python爬虫requests模块基础
get请求

urllib爬取贴吧

方法一:直接写
import urllib.request
import urllib.parse
# 贴吧主题
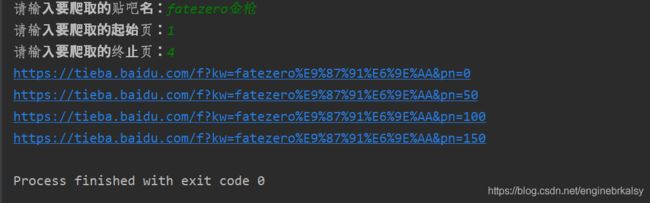
name =input('请输入要爬取的贴吧名:')
begin =int(input('请输入要爬取的起始页:'))
end =int(input('请输入要爬取的终止页:'))
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# 对name处理 转换
kw ={
'kw':name}
# 两种都可
# result =urllib.parse.quote(kw)
result = urllib.parse.urlencode(kw)
# 页数循环:range前闭后开,要+1
for i in range(begin,end+1):
pn = (i - 1) * 50
# print(pn)
# 拼接url
base_url ='https://tieba.baidu.com/f?'
url = base_url + result + "&pn=" + str(pn)
print(url)
import urllib.request
import urllib.parse
# 贴吧主题
name =input('请输入要爬取的贴吧名:')
begin =int(input('请输入要爬取的起始页:'))
end =int(input('请输入要爬取的终止页:'))
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'
}
# 对name处理 转换
kw ={
'kw':name}
# 两种都可
# result =urllib.parse.quote(kw)
result = urllib.parse.urlencode(kw)
# 页数循环:range前闭后开,要+1
for i in range(begin,end+1):
pn = (i - 1) * 50
# print(pn)
# 拼接url
base_url = 'https://tieba.baidu.com/f?'
url = base_url + result + "&pn=" + str(pn)
# print(url)
# 发起请求
req = urllib.request.Request(url, headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
# 保存数据
filename = "第" + str(i) + "页.html"
with open(filename,"w",encoding='utf-8') as f:
print('正在爬取第 %d 页'% i)
f.write(html)
结果:



方法二:函数def形式写
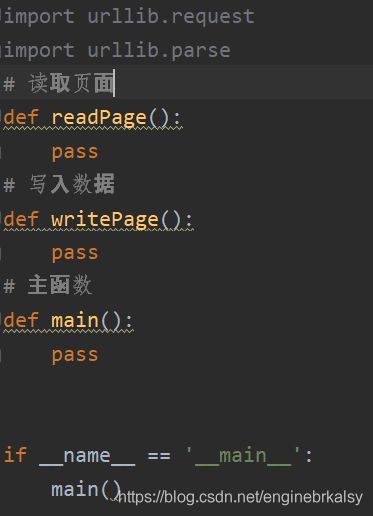
基本架构
import urllib.request
import urllib.parse
# 读取页面
def readPage(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
req = urllib.request.Request(url,headers=headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
# 写入数据
def writePage(filename , html):
with open(filename,"w",encoding='utf-8') as f:
f.write(html)
print('爬取成功')
# 主函数
def main():
name =input('请输入爬取贴吧主题名')
begin =int(input('请输入爬取起始页'))
end = int(input('请输入爬取结束页'))
kw ={
'kw':name}
result =urllib.parse.urlencode(kw)
for i in range(begin,end+1):
pn =(i -1) * 50
base_url = 'https://tieba.baidu.com/f?'
url = base_url + result + "&pn=" + str(pn)
# 调用函数
html = readPage(url)
filename ='第' + str(i) + "页.html"
writePage(filename,html)
if __name__ == '__main__':
main()


