本文为论文《Deep Learning for Generic Object Detection: A Survey》的译文,译者能力有限,仅供参考。
由于平台字数限制,本文分成两部分,第二部分。
概述
对象检测(Object detection)是计算机视觉中最基本且具有挑战性的问题之一,其试图在自然图像中定位出属于大量预定义类别集的对象实例(instances of objects)。深度学习技术已经成为一种直接从数据中学习特征表征的强大方法,而且在通用对象检测方向取得了显著突破。在当前对象检测快速发展的时期,本文的目标是提供一个全面的关于深度学习在该方向最新进展的报告。本报告包含了300多个研究,涵盖通用对象检测的多个方面,如检测网络框架(detection frameworks)、对象特征表征(object
feature representation)、对象区域建议生成(object proposal generation)、上下文建模( context modeling)、训练方法和评估指标(evaluation metrics)。本文最后以提供确定的未来研究方向作为结束。
关键字 对象检测( Object detection) 深度学习(deep learning) 卷积神经网络( convolutional neural
networks) 对象识别( object recognition)
1 简介
作为具有挑战性的计算机视觉基础任务之一,对象检测一直是近二十年来活跃的研究领域(如图1所示) [74] 。对象检测的目标是在给定的图片中确定是否存在预定义类别的对象实例(如人类、汽车、自行车、狗或者猫),如果存在,给出每个对象实例在图片中的空间位置和范围,例如以边界框(bounding box)的方式给出 [66,230]。作为图像理解( image understanding)和计算机视觉的基础,对象检测构成了解决复杂或者高级视觉任务的基础,例如分割(segmentation)、场景理解(scene understanding)、对象追踪(object tracking)、图像描述(image captioning)、事件检测(event detction)和动作识别(activity recognition)等。此外,对象检测还有广泛的应用,包括机器人视觉(robot vision)、消费电子产品(consumer electronics)、安防(security)、自动驾驶(autonomous driving)、人机交互(human computer interaction)、基于内容的图像检索(content based image retrieval)、智能视频监控(intelligent video surveillance)和增强现实(augmented reality)。

最近,深度学习技术 [102,145] 已经成为一种强大的直接从数据中学习特征表征的方法。特别是这些技术也为对象检测带来了巨大的提升,如图3所示。
如图2所示,对象检测可以分为两种 [88,302] :特定类别的对象实例检测和多种类别的对象实例检测。第一种的目的是检测特定类型的对象实例(例如唐纳德川普的脸、埃菲尔铁塔或者邻居的狗),其本质上是一个匹配问题。第二种的目标是检测(一般是之前未见过的)多个预定义类别(如人类、汽车、自动车和狗)的对象实例。过去,对象检测领域大部分研究都是聚焦在单一类别(尤其是人脸和行人)或者少量特定类别的对象检测上。相反,在过去几年,研究者们开始将目光转移到构建更具有挑战性的通用对象检测系统上,其对象检测能力的广度可以与人类媲美。
在2012年,Krizhevsky等人 [136] 提出称为AlexNet的深度卷积神经网络(DCNN),在ILSVRC(Large Scale Visual Recognition Challenge ) [230] 的图像分类比赛中获得了破纪录的精度。从那时起,许多计算机视觉领域的研究重点就集中在深度学习方法上,甚至包括通用对象检测 [83,96,82,235,226]。尽管如图3所示通用对象检测已经获得了巨大的发展,但是我们仍没有一个对过去五年发展有一个全面总结的文献。鉴于目前的研究进展速度异常之快,本文试图对近年来的研究进行跟踪和总结,以便更清晰地了解当前通用对象检测领域的全貌。

1.1 与过往综述文献的对比
如表1所示,目前已有很多著名的对象检测相关的综述文献。很多文献主要关注特定对象检测问题,如行人检测 [64,77,57]、人脸检测(face detection) [287,294]、车辆检测(vehicle detection) [251] 和文本检测(text detection) [288]。直接关注通用对象检测的文献则相对较少,其中Zhang [302] 等人发表了关于对象检测的综述文献。然而, 在 [88,5,302] 中囊括的主要是2012年之前的研究,并未涵盖最近几年的突破发展以及并未彰显深度学习相关方法的主导地位。
深度学习使得计算模型能够学习极其复杂、微妙和抽象的表征,推动了视觉识别、目标检测、语音识别(speech recognition)、自然语言处理(natural language processing)、医学图像分析(medical image analysis,)、药物发现( drug discovery)和基因组学(genomics)等广泛领域取得了重大进展。在多种不同的深度神经网络类型中,DCNN [144,136,145] 为处理图像、视频、声音和音频数据带来了巨大的突破。当然,已经有很多关于深度学习的相关综述文献,包括 Bengio等人 [13],LeCun等人 [145],Litjens等人 [166],Gu等人 [89], 还有最近在ICCV和CVPR上发表的报告。
虽然目前已经提出了许多基于深度学习的目标检测方法,但还没有一个全面的、最新的综述文献。对现有研究的深入探讨和总结,是对象检测的进一步进展所必不可少的,特别是对于希望进入该领域的研究人员。由于我们的阐述重点是通用对象检测,所以针对特定对象的检测问题,如人脸检测 [150,299,112]、行人检测 [300,105]、车辆检测 [314]、交通标志检测(traffic sign detection)[321] 等,不在本文的阐述范围内。
1.2 范围
