android搜索框功能实现_【公众号开发】用Serverless实现公众号图文搜索功能
大家都看到了,这是一个全新的公众号,而我,目前也在疯狂的写Serverless架构的各种实战化教程:为什么不拿这个公众号开刀呢?是的,在过去的日子中,我发了两个工程化项目:
- AI_Album:一个Python开发的人工智能相册系统,搭建在Serverless架构上;
- ServerlessBlog:一个Python开发的Serverless博客系统,前台接口是原生开发,后台是一个Flask框架部署在函数计算上。
我为什么要做这样的工程化例子呢?因为我发现,Serverless架构真的很好用,但是最佳实践却很少。尤其是工程化的例子更是少的可怜。做了小程序、做了CMS,我的第三个实践案例就是公众号的开发。
在之前的文章中,已经和大家分享了如何快速简单的上手公众号开发:

今天将和大家在这个基础上,开始第一个模块的开发:文章搜索功能。
首先要说为什么要做文章搜索功能?
因为用户,不知道我们发了什么文章,也不清楚每个文章具体内容,他可能只需要简单的关键词,来看一下这个公众号是否有他想要的东西,例如他搜索:如何上传文件?或者搜索:如何开发Component?这样简单的问题,就可以快速把最相关的历史文章推送给用户,这将会是很方便的一件事情(别管这个是不是伪需求,主要目的是要开发一个有趣的公众号,通过这个公众号的开发,让大家对Serverless架构更加了解和熟悉。)
先简单的来看一下效果图:

是的,通过这样简单的问题描述,找到目标结果,表面上这是一个文章搜索功能,实际上可以把它拓展成是一种“客服系统”。甚至将其升级为一种“聊天系统”,当然这些都是后话。
在上一节课的基础上,我们新增两个函数:
函数1: 索引建立函数
主要功能:通过触发该函数,可以将现有的公众号数据进行整理,并且建立适当的索引文件,存储到COS中。
# -*- coding: utf8 -*-
import os
import re
import json
import random
from snownlp import SnowNLP
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
bucket = os.environ.get('bucket')
secret_id = os.environ.get('secret_id')
secret_key = os.environ.get('secret_key')
region = os.environ.get('region')
client = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key))
def main_handler(event, context):
response = client.get_object(
Bucket=bucket,
Key=event["key"],
)
response['Body'].get_stream_to_file('/tmp/output.txt')
with open('/tmp/output.txt') as f:
data = json.loads(f.read())
articlesIndex = []
articles = {}
tempContentList = [
"_", " ",
"点击Go Serverless关注我们这是一个全新的微信公众号,大家的支持是我分享的动力,如果您觉得这个公众号还可以,欢迎转发朋友圈,或者转发给好友,感谢支持。",
"点击GoServerless关注我们感谢各位小伙伴的关注和阅读,这是一个全新的公众号,非常希望您可以把这个公众号分享给您的小伙伴,更多人的关注是我更新的动力,我会在这里更新超级多Serverless架构的经验,分享更多有趣的小项目。",
]
for eveItem in data:
for i in range(0, len(eveItem['content']['news_item'])):
content = eveItem['content']['news_item'][i]['content']
content = re.sub(r'', '_', content)
content = re.sub(r'<.*?>', '', content)
for eve in tempContentList:
content = content.replace(eve, "")
if "Serverless实践列表" in content:
content = content.split("Serverless实践列表")[i]
desc = "%s。%s。%s" % (
eveItem['content']['news_item'][i]['title'],
eveItem['content']['news_item'][i]['digest'],
"。".join(SnowNLP(content).summary(3))
)
tempKey = "".join(random.sample('zyxwvutsrqponmlkjihgfedcba', 5))
articlesIndex.append(
{
"media_id": tempKey,
"description": desc
}
)
articles[tempKey] = eveItem['content']['news_item'][i]
client.put_object(
Bucket=bucket,
Body=json.dumps(articlesIndex).encode("utf-8"),
Key=event['index_key'],
EnableMD5=False
)
client.put_object(
Bucket=bucket,
Body=json.dumps(articles).encode("utf-8"),
Key=event['key'],
EnableMD5=False
)
这一部分,可能定制化比较多一些,首先是tempContentList变量,这个部分是因为我的很多公众号都会有开始的这样一句话,所以为了建立索引比较准确,我将一些可能影响结果的话去掉。然后我还通过上述代码去掉了code标签里面的内容,因为代码也会影响结果,同时我还去掉了html标签。
原始的文件大概是这样的:

