百面机器学习—11.集成学习(GBDT、XGBoost)面试问题总结
文章目录
-
-
- 1. 大小为N的样本集进行有放回抽样,样本N次有重复抽取被选中的概率是多少?
- 2.集成学习分为哪几种?它们有何异同?
- 3. 为什么很多集成学习模型都选择决策树作为基分类器?
- 4.什么是偏差与方差?如何从减小方差和偏差的角度解释Boosting和Bagging的原理?
-
- 4.1 什么是偏差与方差?
- 4.2 如何从减小方差和偏差的角度解释Boosting和Bagging的原理?
- 5. GBDT算法问题总结
-
- 5.1梯度提升树GBDT的基本原理是什么?
- 5.2 为什么可以使用梯度近似代替残差?
- 5.3 二分类问题的GBDT算法
- 5.4 多分类问题的GBDT算法
- 5.5 回归问题的GBDT算法
- 5.6 GBDT的boosting体现在哪里?
- 5.7 GBDT树根据什么分裂?怎么选择特征?
- 5.8 GBDT怎么用于分类?
- 5.9 GBDT的优点和局限性有哪些?
- 5.10 随机森林和GBDT的异同点有哪些?
- 5.11 Adaboost和GBDT的区别有哪些?
- 5.12 GBDT是怎么构建特征的?
- 6. XGBoost算法问题总结
-
- 6.1 XGBoost算法的原理
-
- 6.1.1 XGBoost算法预备知识
- 6.1.2 XGBoost算法结构分
- 6.1.3 XGBoost算法之贪心算法寻找分裂点
- 6.1.4 XGBoost算法之近似算法和加权分桶
- 6.1.5 XGBoost算法之缺失值处理
- 6.1.6 XGBoost算法之其他优化
- 6.2 总结GBDT和XGBoost的联系和区别
- 6.3 XGBoost为什么使用泰勒二阶展开?
- 6.4 XGBoost为什么可以并行训练?
- 6.5 XGBoost为什么快?
- 6.6 XGBoost防止过拟合的方法是什么?
- 6.7 使用XGBoost训练模型时,如果过拟合了怎么调参?
- 6.8 XGBoost 如何处理缺失值?
- 6.9 XGBoost如何选择最佳分裂点?
- 6.10 XGBoost中如何对树进行剪枝?
- 6.11 XGBoost的延展性很好,怎么理解?
- 6.12 XGBoost的优缺点有哪些?
- 6.13 xgboost使用之前是否需要对数据进行归一化处理?
- 6.14 xgboost使用之前是否需要对类别型特征进行one-hot处理?
- 6.15 XGBoost可以做特征选择,它是如何评价特征重要性的?
-
GBDT、XGBoost是校招算法面试中的重点难点,这是一份精心总结的关于集成学习面试中常见问题,如果对您有帮助的话,不妨点赞、收藏、关注!!!
1. 大小为N的样本集进行有放回抽样,样本N次有重复抽取被选中的概率是多少?

2.集成学习分为哪几种?它们有何异同?
集成学习方法可以分为Bagging和Boosting。
Bagging方法在训练过程中,各基分类器之间无强依赖,可以进行并行训练。Bagging的基本思路是:每一次从原始数据中自助采样(有放回),样本点可能出现重复,不同的训练集随机子集在基模型上进行训练,再对这些基模型进行组合,通过投票的方式作出最后的集体决策。Bagging方法之所以有效,是因为每个模型都是在略微不同的训练数据集上拟合完成的,这又使得每个基模型之间存在略微的差异,使每个基模型拥有略微不同的训练能力。
这里介绍一下随机森林:

Boosting方法在训练过程中,基分类器采用串行方式,各个基分类器之间有依赖。Boosting的基本思路是将基分类器层层叠加,后一个基分类器在训练时,对前一个基分类器分错的样本给予更高的权重,使模型在之后的训练中更加注意难以分类的样本,这是一个不断学习的过程。
这里介绍一下AdaBoost:

3. 为什么很多集成学习模型都选择决策树作为基分类器?
- 决策树可以较为方便地将样本的权重整合到训练过程中,而不需要使用过采样的方法来调整样本权重。
- 决策树的表达能力和泛化能力,可以通过调节树的层数来做折中。
- 数据样本的扰动对于决策树的影响较大,因此不同子样本集合生成的决策树基分类器随机性较大,这样的“不稳定学习器”更适合作为基分类器。此外,在决策树节点分裂的时候,随机地选择一个特征子集,从中找出最优分裂属性,很好地引入了随机性。
除了决策树外,神经网络模型也适合作为基分类器,主要由于神经网络模型也比较“不稳定”,而且还可以通过调整神经元数量、连接方式、网络层数、初始权值等方式引入随机性。
4.什么是偏差与方差?如何从减小方差和偏差的角度解释Boosting和Bagging的原理?
4.1 什么是偏差与方差?
偏差指的是由所有采样得到的大小为m的训练数据集训练出的模型的输出的平均值和真实模型输出之间的偏差。偏差主要是由于分类器的表达能力有限导致的系统性错误,表现在训练误差不收敛。通俗来讲,就是假设错了,导致分类器没选好
方差指的是由所有采样得到的大小为m的训练数据集训练出的模型的输出的方差。方差通常是由于模型的复杂度相对于训练样本数m过高导致的。方差是由于分类器对于样本分布过于敏感,导致在训练样本数较少时,产生过拟合。
4.2 如何从减小方差和偏差的角度解释Boosting和Bagging的原理?
Bagging方法则是采取分而治之的策略,通过对训练样本多次重采样,并分别训练出多个不同模型,然后做综合,来减小集成分类器的方差。假设模型是独立不相关的,对n个独立不相关的模型的预测结果取平均,方差是原来单个模型的1/n。
当然,模型之间不可能完全独立。为了追求模型的独立性,诸多Bagging 的方法做了不同的改进。比如在随机森林算法中,每次选取节点分裂属性时,会随机抽取一个属性子集,而不是从所有属性中选取最优属性,这就是为了避免弱分类器之间过强的相关性。通过训练集的重采样也能够带来弱分类器之间的一定独立性,从而降低 Bagging后模型的方差。
Boosting方法是通过逐步聚焦于基分类器分错的样本,不断较小损失函数,来使模型接近“靶心”,使得模型偏差不断降低。但是Boosting的过程并不会显著降低方差,这是因为Boosting的训练过程使得各弱分类器之间是强相关的,缺乏独立性,所以并不会降低方差。
5. GBDT算法问题总结
5.1梯度提升树GBDT的基本原理是什么?
首先,先弄清楚一个点:GBDT的核心在于累加所有树的结果作为最终结果,GBDT可用于分类,并不代表是累加所有分类树的结果。GBDT中的树都是回归树
梯度提升树:当损失函数是平方损失时,下一棵树拟合的是上一棵树的残差值(实际值减预测值)。当损失函数是非平方损失时,拟合的是损失函数的负梯度值,利用损失函数的负梯度在当前模型的值作为残差的一个近似值,进行拟合回归树。梯度提升算法实际采用加法模型(基函数的线性组合)与前向分布算法。

梯度提升算法的基本流程可以总结为:在每一次迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最后实现对模型的更新,其算法伪代码如下:

算法伪代码中, N N N表示数据的数量, M M M表示基分类器的数量, h ( x i : a m ) h(x_i:a_m) h(xi:am)表示基本分类器 ,4中 a m a_m am表示拟合负梯度能力最好的分类器参数,负梯度只是表示下降的方向,但是下降多少没有确定,5中 p m p_m pm可以认为是下降最快的步长(也可以认为是学习率),可以让 L o s s Loss Loss最小,可以用线性搜索的方式来估计 p m p_m pm的值。
一个包含 J J J个节点的回归树模型可以表示为
h ( x , { b j , R j } 1 J ) = ∑ j = 1 J b j I ( x ∈ R j ) h(x,\{b_j,R_j\}_{1}^{J})=\sum_{j=1}^{J}b_jI(x∈R_j) h(x,{ bj,Rj}1J)=j=1∑JbjI(x∈Rj)
其中 { R j } 1 J \{R_j\}_{1}^{J} { Rj}1J是不相交区域,可以认为是落在一颗决策树叶子节点上的 x x x值的集合; { b j } 1 J \{b_j\}_{1}^{J} { bj}1J是叶子节点的值。 b j b_j bj的计算方式:对于回归问题,计算方式可以取落在该叶子节点的样本点的平均值;对于分类问题,计算方式可以取落在该叶子节点中数量多的类别。
从算法中,我们可以看出先求出 b j m b_{jm} bjm,然后在求解 ρ m \rho_{m} ρm,那可不可以一起求解呢?
F m ( x ) = F m − 1 ( x ) + ρ m ∑ j = 1 J b j m I ( x ∈ R j m ) F_m(x)=F_{m-1}(x)+\rho_{m}\sum_{j=1}^{J}b_{jm}I(x∈R_{jm}) Fm(x)=Fm−1(x)+ρmj=1∑JbjmI(x∈Rjm)
令 γ j m = ρ m b j m \gamma_{jm}=\rho_{m}b_{jm} γjm=ρmbjm
F m ( x ) = F m − 1 ( x ) + ∑ j = 1 J γ j m I ( x ∈ R j m ) F_m(x)=F_{m-1}(x)+\sum_{j=1}^{J}\gamma_{jm}I(x∈R_{jm}) Fm(x)=Fm−1(x)+j=1∑JγjmI(x∈Rjm)
这样就把几个参数合并成一个来求解,并且由于叶子节点各个区域互不相加,样本最终都会属于某个节点因此可以求解如下公式来获取最优 γ j m \gamma_{jm} γjm
γ j m = a r g m i n γ ∑ x i ∈ R j m L ( y i , F m − 1 ( x i ) + γ ) \gamma_{jm}=argmin_{\gamma}\sum_{x_i∈R_{jm}}L(y_i,F_{m-1}(x_i)+\gamma) γjm=argminγxi∈Rjm∑L(yi,Fm−1(xi)+γ)
给定当前的 F m − 1 ( x i ) F_{m-1}(x_i) Fm−1(xi), γ j m \gamma_{jm} γjm可以作为叶子节点的值,该值可以看做是基于损失函数L的每一个叶子节点的理想更新值,也可以认为 γ j m \gamma_{jm} γjm既有下降方向又有下降步长。
其中4可能不太好理解,可以理解为求解一棵树,并且形成了不相交的叶子节点区域

5.2 为什么可以使用梯度近似代替残差?
梯度提升树的损失函数为:


5.3 二分类问题的GBDT算法


因此,整体的算法可以如下表示:

现在我们只需要理解其初始值是如何设置的以及怎么使用牛顿法得出近似结果的,就可以实现二分类的GBDT算法。
- 初始值是如何设置的?