基于深度学习的通用对象检测论文数量是惊人的。事实上,撰写任何对技术现状的全面回顾都超出了任何合理论文的长度范围。因此,有必要建立选择标准,我们便把本文的重点限制在顶级期刊和会议论文上。由于这些限制,我们真诚地向那些作品没有包含在本文中的作者致歉。关于其他相关主题的综述文献,请读者参考表1中的文章。本文将注意力集中在过去五年的主要进展上,我们还将只关注基于静态图片的上相关算法,基于视频的对象检测问题更适合放在一个单独的主题文献中。
本文的主要目的是对基于深度学习的通用对象检测技术进行全面的研究,并主要基于流行的数据集、评估指标(evaluation metrics)、上下文建模和区域建议方法,本文提供一定程度的分类、高层视角和组织。我们的目的是帮助读者理解各种策略之间的异同。提出的分类法为研究人员提供了一个框架,以了解当前的研究,并确定未来研究面临的开放挑战。
本文的其余部分组织如下。第2部分概述了相关背景,包括问题的定义、主要的挑战和过去二十年来取得的进展。第3部分简要介绍了深度学习。第4部分总结了常用的数据集和评价标准。第5部分描述具有里程碑意义的对象检测框架。从第6部分到第9部分,讨论了设计对象检测器所涉及的基本子问题和相关问题。最后,在第10部分我们全面讨论了对象检测,包括一些SoA框架的性能,并分析了未来的几个研究方向。

2 通用对象检测
2.1 问题定义
通用对象检测(即通用对象类别检测),也称为对象类别(class)检测 [302] 或者对象种类(category)检测,其定义如下:给定一张图片,对象检测的目标是确定该图片中是否存在预定义类别(一般会有很多种类,如ILSVRC的对象检测挑战中有200个种类)的对象实例,如果存在,给出每个对象实例在图片中的空间位置和范围。此处更强调的是在更广泛的自然类别上进行检测,而不是指特定的对象类别检测,这些对象属于一个较窄范围的感兴趣的预定义类别(集合)(例如,人脸、行人或汽车)。虽然成千上万的物体占据了我们生活的视觉世界,但目前研究领域主要关注高度结构化的物体(如汽车、人脸、自行车和飞机)和有关节连接的物体(如人、牛和马)的定位,而不是非结构化的场景(如天空、草地和云)。


对象的空间位置和范围可以用一个边界框(bounding box)(一个紧紧包围对象的矩形框) [66,230] 表示,或者用精确度更高的像素级分割掩码表示,又或者是一个封闭的区域 [162,231],如图5所示。据我们所知,在当前的文献中,为了评估通用对象检测算法,边界框是被使用最广泛的,这也是本文使用的方法。然而,随着研究社区对场景理解的不断深入(从图像级别的对象分类到单个对象定位,到通用对象检测,再到像素级的对象分割),可以预见的是将来的挑战是在像素级别 [162]。
有许多问题是与通用对象检测紧密相关的。对象分类的目标是确定图像中有没有属于给定数量的对象类别(集合)的对象存在,即对一个给定的图像指定一到多个对象类别标签,并不需要指出所指类别对象的位置。在图像中定位实例的额外要求使得检测比分类更具挑战性。对象识别问题是指对图像中出现的所有对象进行识别/定位时面临的更加普遍的问题,包括目标检测和分类问题 [66,230,194,5]。通用对象检测更加接近图像语义分割( semantic image segmentation)(图5(c)),其目标是将图像中的每个像素分配一个语义类别标签。对象实例分割(Object instance segmentation)(图5(d))旨在区分相同对象类别的不同实例,语义分割并不做这样的区分。
2.2 主要挑战
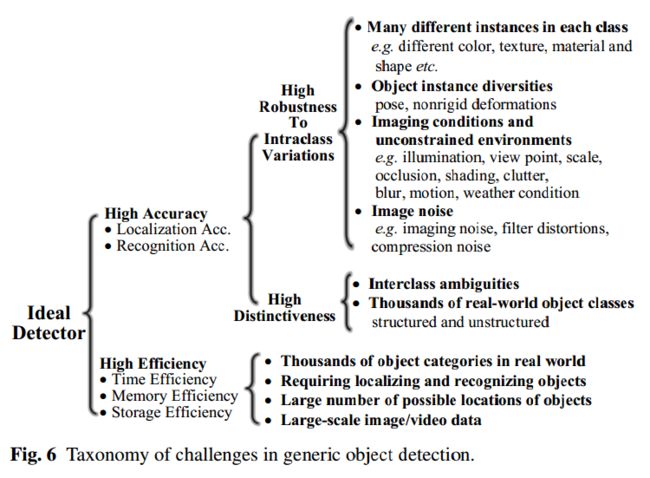
理想的通用对象检测目标是开发一种通用的算法,其可以达到高效(high efficiency)且高质量或高精度(high
quality/accuracy)的目标,如图6所示。如图7所描述的,高质量检测能以高精度的效果定位和识别图像或者视频帧上的对象,因而真实世界的大量对象种类可以被分辨出来(即高区分性),并且在类内外观发生变化的情况下,来自同一类别的对象实例仍然可以被定位和识别(即高健壮性)。高效率则要求整个检测任务在可接受的内存和存储限制下实时运行。
2.2.1 精度相关挑战
准确性的挑战主要源于:大量的类内变化(intraclass variations)和大量的对象类别。
我们从类内变化开始阐述,其可以被分为两种:类内固有的变化因素(intrinsic factors)和图像成像条件(imaging conditions)。在类内固有的变化因素方面,每个对象种类可以有很多种不同的对象实例,它们可能在一种或多种因素上产生变化,如颜色、纹理、材料、形状和尺寸等,例如图7(i)所示的椅子种类。即使是定义更加狭窄的种类,如人类或者马,对象实例仍然可以以不同的姿态、不同的非刚体形变或者不同的服装出现。
对于图像成像的因素,变化是在成像过程中产生的,因为非限制的环境会严重影响对象的外观。而且,一个给定的对象实例的图像可以在许多不同的情况下被捕获,如日光(黎明、白天、黄昏)、位置、天气情况、摄像机、背景、光照、遮挡情况和观察距离等。所有这些条件都会造成物体外观的显著变化,如光照、姿态、尺寸、遮挡、拥挤、阴影、模糊和运动,如图7(a-h)例所示。进一步的挑战可能还包括数字化处理、噪声干扰、低分辨率和滤波失真( filtering distortions)。
另外,对于类别变化,大量的类别种类,如 到量级,则要求检测器具有很强的分辨能力,能够区分类间(interclass)的细微变化,如图7(j)所示。实际上,当前的检测器主要还是关注结构化类别,如PASCAL VOC [66] 、ILSVRC
[230] 和MS COCO [162] 中各自对应的20、200和91个类别。显然,现有基准数据集中的对象类别数量比人类能够识别的要少得多。

2.2.2 效率和可扩展性相关挑战
社交媒体网络和移动或可穿戴设备的普及,使得分析视觉数据的需求越来越大。然而,移动或可穿戴设备的计算能力和存储空间有限,在这种情况下,高效的目标探测器是至关重要的。
性能方面,挑战主要是随着对象类别数量和单个图片中可能出现对象的位置和尺寸的大量增加,定位和识别需要更多的计算量,如图7(c,d)所示。另外的挑战是可扩展性,即检测器应该能够处理未曾见过的对象、未知的情况和快速增长的图像数量。例如,ILSVRC的规模 [230] 已经达到了人工标注的极限。随着图像数量和类别数量越来越多,手工标注将变得不可能,这迫使算法需要更多地依赖弱监督的训练数据。这一系列成功的对象检测器为这一领域的后续研究奠定了基础。
