chrome浏览器 docker_基于Docker的Python Selenium自动化测试
写在最前面
最近测试的同学找到木子,说前面他们一直在Windows下进行压测,不懂Docker,对于Docker的压测更是没有研究。既然找到木子,木子也得想办法协助处理,只能自己先研究一下,然后写一个Demo,输出给他们一个大概的流程和方案,后面就他们自己慢慢琢磨研究了。因为木子也没有玩过Selenium,所以将整个过程记录下来,希望能够帮忙到初级入门的同学,大神左转。在使用Selenium进行自动化测试时,首先需要搭建Selenium的运行环境,其中包括:安装Java、浏览器Firefox/Chrome、Selenium-standalone-server等等。这个部署过程相对来说比较复杂,而且容易出现Selenium运行环境中浏览器driver与浏览器版本不一致问题,造成在环境准备和维护上需要消耗很多时间。而采用Docker的方式部署Selenium方式,可以大大提高部署效率。
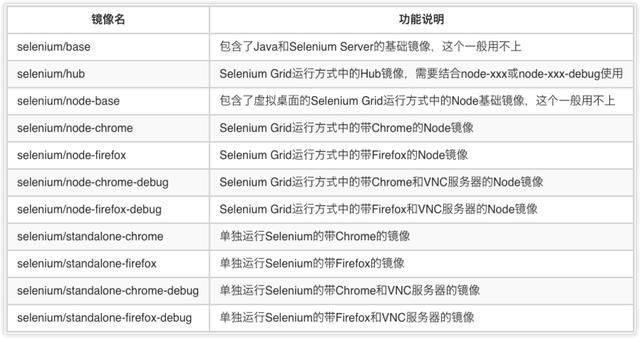
Selenium镜像分类
Selenium的镜像有很多种,如果不区分清楚各镜像的功能,会给后面的部署带来很多不必要的麻烦,所以木子这里简单列出各镜像的功能。
Docker容器化压测环境部署
为了满足调试与生产两种环境下的实际使用需求,下面木子采用selenium/hub + selenium/node-chrome-debug & node-firefox-debug来进行Docker部署。
# 创建selenium hub容器docker run -d -p 4444:4444 --name selehub selenium/hub:latest# 创建chrome node容器docker run -d -p 5801:5900 --name chrome01 --link selehub:hub --shm-size=1024m selenium/node-chrome-debug:latestdocker run -d -p 5802:5900 --name chrome02 --link selehub:hub --shm-size=1024m selenium/node-chrome-debug:latest# 创建firefox node容器docker run -d -p 5901:5900 --name firefox01 --link selehub:hub --shm-size=1024m selenium/node-firefox-debug:latestdocker run -d -p 5902:5900 --name firefox02 --link selehub:hub --shm-size=1024m selenium/node-firefox-debug:latest'''参数说明:-d: 后台模式运行;--name: 容器名称;-p: 将容器的5900端口映射到Docker的5901端口,访问Docker的5901端口即可访问到node容器;--link: 用于链接2个容器,使得源容器(被链接的容器)和接收容器(主动去链接的容器)之间可以互相通信,并且接收容器可以获取源容器的一些数据,如源容器的环境变量;--shm-size: docker默认的共享内存/dev/shm只有64m,有时导致chrome崩溃,该参数增加共享内存大小到1024m;'''#正常现在应该启动了5个容器~ » docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES607caf8c5e07 selenium/node-firefox-debug:latest "/opt/bin/entry_poin…" 3 seconds ago Up 2 seconds 0.0.0.0:5902->5900/tcp firefox022377af007659 selenium/node-firefox-debug:latest "/opt/bin/entry_poin…" 8 seconds ago Up 6 seconds 0.0.0.0:5901->5900/tcp firefox0187b6cf881e66 selenium/hub:latest "/opt/bin/entry_poin…" 4 days ago Up 2 hours 0.0.0.0:4444->4444/tcp selehub795a10e3ddf9 selenium/node-chrome-debug:latest "/opt/bin/entry_poin…" 5 days ago Up 2 hours 0.0.0.0:5802->5900/tcp chrome02f0a142607c48 selenium/node-chrome-debug:latest "/opt/bin/entry_poin…" 5 days ago Up 2 hours 0.0.0.0:5801->5900/tcp chrome01#我们查看其中一个node-firefox-debug日志,正常会提示注册功能。