处理好的文件(通过标题+描述+SnowNLP提取的摘要):

然后这些文件存储到COS中:

这一部分的核心就是,正确让我们提取出来的description尽可能的可以准确的描述文章的内容。一般情况下,标题就是文章的核心,但是标题可能有一些信息丢失,例如说文章:【想法】用腾讯云Serverless你要知道他们两个的区别实际上描述的是Plugin和Component的区别,虽然标题知道是两个东西,但是却缺少了核心的目标,所以再加上我们下面的描述:什么是Serverless Framework Plugin?什么是Component?Plugin与Component有什么区别?想要入门Serverless CLI,这两个产品必须分的清楚,本文将会分享这二者区别与对应的特点、功能。当然,加上描述之后内容变得已经相当精确,但是正文中,可能有相对来说更加精准的描述或者额外的内容,所以采用的是标题+描述+摘要(textRank提取出来的前三句,属于提取式文本)。
函数2: 搜索函数
主要功能:当用户向微信号发送了指定关键词,通过该函数获取的结果。
思考:函数1和函数2,都可以集成在之前的函数中,为什么要把函数1和函数2单独拿出来做一个独立的函数存在呢?放在一个函数中不好么?
是这样的,主函数触发次数相对来说是最多的,而且这个函数本身不需要太多的资源配置(64M就够了),而函数1和函数2,可能需要消耗更多的资源,如果三个函数合并放在一起,可能函数的内存大小需要整体调大,满足三个函数需求,这样的话,相对来说会消耗更多资源,例如
主函数触发了10次(64M,每次1S),函数1触发了2次(512M,每次5S),函数2触发了4次(384M,每次3S)
如果将三个函数放在一起,资源消耗是:

如果将其变成三个函数来执行,资源消耗是:

前者总计资源消耗13308,后者10432,随着调用次数越来越多,主函数的调用比例会越来越大,所以节约的资源也就会越来越多,所以此处建议将资源消耗差距比较大的模块,分成不同函数进行部署。
import os
import json
import jieba
from qcloud_cos_v5 import CosConfig
from qcloud_cos_v5 import CosS3Client
from collections import defaultdict
from gensim import corpora, models, similarities
bucket = os.environ.get('bucket')
secret_id = os.environ.get('secret_id')
secret_key = os.environ.get('secret_key')
region = os.environ.get('region')
client = CosS3Client(CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key))
def main_handler(event, context):
response = client.get_object(
Bucket=bucket,
Key=event["key"],
)
response['Body'].get_stream_to_file('/tmp/output.txt')
with open('/tmp/output.txt') as f:
data = json.loads(f.read())
articles = []
articlesDict = {}
for eve in data:
articles.append(eve['description'])
articlesDict[eve['description']] = eve['media_id']
sentence = event["sentence"]
documents = []
for eve_sentence in articles:
tempData = " ".join(jieba.cut(eve_sentence))
documents.append(tempData)
texts = [[word for word in document.split()] for document in documents]
frequency = defaultdict(int)
for text in texts:
for word in text:
frequency[word] += 1
dictionary = corpora.Dictionary(texts)
new_xs = dictionary.doc2bow(jieba.cut(sentence))
corpus = [dictionary.doc2bow(text) for text in texts]
tfidf = models.TfidfModel(corpus)
featurenum = len(dictionary.token2id.keys())
sim = similarities.SparseMatrixSimilarity(
tfidf[corpus],
num_features=featurenum
)[tfidf[new_xs]]
answer_list = [(sim[i], articles[i]) for i in range(1, len(articles))]
answer_list.sort(key=lambda x: x[0], reverse=True)
result = []
print(answer_list)
for eve in answer_list:
if eve[0] > 0.10:
result.append(articlesDict[eve[1]])
if len(result) >= 8:
result = result[0:8]
return {"result": json.dumps(result)}
这一部分的代码也是很简单,主要是通过文本的相似度对每个文本进行评分,然后按照评分从高到低进行排序,给定一个阈值(此处设定的阈值为0.1),输出阈值之前的数据。
另外这里要注意,此处引用了两个依赖是jieba和gensim,这两个依赖都可能涉及到二进制文件,所以强烈推荐在CentOS系统下进行打包。当然,如果没有CentOS的小伙伴也可以尝试我的打包工具:

(小声BB:我是MacOS,我就是在自己做的这个网页上打包之后,下载到本地,放进去的,完美,自己做的东西先满足了自己的需求,嘻嘻)
接下来就是主函数中的调用,为了实现上述功能,需要在主函数中新增方法:
1: 获取全部图文消息
def getTheTotalOfAllMaterials():
'''
文档地址:https://developers.weixin.qq.com/doc/offiaccount/Asset_Management/Get_the_total_of_all_materials.html
:return:
'''
accessToken = getAccessToken()
if not accessToken:
return "Get Access Token Error"
url = "https://api.weixin.qq.com/cgi-bin/material/get_materialcount?access_token=%s" % accessToken
responseAttr = urllib.request.urlopen(url=url)
return json.loads(responseAttr.read())
def getMaterialsList(listType, count):
'''
文档地址:https://developers.weixin.qq.com/doc/offiaccount/Asset_Management/Get_materials_list.html
:return:
'''
accessToken = getAccessToken()
if not accessToken:
return "Get Access Token Error"
url = "https://api.weixin.qq.com/cgi-bin/material/batchget_material?access_token=%s" % accessToken
materialsList = []
for i in range(1, int(count / 20) + 2):
requestAttr = urllib.request.Request(url=url, data=json.dumps({
"type": listType,
"offset": 20 * (i - 1),
"count": 20
}).encode("utf-8"), headers={
"Content-Type": "application/json"
})
responseAttr = urllib.request.urlopen(requestAttr)
responseData = json.loads(responseAttr.read().decode("utf-8"))
materialsList = materialsList + responseData["item"]
return materialsList
可以通过以下代码调用:
rticlesList = getMaterialsList("news", getTheTotalOfAllMaterials()['news_count'])
2: 将图文消息存储到COS,并且通过函数的Invoke接口,实现函数间调用:
def saveNewsToCos():
global articlesList
articlesList = getMaterialsList("news", getTheTotalOfAllMaterials()['news_count'])
try:
cosClient.put_object(
Bucket=bucket,
Body=json.dumps(articlesList).encode("utf-8"),
Key=key,
EnableMD5=False
)
req = models.InvokeRequest()
params = '{"FunctionName":"Weixin_GoServerless_GetIndexFile", "ClientContext":"{"key": "%s", "index_key": "%s"}"}' % (
key, indexKey)
req.from_json_string(params)
resp = scfClient.Invoke(req)
resp.to_json_string()
response = cosClient.get_object(
Bucket=bucket,
Key=key,
)
response['Body'].get_stream_to_file('/tmp/content.json')
with open('/tmp/content.json') as f:
articlesList = json.loads(f.read())
return True
except Exception as e:
print(e)
return False
3: 根据搜索反馈回来的Key实现文章内容的对应
def searchNews(sentence):
req = models.InvokeRequest()
params = '{"FunctionName":"Weixin_GoServerless_SearchNews", "ClientContext":"{"sentence": "%s", "key": "%s"}"}' % (
sentence, indexKey)
req.from_json_string(params)
resp = scfClient.Invoke(req)
print(json.loads(json.loads(resp.to_json_string())['Result']["RetMsg"]))
media_id = json.loads(json.loads(json.loads(resp.to_json_string())['Result']["RetMsg"])["result"])
return media_id if media_id else None
最后在main_handler中,增加使用逻辑:
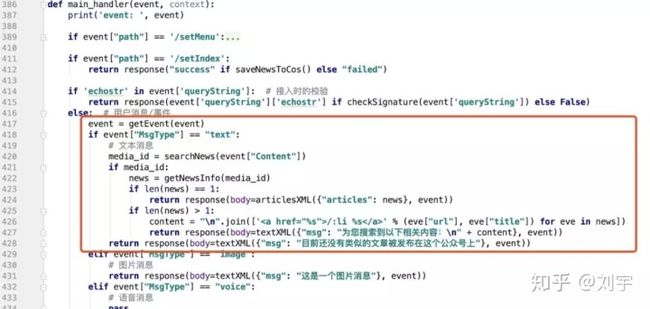
逻辑很简答,就是根据用户发的消息,去查找对应的结果,拿到结果之后判断结果个数,如果有1个相似内容,则返回一个图文,如果有多个则返回带有链接的文本。
另外一个逻辑是建立索引,直接是通过API网关触发即可,当然,如果怕不安全或者有需要的话,可以增加权限坚定的参数:

额外优化:

在接口列表中,我们可以看到获取accessToken的接口实际上是有次数限制的,每次获取有效期两个小时。所以,我们就要在函数中,对这部分内容做持久化。为了这个小东西,弄一个MySQL貌似不是很划算,所以决定用COS:
def getAccessToken():
'''
文档地址:https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Get_access_token.html
正常返回:{"access_token":"ACCESS_TOKEN","expires_in":7200}
异常返回:{"errcode":40013,"errmsg":"invalid appid"}
:return:
'''
global accessToken
# 第一次判断是判断本地是否已经有了accessToken,考虑到容器复用情况
if accessToken:
if int(time.time()) - int(accessToken["time"]) <= 7000:
return accessToken["access_token"]
# 如果本地没有accessToken,可以去cos获取
try:
response = cosClient.get_object(
Bucket=bucket,
Key=accessTokenKey,
)
response['Body'].get_stream_to_file('/tmp/token.json')
with open('/tmp/token.json') as f:
accessToken = json.loads(f.read())
except:
pass
# 这一次是看cos中是否有,如果cos中有的话,再次进行判断段
if accessToken:
if int(time.time()) - int(accessToken["time"]) <= 7000:
return accessToken["access_token"]
# 如果此时流程还没停止,则说明accessToken还没获得到,就需要从接口获得,并且同步给cos
url = "https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid=%s&secret=%s" % (appid, secret)
accessTokenResult = json.loads(urllib.request.urlopen(url).read().decode("utf-8"))
accessToken = {"time": int(time.time()), "access_token": accessTokenResult["access_token"]}
print(accessToken)
response = cosClient.put_object(
Bucket=bucket,
Body=json.dumps(accessToken).encode("utf-8"),
Key=accessTokenKey,
EnableMD5=False
)
return None if "errcode" in accessToken else accessToken["access_token"]
当然,我觉得这段代码可以继续优化,但是目前这个算是一个思路。
最后上一下Yaml:
Conf:
component: "serverless-global"
inputs:
region: ap-shanghai
bucket: go-serverless-1256773370
wxtoken: 小程序Token
appid: 小程序appid
secret: 小程序密钥
secret_id: 腾讯云SecretId
secret_key: 腾讯云SecretKey
Weixin_Bucket:
component: '@gosls/tencent-cos'
inputs:
bucket: ${Conf.bucket}
region: ${Conf.region}
Weixin_GoServerless:
component: "@gosls/tencent-scf"
inputs:
name: Weixin_GoServerless
codeUri: ./Admin
handler: index.main_handler
runtime: Python3.6
region: ap-shanghai
description: 微信公众号后台服务器配置
memorySize: 64
timeout: 100
environment:
variables:
region: ${Conf.region}
bucket: ${Conf.bucket}
wxtoken: ${Conf.wxtoken}
appid: ${Conf.appid}
secret: ${Conf.secret}
secret_id: ${Conf.secret_id}
secret_key: ${Conf.secret_key}
events:
- apigw:
name: Weixin_GoServerless
parameters:
serviceId: service-lu0iwy4t
protocols:
- https
environment: release
endpoints:
- path: /
serviceTimeout: 100
method: ANY
function:
isIntegratedResponse: TRUE
Weixin_GoServerless_GetIndexFile:
component: "@gosls/tencent-scf"
inputs:
name: Weixin_GoServerless_GetIndexFile
codeUri: ./GetIndexFile
handler: index.main_handler
runtime: Python3.6
region: ap-shanghai
description: 微信公众号索引建立功能
memorySize: 512
timeout: 100
environment:
variables:
region: ${Conf.region}
bucket: ${Conf.bucket}
secret_id: ${Conf.secret_id}
secret_key: ${Conf.secret_key}
Weixin_GoServerless_SearchNews:
component: "@gosls/tencent-scf"
inputs:
name: Weixin_GoServerless_SearchNews
codeUri: ./SearchNews
handler: index.main_handler
runtime: Python3.6
region: ap-shanghai
description: 微信公众号图文搜索功能
memorySize: 384
timeout: 100
environment:
variables:
region: ${Conf.region}
bucket: ${Conf.bucket}
secret_id: ${Conf.secret_id}
secret_key: ${Conf.secret_key}
这里组件记住一定要用@gosls代替@serverless,因为@serverless目前没有指定组件部署,所以你每次修改都要全部重新部署,你要知道这里最后两个函数代码非常大,你部署一次要10分钟左右,所以用@gosls这个组件库,就可以通过-n参数进行单独部署
最后:代码已经在Git上开源,我会不断更新,直到项目完成

欢迎watch-star-fork三连击。
