大数据电影可视化系统
本项目以电影数据为主题,以数据采集、处理、分析及数据可视化为项目流程,可实现百万级电影数据离线处理与计算。
项目链接: https://github.com/GoAlers/Bigdata-movie
开发环境:IDEA+Pycharm+Python3+hadoop2.8+hive2.3.0+mysql5.7+sqoop+spark
其中针对大数据分析流程部分流程图:
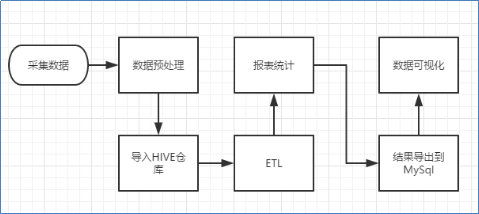
1.数据采集(pachong.py)、预处理:
采集豆瓣电影top250电影信息,采集电影名称、电影简介、电影评分、其他信息、电影连接等字段,抓取电影票房总收入排名情况(取前20),删除冗余和空值字,利用Python的PyMysql库连接本地Mysql数据库并导入movies表,可以将数据保存到本地,从而进行数据可视化展示,也可将数据导入到大数据的Hive数仓工具中,用于大数据分析。
采集数据展示:
| 排序 | 影片名称 | 类型 | 总票房(万) | 场均人次 | 上映日期 |
| 1 | 战狼2 | 动作 | 567928 | 38 | 2017/7/27 |
| 2 | 哪吒之魔童降世 | 动画 | 501324 | 24 | 2019/7/26 |
| 3 | 流浪地球 | 科幻 | 468433 | 29 | 2019/2/5 |
| 4 | 复仇者联盟4:终局之战 | 动作 | 425024 | 23 | 2019/4/24 |
| 5 | 红海行动 | 动作 | 365079 | 33 | 2018/2/16 |
| 6 | 唐人街探案2 | 喜剧 | 339769 | 39 | 2018/2/16 |
| 7 | 美人鱼 | 喜剧 | 339211 | 44 | 2016/2/8 |
| 8 | 我和我的祖国 | 剧情 | 317152 | 36 | 2019/9/30 |
| 9 | 我不是药神 | 剧情 | 309996 | 27 | 2018/7/5 |
| 10 | 中国机长 | 剧情 | 291229 | 27 | 2019/9/30 |
2.数据统计及可视化:
数据可视化能使数据更加直观,更有利于分析,可以说可视化技术是数据分析与挖掘最重要的内容。Matplotlib作为基于Python语言的开源项目,旨在为Python提供一个数据绘图包,实现专业丰富的绘图功能。
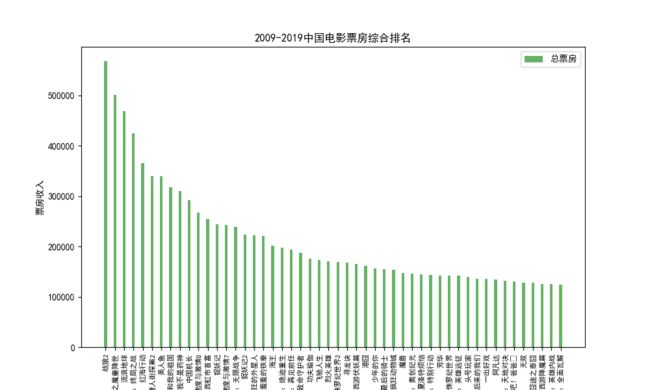
(1)电影票房排名
利用Python中Matplotlib绘图库及Pandas中的pd.readcsv()方法读取Excel电影数据文件,读取每列数据进行,设置参数将结果绘制成折线图。
(2)电影评分排名douanscore.py
利用Python的Request、Beautifulsoup库进行爬虫,模拟请求获取网页数据,结合正则表达式匹配提取数据,并将豆瓣电影top250电影数据存储到Mysql数据库中,通过数据库语句使用order by实现电影top评分统计。
movie表结构:
| 属性 | 字段命名 | 类型 | 约束 |
| id | 序号 | int | primary key |
| name | 电影名称 | VARCHAR(20) | not null |
| Link | 电影连接 | VARCHAR(100) | not null |
