参考文章:
https://my.oschina.net/u/2277929/blog/660748*
http://www.jianshu.com/p/debf0e6a3f3b*
http://www.jianshu.com/p/6e59df5f2461*
https://my.oschina.net/wstone/blog/522165*
http://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/*
http://business.sohu.com/20160919/n468669356.shtml*
https://www.gitbook.com/book/forevernull/hortonworks-getstarted*
http://www.cnblogs.com/starof/p/4685999.html*
http://www.cnblogs.com/linuxhan/archive/2012/04/18/3017178.html*
http://blog.csdn.net/bluishglc/article/details/42049047*
0Hbase搭建
0.1背景知识
Hbase为Hadoop的组件之一。Hadoop在大数据领域的应用前景很大,不过因为是开源技术,实际应用过程中存在很多问题。于是出现了各种Hadoop发行版,国外目前主要是三家创业公司在做这项业务:
Hortonworks,
Cloudera,
MapR
其中Cloudera和MapR的发行版是收费的,他们基于开源技术,提高稳定性,同时强化了一些功能,定制化程度较高,核心技术是不公开的。营收主要来自软件收入,国内的星环科技, 红象云腾盈利模式与之类似。这类公司,如果一直保持技术领先性,那么软件收入溢价空间很大。但一旦技术落后于开源社区,整个产品需要进行较大调整。
Hortonworks则走向另一条路,他们将核心技术完全公开,用于推动Hadoop社区的发展。这样做的好处是,如果开源技术有很大提升,他们受益最大,因为定制化程度较少,自身不会受到技术提升的冲击。
不同于传统软件提供商,Hortonworks没有对产品收费,而是将这两款产品完全开放,将核心技术放在Hadoop开源社区中,每个人都可以看到并使用这两款产品。开公司又不是做慈善,Hortonworks靠什么来赚钱?对于企业客户来说,就算知道新技术的核心内容,具体应用还是会碰到很多问题。有了源代码,如何与自己系统相结合、增强功能、调试故障、对接应用都是问题。这个时候,程序开发者找上门来说:“这个技术是我研发的,我可以帮你将技术应用到你的系统中,调试、更新升级、加入特定的功能这些事情我都可以做。后期需要的话,还可以提供维护。”企业客户如果想用这项技术,自己开发难度较大的话,就会选择合作。这就是Hortonworks的盈利模式,通过提供支持服务和后期维护,向企业级客户收费。即类似于RedHat,通过服务赚钱。
0.2物理架构
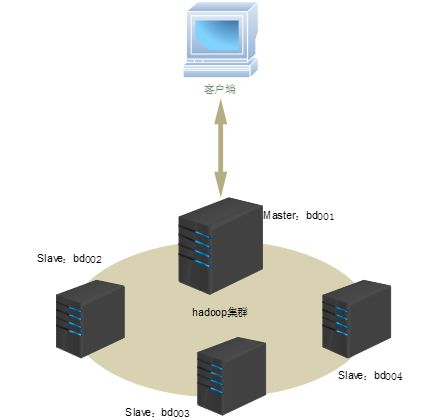
图1-1测试物理架构图
0.3下载相关文件
