default_content_settings.images": 2}) # 不加载图片,加快访问速度
try:
self.browser = webdriver.Chrome(executable_path='/Users/bird/Desktop/chromedriver.exe',chrome_options=chrome_options) # 设置chromedriver路径
self.wait = WebDriverWait(self.browser, 10) # 超时时长为10s
except:
print("chromedriver.exe出错,请检查是否与你的chrome浏览器版本相匹配\n缺失chromedriver.exe不会导致从排行榜搜索功能失效,但会导致从关键字搜索功能失效")
# 从排行榜中获取电影数据
def get_url_data_in_ranking_list(self, typeId, movie_count, rating, vote_count):
context = _create_unverified_context() # 屏蔽ssl证书
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36', }
url = 'https://movie.douban.com/j/chart/top_list?type=' + str(
typeId) + '&interval_id=100:90&action=unwatched&start=0&limit=' + str(movie_count)
req = urllib.request.Request(url=url, headers=headers)
f = urllib.request.urlopen(req, context=context)
response = f.read()
jsonData = loads(response) # 将json转为python对象
list = []
for subData in jsonData: # 依次对每部电影进行操作
if ((float(subData['rating'][0]) >= float(rating)) and (float(subData['vote_count']) >= float(vote_count))):
subList = []
subList.append(subData['title'])
subList.append(subData['rating'][0])
subList.append(subData['rank'])
subList.append(subData['vote_count'])
list.append(subList)
for data in list:
print(data)
return list, jsonData
# 从关键字获取电影数据
def get_url_data_in_keyWord(self, key_word):
# 浏览网页
self.browser.get('https://movie.douban.com/subject_search?search_text=' + urllib.parse.quote(
key_word) + '&cat=1002') # get方式获取返回数据
# js动态渲染的网页,必须等到搜索结果元素(DIV中class=root)出来后,才可以停止加载网页
# 等待DIV中class=root的元素出现
self.wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.root')))
dr = self.browser.find_elements_by_xpath("//div[@class='item-root']") # 获取class为item-root的DIV(因为有多个结果)
jsonData = []
list = []
for son in dr:
movieData = {'rating': ['', 'null'], 'cover_url': '', 'types': '', 'title': '', 'url': '',
'release_date': '', 'vote_count': '', 'actors': ''}
subList = ['', '', '', '']
url_element = son.find_elements_by_xpath(".//a") # 获取第一个a标签的url(因为有多个结果)
if (url_element):
movieData['url'] = (url_element[0].get_attribute("href"))
img_url_element = url_element[0].find_elements_by_xpath(".//img") # 获取影片海报图片地址
if (img_url_element):
movieData['cover_url'] = (img_url_element[0].get_attribute("src"))
title_element = son.find_elements_by_xpath(".//div[@class='title']") # 获取标题
if (title_element):
temp_title = (title_element[0].text)
movieData['title'] = (temp_title.split('('))[0]
movieData['release_date'] = temp_title[temp_title.find('(') + 1:temp_title.find(')')]
subList[0] = movieData['title']
rating_element = son.find_elements_by_xpath(".//span[@class='rating_nums']") # 获取评分
if (rating_element):
movieData['rating'][0] = (rating_element[0].text)
subList[1] = movieData['rating'][0]
vote_element = son.find_elements_by_xpath(".//span[@class='pl']") # 获取数量
if (vote_element):
movieData['vote_count'] = (vote_element[0].text).replace('(', '').replace(')', '').replace('人评价', '')
subList[3] = movieData['vote_count']
type_element = son.find_elements_by_xpath(".//div[@class='meta abstract']") # 获取类型
if (type_element):
movieData['types'] = (type_element[0].text)
subList[2] = movieData['types']
actors_element = son.find_elements_by_xpath(".//div[@class='meta abstract_2']") # 获取演员
if (actors_element):
movieData['actors'] = (actors_element[0].text)
jsonData.append(movieData)
list.append(subList)
# 关闭浏览器
self.browser.quit()
for data in list:
print(data)
return list, jsonData
全部源码:
# -*- coding:utf-8 -*-
from PIL import Image, ImageTk
from getMovieInRankingList import *
from tkinter import Tk