| score | 评分 | VARCHAR(5) | not null |
| descr | 电影概述 | VARCHAR(50) | |
| directer | 导演及其他 | VARCHAR(100) |
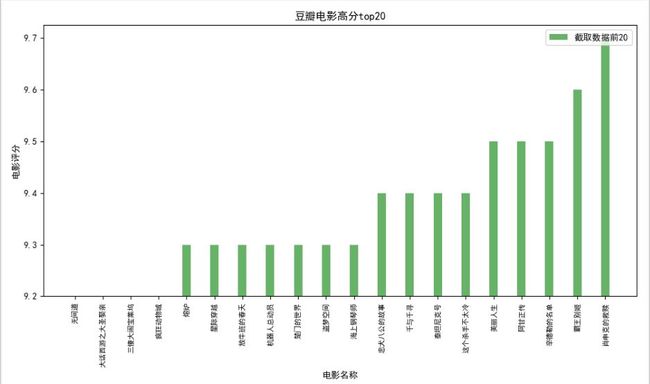
最终电影数据结果如下:

利用数据库语句统计movies进行电影评分top20,并将结果通过Python的Matplotlib库进行数据可视化,绘图结果如下:
(3)Echarts最近上映电影
Echarts 主要用于数据可视化展示,是一个开源的JavaScript库,兼容现有绝大部分浏览器。在Python中,Echarts被包装成数据可视化工具库Pyecharts。它提供直观、丰富、可个性化定制的数据可视化图表,包括常规的折线图、柱状图、散点图、饼图等。

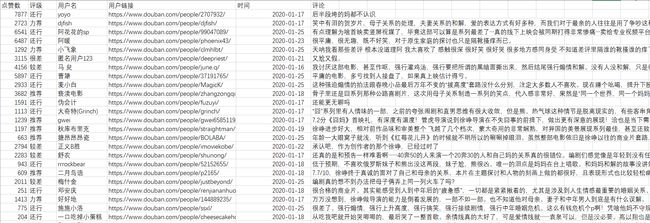
(4)影片《囧妈》短评信息
大年初一电影《囧妈》网络首映映,截止目前其豆瓣电影评分6.0分,通过电影《囧妈》的豆瓣热门短评进行案例分析,以八爪鱼软件为数据采集工具进行数据爬虫,采集字段有用户名、评级、点赞数和评论内容等信息,利用正则表达式匹配字段标签,根据豆瓣电影提供的评级星数系统显示力荐、推荐、还行、较差、很差等五个评级,满分为五星,数据格式如下:
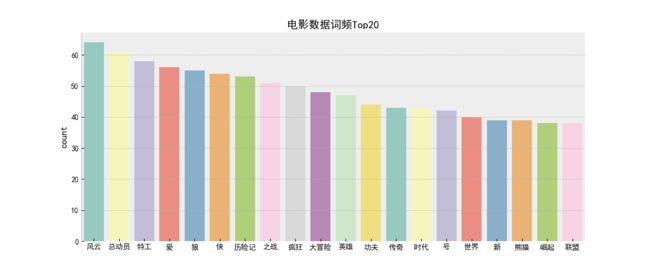
(5)词图云cituyun.py
利用Python的jieba分词工具以及wordcloud库实现词云展示,截取电影《囧妈》评论一列,按照规定的停用词切割每行语句,实现分词功能。通过词图云展示可以直观地看出用户对电影的态度情况,数据展示结果如下:

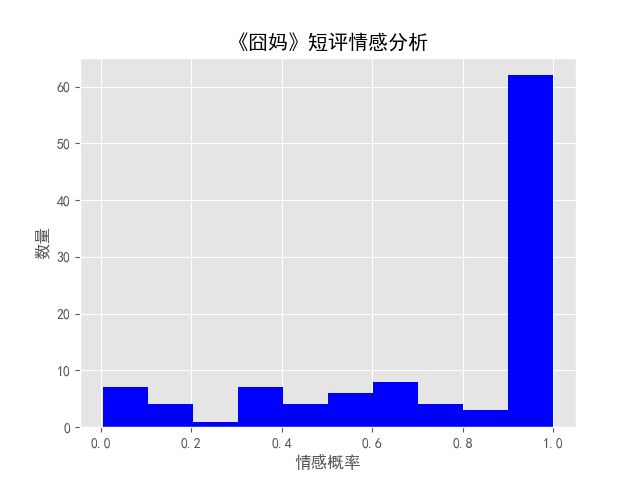
(6)情感分析emotion.py
运用Python机器学习中的情感分析库Snownlp和绘图库pyplot挖掘囧妈短评数据,做出情感分析并展示。利用Snownlp中s.sentiments方法计算情感分数,分数在0.5以上判断为是好评,可以看到电影的评论差距明显。情感分析效果图如下:
(7)python词频统计wordcount.py
3.大数据分析:
大数据处理最重要的环节就是数据分析,数据分析通常分为两种:批处理和流处理。批处理是对一段时间内海量的离线数据进行统一处理,对应的处理框架Mapreduce、Spark等;流处理则是针对动态实时的数据处理,即在接收数据的同时就对其进行处理,对应的处理框架有 Storm、Spark Streaming、Flink等。本文以离线计算为主,介绍电影数据分析。
(1)Mapreduce离线计算(mapreduce_hive文件)
Mapreduce编程词频统计主要利用wordcount思想,通过按规定格式分割词句,实现单词统计词频。其统计数据为历史电影的上映信息,map阶段主要负责单词分割统计,map阶段把每个字符串映射成键、值对,按行将单词映射成(单词,1)形式,Shuffle过程会对map的结果进行分区排序,然后按照同一分区的输出合并在一起写入到磁盘中,最终得到一个分区有序的文件,最后reduce阶段会汇总统计出每个词对应个数,数据最终会存储在HDFS上。本文以电影词作为统计对象,实现单词统计词频功能。词频统计流程图如下:
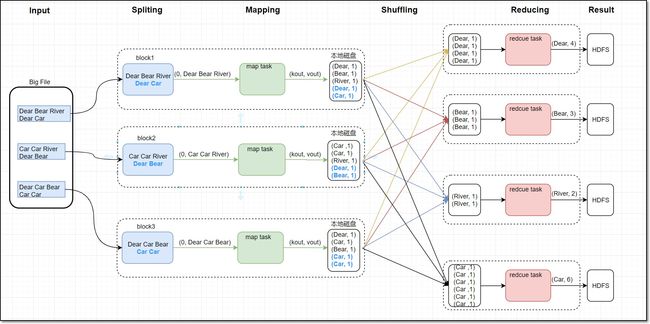