~ » docker logs firefox012020-05-12 09:52:35,650 INFO Included extra file "/etc/supervisor/conf.d/selenium-debug.conf" during parsing2020-05-12 09:52:35,650 INFO Included extra file "/etc/supervisor/conf.d/selenium.conf" during parsing2020-05-12 09:52:35,651 INFO supervisord started with pid 82020-05-12 09:52:36,655 INFO spawned: 'xvfb' with pid 112020-05-12 09:52:36,658 INFO spawned: 'fluxbox' with pid 122020-05-12 09:52:36,660 INFO spawned: 'vnc' with pid 132020-05-12 09:52:36,661 INFO spawned: 'selenium-node' with pid 142020-05-12 09:52:36,738 INFO success: xvfb entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)2020-05-12 09:52:36,739 INFO success: fluxbox entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)2020-05-12 09:52:36,739 INFO success: vnc entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)2020-05-12 09:52:36,739 INFO success: selenium-node entered RUNNING state, process has stayed up for > than 0 seconds (startsecs)09:52:37.424 INFO [GridLauncherV3.parse] - Selenium server version: 3.141.59, revision: e82be7d35809:52:37.529 INFO [GridLauncherV3.lambda$buildLaunchers$7] - Launching a Selenium Grid node on port 55552020-05-12 09:52:37.618:INFO::main: Logging initialized @408ms to org.seleniumhq.jetty9.util.log.StdErrLog09:52:37.831 INFO [WebDriverServlet.] - Initialising WebDriverServlet09:52:37.908 INFO [SeleniumServer.boot] - Selenium Server is up and running on port 555509:52:37.909 INFO [GridLauncherV3.lambda$buildLaunchers$7] - Selenium Grid node is up and ready to register to the hub09:52:37.945 INFO [SelfRegisteringRemote$1.run] - Starting auto registration thread. Will try to register every 5000 ms.09:52:38.181 INFO [SelfRegisteringRemote.registerToHub] - Registering the node to the hub: http://172.17.0.2:4444/grid/register09:52:38.198 INFO [SelfRegisteringRemote.registerToHub] - The node is registered to the hub and ready to use这时候打开浏览器http://127.0.0.1:4444/grid/console,可以看到4个节点,两个chrome,两个firefox,正常来说如果下载的hub与node节点的镜像版本相同,是不会出现浏览器driver问题的,这个可以放心。

如果需要安装一些基础调试工具可以换源,然后根据自己的需求安装对应软件。
# 更换国内源sudo cat > /etc/apt/sources.list << EOFdeb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiversedeb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiversedeb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverseEOF# 安装Ping工具,selenium等sudo apt updatesudo apt install -y iputils-ping vim python3-pipsudo pip3 install selenium如果需要实现Docker的弹性扩容自动压测,可以采用Jenkins或者Kubernetes HPA的方式部署,实现自动化构建批量容器进行压测。说到这里大概的一个容器压测环境就已经部署完成,下面就需要采用Python + Selenium来实现整个自动化压测了,在这之前需要先简单了解一下Selenium的基本使用方法。
Selenium基础
定位元素
有多种策略可以在页面中定位元素,你可以根据自己的情况选择最合适的一种。Selenium提供了以下方法来查找页面中的元素:
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
查找多个元素(这些方法将返回一个列表):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