2.3 过去20年的进展
早期的对象识别是基于模式匹配(template matching)技术和简单部件建模(simple part based model) [74] ,主要关注的是识别空间分布大致为刚性的特定对象,例如人脸。1990年之前,对象识别的主导范式是基于几何表征 [186,211] ,随后焦点又从几何和先验模型(prior model)转移到基于外观特征(appearance features) [187,232] 的统计分类器上(如神经网络 [299]、 SVM [197] 和Adaboost [269,283])。
20世纪90年代末到21世纪初,对象检测研究取得了显著的进步。图4罗列了部分目前里程碑式的工作,其中两个主要的时期(SIFT和DCNN)值得被强调。外观特征从全局表征(representation ) [188,253,260] 转移到局部表征,这些局部表征被设计为不受平移、尺寸、旋转、光照、观察点和遮挡等变化的影响。手工设计(handcrafted)的局部不变特征获得了研究者极大的青睐,从尺度不变特征变换(SIFT)特征 [174] 开始,各种视觉识别任务的进展很大程度上是基于局部描述子(local descriptor) [183] 的使用, 例如Haar like feature [269]、SIFT [175]、Shape Context [12]、Histogram of Gradients (HOG) [50] 、 Local Binary Patterns (LBP) [192] 和covariance [261]。这些局部特征还经常使用简单的串接或特性池编码器(feature pooling encoder)来增强效果,如由Sivic、Zisserman [247] 和Csurka 等 [45] 提出的有效视觉词袋方法(efficient Bag of Visual Words)、空间金字塔匹配(SPM Spatial Pyramid Matching) [143] 和Fisher Vectors [208]。
多年来,由手工设计的局部描述子和判别分类器组成的多阶段手工调校检测流水线在计算机视觉领域占据着主导地位,包括对象检测,转折点发生在2012年DCNN [136] 在图像分类领域取得了破纪录的成绩。
将CNN用于检测和定位可以追溯至20世纪90年代。具有少量隐藏层的神经网络在最后二十年一直被用于目标检测 [265,229,234]。直到最近几年,它们才在一些如人脸检测之类的限制场景中取得成功。最近,深层CNN已经在更加通用的对象类别检测上取得了突破进展。这一转变是由于DCNN被从在图像分类上的成功应用 [136] 转移到目标检测上,从而产生了由Girshick等人提出的具有里程碑式的RCNN检测器 [83]。从那时起,大量的目标检测研究便建立在快速发展的RCNN工作的基础上之上。
深度检测器的成功在很大程度上依赖于数据和具有数百万甚至数十亿参数的高耗能深度网络,而具有极高计算能力的GPU和可获得具有完全边界框标注的大规模检测数据集是它们成功的关键。然而,精确的标注则需要大量的劳动才能获得。因此,检测器必须考虑能够减轻标注困难或能够使用小型训练数据集进行学习的方法。
DCNN在图像分类中的成功应用 [136] 转入目标检测领域,从而产生了由Girshick等人提出的具有里程碑式的RCNN检测器 [83]。从那时起,对象检测领域发生了巨大的变化,许多基于深度学习的方法被开发出来,这在一定程度上要归功于可用的GPU计算资源、大规模数据集和像ImageNet [52,230] 和 MS COCO [162] 这样的比赛。有了这些新的数据集,当研究人员在具有较大类内差异和类间相似性(interclass similarities ) [162,230] 的图像中检测数百个类别的对象时,可以解决(target)更现实和更复杂的问题。
研究社区已经开始朝着建立通用目标检测的目标迈进,这个目标具有挑战性,即能够检测出与人类相匹配的大量对象类别的通用目标检测系统。这是一个主要的挑战:根据认知科学家的研究,人类总体上可以识别大约3000个初级类别(entry level categories)和30000个视觉类别(visual categories),而领域专家可识别的类别数量可能在个左右 [15]。尽管在过去的几年中取得了显著的进展,但是设计一个精确、健壮、高效的检测和识别系统,使其在到个类别上的性能接近人类水平,无疑是一个有待解决的问题。
3 深度学习简要概述
深度学习已经彻底改变了众多机器学习任务,从图像分类和视频处理到语音识别和自然语言理解。在这个飞速发展的时代,最近有很多关于深度学习的综述论文 [13, 86, 89, 145, 166, 212, 280, 290, 305, 312, 317]。这些文献从不同的角度回顾了深度学习技术 [13, 86, 89, 145, 212, 280, 312],包括在医学图像分析的应用 [166]、自然语言处理 [290]、语音识别系统 [305] 和遥感 [317]。
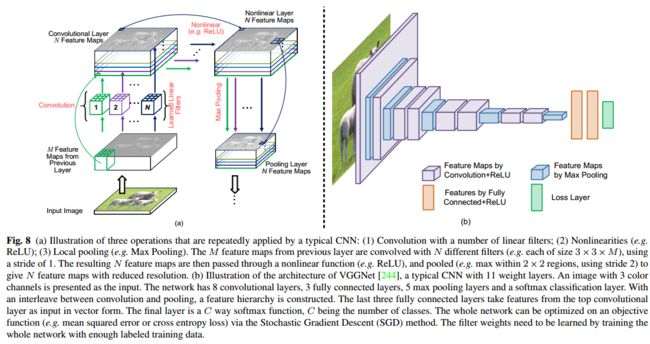
CNN是最具代表性的深度学习模型。CNN能够利用潜在自然信号的基本特性:平移不变性、局部连通性和分层结构 [145]。一个典型的CNN具有层次结构,由多个层次(如卷积、非线性、池化等)组成,从而学习具有多层抽象的数据表征 [145]。池化对应于对特征图进行下采样或上采样。卷积和非线性可以表示为:
其中,表示第层的第个二维输入特征图,表示第l层的第j个输出特征图,表示二维卷积运算,表示偏置项。表示第l-1层的特征映射数量。表示进行元素级(elementwise)运算的非线性函数,具体地可以是整流线性单元(ReLU),对每个元素的操作如下:
如图8(a)所示,是一个典型的重复使用上述三种操作的CNN过程。DCNN具有大量称为“深度”网络(“deep”network)的层,如图8 (b)所示是一个典型的DCNN结构。
从图8 (b)可以看出,CNN的每一层都由若干个feature map组成,其中每个像素都像一个神经元。卷积层中的每个神经元通过一组权重(本质上是一个过滤器)与前一层的特征图连接。如图8 (b)所示,CNN的较浅层(early layers)通常由卷积层和池化层组成。后面的一些层通常是完全连接层( fully connected layers)。每对层之间通常都存在某种非线性(操作)。