map阶段会把每个字符串映射成键、值对,按行将单词映射成(单词,1)形式输出,其中shuffle过程会对map的结果进行分区排序,然后按照同一分区的输出合并在一起写入到磁盘中,最终得到一个分区有序的文件。通过Python编程实现Map阶段代码如下:
Map阶段代码:
import sys
for line in sys.stdin:
ss = line.strip().split(' ')
for s in ss:
if s.strip() != "":
print "%s\t%s" % (s, 1)(2)reduce阶段
reduce阶段会汇总map阶段结果每个词对应个数,数据最终会存储在HDFS上。本文通过统计《哈利波特》英文电影文本,实现词频统计功能。实现Reduce阶段代码如下:
Reduce阶段代码:
import sys
current_word = None
count_pool = []
sum = 0
for line in sys.stdin:
word, val = line.strip().split('\t')
if current_word == None:
current_word = word
if current_word != word:
for count in count_pool:
sum += count
print "%s\t%s" % (current_word, sum)
current_word = word
count_pool = []
sum = 0
count_pool.append(int(val))
for count in count_pool:
sum += count
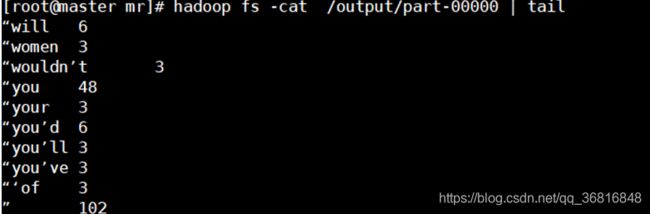
print "%s\t%s" % (current_word, str(sum))利用Hadoop Streaming可以使用任何可运行程序或语言作为Map和Reduce的创建和执行MapReduce作业,通过编写shell脚本执行wordcount统计结果如下:
(2)Hive数据仓库
Hive是一个基于Hadoop的数据仓库工具,主要用于解决海量结构化日志的数据统计,可以将结构化的数据文件映射成一张表,通过类SQL语句的方式对表内数据进行查询、统计分析。利用Sqoop数据传输工具可以将Mysql数据库信息导入到Hive数仓。
运用Hive可以实现海量数据分析,并且支持自定义函数,省去MapReduce编程。本文针对历史豆瓣电影数据进行统计,数据经过清洗,删除空值、多余项,得到大约100000多条电影数据,部分数据格式如下:
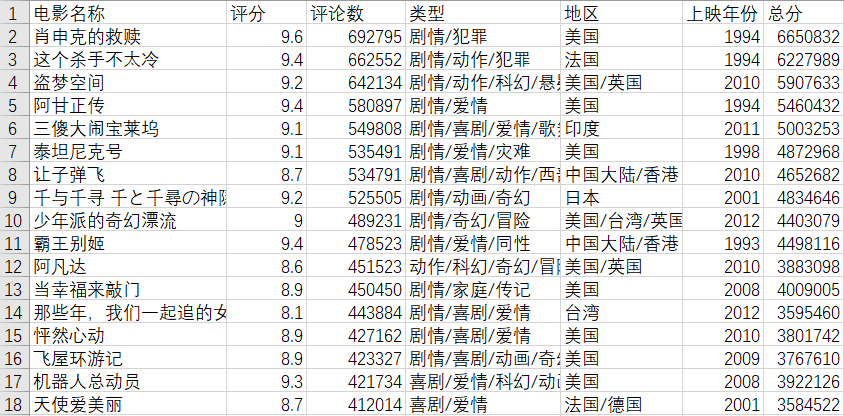
(1)建表
Hive建表分为内部表和外部表两种。创建内部表,表内数据将会移动到数据仓库指向的路径,删除表时,数据会随之删除;而外部表在删除时,不会删除数据表原有信息,相对更加安全。
本文电影表包括电影名称、评分、评论人数、类型、上映年份,以及总分等字段,数据默认逗号分隔,其中总分=电影评分*评论人数,数据创建命令如下:
create table IF NOT EXISTS movie1(name string,
score double,
people int,
type string,
address string,
time int,
