Day13:Hive优化及数据倾斜
-
- 知识点01:回顾
- 知识点02:目标
- 知识点03:Hive函数:多行转多列
- 知识点04:Hive函数:多行转单列
- 知识点05:Hive函数:多列转多行
- 知识点06:Hive函数:多列转单行
- 知识点07:Hive函数:反射函数
- 知识点08:Hive函数:Python脚本
- 知识点09:Hive函数:JSON处理
- 知识点10:Hive函数:窗口聚合函数
- 知识点11:Hive函数:窗口位置函数
- 知识点12:Hive函数:窗口分析函数
- 知识点13:Hive函数:窗口函数案例
- 知识点14:Hive优化:参数优化
- 知识点15:Hive优化:SQL优化
- 知识点16:Hive优化:表设计优化
- 知识点17:数据倾斜:现象原因
- 知识点18:数据倾斜:解决方案
知识点01:回顾
-
MapReduce处理Hive表数据的规则以及普通表结构的特点是什么?
-
底层MapReduce的输入:表的最后一级目录
-
普通表结构
数据仓库目录/数据库目录/表的目录/数据文件- 最后一级目录就是表的目录
-
-
分区表的功能、结构和特点是什么?
-
功能:将大量的数据按照一定规则条件进行划分,将数据分区目录存储,减少了底层MapReduce输入,提高了性能
-
结构
数据仓库目录/数据库目录/表的目录/分区目录/分区文件 -
特点:最后一级目录是分区目录
-
注意:分区表能实现优化的前提查询的过滤条件一定是分区字段【时间】
-
-
如何实现构建分区表?分区的设计是什么级别的?分区的字段是逻辑的还是物理的?
- 两种方式
- 静态分区:数据本身按照分区的规则划分好的
- step1:创建分区表
- step2:直接加载分区数据
- 动态分区:数据本身没有做划分
- step1:创建普通表,加载数据
- step2:创建分区表,将普通表的数据动态分区写入分区表
- 静态分区:数据本身按照分区的规则划分好的
- 分区级别:目录
- 分区字段:逻辑字段
- 两种方式
-
分桶表的功能和设计思想是什么?分桶的设计是什么级别的?分桶字段是逻辑的还是物理的?
- 功能:优化大表join大表过程,提高大表join大表的性能
- 设计:将数据按照一定的规则划分到不同的文件中,将大文件拆分为多个小文件,实现每个小文件的Map Join
- 本质:底层的MapReduce的分区,一个桶就是一个reduce,对应一个结果文件
- 规则:Hash取余
- 级别:文件
- 分桶字段:物理字段
-
Hive中的order by、sort by 、distribute by、cluster by的功能分别是什么?
- order:全局排序,只能有1个reduce
- sort:局部排序,多个Reduce,每个Reduce内部排序
- distribute:指定底层MapReduce的K2的
- cluster:在指定的是同一个字段的情况下,功能上等价于sort + distribute
-
parse_url_tuple函数的功能及语法是什么?
- 功能:用于解析URL
- 语法:parse_url_tuple(url,… 要解析的字段)
- HOST
- PATH
- QUERY
- 应用:UDTF函数,一次性解析多个字段
-
explode函数的功能及语法是什么?
- 功能:拆分集合类型的元素,将每个元素变成一行
- 语法:explode(Array | Map)
- 应用:列转行
-
lateral view的功能及语法是什么?
-
功能:将UDTF结果构建成一个类似于视图的临时表,用于与原表进行拼接查询,解决UDTF查询限制问题
-
语法
lateral view udtf 别名 as 临时表的列的列名 -
应用:搭配UDTF使用
-
知识点02:目标
- Hive中的函数
- 了解反射函数、Python脚本辅助处理
- 掌握
- 行列转换实现:特殊函数
- JSON处理函数
- 开窗函数:窗口聚合、位置偏移、分析函数
- 实例
- Hive优化以及数据倾斜【掌握】
- 基本优化:参数优化、SQL优化、设计优化【文件格式】
- 数据倾斜:现象、原因、解决
知识点03:Hive函数:多行转多列
-
目标:掌握行列转换的应用场景及实现多行转多列
-
路径
- step1:行列转换的场景
- step2:多行转多列实现
-
实施
-
行列转换的场景
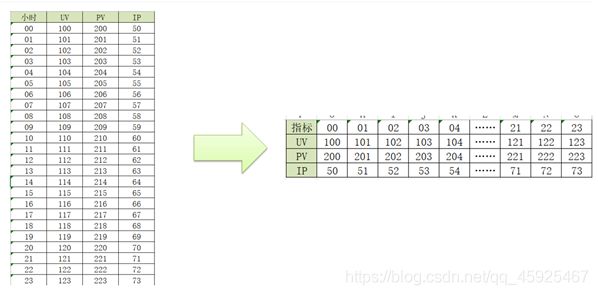
-
分析:基于每个小时分析不同指标【UV,PV,IP】的结果
select hourstr,count(distinct userid),count(url),count(distinct ip) from table group by hourstr00 300 1000 90 01 200 1000 90 02 100 1000 90 …… 23 1000 1000 90 -
需求:得到每个指标不同小时的值:每个小时UV的值
select * from table where key = 'uv'00 01 02 …… 23 300 200 100 1000
-
-
多行转多列实现
-
输入
vim /export/data/r2c1.txta c 1 a d 2 a e 3 b c 4 b d 5 b e 6--建表 create table row2col1( col1 string, col2 string, col3 int )row format delimited fields terminated by '\t'; --加载数据 load data local inpath '/export/data/r2c1.txt' into table row2col1; -
结果
+-------+----+----+----+--+ | col1 | c | d | e | +-------+----+----+----+--+ | a | 1 | 2 | 3 | | b | 4 | 5 | 6 | +-------+----+----+----+--+ -
分析
-
肯定做了分组:按照第一列分组
-
每一组如何能返回这一组的结果
-
数据
col1 col2 col3 a c 1 a d 2 a e 3 -
结果
+-------+----+----+----+--+ | col1 | c | d | e | +-------+----+----+----+--+ | a | 1 | 2 | 3 | -