从较浅层到较深层,输入图像反复执行卷积,每一层的感受视野(receptive field)(支持区域)较前层增大。一般来说,较浅层CNN层提取低层特征(low-level features)(如边缘),随后的层提取复杂度越来越高的特征 [296, 13, 145, 195]。
DCNN有许多突出的优点,如:层次结构可以学习数据的具有多个抽象层次的表征,能够学习非常复杂的函数,以及以最少领域知识直接且自动地从数据中学习特征表征。让
DCNN变得可行的原因是大规模标注数据集的可获得性和可供使用的具有很高计算能力的GPU。
尽管取得了巨大的成功,但已知的缺点仍然存在。特别是,对有标注的训练数据和昂贵的计算资源的极度依赖,以及选择适当的学习参数和网络结构仍然需要相当多的技巧和经验。已训练的网络解释性差,对图像变换和退化缺乏鲁棒性,许多DCNN表现出严重的易攻击(attacks)性,所有这些都限制了DCNN在现实世界中的许多应用。
4. 数据集和性能评估
4.1 数据集
数据集在对象检测研究的历史中扮演着重要的角色,它不仅是作为评估和比较算法之间性能的共同基础,而且推动领域朝着解决更加复杂、困难的问题方向前进。尤其对于深度学习在各个方面取得的突破发展,大量的标注数据集起到了至关重要的作用。由于现在可以轻易获得互联网图片数据,所以有可能创建包含很多类别的大型数据集。这使得算法可以学习到更加丰富和多元的类别对象,从而获得前所未有的性能。
针对通用对象检测,目前有四个著名的数据集:PASCAL VOC [66, 67],ImageNet [52],MS COCO [162] 和Open Images [139]。表3总结了这些数据集的特征,图9展示了数据集中的部分图片。创建大型标注数据集需要三步:确定目标类别集合; 从互联上收集多元的能够代表预选类别的图片;标注已收集的大量图片。最后一步一般是通过设计众包策略将数据标注工作外包实现的(也是最有挑战性的一步)。由于篇幅有限,我们建议有兴趣的读者参考这些数据集的原始论文 [66, 67, 162, 230, 139] 以了解更多细节。

四个数据集构成了各自检测比赛的基础。每个比赛由以下几个部分组成:公开可获得的带有标注标签和标准验证软件的数据集、每年举办一次的比赛和对应的研讨会。表4总结了各个数据集用于检测比赛的训练、验证和测试图片数量以及对象实例数的统计信息。表2总结了最常出现在这些数据集中的对象类别。



PASCAL VOC [66,67] 是一个多年来致力于创建和维护一系列用于分类和对象检测的基准数据集,以年度比赛的形式开创了对识别算法进行标准化评估的先例。从2005年仅有的4个类别开始,数据集已经增加到日常生活中常见的20个类别,如图9所示。
对于PASCAL VOC比赛来说,自2009年以来,每次的数据由前几年的数据加上新数据组成,图片数量不断增长,更重要的是,这意味着测试结果可以按年进行比较。由于像ImageNet、MS COCO和Open Images这样的大型数据集的开源,PASCAL VOC已逐渐过时。
ILSVRC ,即大规模视觉识别挑战赛(the ImageNet Large Scale Visual Recognition Challenge) [230] ,源自ImageNet [52]。在对象类别数量和训练数据量方面,ILSVRC将PASCAL VOC的标准化训练和评估目标提高了一个数量级。ImageNet的数据子集(ImageNet1000)已经成为图像分类比赛的标准基准,其包含1000个不同的对象类别,120万张图片。ImageNet1000也通常用于DCNN的预训练。
MS COCO 是对ImageNet的批评的回应,对ImageNet数据集批评的原因是该数据集中的对象往往比较大且位于图片中间,这样不符合现实世界场景。为了推动对图像更丰富的理解研究,研究人员创建了MS COCO数据集 [162], 包含了复杂的日常场景和自然环境中的常见对象,更加接近真实生活,其中对象使用全分割实例(fully-segmented instances)方式进行标记,以此提供更准确的检测器评估。COCO对象检测比赛 [162] 可能是最具挑战性的检测基准,具有两个对象检测任务:使用边界框(bounding box)作为输出和使用对象实例分割作为输出。与ILSVRC相比,它具有更少的对象类别,每个类别有更多的实例,并且包含ILSVRC没有的对象分割标注。COCO主要提出了三个新的挑战:
- 它包含的对象尺寸变化范围较大,小目标对象占有比较高的比例 [245];
- 对象(表现)并不那么单调(iconic),而且处于杂乱环境或存在严重的遮挡;
- 评估指标(见表5)鼓励更精确的对象定位。
就像当时的ImageNet一样,MS COCO现在已经成为对象检测的标准,表4总结了用于训练、验证和测试的数据集统计信息。
OICOD (the Open Image Challenge Object Detection)源于Open Images V4 [139],这是目前开源的规模最大的对象检测数据集,第一次比赛是在2018年的ECCV上举办的。OICOD不同于之前的大规模对象检测数据集,如ILSVRC和MS COCO,不仅在类别数量、图片和边界框标注数量上有大幅增加,而且标注过程也不一样。在ILSVRC和MS COCO中,每个感兴趣类别的对象实例都需要被人工尽力标注出来。但是对于Open Images V4,先使用一个分类器对每张图片进行分类,并且将拥有高得分的分类结果发送给人类进一步确认。因此,在OICOD中,每个照片中只有被人类确认的正样本实例才会被标注出来,没有被确认的对象实例是不会被标注的。OICOD还有视觉关系标签,但是没有对象分割标签。
4.2 评估指标
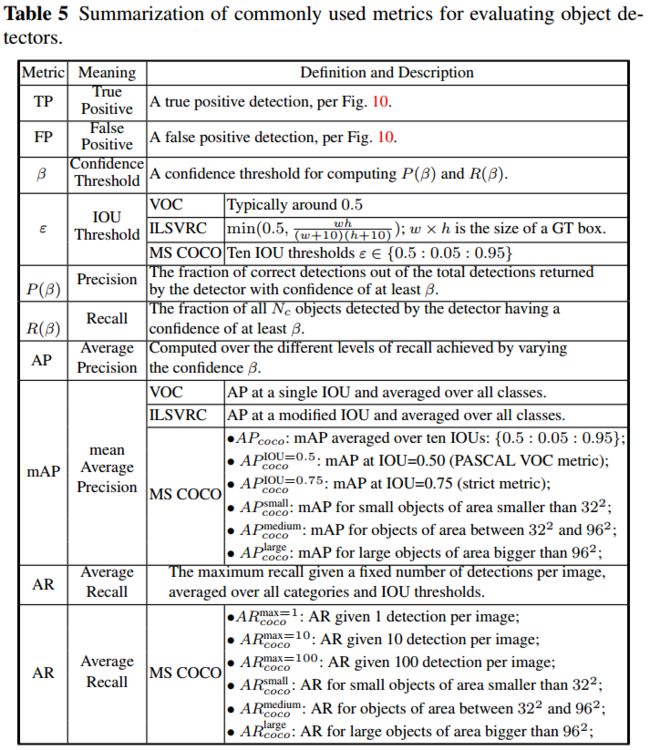
主要有三个指标用来评估检测算法的性能:检测速度(每秒帧,FPS)、精度(precision)和召回率(recall)。通常最常用的平均精度(Average Precision,AP),来源于精度和召回率。AP常常是用于评估特定类别的方法,如用于分别计算每种类别的检测精度。为了对比算法在所有类别上的整体性能,通过计算所有类别的平均AP以获得期望平均精度(mean AP,mAP)作为最终的性能评估。更多的细节可以参考 [66, 67, 230, 104]。