- 牛顿法近似求解是怎么求的?

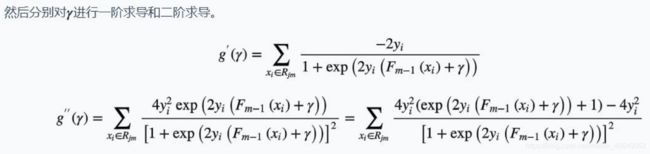
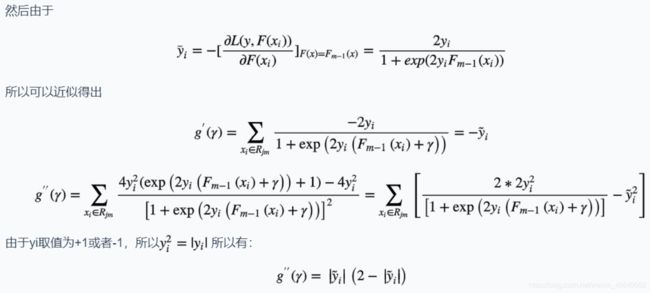
- 最后如何进行分类

5.4 多分类问题的GBDT算法



5.5 回归问题的GBDT算法
想要了解huber损失函数的可以参考这个博客:最常用的5个回归损失函数


5.6 GBDT的boosting体现在哪里?
GBDT基本流程可以总结为:在每一次迭代中,首先计算出当前模型在所有样本上的负梯度,然后以该值为目标训练一个新的弱分类器进行拟合并计算出该弱分类器的权重,最后实现对模型的更新。
5.7 GBDT树根据什么分裂?怎么选择特征?
GBDT树的基分类器一般使用CART回归树。CART回归树采用平方误差最小化准则进行特征选择生成二叉树。