SQL
select col1, max(case col2 when 'c' then col3 else 0 end ) as c, max(case col2 when 'd' then col3 else 0 end ) as d, max(case col2 when 'e' then col3 else 0 end ) as e from table group by col1;
-
-
-
函数
-
group by语句中:select后面的字段要么是分组字段要么是聚合函数的结果
- 每一组只返回一条
-
case when:判断函数
-
功能:实现多种条件的判断
-
方式一
case col when value1 then rs1 when value2 then rs2 …… else rsN end -
方式二
case when col = value1 then rs1 when col = value2 then rs2 …… else rsN end
-
-
-
SQL
select col1 as col1, max(case col2 when 'c' then col3 else 0 end) as c, max(case col2 when 'd' then col3 else 0 end) as d, max(case col2 when 'e' then col3 else 0 end) as e from row2col1 group by col1;
-
-
-
小结
- case when函数的功能及语法?
- 功能:判断函数,实现条件的判断
- 语法
- case col when value
- case when col = value
- 应用:多条件判断场景
- 语法
知识点04:Hive函数:多行转单列
-
目标:实现多行转单列的SQL开发
-
实施
-
输入
vim /export/data/r2c2.txta b 1 a b 2 a b 3 c d 4 c d 5 c d 6--建表 create table row2col2( col1 string, col2 string, col3 int )row format delimited fields terminated by '\t'; --加载数据 load data local inpath '/export/data/r2c2.txt' into table row2col2; -
结果
+-------+-------+--------+--+ | col1 | col2 | col3 | +-------+-------+--------+--+ | a | b | 1,2,3 | | c | d | 4,5,6 | +-------+-------+--------+--+ -
分析
- 分组:col1,col2
- 聚合:将每组中的三行变成一行
- 拼接字符串:将集合中每个元素进行拼接为字符串
-
函数
- collect_list/collect_set
- 功能:聚合函数,将多行的内容合并为一行的内容
- 语法:
- collect_list(col):不做去重
- collect_set(col):做去重
- 应用:用于将多行转换为单列单行
- concat / concat_ws
- 功能:字符串拼接的
- 语法
- concat(str1,str2,str3……):不能指定分隔符,有一个为null,整个结果就为null
- concat_ws(分隔符,str1,str2,str3……):可以指定分隔符,只要一个不为null,结果就不为null
- collect_list/collect_set
-
SQL
select col1, col2, concat_ws(",",collect_set(cast(col3 as string))) as col3 from row2col2 group by col1,col2;
-
-
小结
- concat与concat_ws函数的功能与语法?
- 功能:字符串拼接
- 语法
- concat(str1,str2,str3……)
- concat_ws(分隔符,str1,str2……)
- collect_set与collect_list的功能与语法?
- 功能:将多行合并到一行
- 语法
- collect_set(col):做去重
- collect_list(col):不做去重
- concat与concat_ws函数的功能与语法?
知识点05:Hive函数:多列转多行
-
目标:实现多列转多行的SQL开发
-
实施
-
输入
vim /export/data/c2r1.txta 1 2 3 b 4 5 6create table col2row1( col1 string, col2 int, col3 int, col4 int )row format delimited fields terminated by '\t'; --加载数据 load data local inpath '/export/data/c2r1.txt' into table col2row1; -
结果
+-----------+-----------+-----------+--+ | _u1.col1 | _u1.col2 | _u1.col3 | +-----------+-----------+-----------+--+ | a | c | 1 | | b | c | 4 | | a | d | 2 | | b | d | 5 | | a | e | 3 | | b | e | 6 | +-----------+-----------+-----------+--+ -
分析
- 实现行的合并
- union all
-
实现
select col1,'c' as col2,col2 as col3 from col2row1 union all select col1,'d' as col2,col3 as col3 from col2row1 union all select col1,'e' as col2,col4 as col3 from col2row1;
-
-
小结
- union all的功能?
