ZooKeeper
ZK是什么?
ZK是一个分布式服务框架,主要用来解决分布式应用中经常遇到的一些数据管理问题,如统一命名服务,集群管理,分布式应用配置项的管理等.1.ZK是一个拥有文件系统特点的数据库2.ZK是一个解决了数据一致性问题的分布式数据库3.ZK是一个具有发布和订阅功能的分布式数据库
ZAB协议
•领导者选举
•数据同步(恢复阶段)
•接收请求(⼆二阶段提交)
特点
ZooKeeper 分布式协调服务
入门
Zookeeper工作机制
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它 负责存储和管理大家都关心的数据,然后 接受观察者的注册 ,一旦这些数据的状态发生变化,Zookeeper就将 负责通知已经在Zookeeper上注册的那些观察者 做出相应的反应。Zookeeper= 文件系统 + 通知机制
Zookeeper特点
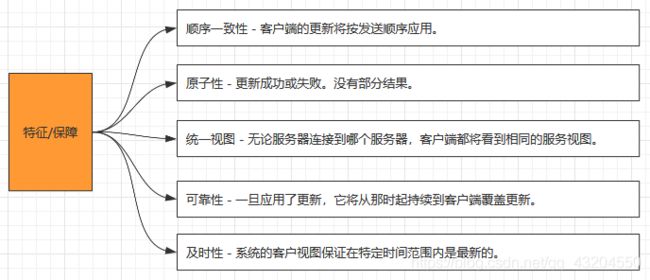
1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。4)更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行。5)数据更新原子性,一次数据更新要么成功,要么失败。6)实时性,在一定时间范围内,Client能读到最新数据。
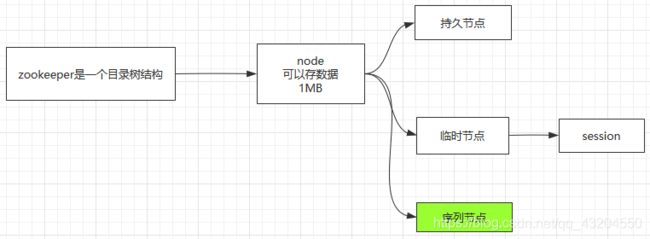
数据结构
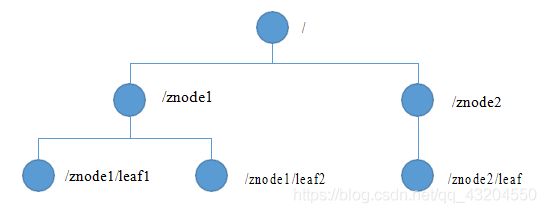
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每一个ZNode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
配置参数
#心跳时间,心跳帧,此处为2秒
tickTime=2000
#刚开始启动时,leader和follower的最大延迟时间,10个心跳帧
initLimit=10
#启动之后,leader和follower的通信时间
syncLimit=5
#数据文件目录+数据持久化路径 主要用于保存ZooKeeper中的数据
dataDir=/opt/apache-zookeeper-3.6.2-bin/zkData
#客户端的连接端口号
clientPort=2181
#用于创建集群
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
Stat结构体
#1.创建节点的事务zxid
cZxid = 0x6
#2.被创建的毫秒数,从1970年开始
ctime = Sun Oct 18 13:43:43 CST 2020
#3.最后更新的事务zxid
mZxid = 0x6
#4.最后修改的毫秒数,从1970年开始
mtime = Sun Oct 18 13:43:43 CST 2020
#5.最后更新的子节点zxid
pZxid = 0x7
#6.子节点变化号,子节点修改次数
cversion = 1
#7.数据变化号
dataVersion = 0
#8.访问控制列表的变化号
aclVersion = 0
#9.如果是临时节点,这个是znode拥有者的session id.如果不是临时节点,则是0