GBDT树可用于分类与回归任务,不同任务对应的损失函数不同。以原始论文中为例,二分类问题的GBDT中CART树将采用对数损失最小化准则进行特征选择生成二叉树。三分类问题的GBDT中CART树将采用交叉熵损失最小化准则进行特征选择生成二叉树。回归问题的GBDT中CART树将采用huber损失最小化准则进行特征选择生成二叉树,或者直接采用平方误差最小化准则进行特征选择生成二叉树。
5.8 GBDT怎么用于分类?
参考二/三分类问题的GBDT算法来答
5.9 GBDT的优点和局限性有哪些?
优点:
- 预测阶段的计算速度快,树与树之间可并行计算
- 在分布稠密的数据集上,泛化能力与表达能力都很好
- 采用决策树作为弱分类器使得GBDT模型具有较好的解释性和鲁棒性,能够自动发现特征间的高阶关系,并且也不需要对数据进行特殊的预处理如归一化等
局限性:
- GBDT在高维稀疏的数据集上,表现不如支持向量机或神经网络。
- GBDT在处理文本分类特征问题上,相对其他模型的优势不如处理在数值特征上明显。
- 训练过程需要串行训练,只能在决策树内部采用一些局部并行手段提高训练速度。
5.10 随机森林和GBDT的异同点有哪些?
相同点:
- 都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:
- 集成学习:RF属于bagging思想,而GBDT是boosting思想。
- 偏差-方差权衡:RF不断的降低模型的方差,而GBDT不断的降低模型的偏差。
- 基分类器: 组成随机森林的树可以是分类树,也可以是回归树;而GBDT只能由回归树组成;
- 训练样本:RF每次迭代的样本是从全部训练集中有放回抽样形成的,而GBDT每次使用全部样本。
- 并行性:RF的树可以并行生成,而GBDT只能顺序生成(需要等上一棵树完全生成)。
- 最终结果:RF最终是多棵树进行多数表决(回归问题是取平均),而GBDT是加权融合。
- 数据敏感性:RF对异常值不敏感,而GBDT对异常值比较敏感。
- 泛化能力:RF不易过拟合,而GBDT容易过拟合。
5.11 Adaboost和GBDT的区别有哪些?
Adaboost是通过提高错分样本的权重来定位模型的不足;GBDT是通过负梯度来定位模型的不足,因此GBDT可以使用更多种类的损失函数。
5.12 GBDT是怎么构建特征的?
决策树可以用于特征构造,创建新特征。在回答GBDT是怎么构建特征的?之前,我们先分析GBDT相对于单颗决策树与随机森林在特征构造方面的优势(即为什么选择GBDT算法):
- 采用ensemble决策树而非单颗树
一棵树的表达能力很弱,不足以表达多个有区分性的特征组合,多棵树的表达能力更强一些。GBDT每棵树都在学习前面棵树尚存的不足,迭代多少次就会生成多少颗树。多棵树正好满足 LR 每条训练样本可以通过 GBDT映射成多个特征的需求。 - 采用 GBDT 而非 RF
RF 也是多棵树,但从效果上有实践证明不如 GBDT。且 GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前 N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用 GBDT的原因。
那么,GBDT是怎么构造特征的呢?
gbdt本身是不能产生特征的,但是我们可以利用gbdt去产生特征的组合。Facebook在2014年发表的一篇论文就是利用gbdt去产生有效的特征组合,以便用于逻辑回归的训练,提升模型最终的效果。比如:我们使用GBDT生成了两棵树,两颗树一共有五个叶子节点。我们将样本×输入到两颗树当中去,样本X落在了第一棵树的第二个叶子节点,第二颗树的第一个叶子节点,于是我们便可以依次构建一个五纬的特征向量,每一个纬度代表了一个叶子节点,样本落在这个叶子节点上面的话那么值为1,没有落在该叶子节点的话,那么值为0。于是对于该样本,我们可以得到一个向量[0,1,0,1,0]作为该样本的组合特征,和原来的特征一起输入到逻辑回归当中进行训练。实验证明这样会得到比较显著的效果提升。且工业界现在已有实践,GBDT+LR、GBDT+FM都是值得尝试的思路。这里介绍一个GBDT+LR的实现过程。
import numpy as np
import random
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.preprocessing import OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_curve, roc_auc_score
# 生成随机数据
np.random.seed(10)
X, Y = make_classification(n_samples=1000, n_features=30)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=233, test_size=0.4)
# LR模型
LR = LogisticRegression()
LR.fit(X_train, Y_train)
y_pred = LR.predict_proba(X_test)[:, 1]
fpr, tpr, _ = roc_curve(Y_test, y_pred)
auc = roc_auc_score(Y_test, y_pred)
print('LogisticRegression: ', auc)
# 训练GBDT模型
gbdt = GradientBoostingClassifier(n_estimators=10)
gbdt.fit(X_train, Y_train)
# 将训练好的树应用到X_train,返回叶索引,shape大小为(600,10,1)
print(gbdt.apply(X_train)[:, :, 0])
# print(gbdt.apply(X_train)[:, :, 0].shape)
# 对GBDT预测结果进行onehot编码
onehot = OneHotEncoder()
onehot.fit(gbdt.apply(X_train)[:, :, 0])
print(onehot.transform(gbdt.apply(X_train)[:, :, 0]))
# 训练LR模型
lr = LogisticRegression()
lr.fit(onehot.transform(gbdt.apply(X_train)[:, :, 0]), Y_train)
# 测试集预测
Y_pred = lr.predict_proba(onehot.transform(gbdt.apply(X_test)[:, :, 0]))[:, 1]
fpr, tpr, _ = roc_curve(Y_test, Y_pred)
auc = roc_auc_score(Y_test, Y_pred)
print('GradientBoosting + LogisticRegression: ', auc)
LogisticRegression: 0.9349156965074267
GradientBoosting + LogisticRegression: 0.9412133681252508
6. XGBoost算法问题总结
基于这三个博客对XGBoost算法中重要的点进行总结
机器学习—XGboost的原理、工程实现与优缺点
机器学习—XGBoost实战与调参
机器学习—XGBoost常见问题解析
6.1 XGBoost算法的原理
Xgboost以CART决策树为子模型,通过Gradient Tree Boosting实现多棵CART树的集成学习,得到最终模型。XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致;XGBoost是一个优化的分布式梯度增强库,旨在实现高效,灵活和便携;XGBoost提供了并行树提升,可以快速准确地解决许多数据科学问题;在工业界大规模数据方面,XGBoost的分布式版本有广泛的可移植性,支持在Hadoop等分布式环境下运行。下面以陈天奇XGBoost论文为框架来讲解,XGBoost论文链接提取码:1234
6.1.1 XGBoost算法预备知识
- 目标函数方面
XGBoost与GBDT一样同样适用了加法模型与前向分布算法,其区别在于,GBDT通过经验风险最小化来确定下一个决策树参数,XGBoost通过结构风险极小化来确定下一个决策树参数 Θ m \Theta_{m} Θm,通俗理解来说,就是XGBoost目标函数中加入了正则项
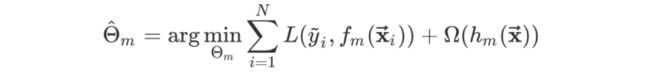
其中 Ω ( h m ( x ) ) \Omega(h_m(x)) Ω(hm(x))为第m颗决策树的正则项,这是XGBoost与GBDT的一个重要区别,其目标函数可写为:
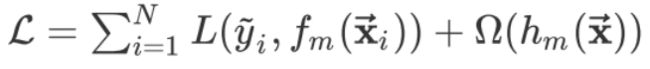
- 泰勒展开式方面
GBDT是泰勒一阶展开式,XGBoost是泰勒二阶展开式

原论文中将 L ( y i ~ , ( ^ y i ) < m − 1 > ) L(\widetilde{y_i},\hat(y_i)^{}) L(yi ,(^yi)<m−1>)合并到constant中,因为真实标签 y i ~ \widetilde{y_i} yi 是已知的,当求第 m m m步时,第 m − 1 m-1 m−1步的预测值也是知道,所以这个值是一个常量。 - 决策树改写
XGBoost与GBDT对决策树进行了改写,两者类似,只不过改写的结果不同