- 功能:实现行的合并
- 语法:select…… union all select ……
- 应用:union all与union区别
- union all的功能?
知识点06:Hive函数:多列转单行
-
目标:实现多列转单行的SQL开发
-
实施
-
输入
vim /export/data/c2r2.txta b 1,2,3 c d 4,5,6create table col2row2( col1 string, col2 string, col3 string )row format delimited fields terminated by '\t'; --加载数据 load data local inpath '/export/data/c2r2.txt' into table col2row2; -
输出
+-------+-------+-------+--+ | col1 | col2 | col3 | +-------+-------+-------+--+ | a | b | 1 | | a | b | 2 | | a | b | 3 | | c | d | 4 | | c | d | 5 | | c | d | 6 | +-------+-------+-------+--+ -
分析
- 由少变多,将一行的内容拆分为多行
-
函数
- explode:将一个集合类型的内容中的每一个元素变成一行
-
SQL
select col1, col2, lv.col3 as col3 from col2row2 lateral view explode(split(col3, ',')) lv as col3;
-
-
小结
- explode函数的功能?
- 功能:用于将集合或者数组类型列中的每一个元素变成一行
- 语法:explode(Array | map)
- 应用:将一列转为多行
- explode函数的功能?
知识点07:Hive函数:反射函数
-
目标:了解reflect函数的功能及用法
-
实施
-
功能
- 用于在Hive中直接调用Java中类的方法
-
本质
- 通过给定的类,反射构建了这个类的对象,通过对象调用方法给用户返回
-
语法
reflect(类,方法,参数) -
测试
select reflect("java.util.UUID", "randomUUID"); select reflect("java.lang.Math","max",20,30); select reflect("org.apache.commons.lang.math.NumberUtils","isNumber","123"); -
应用:一般用于Java中已经有对应的工具类,可以直接被调用,省去写UDF
-
-
小结
- 了解即可
知识点08:Hive函数:Python脚本
-
目标:了解Hive中如何实现Python脚本辅助处理
-
实施
- 数据

-
建表加载数据
--创建原始数据表:用户id、电影id、用户评分、用户的观影时间 CREATE TABLE u_data ( userid INT, movieid INT, rating INT, unixtime STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; --加载数据: load data local inpath '/export/data/u.data' into table u_data; --查询数据 select count(*) from u_data; -
创建目标表
--创建新表:用户id、电影id、用户评分、用户的时间是周几 CREATE TABLE u_data_new ( userid INT, movieid INT, rating INT, weekday INT) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -
创建Python脚本
--创建Python脚本实现将原始表的时间转为对应的星期几 vim /export/data/weekday_mapper.pyimport sys import datetime for line in sys.stdin: line = line.strip() userid, movieid, rating, unixtime = line.split('\t') weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday() print '\t'.join([userid, movieid, rating, str(weekday)]) -
加载脚本,写入数据
--加载python脚本并将数据写入新表 add FILE /export/data/weekday_mapper.py; INSERT OVERWRITE TABLE u_data_new SELECT TRANSFORM (userid, movieid, rating, unixtime) USING 'python weekday_mapper.py' AS (userid, movieid, rating, weekday) FROM u_data; -
查询分析
--统计每周内每天用户观影的次数 SELECT weekday, COUNT(*) FROM u_data_new GROUP BY weekday; -
小结
- 了解即可
知识点09:Hive函数:JSON处理
-
目标:掌握Hive中处理JSON数据的两种方式
- 常见的数据格式:结构化数据格式
- csv:每一列都是用逗号分隔符
- tsv:每一列都是用制表符分隔符
- json:专有的JSON格式文件
- properteies
- xml
- 常见的数据格式:结构化数据格式
-
路径
- step1:JSON函数
- step2:JSONSerDe
-
实施
-
JSON函数
-
创建数据
vim /export/data/hivedata.json{ "id": 1701439105,"ids": [2154137571,3889177061],"total_number": 493} { "id": 1701439106,"ids": [2154137571,3889177061],"total_number": 494} -
创建表
create table tb_json_test1 ( json string ); --加载数据 load data local inpath '/export/data/hivedata.json' into table tb_json_test1; -
函数
-
get_json_object:用于解析JSON字符串,指定取出JSON字符串中的某一个元素
select get_json_object(t.json,'$.id'), get_json_object(t.json,'$.total_number') from tb_json_test1 t ; -
json_tuple:UDTF函数,一次性取出多个JSON字符串的元素
select t1.json, t2.* from tb_json_test1 t1 lateral view json_tuple(t1.json, 'id', 'total_number') t2 as c1,c2;
-
-
-
JSONSerDe
-
功能:可以直接在加载数据文件的时候解析JSON格式
-
配置:修改hive-env.sh
export HIVE_AUX_JARS_PATH=/export/server/hive-2.1.0-bin/hcatalog/share/hcatalog/hive-hcatalog-core-2.1.0.jar
- 重启hiveserver2 - 创建表 ```sql create table tb_json_test2 ( id string, ids array, total_number int) ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe' STORED AS TEXTFILE; --加载数据 load data local inpath '/export/data/hivedata.json' into table tb_json_test2; - 查询数据
-
-

-
小结
-
Json处理的函数有哪些?
