Spring Cloud Sleuth 实现原理源码解读
Sleuth源码地址:https://github.com/spring-cloud/spring-cloud-sleuth
Sleuth如何实现自动配置?
在spring boot启动时,需要执行自动配置类。sleuth自动配置类都在spring-cloud-sleuth-core.jar包的spring.factories文件中:
# Auto Configuration
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
org.springframework.cloud.sleuth.annotation.SleuthAnnotationAutoConfiguration,\
org.springframework.cloud.sleuth.autoconfig.TraceAutoConfiguration,\
org.springframework.cloud.sleuth.propagation.SleuthTagPropagationAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.web.TraceHttpAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.web.TraceWebServletAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.web.client.TraceWebClientAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.web.client.TraceWebAsyncClientAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.async.AsyncAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.async.AsyncCustomAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.async.AsyncDefaultAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.scheduling.TraceSchedulingAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.web.client.feign.TraceFeignClientAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.hystrix.SleuthHystrixAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.circuitbreaker.SleuthCircuitBreakerAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.rxjava.RxJavaAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.reactor.TraceReactorAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.web.TraceWebFluxAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.zuul.TraceZuulAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.rpc.TraceRpcAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.grpc.TraceGrpcAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.messaging.SleuthKafkaStreamsConfiguration,\
org.springframework.cloud.sleuth.instrument.messaging.TraceMessagingAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.messaging.TraceSpringIntegrationAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.messaging.TraceSpringMessagingAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.messaging.websocket.TraceWebSocketAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.opentracing.OpentracingAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.redis.TraceRedisAutoConfiguration,\
org.springframework.cloud.sleuth.instrument.quartz.TraceQuartzAutoConfiguration
# Environment Post Processor
org.springframework.boot.env.EnvironmentPostProcessor=\
org.springframework.cloud.sleuth.autoconfig.TraceEnvironmentPostProcessor
这些配置类在满足条件的情况下都会被自动配置,而一些关键的类会自动配置,所以我们不需要写任何代码就可以实现采集与监控。
-
SleuthAnnotationAutoConfiguration
主要是配置一些Annotation,来及时记录一个事件的存在@Configuration( proxyBeanMethods = false ) @Role(2) @ConditionalOnBean({ Tracing.class}) @ConditionalOnProperty( name = { "spring.sleuth.annotation.enabled"}, // 有这个配置参数才会自动配置,没有默认为true matchIfMissing = true ) @AutoConfigureAfter({ TraceAutoConfiguration.class}) // 自动配置完后配置TraceAutoConfiguration public class SleuthAnnotationAutoConfiguration { ... } -
TraceAutoConfiguration
配置了spring.sleuth.enabled=true会自动配置Trace,默认值true,主要是配置一个Tracing对象 -
TraceWebServletAutoConfiguration
主要是对http请求的采集,通过配置一些filter,来对servlet进行过滤,获取请求时间、处理时间@Bean @ConditionalOnMissingBean public TracingFilter tracingFilter(HttpTracing tracing) { return (TracingFilter) TracingFilter.create(tracing); }
Sleuth采集支持范围
在sleuth中,目前共支持如下几种信息采集:
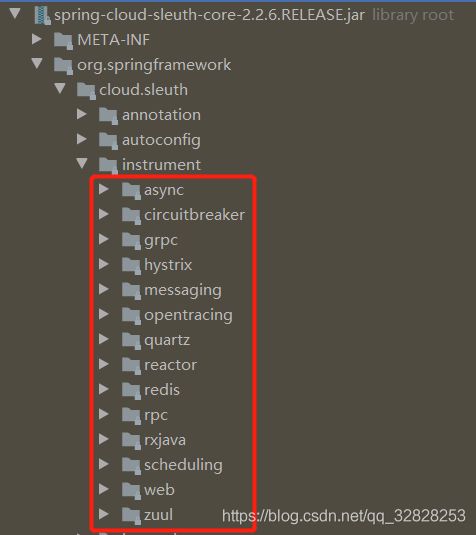
在与zipkin整合时,zipkin支持范围如下:
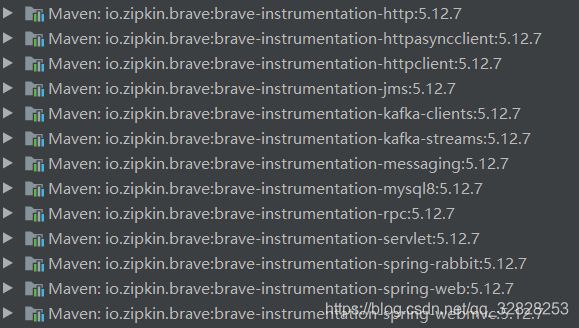
有兴趣可以自己搭建别的组件进行采集,比如kafka
数据库信息采集实现原理
在配置数据库的时候,我们是这样的:
spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?\
useSSL=false\
&queryInterceptors=brave.mysql8.TracingQueryInterceptor\
&exceptionInterceptors=brave.mysql8.TracingExceptionInterceptor\
&zipkinServiceName=userDB\
&useUnicode=true&characterEncoding=utf8\
&allowMultiQueries=true\
&serverTimezone=UTC
其中有几个关键信息:
-
queryInterceptors:配置查询拦截器,我们这里配置的是zipkin的