from tkinter import ttk
from tkinter import font
from tkinter import LabelFrame
from tkinter import Label
from tkinter import StringVar
from tkinter import Entry
from tkinter import END
from tkinter import Button
from tkinter import Frame
from tkinter import RIGHT
from tkinter import NSEW
from tkinter import NS
from tkinter import NW
from tkinter import N
from tkinter import Y
from tkinter import DISABLED
from tkinter import NORMAL
from re import findall
from json import loads
from threading import Thread
from urllib.parse import quote
from webbrowser import open
import os
import ssl
ssl._create_default_https_context = ssl._create_unverified_context #关闭SSL证书验证
def thread_it(func, *args):
'''
将函数打包进线程
'''
# 创建
t = Thread(target=func, args=args)
# 守护
t.setDaemon(True)
# 启动
t.start()
def handlerAdaptor(fun, **kwds):
'''事件处理函数的适配器,相当于中介,那个event是从那里来的呢,我也纳闷,这也许就是python的伟大之处吧'''
return lambda event, fun=fun, kwds=kwds: fun(event, **kwds)
def save_img(img_url, file_name, file_path):
"""
下载指定url的图片,并保存运行目录下的img文件夹
:param img_url: 图片地址
:param file_name: 图片名字
:param file_path: 存储目录
:return:
"""
#保存图片到磁盘文件夹 file_path中,默认为当前脚本运行目录下的img文件夹
try:
#判断文件夹是否已经存在
if not os.path.exists(file_path):
print('文件夹',file_path,'不存在,重新建立')
os.makedirs(file_path)
#获得图片后缀
file_suffix = os.path.splitext(img_url)[1]
#拼接图片名(包含路径)
filename = '{}{}{}{}'.format(file_path,os.sep,file_name,file_suffix)
#判断文件是否已经存在
if not os.path.exists(filename):
print('文件', filename, '不存在,重新建立')
# 下载图片,并保存到文件夹中
urllib.request.urlretrieve(img_url, filename=filename)
return filename
except IOError as e:
print('下载图片操作失败',e)
except Exception as e:
print('错误:',e)
def resize(w_box, h_box, pil_image):
"""
等比例缩放图片,并且限制在指定方框内
:param w_box,h_box: 指定方框的宽度和高度
:param pil_image: 原始图片
:return:
"""
f1 = 1.0 * w_box / pil_image.size[0] # 1.0 forces float division in Python2
f2 = 1.0 * h_box / pil_image.size[1]
factor = min([f1, f2])
# print(f1, f2, factor) # test
# use best down-sizing filter
width = int(pil_image.size[0] * factor)
height = int(pil_image.size[1] * factor)
return pil_image.resize((width, height), Image.ANTIALIAS)
def get_mid_str(content,startStr,endStr):
startIndex = content.index(startStr)
if startIndex>=0:
startIndex += len(startStr)
endIndex = content.index(endStr)
return content[startIndex:endIndex]
class uiObject:
def __init__(self):
self.jsonData = ""
self.jsonData_keyword = ""
def show_GUI_movie_detail(self):
'''
显示 影片详情 界面GUI
'''
self.label_img['state'] = NORMAL
self.label_movie_name['state'] = NORMAL
self.label_movie_rating['state'] = NORMAL
self.label_movie_time['state'] = NORMAL
self.label_movie_type['state'] = NORMAL
self.label_movie_actor['state'] = NORMAL
def hidden_GUI_movie_detail(self):
'''
显示 影片详情 界面GUI
'''
self.label_img['state'] = DISABLED
self.label_movie_name['state'] = DISABLED
self.label_movie_rating['state'] = DISABLED
self.label_movie_time['state'] = DISABLED
self.label_movie_type['state'] = DISABLED
self.label_movie_actor['state'] = DISABLED
def show_IDMB_rating(self):
'''
显示IDM评分
'''
self.label_movie_rating_imdb.config(text='正在加载IMDB评分')
self.B_0_imdb['state'] = DISABLED
rating_imdb = '未知'
item = self.treeview.selection()
if(item):
item_text = self.treeview.item(item, "values")
movieName = item_text[0] # 输出电影名
for movie in self.jsonData:
if(movie['title'] == movieName):
f = urllib.request.urlopen(movie['url'])
response = (f.read()).decode()
url_imdb = get_mid_str(response, 'IMDb链接: ')
f = urllib.request.urlopen(url_imdb)
data_imdb = (f.read()).decode()
rating_imdb = get_mid_str(data_imdb, '