sum float)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';(2)导入数据
Hadoop支持各类型文件上传到HDFS,可以通过本地命令直接上传到Hive中,也可以利用Sqoop数据传输工具实现将Mysql数据库与Hive数据库互传。本地导入命令如下:
load data local inpath '/douban/movie.csv' into table movie1;
(3)统计分析
Hive底层基于Mapreduce执行,利用distribute by和sort by命令可以实现分组排序,统计总分在1000000分以上电影数据,并按照评分、总得分降序顺序排列,优化后命令如下:
select name,score,sum,time
from movie1
where sum > 1000000
distribute by score sort by score desc,sum desc
limit 20;
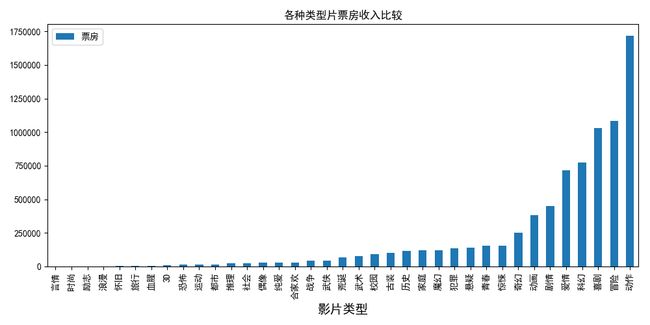
(3)影片类型与票房统计图movietype.py
(5)导演与影片类型关系图director.py
(6)电影票房预测(电票票房预测.xls)
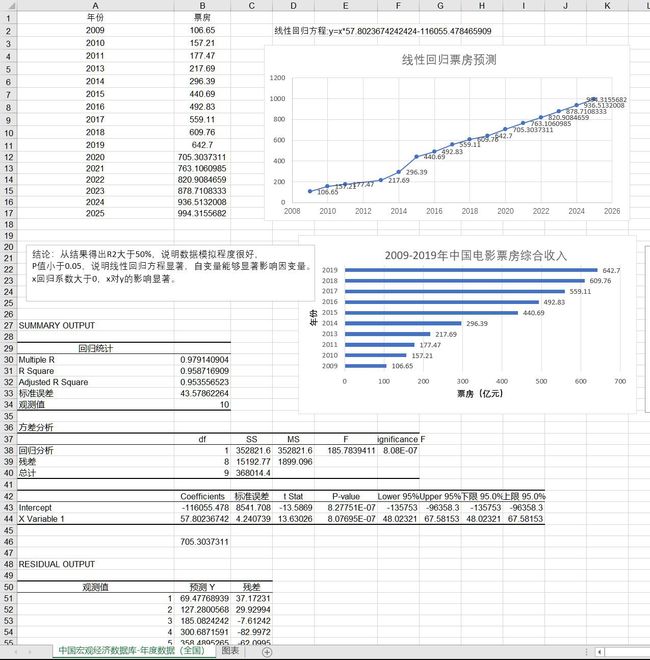
(7)电影评分预测scorepredict.py
利用机器学习sklearn库建立回归模型,随机取5个用户计算评分预测出用户对于某新影片的评分范围,输出评分最大、最小、平均值。
#encoding:utf-8
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import re
from sklearn.linear_model import LinearRegression
#绘图部分
data = pd.read_csv('lianxi/film-csv.txt',encoding = 'utf-8',delimiter = ';') #读取文件
data = data.iloc[:,:-1] #去除文件中的非法数据
data = data.drop(0).drop_duplicates().reset_index().drop('index',axis = 1) #由于第一行为空数据 去除 并去重 重置索引
# print data
t = [] #将电影类型按多种分割符切分
for i in range(len(data)):
a = re.split(u' / |/|,|、| | ',data[u'影片类型'][i])
for j in a:
t.append(j)
t = set(t) #将重复的类型去掉
tt = []
for i in t: #将不规范的类型去除 得出所有存在的类型
if (len(i)<=2)|(i==u'合家欢'):
tt.append(i)
#评分预测
id = [1050,1114,1048,1488,1102] #五个用户id
data1 = pd.read_csv('lianxi/score.log',delimiter=',',encoding = 'utf-8',header=0,names = [u'电影名称',u'userid',u'score'])
data1 = data1[data1[u'userid'].isin(id)] #去除五个用户 相关数据