方法三:类方法写
import urllib.request
import urllib.parse
class BaiduSpider:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
self.base_url ='https://tieba.baidu.com/f?'
def readPage(self,url,):
req = urllib.request.Request(url, headers=self.headers)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
return html
def writePage(self,filename,html):
with open(filename,"w",encoding='utf-8') as f:
f.write(html)
print('爬取成功')
def main(self):
name = input('请输入爬取贴吧主题名')
begin =int(input('请输入爬取起始页'))
end = int(input('请输入爬取结束页'))
kw ={
'kw':name}
result = urllib.parse.urlencode(kw)
for i in range(begin,end+1):
pn =(i -1) * 50
url = self.base_url + result + "&pn=" + str(pn)
html =self.readPage(url)
filename ='第' + str(i) + '页.html'
self.writePage(filename,html)
if __name__ == '__main__':
spider = BaiduSpider()
spider.main()

Post方式


import urllib.request
import urllib.parse
# 输入内容
content = input('请输入你要翻译的句子')
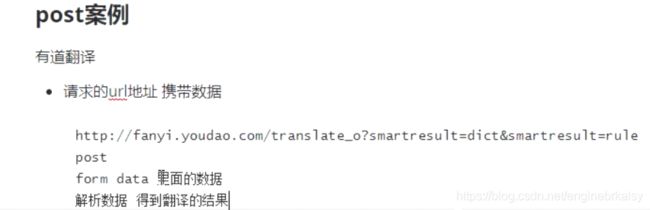
# URL
# https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
# 获取form data数据
data = {
'i': content,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16187688635891',
'sign': 'f7858bb42fe7c52e6821a15831c2915e',
'lts': '1618768863589',
'bv': '3d91b10fc349bc3307882f133fbc312a',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'}
data = urllib.parse.urlencode(data)
url = 'https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
req = urllib.request.Request(url,headers=headers,data=data)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
print(html)
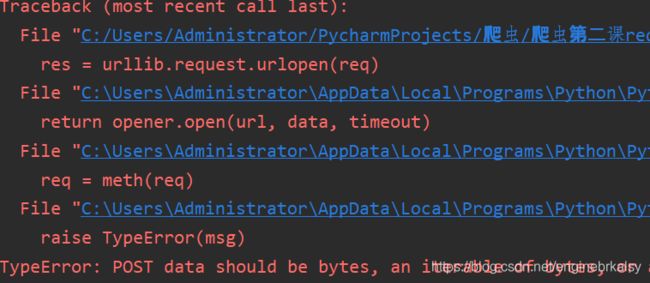
解决方式:使data数据类型为bytes字节
# 获取form data数据
data = {
'i': content,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16187688635891',
'sign': 'f7858bb42fe7c52e6821a15831c2915e',
'lts': '1618768863589',
'bv': '3d91b10fc349bc3307882f133fbc312a',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'}
data = urllib.parse.urlencode(data)
data =bytes(data,'utf-8')
仍出错:

解决:去掉_o——后续js解密再说

结果:

字符串转化字典 json.load
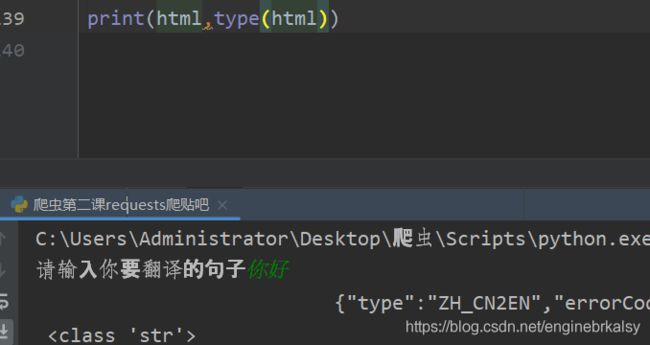
拿到字典后需要直接取出翻译的数据:
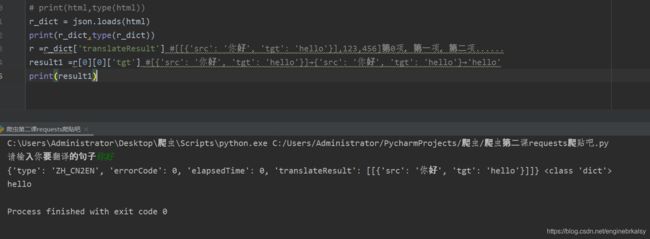
r =r_dict['translateResult'] #[[{'src': '你好', 'tgt': 'hello'}],123,456]第0项,第一项,第二项......
result1 =r[0][0]['tgt'] #[{'src': '你好', 'tgt': 'hello'}]→{'src': '你好', 'tgt': 'hello'}→'hello'
print(result1)
总体代码:
import urllib.request
import urllib.parse
import json
# 输入内容
content = input('请输入你要翻译的句子')
# URL
# https://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
# 获取form data数据
data = {
'i': content,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16187688635891',
'sign': 'f7858bb42fe7c52e6821a15831c2915e',
'lts': '1618768863589',
'bv': '3d91b10fc349bc3307882f133fbc312a',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'}
data = urllib.parse.urlencode(data)
data =bytes(data,'utf-8')
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
req = urllib.request.Request(url,headers=headers,data=data)
res = urllib.request.urlopen(req)
html = res.read().decode('utf-8')
# print(html,type(html))
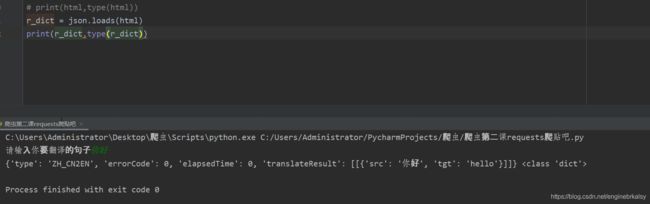
r_dict = json.loads(html)
# print(r_dict,type(r_dict))
r =r_dict['translateResult'] #[[{'src': '你好', 'tgt': 'hello'}],123,456]第0项,第一项,第二项......
result1 =r[0][0]['tgt'] #[{'src': '你好', 'tgt': 'hello'}]→{'src': '你好', 'tgt': 'hello'}→'hello'
print(result1)

requests方式爬取
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
# 发起请求获得响应 

问题:直接res.text会出现乱码
解决1:res.content.decode(‘utf-8’)
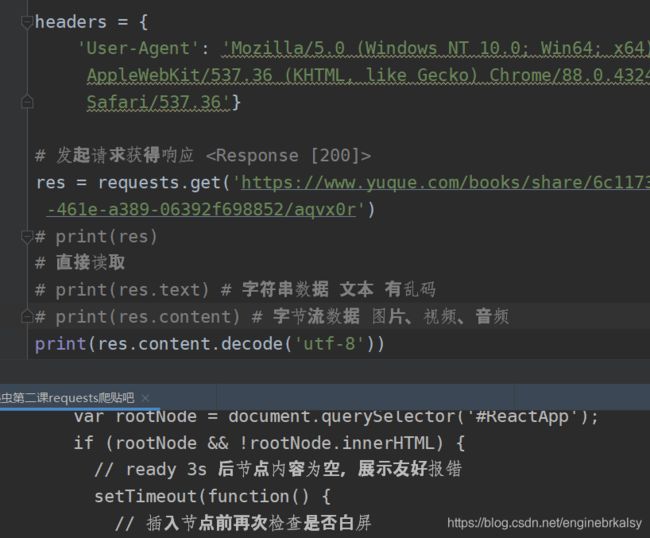
解决2:res.encoding =‘utf-8’,再print(res.text)

# 直接读取
# print(res.text) # 字符串数据 文本 有乱码
# print(res.content) # 字节流数据 图片、视频、音频
print(res.content.decode('utf-8')) # 方法一
res.encoding ='utf-8' # 方法二
print(res.text)
完整代码:
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36'}
# 获取form data数据
content = input('请输入你要翻译的句子')
data = {
'i': content,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '16187688635891',
'sign': 'f7858bb42fe7c52e6821a15831c2915e',
'lts': '1618768863589',
'bv': '3d91b10fc349bc3307882f133fbc312a',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'}
url = 'https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
res =requests.post(url,data=data,headers=headers)
html =res.text
# print(html)
r =json.loads(html)
r =r['translateResult']
r1 =r[0][0]['tgt']
print(r1)