从官网(hortonworks)下载Hadoop安装工具及包ambari,避免待会yum在线安装时,老安装失败(因为文件比较大,又要翻墙,容易断)。
HDP-2.4.0.0(6GB)
http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.4.0.0/HDP-2.4.0.0-centos6-rpm.tar.gz
HDP-UTILS(694MB)
http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos6/HDP-UTILS-1.1.0.20-centos6.tar.gz
ambari(626MB)
http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.2.1.0/ambari-2.2.1.0-centos6.tar.gz
jdk-7u80-linux-x64(294M)
0.4配置集群机器
1.配置磁盘空间
测试用的系统为centos6.7,因为安装后期HDFS磁盘及相关日志占用比较大,因此提交做好分区挂载很重要(测试时虚拟机扩容了几次),需要比较大空间的目录为:HDFS目录和Log目录和lib目录。
各台机器的默认安装目录:
/usr/lib/hadoop
/usr/lib/hbase
/usr/lib/zookeeper
/usr/lib/hcatalog
/usr/lib/hive
Log路径, 这里需要看出错信息都可以在目录下找到相关的日志
/var/log/hadoop
/var/log/hbase
配置文件的路径
/etc/hadoop
/etc/hbase
/etc/hive
HDFS的存储路径
/hadoop/hdfs
2.配置防火墙
关闭命令: service iptables stop
永久关闭防火墙:chkconfig iptables off
两个命令同时运行,运行完成后查看防火墙关闭状态
service iptables status
3.配置hostname
永久修改hostname,重启后生效
vi /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME=XXXX
想立即生效(不建议,可能失败)可采取如下方法:
修改主机名:hostname bd001
查看主机名:hostname
4.配置自动校时
开启自动校时,并开机自启动
chkconfig ntpd on
service ntpd start
设置时区为北京时间,这里为上海,因为centos里面只有上海。。。
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
时间同步
ntpdate us.pool.ntp.org
没有安装ntpdate的可以yum一下
yum install -y ntpdate
加入定时计划任务,每隔10分钟同步一下时钟
crontab -e
把下面的内容粘贴进去保存即可
0-59/10 * * * * /usr/sbin/ntpdate us.pool.ntp.org | logger -t NTP
设置内网ntp服务器还不知道如何处理
5.配置SSL(版本大于1.0)