-
方式一:JSON函数
-
get_json_object(jsonString,“$.元素名称”):一次只能取一个
-
json_tuple(jsonString,“ . 元 素 名 称 ” , “ .元素名称”,“ .元素名称”,“.元素名称”,“$.元素名称”……)
- UDTF函数
- 一次取多个
-
应用:数据中的某个字段是JSON格式的
id name age info【JSON】 1 张三 18 {addr:上海……}
-
-
方式二:通过JSONSerde来加载JSON格式的文件
-
数据就是一个json文件,每一条数据就是一个完整的JSON字符串
json1 json2 json3 ……
-
-
-
知识点10:Hive函数:窗口聚合函数
-
目标:掌握窗口聚合函数的使用
-
路径
- step1:常见的分析需求
- step2:窗口的基本语法
- step3:窗口聚合函数
-
实施
-
常见的分析需求
-
需求1:统计得到每个部门薪资最高的那个员工薪水
select deptno, max(salary) from tb_emp group by deptno; -
需求2:统计得到每个部门薪资最高的前两名的薪水
select deptno, max(salary) from tb_emp group by deptno order by salary; -
问题:分组一组只能返回一条,怎么办?
-
需求中出现了关键词每个、各个、不同,要么做分组,要么做分区
-
分组:group by:一组返回一条
-
分区:窗口函数partition by:一组返回多条
-
-
-
窗口的基本语法
funName(参数) over (partition by col [order by col] [window_szie])-
partition by:分区,将相同分区的数据放在一起
-
order by:分区内部按照某个字段进行排序
-
window_szie:窗口大小,指定的是函数处理数据的范围
-- N preceding :前N行 -- N following :后N行 -- current row:当前行 -- unbounded preceding 表示从前面的起点,第一行 -- unbounded following:表示到后面的终点,最后一行
-
-
窗口聚合函数
max/min/avg/count/sum-
创建数据
vim /export/data/window.txtcookie1,2018-04-10,1 cookie1,2018-04-11,5 cookie1,2018-04-12,7 cookie1,2018-04-13,3 cookie2,2018-04-13,3 cookie2,2018-04-14,2 cookie2,2018-04-15,4 cookie1,2018-04-14,2 cookie1,2018-04-15,4 cookie1,2018-04-16,4 cookie2,2018-04-10,1 cookie2,2018-04-11,5 cookie2,2018-04-12,7 -
创建表
--建库 create database db_function; use db_function; --建表 create table itcast_f1( cookieid string, daystr string, pv int ) row format delimited fields terminated by ','; --加载 load data local inpath '/export/data/window.txt' into table itcast_f1; --本地模式 set hive.exec.mode.local.auto=true; -
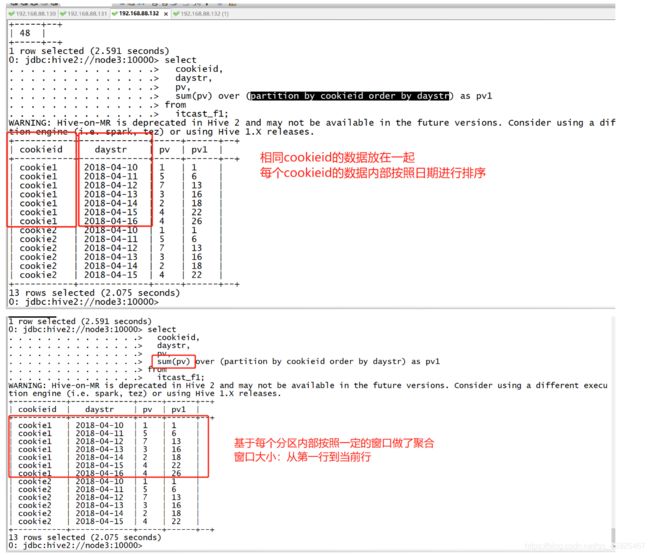
需求1:实现分区内起始行到当前行的pv累加,指定排序
select cookieid, daystr, pv, sum(pv) over (partition by cookieid order by daystr) as pv1 from itcast_f1;
-
-
-
如果指定了partition by和order by,没有指定窗口大小
-
默认窗口:分区的第一行到当前行
-
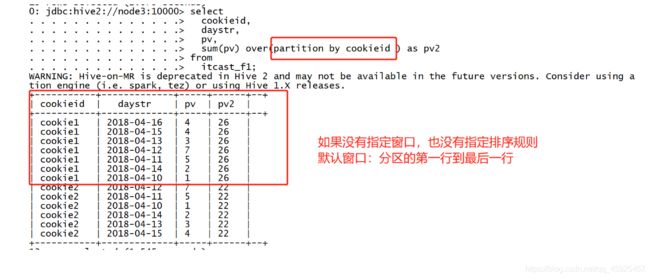
需求2:实现分区内起始行到当前行的pv累加,不指定排序
select
cookieid,
daystr,
pv,
sum(pv) over(partition by cookieid ) as pv2
from
itcast_f1;
- 需求3:实现分区内起始行到当前行的pv累加,指定窗口
select
cookieid,
daystr,
pv,
sum(pv) over (partition by cookieid order by daystr rows between unbounded preceding and current row) as pv3
from
itcast_f1;

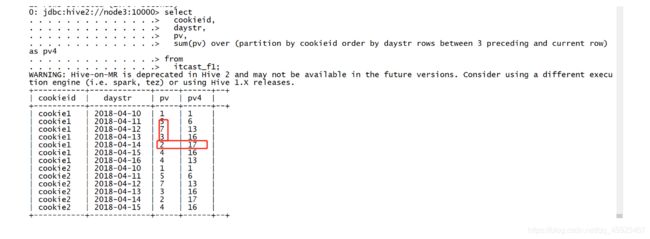