ephemeralOwner = 0x0
#10.数据的长度
dataLength = 3
#11.子节点的数量
numChildren = 1客户端操作
代码
public class TestZooKeeper {
private String connectString = "192.168.43.38:2181";//表示要连接哪一个ZooKeeper集群
private int sessionTimeout = 40000;//连接的时候的超时时间
private ZooKeeper zkClient;//ZooKeeper的客户端
//创建客户端
@Before
public void init() throws IOException {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
//监听回调
@Override
public void process(WatchedEvent watchedEvent) {
List children = null;
try {
System.out.println("---------------start---------------");
children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println("child = " + child);
}
System.out.println("---------------end---------------");
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
System.out.println("zkClient = " + zkClient);
}
//创建节点
@Test
public void createNode() throws KeeperException, InterruptedException {
String path = zkClient.create("/xibei", "wjs".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("path = " + path);
}
//获取子节点 并监控节点的变化
@Test
public void getDataAndWatch() throws KeeperException, InterruptedException {
List children = zkClient.getChildren("/", true);
for (String child : children) {
System.out.println("child = " + child);
}
}
//判断节点是否存在
@Test
public void exist() throws KeeperException, InterruptedException {
Stat stat = zkClient.exists("/xiyou", false);
System.out.println("stat = " + stat);
}
}
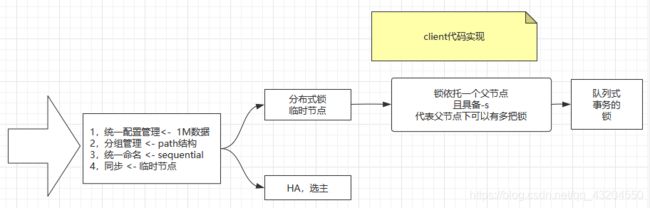