data1[u'电影名称'] = data1[u'电影名称'].str.strip() #去除电影名称的空格
all = []#用来存预测结果
for k in range(len(id)): #循环五次 建模 进行预测
dfp1 = data1[data1[u'userid']==id[k]].reset_index().drop('index',axis = 1)
datamerge = pd.merge(data,dfp1,on=u'电影名称') #用merge 将电影详细信息 与新用户评分合并
lst = []
lsd = []
lsr = []
for i in range(len(datamerge)): #切分出电影类型 和导演 以及对应的票房
for j in tt:
if j in datamerge[u'影片类型'][i]:
d = re.split(u',|、|/| ',datamerge[u'导演'][i])
for k in d:
lsd.append(k.replace(u' ', u''))
lst.append(j.replace(u' ', u''))
lsr.append(datamerge[u'score'][i])
lsd1 = list(set(lsd))
for i in range(len(lsd1)): #将电影类型和票房转成 连续量 以便机器训练
for j in range(len(lsd)):
if lsd1[i] == lsd[j]:
lsd[j] = i + 1
for i in range(len(tt)):
for j in range(len(lst)):
if tt[i] == lst[j]:
lst[j] = i + 1
lsd = pd.DataFrame(lsd, columns=[u'导演'])
lst = pd.DataFrame(lst, columns=[u'影片类型'])
lsr = pd.DataFrame(lsr, columns=[u'评分'])
a = pd.concat([lsd, lst, lsr], axis=1)
print(a)
trainx = a.iloc[:, 0:2] # 电影类型和 导演 作为特征量
trainy = a.iloc[:, 2:3] # 评分作为样本值
l = LinearRegression() # 建模
l.fit(trainx, trainy) # 训练
anstest = pd.DataFrame([[5,10]],columns=[u'导演',u'影片类型'])
ans = l.predict(anstest)#预测
all.append(ans[0][0]) #得出结果
print (u'评分最大值是'+'%.2f'%max(all)) #输出
print (u'评分最小值是'+'%.2f'%min(all))
print (u'评分中位数值是'+'%.2f'%np.median(all))
print (u'评分平均值是'+'%.2f'%np.mean(all))额外电影数据集链接:https://pan.baidu.com/s/1ji3YIjCSGXbvFh7swiWdFg 提取码:1234
实现更多电影数据维度分析,后期更新。
Spark电影数据分析实战:https://github.com/GoAlers/Spark-Movie