学过div+css样式的同学对于html标签等应该不陌生,通过这些方法可以精准定位元素,但在定位的过程中会发现有时候并不是这么简单,在网上我们会看到很多demo,是很简单就可以定位到的,比如通过name、id、tag、class等,但在实际使用过程中是没有这么简单的,你会发现需要采用多方法综合定位才能够实现。
使用的过程中还需要注意Python Selenium提供了两种对象 : WebDriver和WebElement,这两种对象都可以使用这些API,这些API一旦执行失败(即查找不到)就会抛出异常,因此必须使用try: .. except: ... 机制避免错误的行为影响程序继续进行。WebDriver调用以上API进行全局定位,WebElement调用以上API可以进行层级定位, 即查找当前元素的子元素。
WebDriver常用操作
browser.curren_url : 获取当前加载页面的
URLbrowser.close() : 关闭当前窗口, 如果当前窗口是最后一个窗口, 浏览器将关闭
browser.quit() : 关闭所有窗口并停止ChromeDriver的执行
browser.add_cookie(cookie_dict) : 为当前会话添加
cookiebrowser.get_cookie(name) : 得到执行
cookiebrowser.get_cookies() : 得到所有的
cookiedriver.add_cookie() :添加cookie
browser.delete_all_cookies() : 删除当前会话的所有cookie
browser.delete_cookie(name) : 删除指定cookie
browser.back() : 相当于浏览器的后退历史记录
browser.forward() : 相当于浏览器的前进历史记录
browser.execute_script(script, *args) : 同步执行 js 脚本
browser.execute_async_script(script, *args) : 异步执行 js 脚本
browser.get(url) : 在当前窗口加载 url
browser.refresh() : 刷新当前页面
browser.current_window_handle : 当前窗口的 handle, 相当于一个指针一样的东西, 用来指向当前窗口
browser.window_handles : 当前浏览器中的已经打开的所有窗口, 是一个 list
browser.switch_to_window(window_handle) : 切换 window_handle 指向的窗口
browser.title : 当前页面的 title
browser.name : 当前浏览器的名字
WebElement常用操作
webEle.clear() : 清除元素的内容, 假如这个元素是一个文本元素
webEle.click() : 点击当前元素
webEle.is_displayed() : 当前元素是否可见
webEle.is_enabled() : 当前元素是否禁止, 比如经常会禁用一些元素的点击
webEle.is_selected() : 当前元素是否选中, 文本输入框的内容
webEle.send_keys(*value) : 向当前元素模拟键盘事件
webEle.submit() : 提交表单
webEle.tag_name : 当前元素的标签名
webEle.text : 当前元素的内容
webEle.get_attribute(name) : 获取当前元素执行属性的值
等待
等待,就是在模拟点击后,页面有一个加载的过程,而在这过程中需要等待页面加载完成,这时候有两种等待方式:显式等待和隐式等待。
显式等待: 即自己声明等待时间,可以使用WebDriverWait加ExpectedCondition结合方式实现。还有一种简单粗暴的方法就是采用time.sleep(10)。
隐式等待: 即申明一个隐式等待时间driver.implicitly_wait(10),再尝试查找不立即可用的一个或多个元素时在一定时间内轮询DOM。这两种等待方法可以结合使用,以最长时间周期的为准。
简单了解元素定位
如果对于元素的定位没有一个基本的了解,是很难进行元素定位的,所以这里木子以百度为例,可以看到百度的元素定位相对来说是比较简单的,因为它既有id也有name与class,只要这个值是唯一的,就可以拿来直接作为定位元素,如:driver.find_element_by_name('wd')。正如前面木子所说有很多使用开发框架的是没有办法通过id或name、class等定位的,需要我们结合id、div、class等多重方法样式进行定位。
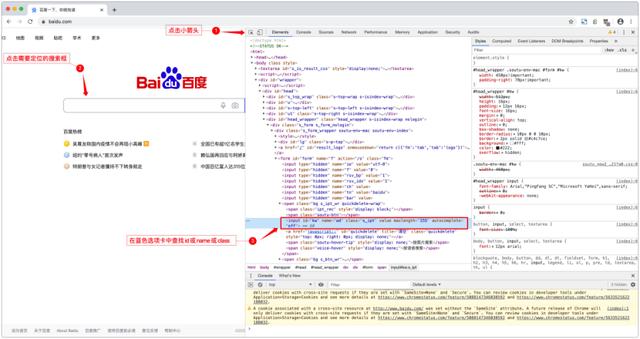
同样以百度为例,还是定位搜索框,我们可以从form ID开始,逐一推进到input搜索框。如:driver.find_element_by_xpath("//*[@id='form']/span/input")

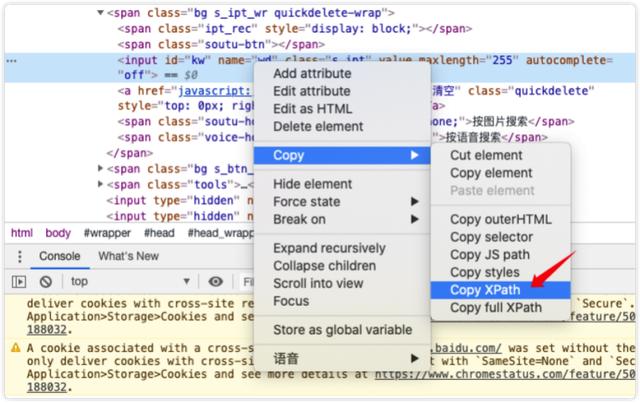
对于XPath方式,可以采用以下方式Copy XPath,但这也不是绝对有效的,因为这个路径在每一次加载的时候有可能不同,所以不建议采用这种方式。
Demo脚本
下面木子通过一个简单的脚本来演示一下通过selenium自动搜索[欧巴云]。