应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
1. 统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
例如:IP不容易记住,而域名容易记住。
2. 统一配置管理
1). 分布式环境下,配置文件同步非常常见。
(1). 一般要求一个集群中,所有节点的配置信息是一致的,比如 Kafka 集群。
(2). 对配置文件修改后,希望能够快速同步到各个节点上。
2). 配置管理可交由ZooKeeper实现。
(1). 可将配置信息写入ZooKeeper上的一个Znode。
(2). 各个客户端服务器监听这个Znode。
(3). 一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
3. 统一集群管理
1)分布式环境中,实时掌握每个节点的状态是必要的。
(1)可根据节点实时状态做出一些调整。
2). ZooKeeper可以实现实时监控节点状态变化
(1). 可将节点信息写入ZooKeeper上的一个ZNode。
(2). 监听这个ZNode可获取它的实时状态变化。
4. 服务器动态上下线
客户端能实时洞察到服务器上下线的变化
5. 软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求
内部原理
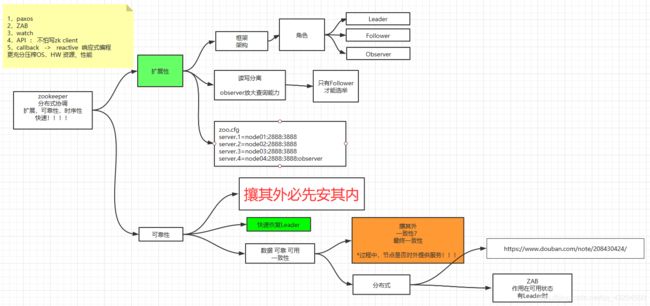
1.选举机制
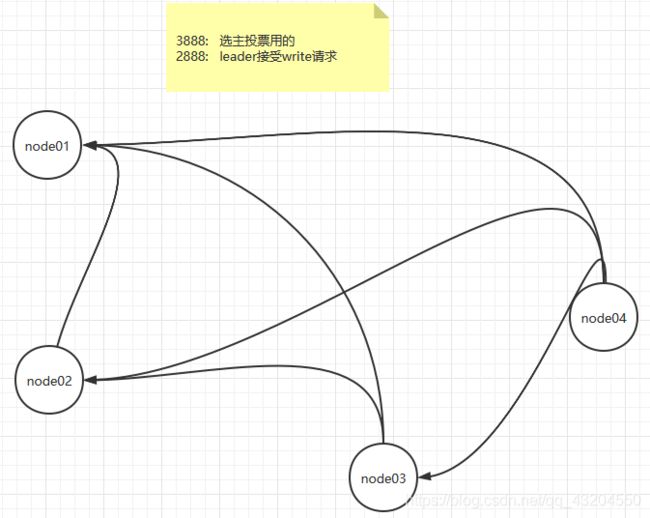
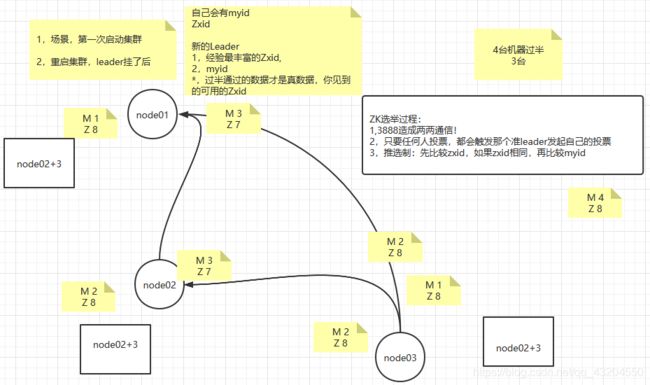
1.集群中半数以上及其存活,集群可用.所以,ZooKeeper适合安装奇数台服务器
2.ZooKeeper虽然在配置文件中内有指定Master和Slave.但是,ZooKeeper工作时,是有一个节点为Leader,其他则为Follower,Leader是通过内部选举机制临时产生的
Leader选举机制的原理(3种)
先比较zxid(事务id),再比较myid(服务器id),在进行领导者选举的时候,不能对外提供服务
1. 集群启动(假设三台服务器)
选票阶段: 1号服务器启动,将票投给自己,2号服务器启动时,将票投给自己,通过配置的端口交流信息,将票的信息发送给1号服务器,票的信息包括zxid和myid
改票阶段: 1号服务器接收到了这张选票,进行比较,如果2号服务器更大,则将票改投给2号服务器,将选票信息发送给2号服务器,2号服务器发现和自己的投票一样,不需要去改票
选举:发现已经有半数以上的票投给了2号服务器,,则2号服务器就是最终的Leader,其他服务器都是Follower
3号服务器加入进来后,也是作为Follower,无需重新选举
如果新加入进集群的服务器3号的zxid比较大,因为没有通过半数以上,所以这次的请求时无效的,会被回滚掉,和集群数据保持一致 ,如果数据比较落后,则同步
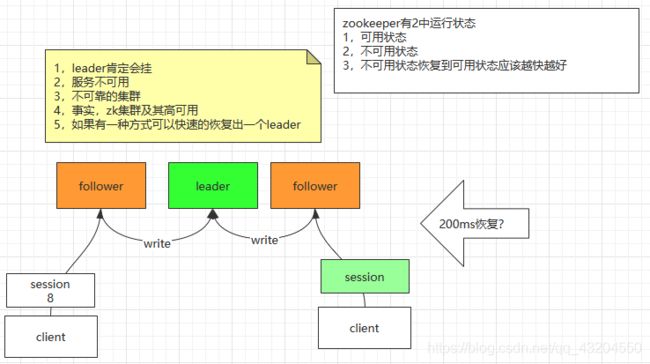
2. Leader挂掉
和刚启动时的选举机制一样
3.Follower挂掉以后,Leader发现已经没有过半的Follower跟随自己了--不能对外提供服务了(领导者选举)