6.1.2 XGBoost算法结构分
首先先明白XGBoost目标函数中的正则项 Ω ( h m ( x ⃗ ) ) \Omega(h_m(\vec{x})) Ω(hm(x))是如何计算的?

然后将正则化项公式代入目标函数(损失函数)中,得到


则损失函数可化简为:
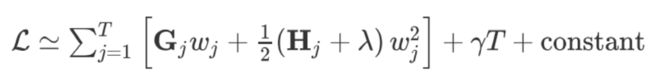
此时假设 w j 和 T 、 G j 、 H j w_j和T、G_j、H_j wj和T、Gj、Hj 都无关的话,那么损失函数实质上是一个关于 w j w_j wj的一元二次方程。根据一元二次方程求极值公式可得:
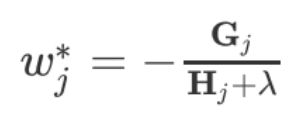
将 w j ∗ w_j^* wj∗代入损失函数得,
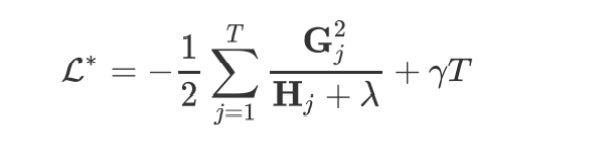
这个就是所谓的结构分
上一步的化简,我们假设 w j 和 T 、 G j 、 H j w_j和T、G_j、H_j wj和T、Gj、Hj都无关, w j w_j wj表示树的叶子节点,所以实质是在假设已知树的结构,而事实上损失函数与 T T T是相关的,甚至和树的结构相关,所以定义 L ∗ L^* L∗为一种
scoring function,来衡量已知树结构情况下目标函数的最小值。
这就把损失函数求极值问题转化成衡量已知树结构情况下损失函数的最小值的问题,那么,我们只要知道了树结构,我们就可以解决这个问题。下面举例:在已知树结构下,如何求目标函数的最小值?
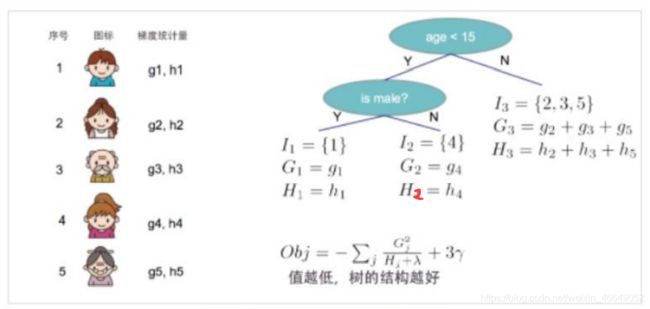
6.1.3 XGBoost算法之贪心算法寻找分裂点
现在的问题是:如何得到最佳的树的结构,来使得目标函数全局最小?我们可以采用贪心算法来寻找最佳树结构使得目标函数全局最小。贪心算法的思想:对现有的叶结点加入一个分裂,然后考虑分裂之后目标函数降低多少,如果目标函数下降,则说明可以分裂,如果目标函数不下降,则说明该叶结点不宜分裂。
贪心算法判断叶结点适不适宜分裂具体过程为:对于叶结点的某个特征,假如给定其分裂点,定义划分到左子结点的样本的集合为: I L = i ∣ q ( x ⃗ i ) = L \Iota_{L}={i|q(\vec{x}_i)=L} IL=i∣q(xi)=L;定义划分到右子结点的样本的集合为: I R = i ∣ q ( x ⃗ i ) = R \Iota_{R}={i|q(\vec{x}_i)=R} IR=i∣q(xi)=R,则右:


上面一段我们已经知道了如何判断某个叶结点适不适宜分裂,但是这是在假设给定其分裂点的前提下。对于每个叶结点来说,存在很多个分裂点,且可能很多分类点都能够带来收益。那么我们应该如何解决呢?解决的办法是:对于叶结点中的所有可能的分裂点排序后进行一次扫描,然后计算每个分裂点的增益,选取增益最大的分裂点作为本叶结点的最优分裂点。
贪心算法寻找分裂点伪代码如下:

贪心算法的缺点为:分裂点贪心算法尝试所有特征和所有分裂位置,从而求得最优分裂点。当样本太大且特征为连续值时,这种暴力做法的计算量太大,计算效率比较低。并且,贪心算法也不容易进行并行运算。不过,我们在平时用到的XGBoost的单线程版本与sklearn版本都是基于贪心算法来寻找分裂点的。接下来,介绍的近似算法正是对贪心算法这一缺点的改进。
6.1.4 XGBoost算法之近似算法和加权分桶
近似算法针对贪心算法计算量大的缺点,用分桶的思想,使得循环的次数减少(贪心算法每一个点都要循环一次,近似算法每一个桶循环一次)。近似算法的思想为:

近似算法寻找分裂点伪代码如下:

近似算法伪代码中提到了两种分桶模式:全局分桶与局部分桶。

分桶时的桶区间间隔大小是个重要的参数。区间间隔越小,则桶越多,则划分的越精细,候选的拆分点就越多。
XGBoost算法中运用的是加权分桶算法。首先,先定义一个排序函数,


我们已经知道了什么是加权分桶?那么我们应该怎么理解加权分桶呢?
损失函数:
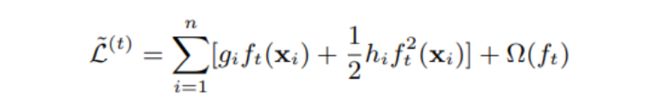
可以改写为:
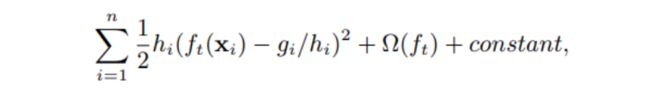
原论文,这里写作减号,我们实际推导下来会发现会是加号,可以这么理解:这里不管是加号还是减号都不会影响函数的最值 4 a c − b 2 4 a \frac{4ac-b^2}{4a} 4a4ac−b2。改写以后,很像平方损失,可以发现对于第 t t t棵决策树而言,它等价于样本 x i x_i xi的真实label为 g i h i \frac{g_i}{h_i} higi,权重为 h i h_i hi,损失函数为平方损失。因此分桶时每个桶的权重为 h h h,所以分桶时使得 h h h更加均匀会使近似算法效果更好一点。
原论文中给出了贪心算法、近似算法全局分桶、近似算法局部分桶的方法比较:
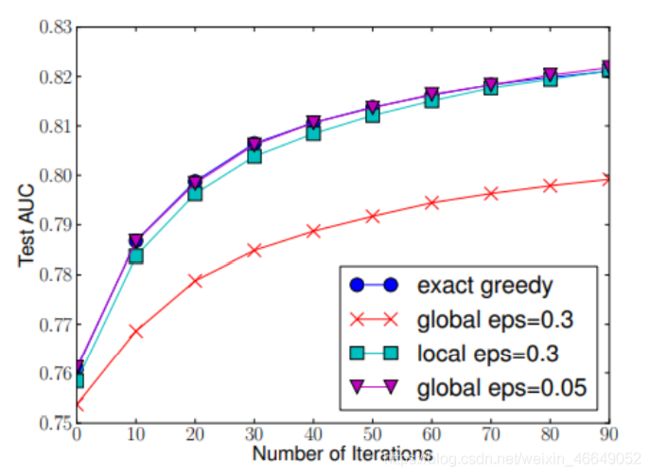
6.1.5 XGBoost算法之缺失值处理
这是一个面试中经常问的问题。
真实场景中,有很多可能导致产生稀疏。如:数据缺失、某个特征上出现很多0项、人工进行one-hot编码导致的大量的0。
- 理论上,数据缺失和数值0的含义是不同的,数值0是有效的。
- 实际上,在xgboost中,数值0的处理方式类似缺失值的处理方式,都视为稀疏特征。
在xgboost中,数值0的处理方式和缺失值的处理方式是统一的。这只是一个计算上的优化,用于加速对稀疏特征的处理速度。 - 对于稀疏特征,只需要对有效值进行处理,无效值则采用默认的分裂方向。
注意:每个结点的默认分裂方向可能不同。 - 在XGBoost算法实现中,允许对数值0做不同的处理。可以将0视作缺失值,也可以将0视作有效值。如果数值0是有真实意义的,则建议将其视作有效值。
我们看输出可以看到返回的是当前叶结点的最佳分裂点,前面也介绍了几个算法来寻找最佳分类点,所以缺失值处理算法并不是一个新的算法,只是在寻找分裂点的算法中加入了一些手段,使算法能够处理缺失值。XGBoost缺失值处理算法如下:



原论文中算法伪代码如下:

6.1.6 XGBoost算法之其他优化
-
预排序—列块并行学习
在树的生成过程中,最耗时的一个步骤是在每次寻找最佳分裂点时都需要对特征的值进行排序。而xgboost在训练之前会根据特征对数据进行排序,然后保存到块结构中,并在每个块结构中都采用了稀疏矩阵存储格式(CSC)进行存储,后面的训练过程中会重复的使用块结构,可以大大减小工作量。

-
缓存访问
列块并行学习的设计可以减少节点分裂时的计算量,在顺序访问特征值时,访问的是一块连续的内存空间,但通过特征值持有的索引(样本索引)访问样本获取一阶、二阶导数时,这个访问操作访问的内存空间并不连续,这样可能造成cpu缓存命中率低,影响算法效率。
为了解决缓存命中率低的问题,XGBoost 提出了缓存访问算法:为每个线程分配一个连续的缓存区,将需要的梯度信息存放在缓冲区中,这样就实现了非连续空间到连续空间的转换,提高了算法效率。此外适当调整块大小,也可以有助于缓存优化。