# -*- coding: utf-8 -*-import unittestfrom selenium import webdriverimport timeimport warningsclass UntitledTestCase(unittest.TestCase): def setUp(self): # 关闭警告信息 warnings.simplefilter("ignore", ResourceWarning) # 使用Chromedriver self.driver = webdriver.Remote( desired_capabilities=webdriver.DesiredCapabilities.CHROME, command_executor='http://127.0.0.1:4444/wd/hub') self.driver.implicitly_wait(30) self.driver.maximize_window() self.verificationErrors = [] self.accept_next_alert = True self.gather_data_dict = [{ 'UrlName': 'baidu', 'Url': 'http://www.baidu.com', 'number': 1 }] def __get_page_load_time_NoCache(self, Url, number=1): driver = self.driver for i in range(number): driver.get(Url) time.sleep(5) # 搜索使用元素定位 # input_element = driver.find_element_by_name('wd') input_element = driver.find_element_by_xpath("//*[@id='form']/span/input") input_element.send_keys("欧巴云") input_element.submit() time.sleep(20) performance_data = driver.execute_script("return window.performance.getEntries()") return (performance_data) def test_untitled_test_case(self): for data in self.gather_data_dict: result = self.__get_page_load_time_NoCache(data['Url'], data['number']) print(result) def tearDown(self): self.driver.quit() self.assertEqual([], self.verificationErrors)if __name__ == "__main__": unittest.main()开始测试
python3 ./baidu_test.py#返回结果数据量是很大的,木子这里截取了一部分输出。[{'connectEnd': 187.30000000505242, 'connectStart': 27.645000009215437, 'decodedBodySize': 259144, 'domComplete': 2142.695000002277, 'domContentLoadedEventEnd': 1181.9800000084797, 'domContentLoadedEventStart': 1126.3550000003306, 'domInteractive': 1125.16000001051, 'domainLookupEnd': 27.645000009215437, 'domainLookupStart': 2.4950000079115853, 'duration': 2148.765000005369, 'encodedBodySize': 64297, 'entryType': 'navigation', 'fetchStart': 1.3700000126846135, 'initiatorType': 'navigation', 'loadEventEnd': 2148.765000005369, 'loadEventStart': 2142.7200000034645, 'name': 'http://www.baidu.com/', 'nextHopProtocol': 'http/1.1', 'redirectCount': 0, 'redirectEnd': 0, 'redirectStart': 0, 'requestStart': 187.45000001217704, 'responseEnd': 1015.2600000001257, 'responseStart': 531.6149999998743, 'secureConnectionStart': 0, 'serverTiming': [], 'startTime': 0, 'transferSize': 65595, 'type': 'navigate', 'unloadEventEnd': 0, 'unloadEventStart': 0, 'workerStart': 0, 'workerTiming': []}]正常当开始运行脚本的时候,hub会从2个chrome工作节点任意调用一个工作节点进行自动化测试,这时候可以通过VNC客户端连接至对应节点进行查看自动化测试的过程。

本身木子截了一个.gif的动图,但图片太大有5MB,就不放上来了。

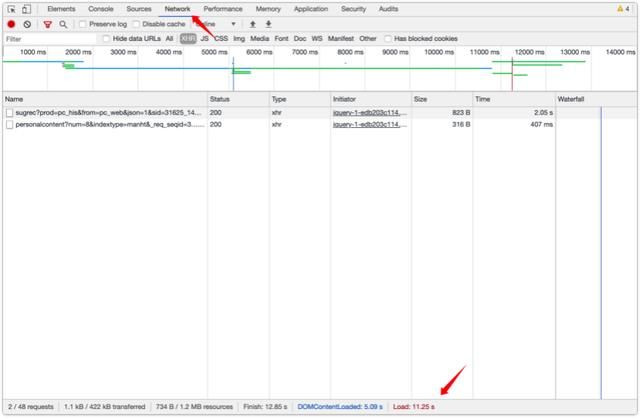
运行的过程不是目的,结果才是我们想要的,所以这里木子取值Performance,正常来说测试需要结合Network与Performance两方面的数据进行分析(如下图所示),但因为输出数据比较多,需要再进行分类整理,这可以根据自己的需求进行调整。

