Percentile
计算百分位数。PDF P438的例子。
当y=(n+1)*p/100 不是整数时,比如12.5, 那么取第12个和第13个数,然后用(v13-v12)(12.5-12)+v12 这样算。即在两个数之间,又按比例取了一个数
注意quitile,quartile这些,不一定是和换算为20,25百分位的数值完全相等。因为百分位可能不整除,而4分,5分位整除。
Coefficient of variation: 注意这个是变异系数,不是协方差。定义是标准差/平均值。比如一组数较小,一组数较大,但标准差相同。这两个
标准差就无法说明哪组数的波动性更大。但除以平均值后就可以说明了。
切比雪夫不等式:从平均值出发,偏离正负K个标准差(K>1)之内包含的数据点占整个集合的百分比,不低于1-1/k^2
夏普比率: (组合收益-无风险收益)/组合收益的标准差。 衡量的是每一点风险带来的超额收益(相对于无风险收益)
如果没有无风险收益做参照物,那么就不可比。例如我把标准差弄的很小,但收益也较低,比率仍然可以比较大。有了无风险收益做对比,大家就被拉到了一个起跑线上
注意如果夏普比率为负,那么有可能标准差越大,夏普比率越大(往0的方向靠近)。这种情况就不能说夏普比率越大越好。
夏普比率的另一个应用是,他是用标准差衡量风险的。如果有些模型天然就是高频交易,每次盈利一点点,但有可能频率较低的有大额亏损,可能就不适合
偏度skewness :
sk=(各个值与均值之差的立方/标准差的立方)/n (n较大,如>100时.n小时公式为n/((n-1)(n-2)) )
偏度衡量整个分布是往左偏还是往右偏。
丰度kurtosis :
kt=(各个值与均值之差的立方/标准差的立方)/n (n较大,如>100时.n小时公式为n(n+1)/((n-1)(n-2)(n-3)) )
相对丰度:
kt' = kt-3 3是正态分布的丰度。这个值衡量的是相对于正态分布的丰度。
丰度较大,意味着fatter tail,表示偏离度可能比较大。一般来说丰度>1就算是比较大了。
有了丰度、偏度基本可以衡量一个历史数据的偏离度和大部分值落在哪里。
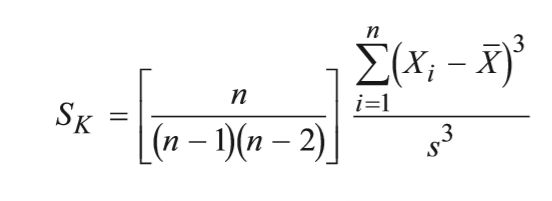
偏度形容了整个数据集往左偏还是往右偏。
错题的经验:
1. 读题不仔细。看清楚是mean,median。 看清楚起止日期。
2. 调和平均数计算平均价格。调和平均数
条件概率的理解:

条件概率的定义这样理解比较好:A和B的概率各是一个圈。A,B同时发生的概率是两个圈的交集。要求两个圈的交集部分占B圈的面积,就是P(AB)/P(B). 但这种理解并不好解释在A和B独立的情况
注意如果A和B独立,则从上述两个公式中可以推出P(A|B)=P(A). 所以大部分的场景下,考虑条件概率一般是A和B不相互独立。
还有一个公式是:
P(AB) = P(A | B)P(B) 是第一个公式的简单变形。
书中P492的例子(A是收益大于无风险收益的概率,0.7, B是收益大于0的概率,0.8)是一种特殊情况。收益大于无风险收益,那么收益肯定是大于0的,所以0.7是一个P(A&B),符合上述公式。
进入数学期望部分
前面所讨论的是基于样本的统计,描述了一组数据的集中程度、偏离集中点的程度。
数学期望则是一种预期,是一种预测,不是对已有数据的描述。但做出预测的基础还是已有的一些信息。期望还有另外一种解释,即样本在无穷大时的均值。
已经知道了随机变量的一些分布信息,比如有p1的概率取值为v1, 有p2的概率取值为v2 ,等等。然后需要给一个随机变量预测一个期望值,就是数学期望。
在前面做样本统计的时候,方差被用来描述样本偏离均值的程度。一个随机变量的方差用下面公式定义:

随机变量的方差,被定义为(随机变量与数学期望的差的平方)的数学期望。
(X-E(X))^2 这个东西没有办法计算出来。因为X是一个随机变量。但这个东西的数学期望却是可以计算的,基于已有的信息。如下公式,X1,X2到Xn都代表一个样本点(或者说我们估计的以某个概率发生的事件)。P(Xn)代表了样本点发生的概率。
所以,上述方差公式展开后就变为:

这个公式比较重要。

数学期望树
这个树比较重要。划清楚这个树对于整理思路很有帮助。
如果一个随机变量是由几个随机变量构成的,每个随机变量有一定的权重,这就是投资组合的数学模型。
要求组合的数学期望,将各组成部分的数学期望求出来,然后乘以权重,再相加就可以了。
对于一个组合的方差,是如下公式:Rp代表Return of Portfolio 。
其中w1代表组合中第一个随机变量的权重,R1代表第一个随机变量。

从而最终推导出:

这是一个比较漂亮的N*N矩阵。对角线为每个随机变量的方差。其中cov协方差的定义:

i==j的时候,协方差就是方差。
一般来说,乘积的期望不等于期望的乘积,除非变量相互独立。所以协方差不能理解为E(Ri-ERi) * E(Rj-ERj)
(R-ER) ,有可能是负的,也有可能是正的,代表了独立变量在多大程度上,哪个方向上对期望的偏离。
两个独立变量距离各自期望的偏离之积。而这个积的期望反应的是这个积在样本无穷大时,这个积的值。当样本空间非常大时,这个积有如下趋势:
1,如果两个独立变量不相关(这里的不相关指不线性相关)或者独立,那么这个积趋向于0. 因为样本多了之后正负最终要相抵。
2,如果两个变量的变化方向相同,那么样本超多之后,这个积一定是正的或负的
协方差的符号说明了两个变量在变化上的相关性。其值的大小在一般的数学问题上没有意义,因为两个变量的量纲可能差距较远。但在计算投资回报时,因为投资回报率都是在-100%到100%波动,所以其值也衡量了波动的大小。
对于一般的数学问题,需要消除掉量纲的影响。消除量纲的方法是协方差除以每个变量的标准差,得到一个东西,这个东西就是相关系数:
相关系数 correlation= Cov(a,b)/(std(a)*std(b))
仍然注意这里的相关指的是线性相关。相关系数为1代表完全正相关,0代表完全不相关,-1代表完全负相关。
两个随机变量独立的定义:P(AB)=P(A)*P(B) 这和前面条件概率的讨论是一致的
两个随机变量不相关的定义:E(AB)=E(A)E(B)
贝叶斯公式:
公式比较简单,从条件概率的变形即可得到:
因为 P(A|B)*P(B)=P(B|A)*P(A)=P(AB)
所以P(A|B)=P(B|A)*P(A)/P(B)
关键是此公式代表的现实意义和如何使用。当A是一个已知信息,B是新发生的信息,那么当B发生时,我如何更新A发生的概率?