自写x86代码变异混淆器及其相关思路
前言
-
作为一个学习/练手的项目,自发写了一个保护x86的exe/dll的变异混淆器(Mutation),类似于CodeVirtualizer的那种(不过CV是VM保护,而且还支持sys)。分别用到了capstone、asmjit和cyxvc大佬的部分库。实现了代码多重变异,代码乱序,jcc指令转换,假分支干扰等功能。
-
相比VMP/TMD的变异保护,强度还可以。但是兼容性比较差,没有考虑程序的异常处理而且没经过大规模测试,可能会有很多bug,仅供参考学习。
-
本文仅分享一下我写Mutation混淆器的一些思路,希望能抛砖引玉。
正文
1.变异的基本思想(扫盲)
代码变异/代码混淆的根本思想都是**“等价替换”。在等价替换的前提下借用寄存器、栈、堆**等来膨胀代码,将1条指令替换成多条指令。
例如以下的mov指令
mov eax,ebx
可以借用ecx寄存器,将其变异成
mov ecx,ebx
mov eax,ecx
但是这样还不行,因为我们破坏了ecx的环境。还必须要先对ecx做一个保存,事后还原它。
push ecx
mov ecx,ebx
mov eax,ecx
pop ecx
这样一个最简单的代码变异就完成了。
2.指令分析处理的思路
要想写出自动化的变异工具,第一步就要先对目标指令进行逐步地拆解分析。
除了少部分没有Operand的指令(syscall等等),大部分指令都可以分为助记符(OP)+Operand的形式。即我们先在助记符这个方向上初步区分出指令来,再在此基础上从Operand的方向进一步拆分出指令的具体类型。
2.1先以助记符拆分
mov eax,ebx
以上面mov指令为例,我们借用capstone反汇编引擎,解析出这条指令的类别为“mov”。
//判断是不是mov指令
if (strcmp(insn.mnemonic, "mov") == 0)
return(_mov());
add eax,ebx
同理以add指令为例,也需先解析出他的指令类别为“add”
//判断是不是add指令
if (strcmp(insn.mnemonic, "add") == 0)
return(_add());
以此初步地区分出目标指令为mov指令还是add指令或是其他的指令类别。
2.2再以Operand拆分
Operand又分为3种情况,分别为:
reg(寄存器),imm(立即数,常数),mem(内存)。
以上文解析出的mov指令为例,搭配这3种Operand的组合,又可进一步分出5种指令类型:
mov reg,reg
mov reg,imm
mov reg,mem
mov mem,reg
mov mem,imm
我们只要针对这5种指令类型写混淆规则,就可以将x86mov指令的所有情况包括进来。
当然,Operand其实还可以再往下分:根据Operand的位数又可以继续分出8位、16位、32位、(64位)。
如果想针对性地写的更细一点,可以选择再分一次。
以下是判断Operand类型的代码
//mov reg,reg
if (x86->operands[0].type == X86_OP_REG && x86->operands[1].type == X86_OP_REG)
return(_mov_reg_reg(x86->operands[0].reg, x86->operands[1].reg));
//mov reg,imm
if (x86->operands[0].type == X86_OP_REG && x86->operands[1].type == X86_OP_IMM) {
imm.address = (DWORD)insn.address;
imm.imm_value = (DWORD)x86->operands[1].imm;
imm.imm_offset = x86->encoding.imm_offset;
imm.imm_size = x86->encoding.imm_size;
return(_mov_reg_imm(x86->operands[0].reg, &imm));
}
//mov_reg_mem
if (x86->operands[0].type == X86_OP_REG && x86->operands[1].type == X86_OP_MEM) {
mem.address = (DWORD)insn.address;
mem.disp_offset = x86->encoding.disp_offset;
mem.disp_size = x86->encoding.disp_size;
mem.base = x86->operands[1].mem.base;
mem.index = x86->operands[1].mem.index;
mem.scale = x86->operands[1].mem.scale;
mem.disp = x86->operands[1].mem.disp;
mem.mem_size = x86->operands[1].size;
return(_mov_reg_mem(x86->operands[0].reg, &mem));
}
//mov_mem_reg
if (x86->operands[0].type == X86_OP_MEM && x86->operands[1].type == X86_OP_REG) {
mem.address = (DWORD)insn.address;
mem.disp_offset = x86->encoding.disp_offset;
mem.disp_size = x86->encoding.disp_size;
mem.base = x86->operands[0].mem.base;
mem.index = x86->operands[0].mem.index;
mem.scale = x86->operands[0].mem.scale;
mem.disp = x86->operands[0].mem.disp;
mem.mem_size = x86->operands[0].size;
return(_mov_mem_reg(&mem, x86->operands[1].reg));
}
//mov_mem_imm
if (x86->operands[0].type == X86_OP_MEM && x86->operands[1].type == X86_OP_IMM) {
mem.address = (DWORD)insn.address;
mem.disp_offset = x86->encoding.disp_offset;
mem.disp_size = x86->encoding.disp_size;
mem.base = x86->operands[0].mem.base;
mem.index = x86->operands[0].mem.index;