为了让这个集群不能够对外提供服务,会让这个集群去进行领导者选举,这个Leader会把自己挂掉,其实就是改变自己的状态,重新进行选举,以达到不能对外提供服务的目的
脑裂
•脑裂出现的原因是⼀一部分服务器器和领导失去了了连接,⽽而这个⼀一部分服务器器之间是可以相互连通的,所以这⼀一部分服务器器会重新选举,如果重新选举出来了了⼀一个Leader,那么整个集群就出现了了两个Leader,这就是脑裂。
•Zookeeper中的领导者选举需要收到超过⼀一半的服务器器的选票,所以如果出现了了脑裂,服务器器的节点数量量是不不够的,所以通过过半机制的验证,避免了了脑裂。
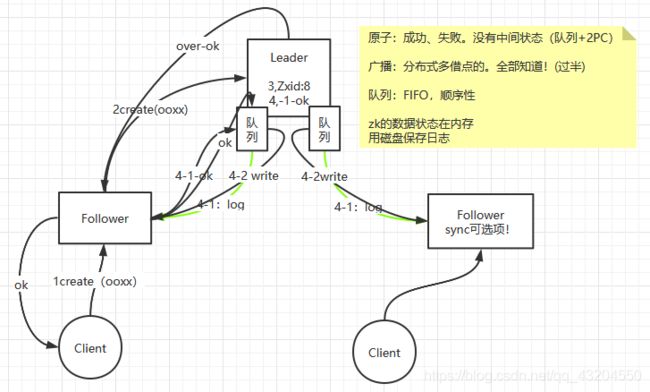
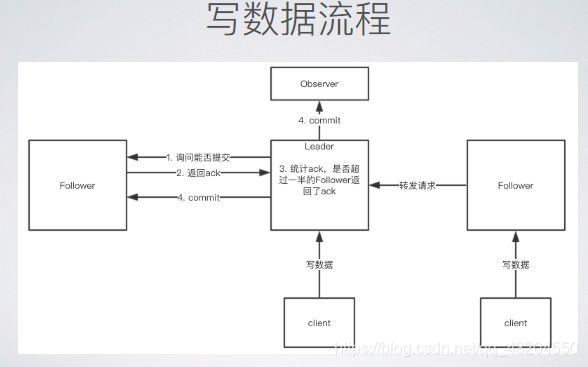
2.读写过程,预提交(两阶段提交)
3.节点类型
1.持久化目录节点:客户端与ZooKeeper断开连接后,该节点依旧存在
2.持久化顺序编号节点:客户端与ZooKeeper断开连接后,该节点依旧存在,只是ZooKeeper给该节点名称进行顺序编号
3.临时目录节点: 客户端与ZooKeeper断开连接后,该节点被删除
4.临时顺序编号目录节点: 客户端与ZooKeeper断开连接后,该节点被删除,只是ZooKeeper给该节点名称进行编号
4.数据一致性
一致性分为三种
强一致性,弱一致性,最终一致性
CAP
Consistency: 一致性(强一致性)
Availability: 可用性
Partition Tolerance: 分区容错性
ZK满足CP
ZK会将接收到的请求预先放在⼀一个队列列中,然后⽤用单线程从队列列中依次取出请求进⾏行行处理理,⽐比如同时有两个写操作进⼊入了了队列列,那么第⼀一个写操作在被处理理的过程中,第⼆二个写操作是需要等待第⼀一个写操作处理理完后才会被处理理的,这对于第⼆二个写操作⽽而⾔言就是集群暂时不不可⽤用,⽽而不不可⽤用的主要原因就是第⼀一个写操作为了了使集群中的数据保持⼀一致正在进⾏行行⼆二阶段提交操作。
BASE理论
基本可⽤用(Basically Available):基本可⽤用是指分布式系统在出现故障的时候,允许损失部分可⽤用性,即保证核⼼心可⽤用。电商⼤大促时,为了了应对访问量量激增,部分⽤用户可能会被引导到降级⻚页⾯面,服务层也可能只提供降级服务。这就是损失部分可⽤用性的体现。
软状态(Soft State):软状态是指允许系统存在中间状态,⽽而该中间状态不不会影响系统整体可⽤用性。分布式存储中⼀一般⼀一份数据⾄至少会有三个副本,允许不不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是⼀一种体现。
最终⼀一致性(Eventual Consistency):最终⼀一致性是指系统中的所有数据副本经过⼀一定时间后,最终能够达到⼀一致的状态。弱⼀一致性和强⼀一致性相反,最终⼀一致性是弱⼀一致性的⼀一种特殊情况。
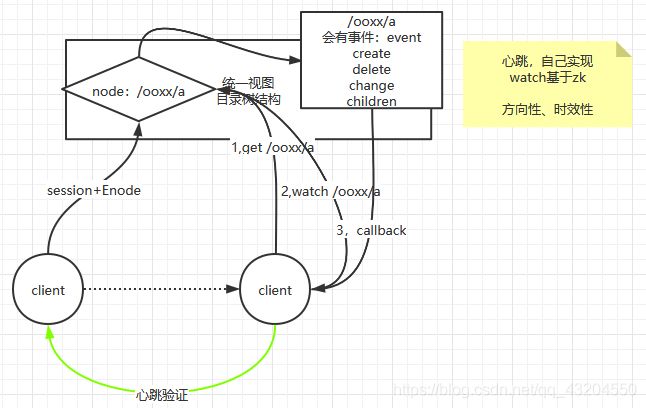
5.监听器原理

1.首先要有一个main()线程
2.在main线程中创建ZooKeeper客户端,这时就会创建两个线程,一个负责网络连接通信(connect),一个负责监听(listen)
3.通过connect线程将注册的监听事件发送给ZooKeeper.