应用于测试图像I的检测器的标准输出为预测的检测结果,为索引值(表示预测的第个实例)。一个特定的检测(为了叙述方便,省略)表示以置信度为预测到图片中有类别的对象实例,且位置为(如boundbing box,BB)。同时满足以下两点的预测被认为(在训练或测试时)是真阳性的(True Positive,TP):
- 预测的BB b与真实标签BB 的交并比不小于预定义的阈值(IoU,Intersection Over Union)[66, 230]。
- 预测的标签c与真实标签类别相同
IOU的计算公式为:
此处,指预测边界框和真实标签边界框面积的交集,是它们面积的并集。典型的阈值值为0.5。除此之外,其他被认为是假阳性(False Positive ,FP)。置信度通常与另外的阈值进行比较,用来决定预测的类别标签是否应该被接受(译者补充:置信度主要在推理时使用,即没有groud truth标签时,这时使用置信度阈值用来决定哪些预测应该被接受,通俗的理解,就是在推理前人类告诉算法,我只接受你的预测把握(置信度)超过设定的阈值的检测结果,其他抛弃掉,因为在推理时根本没有groud truth标签告诉算法哪些预测是真阳性,哪些预测是假阳性)。
AP是分别基于每个类别的精度和召回率计算得到。具体地计算方法为:对于特定的类别和测试图片,使用表示检测器返回的个检测结果列表,根据置信度对所有结果递减排序。使用表示图片上个关于类别的所有标注标签。每个检测结果可以通过图10中的算法确定是TP还是FP。基于划分的TP和FP结果,可以通过一个以置信度阈值为变量的函数计算精度和召回率 [66],从而随着信度阈值的变化可以得到不同的结果对。大体上可以认为精度是关于召回率的函数(),从中可以得到平均精度(AP)结果 [66,230]。
自从MS COCO的提出以来,更多的注意力放在了边界框定位的准确性上。MS COCO提出了更多的度量指标(表5)来刻画检测器的性能,以此取代固定的IoU阈值。例如,不同于传统的使用固定的IoU阈值0.5,用来表示每个类别在多个IoU阈值上AP的平均值,这些IoU阈值的变化范围为以0.05为步长从0.5递增到0.95。由于在MS COCO中有41%的对象是小目标(面积小于),24%的对象是大目标(面积大于),所以COCO也引入了、和三个评估指标。最后,表5总结了分别在PASCAL,ILSVRC和MS COCO比赛中主要使用的指标,最近的 [139] 提出了对PASCAL VOC的mAP指标进行修改的观点。

5. 检测框架
用于识别的对象特征表征和分类器已经有了稳定的进展,从手工特征 [269,50,70,95,268] 到学习的DCNN特征 [83,199,82,225,48] 发生了巨大的变化。
与此相反,用于定位的基本滑动窗口方法 [50, 72, 70] 仍是主流 [141, 264]。然而,窗口的数量很大,并且随着像素数量增加呈二次增长,尤其需要在多个尺度和长宽比(aspect ratios)上进行搜索,这进一步增加了搜索空间。因此,设计有效且高效的检测框架是至关重要的。通常采用的策略包括级联(cascading)、共享特性计算(sharing feature computation)和减少每个窗口的计算量。
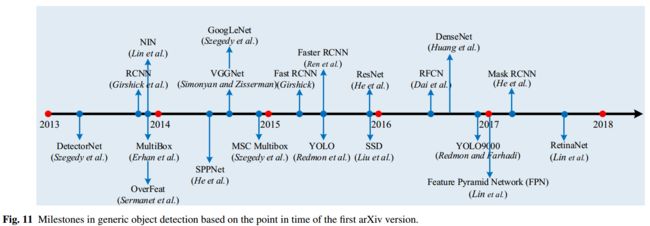
在本章节,我们将回顾自从深度学习进入通用对象检测领域以来,出现的里程碑检测框架,如图11和表11(见文末)所示。过去几年提出的几乎所有检测器都是基于这些里程碑式检测器中的某一个,试图改进一个或多个方面。这些检测器大致可分为两大类:
- 两阶段检测框架,其包括一个用于生成对象建议(区域)的预处理步骤,从而使整个检测流程(pipeline)分为两阶段。
- 单阶段检测框架,或称为无建议区域框架,一种没有将检测建议分离出来的方法,整个检测流程是单阶段的。
第6至第9部分将更详细地讨论检测框架中涉及的基本子问题,包括DCNN特性、检测建议、上下文建模等。

5.1 基于区域的框架(两阶段框架)
在基于区域建议框架中,先从图片中直接生成类别无关(category-independent)的建议区域,然后使用CNN从原图对应的区域中进行特征抽取,再使用特定类别的分类器确定每个区域的类别标签。正如图11所示,DetectorNet [254]、 OverFeat [235]、MultiBox [65] 和 RCNN [83] 几乎是在同一时间独立提出将CNN应用于通用对象检测。
RCNN [83]: 从CNN在图像分类取得突破进展以及selective search在手工设计的特征区域建议 [264] 的成功得到灵感,Girshick等人在第一时间就尝试将CNN用于通用对象检测,并开发了RCNN [83, 85],其集成了AlexNet和区域建议方法selective search。从如图12展示的框架的细节部分可以看出,训练一个RCNN框架由多个阶段组成:
- 计算建议区域。由selective search产生的类别无关(class agnostic)建议区域,是一些可能包含对象的候选区域;
- CNN模型微调(finetuning)训练。从原图中裁剪出的建议区域,调整为相同尺寸大小后用于微调(训练)一个CNN模型,这个CNN模型已经使用大规模数据集(如ImageNet)预训练过。在这一步中,所有与真实标签(ground truth)边界框IoU大于等于0.5的建议区域会被定义为对应ground truth边界框类别的正样本,其余的被定义为负样本;
- 训练特定类别的SVM分类器。使用CNN提取的固定长度特征训练一组特定类别的线性SVM分类器,代替模型中在上一步微调时使用的softmax分类器。为了训练SVM分类器,将每个类别对应的所有ground truth边界框的区域定义为正样本。所有与ground truth边界框IoU小于0.3的建议区域被定义为对应类别的负样本。值得注意的是,用于训练SVM的正负样本的定义方式与上一步微调CNN时的定义方式不同;
- 训练类别相关的边界框回归器(regressors)。使用CNN提取的特征为每个类别训练回归更加精确的边界框。
RCNN在实现高目标检测质量的同时,也存在着明显的不足:
- 整个训练过程是由多个独立训练的阶段组成,这是一种不优雅、缓慢并且很难优化的方法。