需要openssl的1.0以上版本!
yum install openssl
或者
yum upgrade openssl
6.配置python(版本大于等于2.6)
版本在2.6但不要是3.x
7.配置JDK(版本大于等于1.7)
建议安装Sun的JDK1.7版本!
安装完毕并配置java环境变量,
在/etc/profile末尾添加如下代码:
export JAVA_HOME=/usr/jdk1.7.0_80
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
保存退出即可,然后执行source /etc/profile生效.
在命令行执行java -version 如下代表JAVA安装成功.
8.配置SSH免验证登陆
主节点要能无密码登陆到所有数据节点的。为了便于理解,假设需要在hadoop148这台机器上可以通过无密码登录的方式连接到hadoop107上。
具体步骤:
1 、登录hadoop148,
执行命令 ssh-keygen -t rsa 之后一路回车
2 、把 id_rsa.pub 追加到授权的 key 里面去。
执行命令 cat ~/.ssh/id_rsa.pub >>~/.ssh/authorized_keys
3 、修改权限:
执行 chmod 600 ~/.ssh/authorized_keys
4 、将公钥复制到所有其他机器上 :
scp ~/.ssh/id_rsa.pub root@hadoop107:~/
5 、在 hadoop107 机器上 创建 .ssh 文件夹 :
mkdir ~/.ssh
chmod 700 ~/.ssh
6 、追加到授权文件 authorized_keys 执行命令 :
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
7 、验证命令
ssh hadoop107
删除107上的 id_rsa.pub 文件 :rm -r id_rsa.pub
9.配置hosts
在/etc/hosts中内容应为:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.128.111 bd001
192.168.128.112 bd002
192.168.128.113 bd003
192.168.128.114 bd004
10.配置离线源服务器
上述配置需要在集群中各个机器配置,而此离线源服务器可以在集群中一台机器或者集群能访问的一台机器中配置即可。
1.将下载的三个文件的tar.gz拷贝到/home目录下的/hdp目录中,然后分别解压。
2、安装Apache
yum install httpd
3、设置Apache服务的启动级别
chkconfig --levels 235 httpd on
4、现在就启动它,所有更改需要stop后在start
/etc/init.d/httpd start
5、在/etc/httpd/conf/httpd.conf中添加内容,即将/home/hdp映射为http的/hadoop目录
Alias /hadoop "/home/hdp"
Options Indexes FollowSymLinks