4.在ZooKeeper的注册监听器列表中将注册的监听事件添加到列表中
5.ZooKeeper监听到有数据或路径变化时,就会将这个消息发送给listen线程
6.listen线程内部调用process()方法
常用的监听
#1.监听节点数据的变化
get path [watch]
#2.监听子节点增减的变化
ls path [watch]6.配置中心
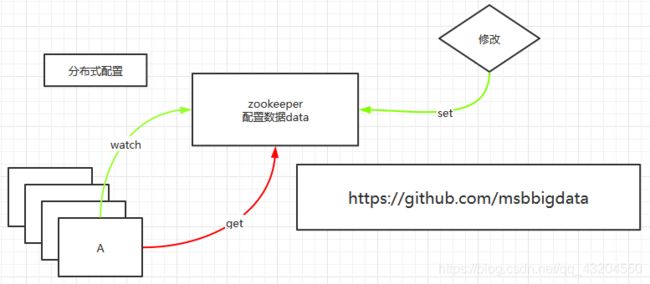
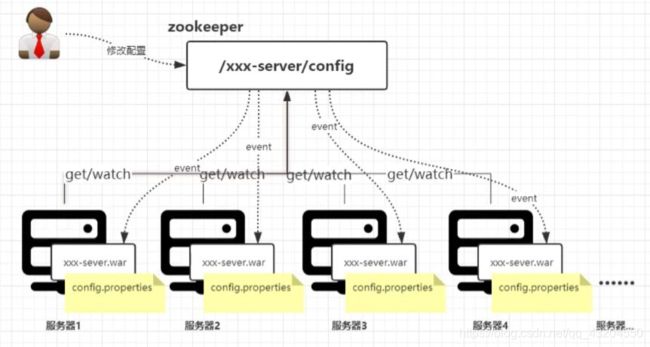
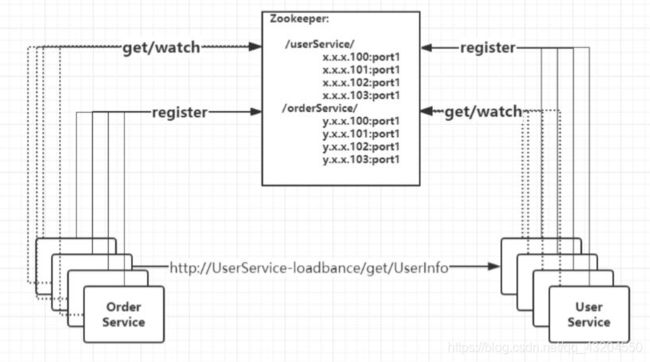
7.注册中心
8.分布式锁
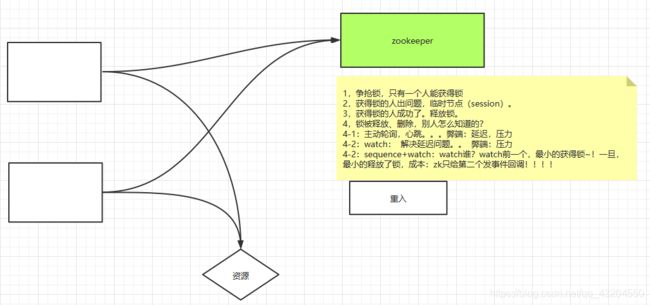
有问题版本,非公平形式
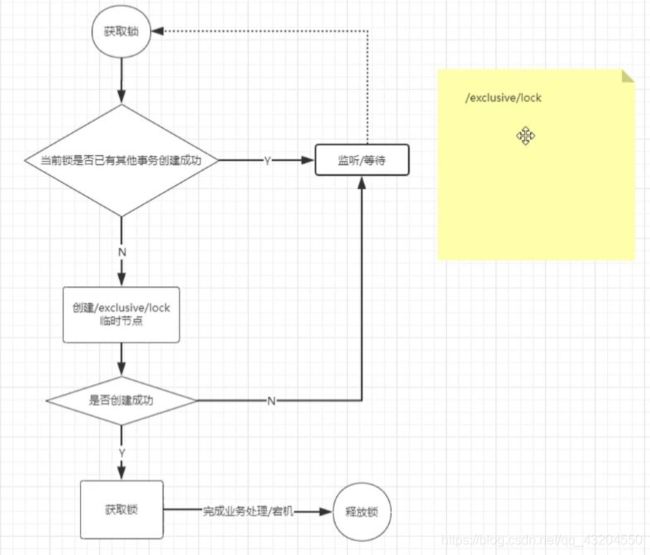
公平形式
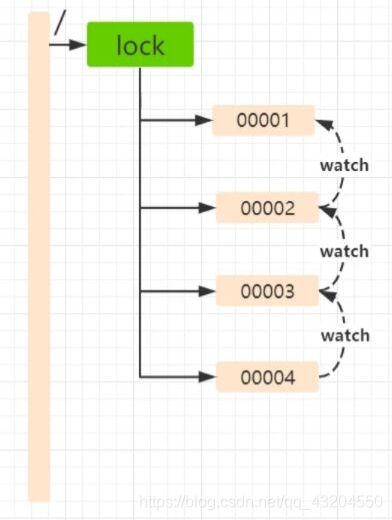
9.监听服务器节点动态上下线
public class DistributeServer {
public static void main(String[] args) throws Exception {
DistributeServer server = new DistributeServer();
//1.连接ZooKeeper集群
server.getConnect();
//2.注册节点
server.regist(args[0]);
//3.业务逻辑处理
server.business();
}
private void business() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private String connectString = "192.168.3.10:2181";
private int sessionTimeout = 20000;
private ZooKeeper zkClient = null;
private void getConnect() throws IOException {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
}
});
}
private void regist(String hostName) throws KeeperException, InterruptedException {
String path = zkClient.create("/servers/server", hostName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostName + " is online");
}
}
(3)客户端代码
public class DistributeClient {
public static void main(String[] args) throws Exception {
DistributeClient client = new DistributeClient();
