Python工程师的大数据之路(6f)图解Kafka生产者和消费者API
图解Kafka的Java API
- 1、前言
- 2、生产者
-
- 1.1、复习一下命令
- 1.2、写入分区的策略有哪些
- 1.3、Java代码原理图
- 1.4、Java代码
- 1.5、试运行
- 2、生产者
-
- 2.1、复习一下命令
- 2.2、消费者偏移量
- 2.3、Java代码
1、前言
- Kafka官网:http://kafka.apache.org/documentation/
- 因为不同版本的Kafka的API不同,所以我们要尽量去官网看配置和找demo
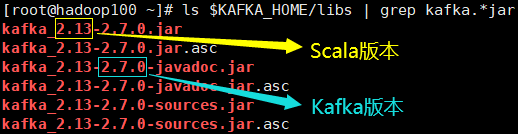
- 查看Kafka版本的方法
ls $KAFKA_HOME/libs | grep kafka.*jar
- 依赖
<dependency>
<groupId>org.apache.kafkagroupId>
<artifactId>kafka-clientsartifactId>
<version>2.7.0version>
dependency>
2、生产者
1.1、复习一下命令
kafka-console-producer.sh \
--broker-list hadoop100:9092 \
--topic topicK
1.2、写入分区的策略有哪些
-
策略1:指定
- 指定分区 策略2:根据key的哈希值
-
没有指定分区,有key,
分区号 = key.hashCode % 分区数(%是取余) 策略3:轮询
-
1、第1批写入时,会生成一个随机数,
分区号 = 随机数 % 分区数(%是取余)
2、第N批写入时,会沿用之前的随机数,分区号 = (随机数 + N - 1) % 分区数 策略4:排除前一次
-
1、第1批写入时,从分区号中随机选一个
2、第N批写入时,排除上一次(N-1)的分区号,从剩余分区中随机选一个
注意:源码实现方式会和上面说的策略有区别,但思想是一样的
1.3、Java代码原理图

1.4、Java代码
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) {
// 1、生产者属性
Properties p = new Properties();
// Kafka集群地址
p.put("bootstrap.servers", "hadoop100:9092");
// Key和Value的序列化器:字符串序列化器
p.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
p.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// ack等级;all就是-1
p.put("acks", "all");
// 批次大小
p.put("batch.size", 1024);
// RecordAccumulator缓冲区大小
p.put("buffer.memory", 2048);
// 最长等待时间,超过这个时间也会进行发送
p.put("linger.ms", 1);
// 2、创建生产者
Producer<String, String> producer = new KafkaProducer<>(p);
// 3、生产数据
for (int i = 0; i < 10; i++) {
// 发送到指定主题,并指定分区
producer.send(new ProducerRecord<>("topicZ", i % 2, "key" + i, "value" + i));
}
// 4、关闭生产者
producer.close();
}
}
1.5、试运行
创建主题(主题名称要和Java代码一样),设定两个分区,然后运行上面的Java代码
kafka-topics.sh \
--zookeeper hadoop100:2181/kafka \
--create \
--replication-factor 1 \
--partitions 3 \
--topic topicZ
3个分区,上面Java代码只写分区0和1,可见分区2的log文件大小是0

2、生产者
2.1、复习一下命令
kafka-console-consumer.sh \
--bootstrap-server hadoop101:9092 \
--topic topicK
2.2、消费者偏移量
-
消费者在消费过程中可能挂掉,消费者恢复后,需要从挂掉前的位置的继续消费
对此需要 记录 每个消费者 消费到了哪里
这个是consumer offset -
消费者 消费数据后,需要提交offset
例如:消费者 消费完offset=15的数据后,需要提交offset=16 -
消费者偏移量 被记录在 Kafka的一个自带的主题中
该主题叫做__consumer_offsets
2.3、Java代码
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
public class MyConsumer {
public static void main(String[] args) {
// 1、消费者属性
Properties props = new Properties();
// Kafka集群地址
props.setProperty("bootstrap.servers", "hadoop100:9092");
// 消费者组
props.setProperty("group.id", "test");
// 是否允许自动提交offset
props.setProperty("enable.auto.commit", "true");
// 自动提交offset的时间间隔
props.setProperty("auto.commit.interval.ms", "1000");
// 反序列化
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 2、创建消费者
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 3、订阅主题(可以多个主题)
consumer.subscribe(Arrays.asList("topicZ", "topicC", "topicN"));
// 4、消费
while (true) {
Duration timeout = Duration.ofMillis(100);
ConsumerRecords<String, String> records = consumer.poll(timeout);
for (ConsumerRecord<String, String> record : records) {
String topic = record.topic();
String key = record.key();
String value = record.value();
long offset = record.offset();
int partition = record.partition();
System.out.printf("topic=%s, offset=%d, partition=%d, key=%s, value=%s%n",
topic, offset, partition, key, value);
}
}
}
}
打印结果
topic=topicZ, partition=0, offset=0, key=key0, value=value0
topic=topicZ, partition=0, offset=1, key=key2, value=value2
topic=topicZ, partition=0, offset=2, key=key4, value=value4
topic=topicZ, partition=0, offset=3, key=key6, value=value6
topic=topicZ, partition=0, offset=4, key=key8, value=value8
topic=topicZ, partition=1, offset=0, key=key1, value=value1
topic=topicZ, partition=1, offset=1, key=key3, value=value3
topic=topicZ, partition=1, offset=2, key=key5, value=value5
topic=topicZ, partition=1, offset=3, key=key7, value=value7
topic=topicZ, partition=1, offset=4, key=key9, value=value9