- 需求4:实现分区内指定前N行到当前行的pv累加
```sql
select
cookieid,
daystr,
pv,
sum(pv) over (partition by cookieid order by daystr rows between 3 preceding and current row) as pv4
from
itcast_f1;
```
- 需求5:实现分区内指定前N行到后N行的pv累加
select
cookieid,
daystr,
pv,
sum(pv) over(partition by cookieid order by daystr rows between 3 preceding and 1 following) as pv5
from
itcast_f1;

-
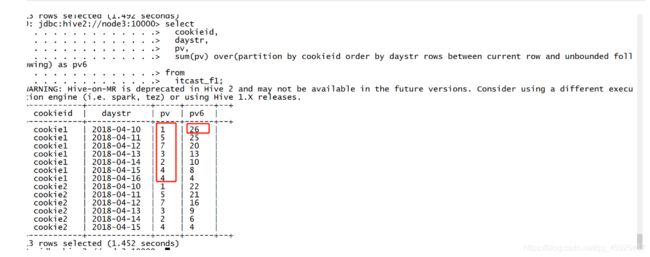
需求6:实现分区内指定当前行到最后一行的pv累加
select cookieid, daystr, pv, sum(pv) over(partition by cookieid order by daystr rows between current row and unbounded following) as pv6 from itcast_f1;
-
小结
-
窗口函数的语法及关键字的含义是什么?
-
语法
functionName(参数) over (partition by col order by col 【window_size】) -
含义
- partition by:分区,将相同分区的数据放在一起
- order by:排序,基于分区内部排序
- window_size:基于分区内部计算的窗口大小
-
-
知识点11:Hive函数:窗口位置函数
-
目标:掌握窗口位置函数的使用
-
路径
- step1:first_value
- step2:last_value
- step3:lag
- step4:lead
-
实施
-
first_value
-
功能:取每个分区内某列的第一个值
-
语法:FIRST_VALUE(col) over (partition by col1 order by col2)
-
示例
use db_emp; --取每个部门薪资最高的员工姓名 select empno, ename, salary, deptno, FIRST_VALUE(ename) over (partition by deptno order by salary desc) as first from db_emp.tb_emp;
-

-
last_value
-
功能:取每个分区内某列的最后一个值
-
语法:LAST_VALUE() over (partition by col1 order by col2)
-
注意:一定要 注意默认窗口的计算范围
-
示例
-
-
--取每个部门薪资最低的员工编号
select
empno,
ename,
salary,
deptno,
LAST_VALUE(empno) over (partition by deptno order by salary desc) as last
from
db_emp.tb_emp;
无法实现
--取每个部门薪资最低的员工编号
select
empno,
ename,
salary,
deptno,
LAST_VALUE(empno) over (partition by deptno order by salary desc rows between unbounded preceding and unbounded following) as last
from
db_emp.tb_emp;
-
lag
-
功能:取每个分区内某列的前N个值
-
语法:LAG(col,N,defaultValue) over (partition by col1 order by col2)
- col:取分区内某一列的值
- N:向前偏移N个单位
- defaultValue:如果取不到的默认值
-
-
示例
select
empno,
ename,
salary,
deptno,
LAG(salary,1,0) over (partition by deptno order by salary) as deptno2
from
db_emp.tb_emp;

-
lead
-
功能:取每个分区内某列的后N个值
-
语法:LEAD(col,N,defaultValue) over (partition by col1 order by col2)
- col:取分区内某一列的值
-
N:向后偏移N个单位
- defaultValue:如果取不到的默认值
-
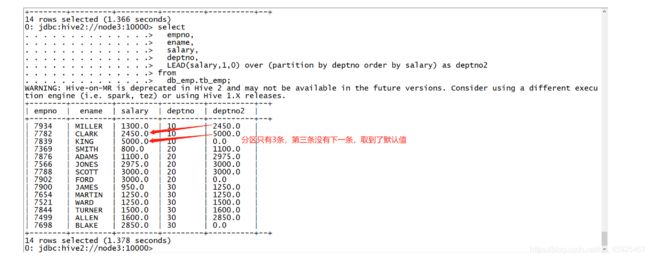
示例
select empno, ename, salary, deptno, LEAD(salary,1,0) over (partition by deptno order by salary) as deptno2 from db_emp.tb_emp;
-
-
小结
- first_value的功能及语法?