//1.获取ZooKeeper集群连接
client.getConnect();
//2.注册监听
client.getChildren();
//3.业务逻辑处理
client.bussiness();
}
private void bussiness() throws InterruptedException {
Thread.sleep(Long.MAX_VALUE);
}
private void getChildren() throws KeeperException, InterruptedException {
List children = zkClient.getChildren("/servers", true);
List hosts = new ArrayList<>();
for (String child : children) {
byte[] data = zkClient.getData("/servers/" + child, false, null);
hosts.add(new String(data));
}
//将所有在线主机名称全部打印
System.out.println("****************************");
System.out.println(hosts);
System.out.println("****************************");
}
private String connectString = "192.168.3.10:2181";
private int sessionTimeout = 20000;
private ZooKeeper zkClient = null;
private void getConnect() throws IOException {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
try {
getChildren();
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
下载安装
Zookeeper下载地址:https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.6.2/apache-zookeeper-3.6.2-bin.tar.gz
Linux下安装上传下载工具:yum install lrzsz -y
使用secureCRT工具进行上传
解压: apache-zookeeper-3.6.2-bin.tar.gz
进入conf目录:cd /opt/apache-zookeeper-3.6.2-bin/conf
修改文件名: mv zoo_sample.cfg zoo.cfg
创建zkData文件
打开修改zoo.cfg文件下的dataDir: dataDir=/opt/apache-zookeeper-3.6.2-bin/zkData
开启服务端: ./zkServer.sh start
开启客户端: ./zkServer.sh stop
ZK集群搭建
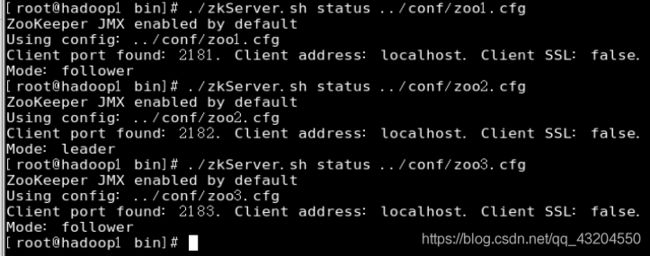