- 训练SVM分类器和边界框回归器是一件既占用磁盘空间又耗时的工作。因为每张图片中的每个建议区域的CNN特征需要提前被提取并保存到磁盘,这给大规模数据集检测任务带来了巨大的挑战。对于非常深的网络,如VGG16 [244],这个过程在大型数据集上需要花费很长的计算时间。而且这些特性也需要大量的存储空间。
- 测试也比较慢,因为每个测试图像中的每个对象建议区域都要独立提取CNN特征,其中并没有共享计算。
所有这些缺点都激发了该领域的不断创新,从而产生了SPPNet、Fast RCNN、Faster RCNN等改进框架。
SPPNet [96]: RCNN主要的瓶颈是在测试时需要从每张图片中的上千个建议区域(独立地)提取CNN特征。He等人 [96] 在注意到这个缺陷后提出了将传统空间金字塔(spatial paramid pooling, SPP )[87, 143] 应用到CNN框架中解决该问题。He等人发现其实卷积层是可以接受任意尺寸的输入,只有全连接层需要固定尺寸的输入。基于该发现,他们将SPP层添加到框架中最后一个卷积层之后,从而为全连接层获取固定长度的特征。通过使用SPPNet,只需要对输入的测试图片执行一次卷积运算,就可以为该图片中所有任意尺寸的建议区域提取固定长度的特征,这样在没有损失任何精度的情况下大大加速了RCNN。虽然SPPNet将RCNN的推理速度提升了几个量级,但是并没有给训练算法带来任何的可观提升。而且,在微调SPPNet [96] 的时候是无法更新SPP层之前的卷积层参数,这限制了深度神经网络的性能。
Fast RCNN [82]:Girshick [82] 提出的Fast RCNN尝试解决RCNN和SPPNet的缺点,在检测速度和质量上都有提高。如图13所示,Fast RCNN提出了同时学习softmax分类器和类别相关边界框回归器的流水线式训练过程,取代了RCNN和SPPNet中需要分三个独立的步骤分别训练softmax分类器、SVM和边界框回归器(Bounding Box Regressors,BBRs),这使得Fast RCNN实现了端到端的检测器训练方法(基于固定的建议区域)。Fast RCNN的改进思想主要有:(一个图片内的)所有建议区域共享卷积计算、在最后一个卷积层和全连接层之间增加感兴趣区域(Region of Interest,RoI)池化层来为每一个建议区域提取固定长度的特征。实际上,RoI池化是通过在特征层面执行(输入尺寸大小)变换来近似在原图上执行的变换。经过RoI池化的特征被输入到一系列FC层中,这些FC层最终分为两个子输出层:对象类别预测的softmax概率和预测更加精细化的边界框回归(相对于建议区域边界框的偏移量)。与RCNN或SPPNet相比,Fast RCNN大大提高了效率,通常在训练中速度提高3倍,在测试中提高10倍。综上所述,Fast RCNN具有引人注目的优点:较高的检测质量、同时更新所有网络层参数的单阶段训练过程和不需要额外存储特征缓存等。
Faster RCNN [225, 226]: 虽然Fast RCNN大大加快了检测过程,但它仍然依赖于外部的建议区域。区域建议计算是Fast RCNN中新的速度瓶颈。最近的研究表明,CNN具有在卷积层中定位对象的显著能力 [309,310,44, 196, 94],在FC层中表现却比较弱。因此,可以用CNN代替selective search生成建议区域。Ren等人提出的Faster RCNN框架 [22,226] 提出了一种高效、准确的区域建议网络(Region Proposal Network,RPN)来生成建议区域。它利用相同的骨干网完成RPN的区域建议任务和Fast RCNN的区域分类任务。在Faster RCNN中,RPN和检测网络(即Fast RCNN)共享主干网的所有卷积层。根据最后一个共享卷积层输出的特征分别独立用于区域建议和区域分类两个分支。如图13所示,检测网络就是Fast RCNN, RPN建立在最后一个卷积层之上。RPN首先在(最后一层的)卷积特征映射的每个(像素)位置上初始化k个不同尺寸和长宽比的参考框(即所谓的锚框,anchors box)。anchors的位置与图像内容无关,但是基于anchors提取的特征向量与图像内容是相关的。每个anchor(内的特征)被映射到一个较低维的向量(如用于ZF网络的256和用于VGG网络的512),这些向量会被分别输入给两个子全连接层分支——对象类别无关分类(预测该区域是否存在某个对象的特征)分支和边界框回归分支。不同于Fast RCNN,在Faster RCNN中,对边界框的回归是在任意大小的建议区域的特征上实现的,回归的参数是在所有大小不同的建议区域中共享的,RPN中用于回归的特征尺寸与anchor box在特征图上的尺寸是相同的。k个anchor对应k个回归器。RPN与Fast RCNN共享卷积特征,从而实现高效的区域建议计算。实际上,RPN是一种全卷积网络(FCN) [173,237],Faster RCNN是一个纯粹基于CNN的框架,不使用任何手工设计的特征。测试时,Faster RCNN使用VGG16模型 [244] ,在GPU上以5 FPS的速度运行,以每张图片使用300个建议区域获得了PASCAL VOC 2007对象检测任务上的最好效果。在 [225] 中,最初的Faster RCNN由几个交替的训练阶段组成,后来被简化为单阶段联合训练 [226]。
在Faster RCNN提出的同时期, Lenc和Vedaldi [147] 也提出对区域建议生成方法(如selective search)作用的质疑,他们研究了区域建议生成在基于CNN的检测器中的作用,发现CNN包含足够的可用于精确对象检测的几何信息,而不是在全连接层中。他们展示了在去除区域建议生成方法(例如seletive search。)后构建更简单、更快并完全依赖于CNN的集成对象检测器的可能性。