Order allow,deny
Allow from all
6、还要对沿途的个个路径授权755
那么要保证/home,/home/hdp这四个层级的目录都是755权限,
不要递归-R(会影响ssh无密码登陆),
hdp下面的文件和文件夹可以赋值为 777
7、/etc/init.d/httpd stop后再start
8、访问http://ip地址/hadoop 测试对应的离线文件能否访问及下载(默认端口80)
11.配置离线源客户端
在所有机器上配置:
(1)配置离线优先级:
yum install yum-plugin-priorities
vi /etc/yum/pluginconf.d/priorities.conf
设置为以下内容
[main]
enabled=1 gpgcheck=0
(2)替换3个repo文件
*hdp.repo
[HDP-2.4.0.0]
name=HDP Version - HDP-2.4.0.0
baseurl=http://192.168.128.111/hadoop/HDP/centos6/2.x/updates/2.4.0.0
gpgcheck=1
gpgkey=http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.4.0.0/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
*hdp-util.repo
[HDP-UTILS-1.1.0.20]
name=HDP Utils Version - HDP-UTILS-1.1.0.20
baseurl=http://192.168.128.111/hadoop/HDP-UTILS-1.1.0.20/repos/centos6
gpgcheck=1
gpgkey=http://public-repo-1.hortonworks.com/HDP/centos6/2.x/updates/2.4.0.0/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
*ambari.repo
[Updates-ambari-2.2.1.0]
name=ambari-2.2.1.0 - Updates
baseurl=http://192.168.128.111/hadoop/AMBARI-2.2.1.0/centos6/2.2.1.0-161
gpgcheck=1
gpgkey=http://public-repo-1.hortonworks.com/ambari/centos6/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
(3)yum repolist
12.其他配置
(1)增大文件句柄
在/etc/security/limits.conf接近末尾处添加:
soft nproc16384hard nproc16384soft nofile65536hard nofile65536
(2)禁止 PackageKit
pkill -9 packagekitd
vim /etc/yum/pluginconf.d/refresh-packagekit.conf
