后端token应该保留在哪里_后端开发之接口幂等性设计
一、天天在写Bug,好难哦
今天晨会结束后,领导叫上了陈同学,到会议室说,小陈啊,我现在手头有一个比较紧急的任务,需要你帮忙处理下。大致的情况是项目二组领导找他了,需要我们这边提供一个创建客户/供应商接口。然后巴拉巴拉说了一大堆的话,最后说jira已经帮你建好了编号是XXX-XXX,你打开看看里面有具体的内容。最后说了一句,今天下班完成哦,并提交给测试。小陈连忙点头并说,好的领导!
陈同学收到任务后,立马跑到座位上,打开jira看了一会需求,开始码代码了。
时间到了下午5点钟,陈同学接口基本写完了,自己用postman测试了几遍,看到没有返回什么异常信息,数据也正常进去了,并提交给测试了。
时间到了5:30分钟左右,测试小姐姐叫了一声,小陈啊,你接口有问题呀o(≧口≦)o,怎么重复的数据都能插入啊!!!,需求要求中文名或者英文名不能重复,我连续点击了多次,现在数据库产生了很多重复记录,这要上生产环境,客户要炸掉了。我不测了,jira我reopen了,你重新改好再提交给我吧!(╬◣д◢)
以上的业务场景,对应数据唯一性有要求的话,一次提交和多次提交产生的结果应该是一样的。
二、如何理解幂等性
这是个高等代数中的概念。 简而言之就是x^Y=x x可能是任何元素,包括(数、矩阵等)
幂等的的意思就是一个操作不会修改状态信息,并且每次操作的时候都返回同样的结果。即:做多次和做一次的效果是一样 的。
在web设计上即指多次HTTP请求返回值相同
简单的说,纯查询,如SELECT,用GET。如果改变数据库的内容,如UPDATE,INSERT,DELETE,用POST。
三、理解HTTP幂等性
根据HTTP标准,HTTP请求可以使用多种请求方式,HTTP/1.1协议中共定义了八种方法/动作,来表明Request-URL指定的资源不同的操作方式
HTTP1.0定义了三种请求方法:GET, POST 和 HEAD方法
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法
下面列举四个常用的方法,来说明下各自是否满足幂等要求
GET
经常使用的方式之一,用于获取数据和资源,不会有副作用,所以是幂等的。
如:URL为http://localhost:8080/crm/get/1,无论调用多少次,数据库数据是不会变 更的,只是每次返回的结果可能不一样,所以是满足幂等。
POST
也是经常使用的方式之一,用于往数据库添加或修改数据,每调用一次
会产生新的数据,是数据经常发生变化,所以不是幂等的。
PUT
常用于创建和更新指定的一条数据,如果数据不存在则新建,如果存在则更新数据,多次和一次调用产生的副作用是一样的,所以是满足幂等。
DELETE
从单词就能理解字面意思,用于删除数据,一般根据ID,如URL:为http://localhost:8080/crm/delete/100,删掉客户ID为100的数据,调用一次或多次对系统产生的副作用是一样的,所以是满足幂等。
四、需要幂等的场景
幂等性问题在我们开发过程中、高并发、分布式、微服务架构中随处可见的,具体举例以下几个经常遇到的场景
网络波动
因网络波动,可能会引起重复请求
MQ消息重复
生产者已把消息发送到mq,在mq给生产者返回ack的时候网络中断,故生产者未收到确定信息,生产者认为消息未发送成功,但实际情况是,mq已成功接收到了消息,在网络重连后,生产者会重新发送刚才的消息,造成mq接收了重复的消息。
用户重复点击
用户在使用产品时,可能会误操作而触发多笔交易,或者因为长时间没有响应,而有意触发多笔交易。
应用使用失败或超时重试机制
为了考虑系统业务稳定性,开发人员一般设计系统时,会考虑失败了如何进行下一步操作或等待一定时间继续前面的动作的。
五、应该在哪一层进行幂等设计
目前互联网技术架构基本都是分布式、微服务架构,层次分的也比较清晰,如
第一层:APP、H5、PC
第二层:负载均衡设备(Nginx)
第三层:网关层(GateWay)
第四层:业务层(Service)
第五层:持久层(ORM)
第六层:数据库层(DB)
那到底在哪一层实现幂等呢?