-
“核外”块计算
当数据量非常大时,我们不能把所有的数据都加载到内存中。那么就必须将一部分需要加载进内存的数据先存放在硬盘中,当需要时再加载进内存。这样操作具有很明显的瓶颈,即硬盘的IO操作速度远远低于内存的处理速度,肯定会存在大量等待硬盘IO操作的情况。针对这个问题作者提出了“核外”计算的优化方法。具体操作为,将数据集分成多个块存放在硬盘中,使用一个独立的线程专门从硬盘读取数据,加载到内存中,这样算法在内存中处理数据就可以和从硬盘读取数据同时进行。此外,XGBoost 还用了两种方法来降低硬盘读写的开销: -
块压缩(Block Compression)。数据按列进行压缩,并且在硬盘到内存的传输过程中自动解压缩。对于行索引,只保存第一个索引值,然后用16位的整数保存与该block第一个索引的差值。作者通过测试在block设置为 2 16 2^{16} 216个样本大小时,压缩比率几乎达到 26 % ∼ 29 % 26\% \sim 29\% 26%∼29%
-
块分区(Block Sharding )。块分区是将特征block分区存放在不同的硬盘上,每个硬盘对应一个预取线程,以此来增加硬盘IO的吞吐量。
6.2 总结GBDT和XGBoost的联系和区别
- GBDT是机器学习算法,XGBoost是该算法的工程实现
- 基分类器
传统的GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器。不仅支持CART决策树,还支持线性分类器。 - 导数信息
XGBoost对损失函数做了二阶泰勒展开,GBDT只用了一阶导数信息,并且XGBoost还支持自定义损失函数,只要损失函数一阶、二阶可导。 - 正则项
GBDT是在决策树构建完成后再进行剪枝,相当于后剪枝;XGBoost的目标函数加了正则项, 相当于预剪枝,使得学习出来的模型更加不容易过拟合。 - 列采样
传统的GBDT在每轮迭代时使用全部的数据,XGBoost则采用了与随机森林相似的策略,支持对数据进行列采样,防止过拟合。 - 缺失值处理
传统的GBDT没有设计对缺失值进行处理,XGBoost能够自动学习出缺失值的处理策略。对树中的每个非叶子结点,XGBoost可以自动学习出它的默认分裂方向。如果某个样本该特征值缺失,会将其划入默认分支。 - 特征维度上的并行—XGBoost预先将每个特征按特征值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大提升训练速度。
6.3 XGBoost为什么使用泰勒二阶展开?
- 精准性:相对于GBDT的一阶泰勒展开,XGBoost 采用二阶泰勒展开,可以更为精准的逼近真实的损失函数
- 可扩展性:损失函数支持自定义,只需要新的损失函数二阶可导。
6.4 XGBoost为什么可以并行训练?
XGB本质上仍然采用boosting 思想,每棵树训练前需要等前面的树训练完成才能开始训练。XGBoost 的并行,并不是tree维度上的并行,而是特征维度上的并行。在训练之前,每个特征按特征值对样本进行预排序,并存储为Block结构,在后面查找特征分割点时可以重复使用,而且特征已经被存储为一个个block结构,那么在寻找每个特征的最佳分割点时,可以利用多线程对每个block 并行计算。
6.5 XGBoost为什么快?
- 分块并行
训练前每个特征按特征值进行排序并存储为Block结构,后面查找特征分割点时重复使用,并且支持并行查找每个特征的分割点 - 候选分位点:每个特征采用常数个分位点作为候选分割点
- 缓存访问
为每个线程分配一个连续的缓存区,将需要的梯度信息存放在缓冲区中 - “核外”块计算
Block预先放入内存; Block按列进行解压缩;将Block划分到不同硬盘,每个硬盘对应一个预取线程,以此来增加硬盘IO的吞吐量。
6.6 XGBoost防止过拟合的方法是什么?
- 目标函数添加正则项:叶子节点个数+叶子节点权重的L2正则化
- 列抽样:训练的时候只用一部分特征(不考虑剩余的block 块即可)
- 子采样:每轮计算可以不使用全部样本,使算法更加保守
early stopping:如果经过固定的迭代次数后,并没有在验证集上改善性能,停止训练过程shrinkage: 可以叫做学习率或步长,调小学习率增加树的数量,为了给后面的训练留出更多的学习空间
6.7 使用XGBoost训练模型时,如果过拟合了怎么调参?
- 控制模型的复杂度。包括
max_depth,min_child_weight,gamma等参数。 - 增加随机性,从而使得模型在训练时对于噪音不敏感。包括
subsample,colsample_bytree。 - 减小
learning rate,但需要同时增加estimator参数。
机器学习—XGBoost实战与调参
6.8 XGBoost 如何处理缺失值?
- 在特征k上寻找最佳 split point 时,不会对该列特征missing 的样本进行遍历,而只对该列特征值为non-missing的样本上对应的特征值进行遍历,通过这个技巧来减少了为稀疏离散特征寻找split point的时间开销。
- 在逻辑实现上,为了保证完备性,会将该特征值 missing的样本分别分配到左叶子结点和右叶子结点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。
- 如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子结点。
6.9 XGBoost如何选择最佳分裂点?
XGBoost在训练前预先将特征按照特征值进行了排序,并存储为block结构,以后在结点分裂时可以重复使用该结构。因此,可以采用特征并行的方法利用多个线程分别计算每个特征的最佳分割点,根据每次分裂后产生的增益,最终选择增益最大的那个特征的特征值作为最佳分裂点。如果在计算每个特征的最佳分割点时,对每个样本都进行遍历,计算复杂度会很大,这种全局扫描的方法并不适用大数据的场景。XGBoost还提供了一种直方图近似算法,对特征排序后仅选择常数个候选分裂位置作为候选分裂点,极大提升了结点分裂时的计算效率。