- 功能:取分区内部某一列第一条
- 语法:first_value(col)
- last_value的功能及语法?
- 功能:取分区内部某一列最后一条
- 语法:last_value(col)
- lag的功能及语法?
- 功能:取分区内某一列的向前偏移N个单位的值
- 语法:lag(col,N,default)
- lead的功能及语法?
- 功能:取分区内某一列的向后偏移N个单位的值
- 语法:lead(col,N,default)
- first_value的功能及语法?
知识点12:Hive函数:窗口分析函数
-
目标:掌握窗口分析函数的使用
-
路径
- step1:row_number
- step2:rank
- step3:dense_rank
- step4:ntil
-
实施
-
row_number
-
功能:用于实现分区内记录编号
-
语法:row_number() over (partition by col1 order by col2)
-
特点:如果值相同,继续编号
-
示例
--统计每个部门薪资最高的前两名 select empno, ename, salary, deptno, row_number() over (partition by deptno order by salary desc) as numb from db_emp.tb_emp;
-
-
rank
-
功能:用于实现分区内排名编号[会留空位]
-
语法:rank() over (partition by col1 order by col2)
-
特点:如果值相同,编号相同,会留下空位
-
示例
--统计每个部门薪资排名 select empno, ename, salary, deptno, rank() over (partition by deptno order by salary desc) as numb from db_emp.tb_emp;
-
-

-
dense_rank
-
功能:用于实现分区内排名编号[不留空位]
-
语法:dense_rank() over (partition by col1 order by col2)
-
特点:如果值相同,编号相同,不留空位
-
示例
--统计每个部门薪资排名 select empno, ename, salary, deptno, dense_rank() over (partition by deptno order by salary desc) as numb from db_emp.tb_emp;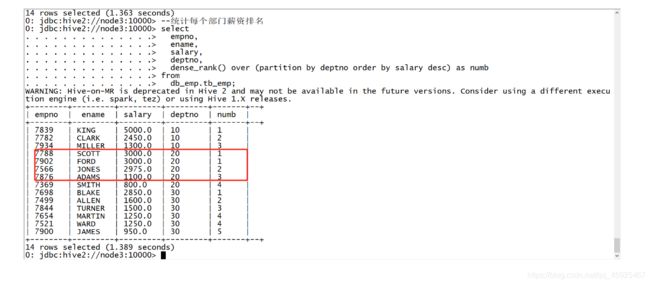
-
-
ntile
-
功能:将每个分区内排序后的结果均分成N份【如果不能均分,优先分配编号小的】
-
语法:NTILE(N) over (partition by col1 order by col2)
-
示例
--统计每个部门薪资排名,将每个部门的薪资分为两个部分,区分高薪和低薪 select empno, ename, salary, deptno, NTILE(2) over (partition by deptno order by salary desc) as numb from db_emp.tb_emp;
-
-
小结
- row_number、rank与dense_rank的功能与区别?
- 功能:做编号
- 区别
- row_number:如果值相同,继续编号
- rank:如果值相同,编号相同,但是会留下空位
- dense_rank:如果值相同,编号相同,不留空位
- row_number、rank与dense_rank的功能与区别?