一般网关层主要的任务是路由转发、请求鉴权和身份认证、限流、跨域、流量监控、请求日志、ACL控制等。如果在网关层实现幂等性,那需要把业务代码写在网关层,这种做法一般在设计中是很少推荐的,所以不适合
业务层主要是处理业务逻辑,对查询或新增的结果进行一些运算等,所以也不合适
持久层也叫数据访问层,和数据库打交道,这块不做幂等性的话,可能对数据产生一定影响,所以这一层是需要作品幂等性校验。
通过以上分析我们得知幂等性一般在持久层去实现。
六、谈谈解决方案
前端幂等性控制
1、按钮只能点击一次
如用户点击查询或提交订单号,按钮变灰或页面显示loding状态。防止用户重复点击。
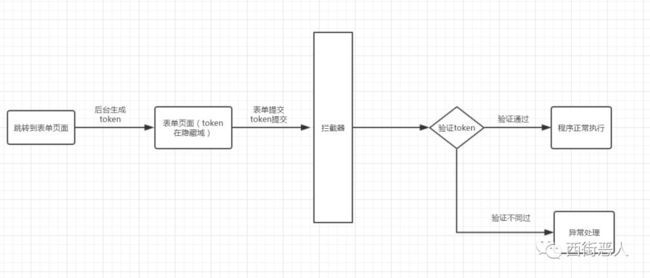
2、token机制
产品允许重复提交,但要保证提交多次和一次产生的结果是一致的。
具体实现是进入页面时申请一个token,然后后面所有请求都带上这个token,根据token来避免重复请求。见下图
3、使用重定向机制(Post-Redirect-Get模式)
当用户提交了表单,后端处理完成后,跳转到另外一个成功或失败的页面,这样避免用户按F5刷新浏览器导致重复提交。
4、在Session存放唯一标识
用户进入页面时,服务端生成一个唯一的标识值,存到session中,同时将它写入表单的隐藏域中,用户在输入信息后点击提交,在服务端获取表单的隐藏域字段的值来与session中的唯一标识值进行比较,相等则说明是首次提交,就处理本次请求,然后删除session唯一标识,不相等则标识重复提交,忽略本次处理。
因前端涉及到多设备,兼容性等问题,以上方案不一定非常可靠。
后端幂等性控制
1、使用数据库唯一索引
开发的同学对数据库肯定不陌生,对数据库的约束也应该比较熟悉,
如MySQL有五大约束,主键、外键、非空、唯一、默认约束。我们可以使用数据库提供的唯一约束来保证数据重复插入,避免脏数据产生。这种做法比较简单粗暴,直接抛出异常信息即可。 2、token+redis
这种方式分成两个阶段:获取token和业务操作阶段。
我们以支付为例
第一阶段,在进入到提交订单页面之前,需要在订单系统根据当前用户信息向支付系统发起一次申请token请求,支付系统将token保存到redis中,作为第二阶段支付使用
第二阶段,订单系统拿着申请到的token发起支付请求,支付系统会检查redis中是否存在该token,如果有,表示第一次请求支付,开始处理支付逻辑,处理完成后删除redis中的token
当重复请求时候,检查redis中token是否存在,不存在,则表示非法请求。可以见下图

该方案唯一的缺点就是需要与系统进行两次交互
3、基于状态控制
如:购物下单,逻辑是当订单状态为已付款,才允许发货
在设计时候最好只支持状态的单向改变(不可逆),这样在更新的时候where条件里可以加上status = 已付款
如:update table set status=下一种状态 where id =1 and status=已付款
4、基于乐观锁来实现
如果更新已有数据,可以进行加锁更新,也可以设计表结构时使用version来做乐观锁,这样既能保证执行效率,又能保证幂等。
乐观锁version字段在更新业务数据时值要自增。
也可以采用update with condition更新带条件来实现乐观锁。
具体看下version如何定义
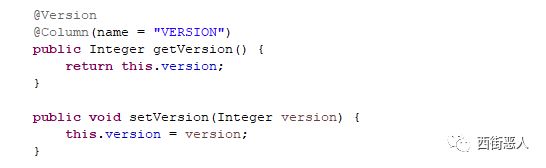
sql为:update table set q =q,version = version + 1 where id =1 and version =#{version }
5、防重表
需要增加一个表,这个表叫做防重表(防止数据重复的表)
使用唯一主键如:uuid去做防重表的唯一索引,每次请求都往防重表中插入一条数据。第一次请求由于没有记录插入成功,成功后进行后续业务处理,处理完后(无论成功或失败)删除去重表中的数据,如果在处理过程中,有新的相同uuid请求过来,插入的时候因为表中唯一索引而插入失败,则返回操作失败。可以看出防重表作用是加锁的功能。
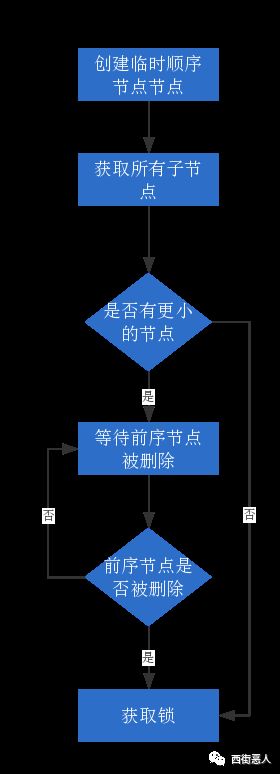
6、分布式锁
在进入方法时,先获取锁,假如获取到锁,就继续后面流程。假设没有获取到锁,就等待锁的释放直到获取锁,当执行完方法时,释放锁,当然,锁要设个超时时间,防止意外没有释放到锁,它可以用来解决分布式系统的幂等性;
常用的分布式锁实现方案是redis 和 zookeeper 等工具。
使用分布式锁类似于防重表,将防重并发放到了缓存中,较为高效,同一时间只能完成一次操作。
zk实现分布式锁的流程如下
redis 分布式锁工具类
@Component
public class RedisLock {
private static final Long RELEASE_SUCCESS = 1L;
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
// 当前设置 过期时间单位, EX = seconds; PX = milliseconds
private static final String SET_WITH_EXPIRE_TIME = "EX";
//lua
private static final String RELEASE_LOCK_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
@Autowired
private StringRedisTemplate redisTemplate;
/**
* 该加锁方法仅针对单实例 Redis 可实现分布式加锁
* 对于 Redis 集群则无法使用
*
* 支持重复,线程安全
*
* @param lockKey 加锁键
* @param clientId 加锁客户端唯一标识(采用UUID)
* @param seconds 锁过期时间
* @return
*/
public boolean tryLock(String lockKey, String clientId, long seconds) {