RFCN (Region based Fully Convolutional Network):虽然Faster RCNN比Fast RCNN快了一个量级,但是仍然需要将基于区域的子网络(RoI之后的子网络)独立地在每个RoI(每张图片有几百个RoI)上进行计算。基于这个事实,Dai等人 [48] 提出了几乎所有的计算在整个图像上共享的RFCN检测器,这是个全卷积(fully convolutional,没有全连接层)框架。如图13所示,RFCN与Faster RCNN唯一不同的地方就是RoI子网络。在Faster RCNN中,RoI池化层之后的计算无法共享。一个自然的想法是将不能共享的计算量最小化,因此Dai等人提出全部使用卷积层来构建一个共享的RoI子网络,RoI的输入特征是从预测输出前的最后一层卷积层提取得到。然而,Dai等人 [48] 发现这种简单的设计检测精度相当低,推测是更深的卷积层对类别语义更敏感,对平移更不敏感,而对象检测需要表示平移变化的位置表征。基于这一观察,Dai等人 [48] 以一组专门的卷积层作为FCN输出,构建了一组位置敏感的分数映射(score map),在此基础上增加了位置敏感的RoI池化层,其不同于 [82,225] 中的标准RoI池化层。作者表示使用ResNet101 [98] 的RFCN与可以达到与Faster RCNN相当的精度,而且速度更快。
Mask RCNN:遵循概念简单、高效且灵活的精神,He等人 [99] 提出了Mask RCNN,通过扩展Faster RCNN的方式,加入处理像素级对象实例分割任务。Mask RCNN仍然采用两阶段流水线,第一阶段(RPN)保持不变。在第二阶段,在预测类别和边界框偏移量的同时,Mask RCNN添加了一个分支,它为每个RoI输出一个二进制掩码。新的分支是一个基于CNN特征图的全卷积网络(FCN) [173, 237] 。为了避免原RoI池化层引起的错位
,Mask RCNN提出了RoIAlign层来保持像素级空间对应关系。使用ResNeXt101-FPN作为骨干网络 [284, 163],Mask RCNN在COCO对象实例分割和边界框对象检测方面取得了较好的效果。它训练简单,泛化良好,只比Faster RCNN增加了一些小开销,可以5 FPS的速度运行 [99]。
Chained Cascade Network and Cascade RCNN:级联的本质是利用多级分类器学习更具有识别能力的分类器。前期阶段的分类器会排除大量容易分类的负样本,以便后期的分类器可以专注于处理更困难的样本。级联可以被广泛应用于对象检测中 [71, 20, 155]。可以将两阶段对象检测框架看作是两个目标检测器的级联,第一级目标检测器去除大量的背景区域,第二阶段对剩余的区域进行分类。最近,Chained Cascade
Network [201] 首次提出了学习用于通用对象检测的多于两个分类器的端到端级联分类器方法,随后Cascade RCNN [23] 对其进行了扩展。最近,Cascade进一步被应用于同步对象检测和实例分割中 [31],并最终赢得了COCO 2018的检测比赛。
Light Head RCNN: 为了进一步加快RFCN [48] 的检测速度,Li等人 [161] 提出了Light Head RCNN,使检测网络的头尽可能的轻,从而降低区域建议RoI的计算。尤其是Li等人 [161] 利用大卷积核的可分卷积( a large kernel separable convolution)产生了具有较少通道数(如在COCO检测基准上使用490个信道)的特征映射和轻量的RCNN子网络,在速度和精度之间做出了很好的平衡。

5.2 统一流程(Unified pipeline,单阶段流程)
自RCNN [83] 以来,5.1节的基于区域的流程策略在检测基准上一直占主导地位。5.1节介绍的工作使得检测器更快、更准确,目前在流行的基准数据集上,领先的结果都是基于Faster RCNN [225]。尽管取得了这些进展,但对于目前存储和计算能力有限的移动和可穿戴设备来说,基于区域的方法在计算上非常昂贵。因此,研究人员不再试图优化复杂的区域流程中的单个组件,而是着手进行研究统一的检测策略。
统一流程是指在只需要单个设置的情况下,使用单个前馈卷积网络从完整图像中直接预测类别概率和边界框偏移量的框架,其不需要生成建议区域或进行二次分类。这种框架简单而优雅,因为它完全消除了生成建议区域和随后的像素或特征重采样,将所有计算封装在一个网络中。由于整个检测流程是一个单一的网络,可以直接对检测性能进行端到端优化。
DetectorNet: Szegedy等人 [254] 是最早尝试使用CNN进行目标检测的研究者。DetectorNet将对象检测问题定义为对边界框掩码的回归问题。他们用回归层替换AlexNet [136] 最后的softmax分类器层。给定一个图像窗口,他们使用一个网络在粗糙的网格上预测前景(对象)像素,还需要另外四个网络来预测对象的顶部、底部、左侧和右侧边界。然后,使用一组后处理方法将预测的掩码转换为检测的边界框。每个对象类型和掩码类型都需要训练一个网络。它无法扩展到多个类别检测任务上。DetectorNet必须从原图中裁剪得到很多部分,并为每个部分运行多个网络,因此使得速度很慢。
OverFeat:可以认为由Sermanet等人 [235] 提出的OverFeat是第一个现代基于深度全卷积网络的单阶段对象检测器。它是最有影响力的对象检测框架之一,曾赢得了ILSVRC2013定位和检测比赛。框架的具体结构如图14所示。从图中可以看出,OverFeat通过以多尺度滑动窗口的方式单次前向通过网络中的全卷积层(即图14(a)所示的“特征提取器”)进行目标检测。测试时目标检测的关键步骤可以概括为以下几步:
- 通过在图像上采用多尺度滑动窗口方式进行对象分类生成候选对象。OverFeat使用的是类似于AlexNet的CNN网络框架 [136](如图14 (a)所示),这些网络的全连接层需要固定输入尺寸。为了利用卷积固有的计算效率,使滑动窗口方法计算效率更高,OverFeat将网络转换为一个可以接受任何尺寸输入的全卷积网络(如图14(a)所示)。具体来说,OverFeat利用可将全连接层看作是核大小为1×1的卷积运算的方法,将CNN扩展到任意大小图像上。OverFeat利用多尺度特征来提高整体性能,通过向网络传递多达6个将原图缩放的输入(如图14(b)所示),从而显著增加了评估的上下文视图数量。对于每个多尺度输入,分类器(如
图14(a))输出一个预测网格(每个位置输出一个类别概率和一个置信度),表示某个对象出现的位置,如图14(b)所示。 - 通过偏移最大池化增加预测的数量。为了提高最终预测的分辨率,OverFeat在最后一个卷积层之后应用偏移最大池化操作,即每偏移一定像素后执行下采样操作。这种方法为候选对象提供了更多的视图,从而在保持效率的同时增强了健壮性。
- 边界框回归。一旦一个对象被识别出来,就在当前位置应用一个边界框回归器。分类器和回归器共享相同的特征提取层(即卷积层),只需要在计算分类网络后重新计算FC层。它们自然地共享公共部分的计算。