知识点13:Hive函数:窗口函数案例
-
目标:使用窗口函数实现以下需求案例
-
路径
- step1:存款金额累计求和
- step2:连续登陆用户统计
-
实施
-
存款金额累计求和
- 数据:用户id【userid】、存款月份【month】、存储金额【money】
-
A 2015-02 6
A 2015-01 10
B 2015-03 11
B 2015-01 25
B 2015-02 10
A 2015-02 4
A 2015-03 10
A 2015-03 6
B 2015-01 5
A 2015-01 13
B 2015-02 5
B 2015-03 6
-
需求:统计每个人每个月存款的金额和累计总金额
+-------------+----------+---------+-------------+--+ | a.userid | a.month | money | accumulate | +-------------+----------+---------+-------------+--+ | A | 2015-01 | 33 | 33 | | A | 2015-02 | 10 | 43 | | A | 2015-03 | 16 | 59 | | B | 2015-01 | 30 | 30 | | B | 2015-02 | 15 | 45 | | B | 2015-03 | 17 | 62 | +-------------+----------+---------+-------------+--+ -
分析
-
先拿到前面三列:每个人在每个月的存储总金额
select userid, month, sum(money) as 这个月的总金额 from table group by userid,month; -
再做窗口聚合
- partition by userid
- order by month
-
-
连续登陆用户统计
-
数据:用户id【userid】,登陆日期【logindate】
A,2021-03-22 B,2021-03-22 C,2021-03-22 A,2021-03-23 C,2021-03-23 A,2021-03-24 B,2021-03-24 -
需求:统计连续登录N天的用户(N>=2)
-
连续登录2天的用户是哪些:A,C
-
连续登录3天的用户是哪些:A
-
-
分析
-
连续登录2天
-
方案一:构建笛卡尔积
userid1 logindate1 userid2 logindate2- userid1 = userid2 and date_add(logindate1,1) = logindate2
-
方案二:窗口函数
select userid, logindate, date_add(logindate,1) , --当前登录日期的后一天 lead(logindate,1,0) over (partition by userid order by logindate) as nextlogin from table;logindate nextday nextlogin A 2021-03-22 2021-03-23 2021-03-23 A 2021-03-23 2021-03-24 2021-03-24 A 2021-03-24 2021-03-25 0 B 2021-03-22 2021-03-23 2021-03-24 B 2021-03-24 2021-03-25 0 C 2021-03-22 2021-03-23 2021-03-23 C 2021-03-23 2021-03-24 0连续登录2天:nextday = nextlogin
select userid, logindate, date_add(logindate,2) , --当前登录日期的后两天 lead(logindate,2,0) over (partition by userid order by logindate) as nextlogin from table;logindate nextday nextlogin A 2021-03-22 2021-03-24 2021-03-24 A 2021-03-23 2021-03-25 0 A 2021-03-24 2021-03-26 0 B 2021-03-22 2021-03-24 0 B 2021-03-24 2021-03-26 0 C 2021-03-22 2021-03-24 0 C 2021-03-23 2021-03-25 0连续登录3天:nextday = nextlogin
-
-
-
-
一般应用场景
- 分区窗口聚合:每个分区的聚合的结果
- 分区排序
- 位置偏移
-
小结
- 根据思路,自己通过代码实现
知识点14:Hive优化:参数优化
-
目标:掌握Hive中常见的参数优化
-
路径
- step1:MapReduce参数
- step2:Hive参数
-
实施
-
MapReduce参数
-
推测执行
-
问题:经常运行一个Mapreduce程序,有多个MapTask和ReduceTask,由于网络或者资源故障导致有一个Task一直不能运行结束
-
解决:开启推测执行
- 如果appmaster发现某个Task一直不能结束,会在另外节点上启动同一个Task,谁先运行结束,另外一个会被kill
-
属性
mapreduce.map.speculative=true mapreduce.reduce.speculative=true hive.mapred.reduce.tasks.speculative.execution=true
-
-
JVM重用
-
问题:每次每个Task都会申请一个JVM进程来运行程序,JVM进程需要内存等资源
- 每个Task运行完成以后,这个JVM就被销毁了
-
解决:申请了一个JVM进程的资源以后,可以运行多个Task
-
实现资源复用
-
配置
set mapreduce.job.jvm.numtasks=10
-
-
-
-
Hive参数
-
Fetch Task
-
Hive自带了小型计算引擎,一部分简单的SQL语句不走Mapreduce,直接由Fetch Task处理
-
属性
hive.fetch.task.conversion Expects one of [none, minimal, more]. Some select queries can be converted to single FETCH task minimizing latency. Currently the query should be single sourced not having any subquery and should not have any aggregations or distincts (which incurs RS), lateral views and joins. 0. none : disable hive.fetch.task.conversion 1. minimal : SELECT STAR, FILTER on partition columns, LIMIT only 2. more : SELECT, FILTER, LIMIT only (support TABLESAMPLE and virtual columns) -
none:不启用fetch抓取
-
minimal
-
more
-
-
严格模式
- 老版本的属性:hive.mapred.mode=nonstrict/strict
- 如果为严格模式:hive会限制一些SQL语句的运行
- 新版本的属性
- hive.strict.checks.type.safe
- 是否允许一些风险性的类型比较
- bigints and strings.
- bigints and doubles.
- hive.strict.checks.cartesian.product
- 是否允许笛卡尔的产生
-
并行执行
- Hive在解析SQL时,默认不会并行执行Stage,只会单个Stage执行
-
设置并行度,提高Hive解析编译的性能
set hive.exec.parallel=true; //打开任务并行执行 set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。 -
压缩
-
先配置Hadoop中的压缩
- 设置Mapreduce的shuffle的中间输出压缩
-
-
属性
#配置多个Mapreduce中的中间Mapreduce的结果压缩 hive.exec.compress.intermediate=true
-
-
-
小结
- MapReduce可以做哪些优化?
- 推测执行
- JVM重用
- Hive中可以做哪些参数优化?