return redisTemplate.execute((RedisCallback) redisConnection -> {
// Jedis jedis = (Jedis) redisConnection.getNativeConnection();
Object nativeConnection = redisConnection.getNativeConnection();
RedisSerializer stringRedisSerializer = (RedisSerializer) redisTemplate.getKeySerializer();
byte[] keyByte = stringRedisSerializer.serialize(lockKey);
byte[] valueByte = stringRedisSerializer.serialize(clientId);
// lettuce连接包下 redis 单机模式
if (nativeConnection instanceof RedisAsyncCommands) {
RedisAsyncCommands connection = (RedisAsyncCommands) nativeConnection;
RedisCommands commands = connection.getStatefulConnection().sync();
String result = commands.set(keyByte, valueByte, SetArgs.Builder.nx().ex(seconds));
if (LOCK_SUCCESS.equals(result)) {
return true;
}
}
// lettuce连接包下 redis 集群模式
if (nativeConnection instanceof RedisAdvancedClusterAsyncCommands) {
RedisAdvancedClusterAsyncCommands connection = (RedisAdvancedClusterAsyncCommands) nativeConnection;
RedisAdvancedClusterCommands commands = connection.getStatefulConnection().sync();
String result = commands.set(keyByte, valueByte, SetArgs.Builder.nx().ex(seconds));
if (LOCK_SUCCESS.equals(result)) {
return true;
}
}
if (nativeConnection instanceof JedisCommands) {
JedisCommands jedis = (JedisCommands) nativeConnection;
String result = jedis.set(lockKey, clientId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, seconds);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
}
return false;
});
}
/**
* 与 tryLock 相对应,用作释放锁
*
* @param lockKey
* @param clientId
* @return
*/
public boolean releaseLock(String lockKey, String clientId) {
DefaultRedisScript redisScript = new DefaultRedisScript<>();
redisScript.setScriptText(RELEASE_LOCK_SCRIPT);
redisScript.setResultType(Integer.class);
// Integer execute = redisTemplate.execute(redisScript, Collections.singletonList(lockKey), clientId);
Object execute = redisTemplate.execute((RedisConnection connection) -> connection.eval(
RELEASE_LOCK_SCRIPT.getBytes(),
ReturnType.INTEGER,
1,
lockKey.getBytes(),
clientId.getBytes()));
if (RELEASE_SUCCESS.equals(execute)) {
return true;
}
return false;
}
}
6、缓存队列
将请求快速的接收下来,放入缓冲队列中,后续使用异步任务处理队列的数据,过滤掉重复请求,我们可以用LinkedList来实现队列,一个HashSet来实现去重。此方法优点是异步处理、高吞吐,不足是不能及时返回请求结果,需要后续轮询处理结果。
7、全局唯一ID
比如通过source来源+seq组成ID来判断请求是否重复,在并发时,只能处理一个请求,其它要么并发请求那么返回请求重复,那么等待前面的请求执行完成后 在执行。具体我们可以将请求关键性数据或者请求的全部数据组合生成md5码,这样的话,重复请求都是一个相同ID;如果所有请求包括重复请求都要唯一ID,那么可以用UUID或者用雪花算法生成唯一ID。
六、保证幂等性总结
幂等性应该是合格程序员的一个基因,在设计系统时,是首要考虑的问题,尤其是在像支付宝,银行,互联网金融公司等涉及的网上资金系统,既要高效,
数据也要准确,所以不能出现多扣款,多打款等问题,这样会很难处理,并会大大降低用户体验。
结束语:
成为高手,需要出色的学习归纳能力,而成为大师,则需要在综合的基础上。