文/michael
前言
最近研究下Machaine Learning,这篇文章作为开始吧。
贝叶斯
贝叶斯(Bayes)算法是什么?
我们在大学时都知道概率论吧,条件概率,贝叶斯定理
-
P( A|B )表示在事件B发生的前提下A事件发生的概率:
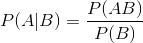
-
而贝叶斯定理我们直接给出:
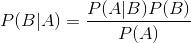
贝叶斯定理之所以有用,是因为我们在生活中经常遇到这种情况:我们可以很容易直接得出P(A|B),P(B|A)则很难直接得出,但我们更关心P(B|A)
朴素贝叶斯分类
朴素贝叶斯分类是一种十分简单的分类算法,朴素贝叶斯思想:对于给出的特定的features,求解在此项出现条件下各个类别出现的概率,哪个概率最大就属于那个类别。
- *先验概率P(A)就是A的先验概率
bayes朴素分类基本步骤:
| x特征属性 | 训练样本(x1,x2,x3...) | 数据准备阶段 |
|---|---|---|
| 计算每个类别的先验概率 | p(yi) | train阶段 |
| 计算各类别下的各个特征属性的条件概率 | p(aj / yi ) | train阶段 |
| 计算样本属于每个类别的概率 | p(x / yi)p(yi) | predict阶段 |
| 取最大项最为x的分类类别 | max( p(x / yi)p(yi)) | predict阶段 |
- _ - 来个直观的

我们这次不用spark的example的data(因为实在不知道代表什么意思)。
我们自己编点吧~
sample_football_weather.txt:
日期|踢足球|天气|温度|湿度|风速|
----|------|----
1,2,3,4...|是(1)否(0)| 晴天(0)阴天(1)下雨(2)|热(0)舒适(1)冷(2)|不适(0)适合(1)|低(0)高(1)
由于MLlib对数据的格式有严格的要求
主要是classification.{NaiveBayes,NaiveBayesModel}的要求data format:
类别,特征1 特征2 特征3.....

训练代码(scala)
import org.apache.spark.mllib.classification.{NaiveBayes,NaiveBayesModel}
import org.apache.spark.mllib.linalg.Vectors
import org.apache.spark.mllib.regression.LabeledPoint
import org.apache.spark.{SparkContext,SparkConf}
object NaiveBayes {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setMaster("local")
.setAppName("NaiveBayes")
val sc = new SparkContext(conf)
val path = "../data/sample_football_weather.txt"
val data = sc.textFile(path)
val parsedData =data.map {
line =>
val parts =line.split(',')
LabeledPoint(parts(0).toDouble,Vectors.dense(parts(1).split(' ').map(_.toDouble)))
}
//样本划分train和test数据样本60%用于train
val splits = parsedData.randomSplit(Array(0.6,0.4),seed = 11L)
val training =splits(0)
val test =splits(1)
//获得训练模型,第一个参数为数据,第二个参数为平滑参数,默认为1,可改变
val model =NaiveBayes.train(training,lambda = 1.0)
//对测试样本进行测试
//对模型进行准确度分析
val predictionAndLabel= test.map(p => (model.predict(p.features),p.label))
val accuracy =1.0 *predictionAndLabel.filter(x => x._1 == x._2).count() / test.count()
//打印一个预测值
println("NaiveBayes精度----->" + accuracy)
//我们这里特地打印一个预测值:假如一天是 晴天(0)凉(2)高(0)高(1) 踢球与否
println("假如一天是 晴天(0)凉(2)高(0)高(1) 踢球与否:" + model.predict(Vectors.dense(0.0,2.0,0.0,1.0)))
//保存model
val ModelPath = "../model/NaiveBayes_model.obj"
model.save(sc,ModelPath)
//val testmodel = NaiveBayesModel.load(sc,ModelPath)
}
}
代码提示:
- randomSplit
def randomSplit(weights: Array[Double], seed: Long =Utils.random.nextLong): Array[RDD[T]]
该函数根据weights权重,将一个RDD切分成多个RDD。该权重参数为一个Double数组第二个参数为random的种子,基本可忽略。 - 保存model
继承于NaiveBayesModel 的model.save和load方法,存成对象方便下次使用,(注意python API 可不支持这个用法,所以写spark推(yi)荐(ding)要用scala) - val model =NaiveBayes.train(training,lambda = 1.0)
这个高度封住的计算公式是不是看的非常棒呀~
我们来试着看看里面有什么
详细算法我也是看的这个blog
我自己也写了点(字有点难看,,好久不动笔了)

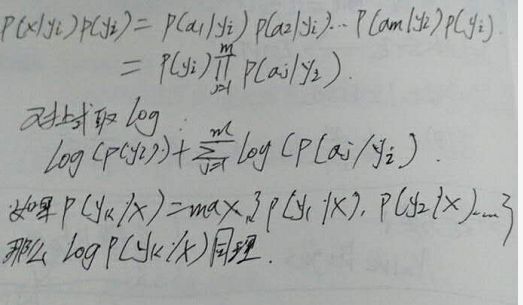
给学习步骤中的两个概率计算公式,分子和分母都分别加上一个常数,就可以避免。这个方法称为拉普拉斯平滑
也就是代码中的NaiveBayes.train(training,lambda = 1.0)
也可以看看这个blog写的很好,其中也有一个更高端的文本分类训练
测试
我们究竟能不能相信计算机的结果呢
就是我们的“假如一天是 晴天(0)凉(2)高(0)高(1) 踢球与否”问题
我们来手动算算:
P(踢)=9/14 #所有数据中踢球的占比
P(晴天|踢)=2/9 #所有踢球的是晴天的占比,后面以此类推
P(凉爽|踢)=3/9
P(湿度高|踢)=3/9
P(风速高|踢)=3/9
P(踢)* P(晴天|踢)* P(凉爽|踢)* P(湿度高|踢) *P(风速高|踢)=0.0053
-----------------------------------------萌萌哒分割线------------------------------------------
P(不踢)=5/14
P(晴天|不踢)=3/5
P(凉爽|不踢)=1/5
P(湿度高|不踢)=4/5
P(风速高|不踢)=3/5
P(不踢)* P(晴天|不踢)* P(凉爽|不踢)* P(湿度高|不踢) *P(风速高|不踢)=0.02057
可以看到 P(不踢) > P(踢) 所以我们println的结果也是
NaiveBayes精度-----> 0.75 #这个好像不太高,数据量上去就好了。
假如一天是 晴天(0)凉(2)高(0)高(1) 踢球与否:0.0
结语
其实现在machine learning的工具很多,tensoflow等。。。工具代码什么都是高度封装的,重要的是里面的算法,博主的线代,概率论一般,但不想当架构师的程序员不是好的相声演员啊~
可以看到ML的难度还是有的,共勉~