将内容改为enabled=0
(3)禁用selinux
vi /etc/sysconfig/selinux
设置selinux=disabled
0.5安装ambari服务
1.安装ambari-server
yum install -y epel-release
yum install ambari-server
选择“n”使用默认配置
等待安装完成
2.初始化ambari-server
安装失败后或重新安装先执行ambari-server reset 后 ambari-setup;
ambari-server setup
3.启动ambari-server
ambari-server start
http://ip:8080
使用默认的admin/admin登录。
0.6相关默认用户名密码
+++++++++++++++++++++++++++++++++++++
ambari管理页面:
访问地址 ip:8080 用户名密码 admin/admin
+++++++++++++++++++++++++++++++++++++
自带postgresql数据库:
数据库类型:postgresql
数据库:ambari
用户名:ambari
密码:bigdata
+++++++++++++++++++++++++++++++++++++
+++++++++++++++++++++++++++++++++++++
0.7集群在线配置
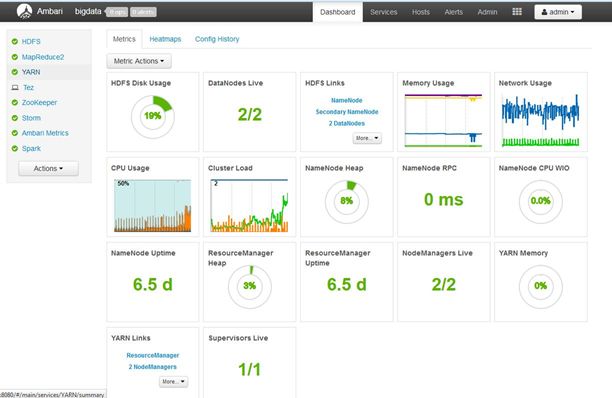
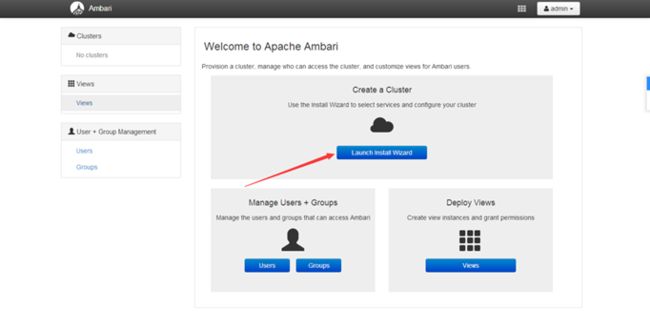
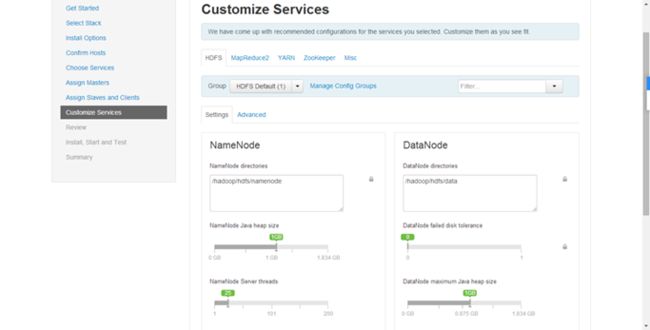
1.界面说明
搭建集群的按钮
输入集群名称,名字不支持 -号空格等

HDP版本号选择
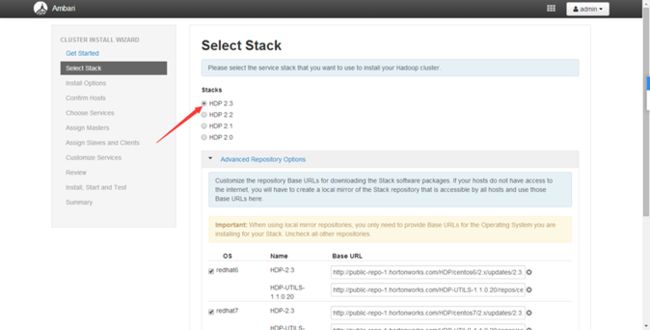
系统的版本不同悬着的os版本也不同
这里记得填写你的 离线地址
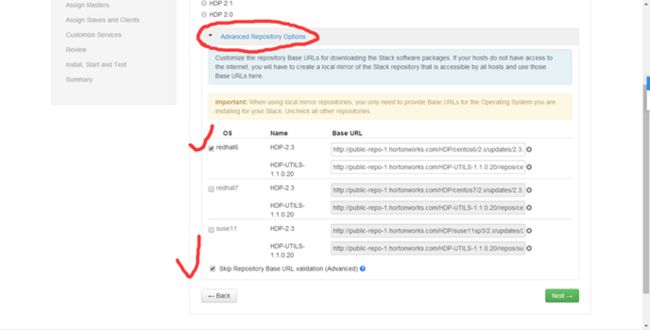
创建ssh免登陆时,主节点.ssh文件夹下有该文件
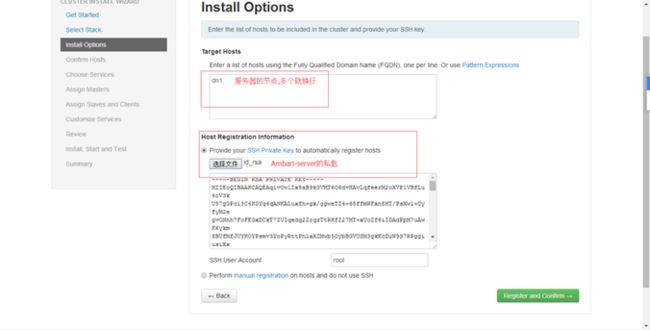
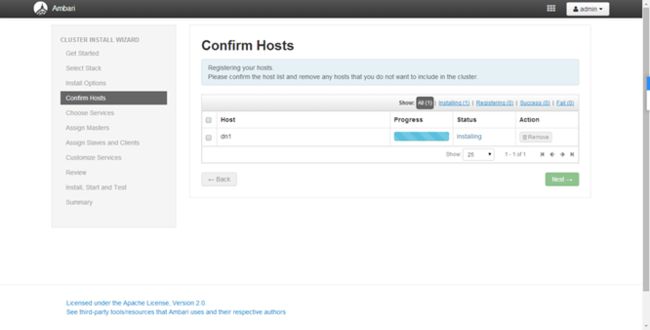
这一步很容易因为配置文件的原因出错(可能节点服务器没设置好dns,导致yum不能使用,也可能节点主机名和先前填写的主机名不一致)
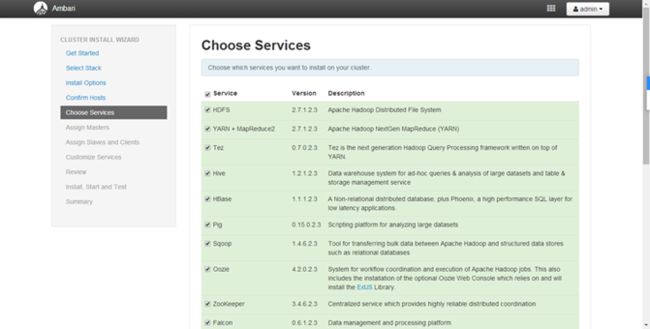
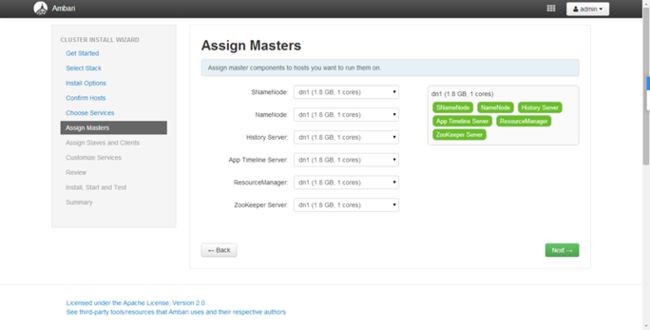
选择要安装哪些
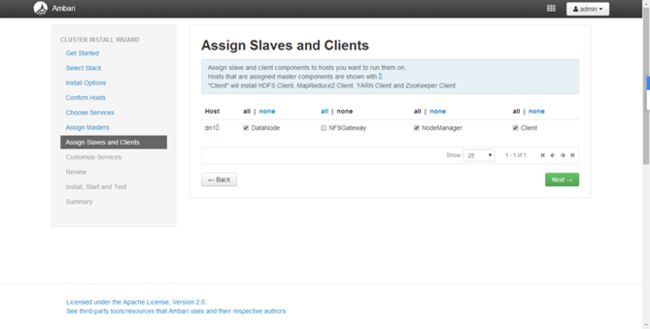
各个服务安装在哪些机器上,自己分配

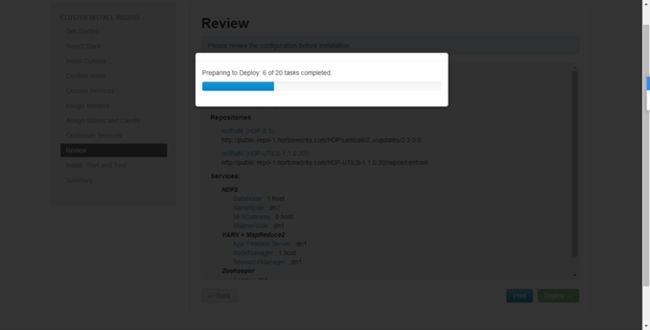
正在安装各个节点
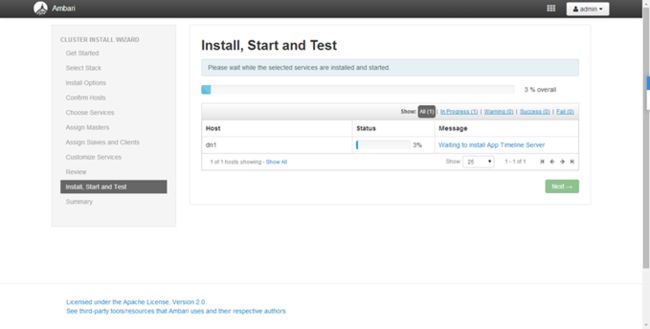
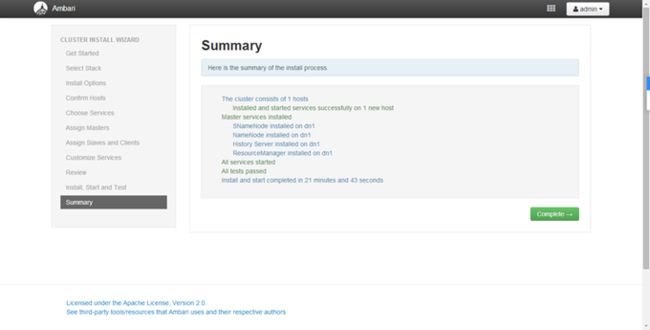
监控页面