- 结合预测。OverFeat使用贪婪的合并策略来合并所有位置和尺寸上的边界框预测结果。
相比同一时期提出的RCNN [83], OverFeat具有显著的速度优势,但是由于当时全卷积网络很难训练,所以它的准确性要低得多。速度优势来自于使用全卷积网络共享重叠窗口之间的卷积计算。后来的框架都类似于OverFeat,比如YOLO [223] 和SSD [171],其中一个主要区别是在OverFeat中分类器和回归器是按顺序训练的。

YOLO (You Only Look Once):Redmon等人 [223] 提出的YOLO是一种统一的检测器,它将对象检测转换为从像素到空间上分隔的边界框及对应类别概率的回归问题。YOLO的设计如图13所示。由于直接丢弃了建议区域的生成阶段,YOLO使用一个小型的候选区域集合来直接进行检测。类似于Faster RCNN等基于区域的方法,都是基于局部区域特征进行检测,不同的是,YOLO使用的是整个图像的全局特征。具体地说,YOLO将一张图像切分成S*S的网格(grid),每个网格预测C个类别概率、B个边界框位置和每个框对应的置信度。这些预测结果被编码为一个S×S×(5B + C)的张量。通过完全丢弃建议区域生成阶段,YOLO在设计上是快速的,实时运行速度为45 FPS,而其快速版本,即fast YOLO [223] ,运行速度为155 FPS。由于YOLO在预测时可以看到整个图像,所以它会隐式地对对象的上下文信息进行编码,所以不太可能将背景误预测为假阳性。由于对边界框位置、尺寸和长宽比的划分比较粗糙,这导致YOLO比Faster RCNN的定位精度差很多。正如 [223] 中所讨论的,YOLO可能无法定位一些目标,尤其是小目标。这可能是因为网格划分非常粗糙的原因,而且在构造上每个网格单元只能包含一个对象。目前还不清楚YOLO有多大程度可以以良好的性能迁移到每幅图像中有更多对象的数据集上,比如ILSVRC检测比赛。
YOLOv2 and YOLO9000:Redmon和Farhadi [222] 提出了YOLO的改进版本YOLOv2, 其使用了很多改进策略,如用定制的GoogLeNet [256] 网络替换了较为简单的DarkNet19,引入一些现有工作的策略,如批归一化(batch normalization ) [97],移除了完全连接层,使用kmeans学习的表现更好的anchor box,使用多尺度方式进行训练。YOLOv2在PASCAL VOC、MS COCO等标准检测任务上取得了当时的SoA水平。此外,Redmon和Farhadi [222] 引入了YOLO9000,提出了一种联合优化方法,利用WordTree同时在ImageNet分类数据集和COCO检测数据集上进行训练,将多个数据源的数据组合起来,实现对9000多个对象类别的实时检测。这种联合训练允许YOLO9000执行弱监督检测,即检测没有边界框标注数据的对象类。例如,尽管200个类中只有44个类有检测标注数据,但YOLO9000在ImageNet检测验证集上获得了19.7%的mAP。
SSD (Single Shot Detector):为了确保在不损失太多精度的前提下尽量保证实时预测速度,Liu等人 [171] 提出了SSD,获得了比YOLO [223] 更快的速度,并且在精度方面与基于区域的SoA检测器包括Faster RCNN [225]也具有可比性。SSD有效地结合了来自Faster RCNN [225] 中的RPN、YOLO [223] 和多尺度卷积特性 [94]的思想, 实现了拥有快速的检测速度的同时仍保持较高的检测质量。与YOLO一样,SSD预测固定数量的边界框和每个框中是否存在类别对象的分数,然后执行NMS获得最终检测结果。SSD中的CNN网络是完全卷积的,其较浅层,也被称为基本网络,是基于标准框架的,如VGG [244] (在分类层之前截断)。然后,在基础网络的末尾添加几个辅助的卷积层,这些层的输出特征尺寸逐渐减小。最后一层的输出特征拥有较低的低分辨率,其在空间上可能过于粗糙,以至于无法进行精确定位。SSD使用分辨率更高的浅层来检测小目标。对于不同大小的对象,SSD通过对多个卷积层特征映射进行多尺度检测,每个卷积层特征映射都预测适当大小的边界框偏移量(相对于anchor box)和类别分数。在VOC2007测试中,对于300×300的输入,运行在Nvidia Titan X上的SSD 以59 FPS 的速度达到了74.3% mAP的效果(对应Faster RCNN的效果为以7 FPS获得73.2% mAP,YOLO的效果为以45 FPS获得63.4% mAP)。
CornerNet:最近,Law等人 [142] 发表了对anchor box在SoA对象检测框架 [82,99,223,171] 中的主导作用的。Law等 [142] 认为使用anchor box,尤其是在单阶段探测器中 [75,164, 171, 223] 也有缺点 [142,164],比如引入正负样本严重不平衡,减缓训练速度和引入额外的超参数。因此,为了避免使用anchor box,借鉴在多人姿态估计任务中使用关联嵌入(Associative Embedding )的研究成果 [191],Law等人 [142] 提出了CornerNet,将边界框对象检测定义为检测成对的关键点(paired keypoints):左上角和右下角。在CornerNet中,骨干网络是通过叠加两个Hourglass网络 [190] 实现的。此外,还提出了一种简单的角池化(corner pooling)方法来更好地定位角。Law等人 [142] 的研究表示,CornerNet在MS COCO上的AP达到42.1%,超过了所有现有的单阶段检测器。然而,其在Titan X GPU上的平均推理时间约为4FPS,明显慢于同是单阶段检测器的SSD [171] 和YOLO [223]。CornerNet [142] 还经常生成一些不正确的边界框,因为很难决定哪些关键点对应该被归为属于同一对象的组。为了进一步改进CornerNet [142], Duan等人 [60] 提出了CenterNet,引入了一个额外的关键点,即建议的中心区域点,将每个对象检测扩展为检测三个关键点。在MS COCO检测任务中,CenterNet取得了47.0%的AP,优于大多数现有的单阶段检测器。CenterNet的推理速度比CornerNet还慢。