- Fetch Task
- 严格模式
- 并行执行
- 压缩
- MapReduce可以做哪些优化?
知识点15:Hive优化:SQL优化
-
目标:掌握Hive中的SQL优化的基本规则
-
实施
-
基本规则:PPD
谓词下推 Predicate Pushdown(PPD)的思想简单点说就是在不影响最终结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,降低了Reduce端的数据负载,节约了集群的资源,也提升了任务的性能。 -
示例
-
where与having
- 能在where中过滤的就不要在having中过滤
-
join
- 需求:订单表a【1000万 orderid pid 】、商品表b【100万 pid pname】,获取每个订单中商品的信息
-
-
select * from a join b on a.pid = b.pid
-
step1:先将所有订单中出现的商品id过滤出来:c[10万]
select distinct pid from a; -
step2:让订单中的商品id与商品表进行关联,得到这些商品id的商品信息:d[10万条]
select
from c join b on c.pid = b.pid
- step3:a与djoin
select
from a join d a.pid = d.pid
-
小结
- Hive默认开启了自动谓词下推,只要掌握原则即可
知识点16:Hive优化:表设计优化
-
目标:掌握Hive中表设计的优化方案
-
路径
- step1:分区表
- step2:分桶表
- step3:文件格式
-
实施
-
分区表:优化底层MapReduce输入,提高性能
-
分桶表:提前将数据分桶存储,提高Join性能
-
文件格式
-
创建表时可以指定
STORED AS file_format -
默认格式:textfile
file_format: : SEQUENCEFILE | TEXTFILE -- (Default, depending on hive.default.fileformat configuration) | RCFILE -- (Note: Available in Hive 0.6.0 and later) | ORC -- (Note: Available in Hive 0.11.0 and later) | PARQUET -- (Note: Available in Hive 0.13.0 and later) | AVRO -- (Note: Available in Hive 0.14.0 and later) | JSONFILE -- (Note: Available in Hive 4.0.0 and later) | INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname -
工作中一般会选用存储文件格式
- 二进制:SEQUENCEFILE
- 列式存储:rcfile、orc、parquet
-
列式存储的优点
-
相同的数据,存储占用的空间更小
-
列式存储:对于SQL分析读取列比较方便
-
-
-
col1 col2 col3
1 a c
2 b d
- 按行存储
1 a c 2 b d
- 列式存储
1 2 a b c d
-
SQL:select col1 from table
-
按行存储:将每一行都读取出来,然后过滤第一列
-
按列存储:直接读取对应的列
-
构建文件数据索引
-
-
测试
- 参考:《Hive实现列式存储parquet与orc对比测试》
-
小结
- 常见的文件格式有哪些?
- 默认:textfile
- 二进制:sequencefile
- 列式存储:rcfile,orc,parquet
- 列式存储的优点是什么?
- 占用空间更小
- 列式存储,列的读取更多
- 构建列式索引
- 常见的文件格式有哪些?
知识点17:数据倾斜:现象原因
-
目标:了解数据倾斜的现象、原因
-
路径
- step1:现象
- step2:原因
-
实施
-
现象
- 运行一个程序,这个程序的某一个Task一直在运行,其他的Task都运行结束了,进度卡在99%或者100%
-
原因
-
基本原因:这个ReduceTask的负载要比其他Task的负载要高
- ReduceTask的数据分配不均衡
-
MapTask会不会有数据倾斜的问题?不会
-
-
根本原因:分区的规则
-
默认分区:根据K2的Hash值取余reduce的个数
-
优点:相同的K2会由同一个reduce处理
-
缺点:可能导致数据倾斜
-
-
举例:
-
Map输出的数据
K 2 V2 hadoop 1 hive 1 hadoop 1 hive 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hbase 1 -
Reduce0
hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 hadoop 1 -
Reduce1
hive 1 hive 1 hbase 1
-
-
-
-
小结
- 了解数据倾斜的现象及原因
知识点18:数据倾斜:解决方案
-
目标:掌握数据倾斜的解决方案
-
路径
- step1:数据倾斜的场景
- step2:解决方案
-
实施
-
数据倾斜的场景
- group by / count(distinct)
- join
-
解决方案
-
group by / count(distinct)
-
开启Combiner
hive.map.aggr=true -
随机分区
-
方式一:开启参数
hive.groupby.skewindata=true -
开启这个参数以后,底层会自动走两个MapReduce
-
-
第一个MapReduce自动实现随机分区
-
第二个MapReduce做最终的聚合
-
方式二:手动指定
-
-
-
-
distribute by rand()
-
join
- 尽量避免走Reduce Join
- Map Join
- 尽量将不需要参加Join的数据过滤,将大表转换为小表
- 构建分桶Bucket Map Join
-
小结
- 哪些场景下会产生数据倾斜以及怎么解决?
- group by / count(distinct)
- 开启Combiner
- 实现随机分区
- join:避免reduce join
- group by / count(distinct)
- 哪些场景下会产生数据倾斜以及怎么解决?