测试脚本
这里输出一个多元素定位的测试脚本,并详细注明每条语句的作用,希望能够帮忙各位更好的了解元素的定位。
# -*- coding: utf-8 -*-import unittestfrom selenium import webdriverimport timeimport warningsclass UntitledTestCase(unittest.TestCase): def setUp(self): # 虽然压测脚本可以正常跑,但会出现一些警告信息,所以这里忽略警告信息。 warnings.simplefilter("ignore", ResourceWarning) # 因为木子采用的是hub + node-xxx-debug模式的,所以浏览器采用的是远程调用模式,这是使用的是CHROME浏览器驱动。如果是standalone-chrome-debug方式,对应的调用方法就会有所不同。同样如果是firefox则采用webdriver.desiredcapabilities.firefox调用。 self.driver = webdriver.Remote( desired_capabilities=webdriver.DesiredCapabilities.CHROME, command_executor='http://127.0.0.1:4444/wd/hub') # 隐式等待时长 self.driver.implicitly_wait(30) # 最大化浏览器窗口 self.driver.maximize_window() # 将脚本运行的错误信息打印到这个列表中 self.verificationErrors = [] # 是否接受下一个警告 self.accept_next_alert = True # 添加压测网址,在数组汇总添加一个Dict即可 self.gather_data_dict = [{ 'UrlName': 'test', 'Url': 'http://test.xxx.com', 'number': 1 }] def __get_page_load_time_NoCache(self, Url, number=1): driver = self.driver for i in range(number): # 调用浏览器打开一个新窗口 driver.execute_script("window.open('','_blank');") # 窗口定位到新打开的窗口 driver.switch_to.window(driver.window_handles[-1]) # 打开请求的页面 driver.get(Url) time.sleep(10) # 定位并点击,这里木子采用了多种定位方式,有xpath、css_selector等 driver.find_element_by_xpath("//*[@id='xxx']//div[@class='xxx']").click() # css样式定位元素 driver.find_element_by_css_selector(".xxx > div > ul > li:nth-child(5)").click() time.sleep(2) # ID加样式定位元素 driver.find_element_by_xpath("//*[@id='xxx']/div/div/div/div/div/div[2]/div[1]/table/thead/tr/th[1]/span/div/span[1]/div/label/span/input").click() time.sleep(2) driver.find_element_by_xpath(".//*[@id='xxx']/div/div[1]/button").click() time.sleep(2) # 绝对路径定位元素 driver.find_element_by_xpath("/html/body/div[3]/div/div[2]/div/div[2]/div/div/div[2]/button[2]").click() time.sleep(20) # 返回所有性能数据 performance_data = driver.execute_script("return window.performance.getEntries()") return (performance_data) time.sleep(30) # 关闭窗口 driver.execute_script("window.close();") # 窗口定位返回旧窗口 driver.switch_to.window(driver.window_handles[-1]) def test_untitled_test_case(self): # 返回结果 # result = [] # 读取压测数数据,返回加载结果! for data in self.gather_data_dict: result = self.__get_page_load_time_NoCache(data['Url'], data['number']) print(result) def tearDown(self): # 退出浏览器 self.driver.quit() self.assertEqual([], self.verificationErrors)if __name__ == "__main__": unittest.main()写在最后
这仅仅只是一个简单的Demo,对于初级入门Docker自动化测试有一定的帮助,但离成为一个真正的自动化测试工程师还有很长的路需要走。对于学习前端或爬虫的同学来说转Python Selenium自动化测试相对来说是一件比较简单的事情,毕竟对于元素定位有足够的了解。