TracingQueryInterceptorpublic class TracingQueryInterceptor implements QueryInterceptor { /** * sql语句执行前的前置处理 */ @Override public <T extends Resultset> T preProcess(Supplier<String> sqlSupplier, Query interceptedQuery) { // 在当前线程里获取一个span Span span = ThreadLocalSpan.CURRENT_TRACER.next(); if (span == null || span.isNoop()) return null; String sql = sqlSupplier.get(); int spaceIndex = sql.indexOf(' '); // Allow span names of single-word statements like COMMIT // 保存span的信息,如name、sql语句 span.kind(CLIENT).name(spaceIndex == -1 ? sql : sql.substring(0, spaceIndex)); span.tag("sql.query", sql); // 保存服务名、ip、端口信息 parseServerIpAndPort(connection, span); // 启动span span.start(); return null; } /** * 后置处理 */ @Override public <T extends Resultset> T postProcess(Supplier<String> sql, Query interceptedQuery, T originalResultSet, ServerSession serverSession) { if (interceptingExceptions && originalResultSet == null) { // Error case, the span will be finished in TracingExceptionInterceptor. return null; } // 从当前线程中移除span Span span = ThreadLocalSpan.CURRENT_TRACER.remove(); if (span == null || span.isNoop()) return null; // 结束span,完成了一次记录 span.finish(); return null; } } -
exceptionInterceptors:配置异常拦截器,zipkin的
TracingExceptionInterceptor
顾名思义,就是处理sql异常的拦截器,主要是保存一些异常信息到span中@Override public Exception interceptException(Exception e) { // 获取span Span span = ThreadLocalSpan.CURRENT_TRACER.remove(); if (span == null || span.isNoop()) return null; // 保存错误信息 span.error(e); if (e instanceof SQLException) { span.tag("error", Integer.toString(((SQLException) e).getErrorCode())); } // 结束 span.finish(); return null; } -
zipkinServiceName:在zipkin的链路图展示中,db节点的名称
HTTP信息采集实现原理
通过自动配置类TraceWebServletAutoConfiguration自动配置了一个TracingFilter,TracingFilter通过继承javax.servlet.Filter接口来实现对请求过滤,就和我们平时写的filter一样
TracingFilter源码:
public final class TracingFilter implements Filter {
public static Filter create(Tracing tracing) {
return new TracingFilter(HttpTracing.create(tracing));
}
public static Filter create(HttpTracing httpTracing) {
return new TracingFilter(httpTracing);
}
final ServletRuntime servlet = ServletRuntime.get();
final CurrentTraceContext currentTraceContext;
final HttpServerHandler<HttpServerRequest, HttpServerResponse> handler;
TracingFilter(HttpTracing httpTracing) {
currentTraceContext = httpTracing.tracing().currentTraceContext();
handler = HttpServerHandler.create(httpTracing);
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse res = servlet.httpServletResponse(response);
// Prevent duplicate spans for the same request
TraceContext context = (TraceContext) request.getAttribute(TraceContext.class.getName());
if (context != null) {
// A forwarded request might end up on another thread, so make sure it is scoped
Scope scope = currentTraceContext.maybeScope(context);
try {
chain.doFilter(request, response);
} finally {
scope.close();
}
return;
}
// 创建一个span
Span span = handler.handleReceive(new HttpServletRequestWrapper(req));
// Add attributes for explicit access to customization or span context
request.setAttribute(SpanCustomizer.class.getName(), span.customizer());
request.setAttribute(TraceContext.class.getName(), span.context());
SendHandled sendHandled = new SendHandled();
request.setAttribute(SendHandled.class.getName(), sendHandled);
Throwable error = null;
Scope scope = currentTraceContext.newScope(span.context());
try {
// any downstream code can see Tracer.currentSpan() or use Tracer.currentSpanCustomizer()
chain.doFilter(req, res);
} catch (Throwable e) {
error = e;
throw e;
} finally {
// When async, even if we caught an exception, we don't have the final response: defer
if (servlet.isAsync(req)) {
// 异步处理采集请求信息到span
servlet.handleAsync(handler, req, res, span);
} else if (sendHandled.compareAndSet(false, true)){
// we have a synchronous response or error: finish the span
HttpServerResponse responseWrapper = HttpServletResponseWrapper.create(req, res, error);
handler.handleSend(responseWrapper, span);
}
scope.close();
}
}
// Special type used to ensure handleSend is only called once
static final class SendHandled extends AtomicBoolean {
}
@Override public void destroy() {
}
@Override public void init(FilterConfig filterConfig) {
}
}
总结
相信你看到这会发现原来Sleuth原理这么简单。基本都是通过Interceptor或Filter来实现采集的,只不过能够支持更大的范围,不需要我们一个个实现。
在实际生产中,skywaking用得还是比较多的,微服务还是推荐使用这个最好,主要是因为是字节码实现且功能丰富。