注:leader用来处理事务请求,follower用来同步数据
第一步:在/opt/apache-zookeeper-3.6.2-bin/data目录下创建三个文件目录zookeeper1 zookeeper2 zookeeper3
在每个目录文件下面创建一个myid文件,输入对应的序号,如1,2,3代表每一个服务器的id
在/opt/apache-zookeeper-3.6.2-bin/conf目录下创建三个文件zoo1.cfg zoo2.cfg zoo3.cfg,文件的内容为
#心跳时间,心跳帧,此处为2秒
tickTime=2000
#刚开始启动时,leader和follower的最大延迟时间,10个心跳帧
initLimit=10
#启动之后,leader和follower的通信时间
syncLimit=5
#数据文件目录+数据持久化路径 主要用于保存ZooKeeper中的数据
dataDir=/opt/apache-zookeeper-3.6.2-bin/data/zookeeper1
#客户端的端口号
clientPort=2181
server.1=localhost:2887:3887
server.2=localhost:2888:3888
server.3=localhost:2889:3889
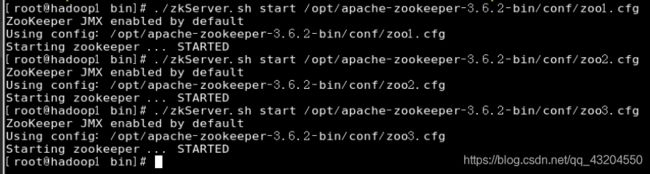
启动三台服务器
查看服务器状态
启动客户端
./zkCli.sh -server localhost:2181
msb版本集群搭建
安装笔记:
准备 node01~node04
1,安装jdk,并设置javahome
*, node01:
2,下载zookeeper zookeeper.apache.org
3,tar xf zookeeper.*.tar.gz
4,mkdir /opt/mashibing
5, mv zookeeper /opt/mashibing
6,vi /etc/profile
export ZOOKEEPER_HOME=/opt/mashibing/zookeeper-3.4.6
export PATH=$PATH:$ZOOKEEPER_HOME/bin
7,cd zookeeper/conf
8,cp zoo.sem*.cfg zoo.cfg
9,vi zoo.cfg
dataDir=
server.1=node01:2888:3888
10, mkdir -p /var/mashibing/zk
11,echo 1 > /var/mashibing/zk/myid
12,cd /opt && scp -r ./mashibing/ node02:`pwd`
13:node02~node04 创建 myid
14:启动顺序 1,2,3,4
15:zkServer.sh start-foreground
zkCli.sh
help
ls /
create /ooxx ""
create -s /abc/aaa
create -e /ooxx/xxoo
create -s -e /ooxx/xoxo
get /ooxx
netstat -natp | egrep '(2888|3888)'
Watch 手表 监控 观察