6.10 XGBoost中如何对树进行剪枝?
- 在目标函数中增加了正则项:使用叶子结点的数目和叶子结点权重的L2模的平方,控制树的复杂度。
- 在结点分裂时,定义了一个阈值,如果分裂后目标函数的增益小于该阈值,则不分裂。
- 当引入一次分裂后,重新计算新生成的左、右两个叶子结点的样本权重和。如果任一个叶子结点的样本权重低于某一个阈值(最小样本权重和),也会放弃此次分裂。
- XGBoost 先从顶到底建立树直到最大深度,再从底到顶反向检查是否有不满足分裂条件的结点,进行剪枝。
6.11 XGBoost的延展性很好,怎么理解?
- 基分类器:弱分类器可以支持CART决策树,也可以支持LR和Linear。
- 目标函数:支持自定义loss function,只需要其二阶可导。因为需要用二阶泰勒展开,得到通用的目标函数形式。
- 学习方法:Block结构支持并行化,支持核外块计算。
6.12 XGBoost的优缺点有哪些?
优点:
- 精度更高
GBDT 只用到一阶泰勒展开,而 XGBoost 对损失函数进行了二阶泰勒展开。XGBoost 引入二阶导一方面是为了增加精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数; - 灵活性更强
GBDT 以 CART 作为基分类器,XGBoost 不仅支持 CART 还支持线性分类器,使用线性分类器的 XGBoost 相当于带 L 1 L1 L1和 L 2 L2 L2 正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题)。此外,XGBoost 工具支持自定义损失函数,只需函数支持一阶和二阶求导; - 正则化
XGBoost 在目标函数中加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、叶子节点权重的 L 2 L2 L2范式。正则项降低了模型的方差,使学习出来的模型更加简单,有助于防止过拟合,这也是XGBoost优于传统GBDT的一个特性。 - Shrinkage(缩减)
相当于学习速率。XGBoost 在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。传统GBDT的实现也有学习速率; - 列抽样
XGBoost 借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算。这也是XGBoost异于传统GBDT的一个特性; - 缺失值处理
对于特征的值有缺失的样本,XGBoost 采用的稀疏感知算法可以自动学习出它的分裂方向; - XGBoost工具支持并行
boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t 次迭代的代价函数里包含了前面 t − 1 t-1 t−1次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道决策树的学习最耗时的一个步骤就是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。 - 可并行的近似算法
树节点在进行分裂时,我们需要计算每个特征的每个分割点对应的增益,即用贪心法枚举所有可能的分割点。当数据无法一次载入内存或者在分布式情况下,贪心算法效率就会变得很低,所以XGBoost还提出了一种可并行的近似算法,用于高效地生成候选的分割点。 - 剪枝
xgboost先从顶到底,建立所有可以建立的子树,再从底到顶进行反向剪枝。比起GBDT,这样不容易陷入局部最优解 - 内置交叉验证
xgboost允许在每一轮boosting迭代中使用交叉验证。因此,我们可以方便的获取最优迭代次数。而GBDT使用网格搜索,只能检测有限个值。
缺点:
- 虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量,但在节点分裂过程中仍需要遍历数据集;
- 预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
6.13 xgboost使用之前是否需要对数据进行归一化处理?
不需要。首先,归一化是对连续特征来说的。那么连续特征的归一化,起到的主要作用是进行数值缩放。数值缩放的目的是解决梯度下降时,等高线是椭圆导致迭代次数增多的问题。而xgboost等树模型是不能进行梯度下降的,因为树模型是阶越的,不可导。树模型是通过寻找特征的最优分裂点来完成优化的。由于归一化不会改变分裂点的位置,因此xgboost不需要进行归一化。
6.14 xgboost使用之前是否需要对类别型特征进行one-hot处理?
xgboost支持离散类别特征进行onehot编码,因为xgboost只支持数值型的特征。但是不提倡对离散值特别多的特征通过one-hot的方式进行处理。因为one-hot进行特征打散的影响,其实是会增加树的深度。针对取值特别多的离散特征,我们可以通过embedding的方式映射成低纬向量。与单热编码相比,实体嵌入不仅减少了内存使用并加速了神经网络,更重要的是通过在嵌入空间中映射彼此接近的相似值,它揭示了分类变量的内在属性。
6.15 XGBoost可以做特征选择,它是如何评价特征重要性的?
XGBoost中有三个参数可以用于评估特征重要性:
- weight :该特征在所有树中被用作分割样本的总次数。
- gain :该特征在其出现过的所有树中产生的平均增益。
- cover:该特征在其出现过的所有树中的平均覆盖范围。覆盖范围这里指的是一个特征用作分割点后,其影响的样本数量,即有多少样本经过该特征分割到两个子节点。
参考:
- [校招-基础算法]GBDT/XGBoost常见问题
- 机器学习—XGBoost常见问题解析
- 陈天奇XGBoost paper
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言!