mem.scale = x86->operands[0].mem.scale;
mem.disp = x86->operands[0].mem.disp;
mem.mem_size = x86->operands[0].size;
imm.address = (DWORD)insn.address;
imm.imm_value = (DWORD)x86->operands[1].imm;
imm.imm_offset = x86->encoding.imm_offset;
imm.imm_size = x86->encoding.imm_size;
return(_mov_mem_imm(&mem, &imm));
}
具体的混淆规则可以用asmjit自由发挥,只要注意让生成的变异代码每次所借用的寄存器不同即可,不要生成的代码完全一模一样。
贴一下我的mov reg,reg混淆规则写法
UINT x86Insn_Mutation::_mov_reg_reg(x86_reg op0, x86_reg op1)
{
//JitRuntime rt;
//CodeHolder code;
//Mut_Code.init(rt.codeInfo());
x86::Assembler a(&Mut_Code);
if (Check_Reg(op0) == false || Check_Reg(op1) == false)
throw "传入的reg错误";
x86_reg regs[] = { X86_REG_EAX, X86_REG_EBX, X86_REG_ECX, X86_REG_EDX, X86_REG_EBP, X86_REG_ESP, X86_REG_ESI, X86_REG_EDI };
x86_reg randreg0, randreg1;
do {
randreg0 = regs[rand() % (sizeof(regs) / sizeof(regs[0]))];
//只有eax,ebx,ecx,edx有8位寄存器
} while (
randreg0 == op0 ||
randreg0 == op1 ||
randreg0 == X86_REG_EBP ||
randreg0 == X86_REG_ESP ||
randreg0 == X86_REG_ESI ||
randreg0 == X86_REG_EDI);
do {
randreg1 = regs[rand() % (sizeof(regs) / sizeof(regs[0]))];
} while (
randreg1 == randreg0 ||
randreg1 == op0 ||
randreg1 == op1 ||
randreg1 == X86_REG_EBP ||
randreg1 == X86_REG_ESP ||
randreg1 == X86_REG_ESI ||
randreg1 == X86_REG_EDI);
auto rand0 = to_asmjit_reg(randreg0);
auto rand1 = to_asmjit_reg(randreg1);
auto reg_op0 = to_asmjit_reg(op0);
auto reg_op1 = to_asmjit_reg(op1);
a.pushfd();
a.push(rand1);
a.mov(rand1, reg_op1);
a.push(rand0);
a.mov(rand0, reg_op0);
a.bswap(rand1);
a.mov(rand0, rand1);
a.xchg(Low_reg(randreg0, al), Low_reg(randreg0, ah));
a.rcl(rand0, 0x10);
a.rcr(rand1, 0x10);
a.xor_(Low_reg(randreg0, ax), Low_reg(randreg1, ax));
a.push(Low_reg(randreg0, ax));
a.xor_(Low_reg(randreg1, ax), Low_reg(randreg0, ax));
a.pop(Low_reg(randreg0, ax));
a.xor_(Low_reg(randreg0, ax), Low_reg(randreg1, ax));
a.mov(Low_reg(randreg1, al), Low_reg(randreg0, ah));
a.mov(Low_reg(randreg1, ah), Low_reg(randreg0, al));
a.xor_(Low_reg(randreg0, ax), Low_reg(randreg0, ax));
a.add(Low_reg(randreg0, ax), Low_reg(randreg1, ax));
a.pop(reg_op0);
a.xchg(reg_op0, rand0);
a.pop(rand1);
a.popfd();
//rt.release(fn);
return mov_reg_reg;
}
3.未知指令及其重定位处理
我们写个小玩具只需要针对编译器最常用的几十种指令写规则即可,没必要对全部的x86指令都去写混淆规则。所以自然就会有大量的指令不在混淆规则内。
不在混淆规则内的指令,我们直接把它copy过去即可
memcpy_s((void*)SingMut_Sec.Mut_CodeStartAddr, insn.size, (void*)insn.address, insn.size);
但是要注意检查未知指令的imm Operand和mem Operand的偏移数(disp)是否需要重定位。以这2个指令为例
mov eax,0x12345678
mov eax,[ebx+0x12345678]
第一个指令就有一个32位的imm Operand,第二个指令的mem Operand里也有一个32位的偏移数(disp)。这2个指令就要查重定位表去检查他们的Operand是否需要重定位处理。
而如果像以下这2个指令:imm或者偏移数(disp)不为32位,就没必要再去检查他们是否需要重定位了。
mov ax,word[bx+0x1]
mov ax,0x1234
//如果该指令的mem的disp_size为4,可能有重定位
if (mem.disp_size == 4) {
DealWithReloc((DWORD)insn.address + mem.disp_offset, SingMut_Sec.BaseAddr + mem.disp_offset);
}
//如果imm的size为4,可能有重定位
if (imm.imm_size == 4) {
DealWithReloc((DWORD)insn.address + imm.imm_offset, SingMut_Sec.BaseAddr + imm.imm_offset);
}
3.1用shellcode处理重定位
上面这种直接加进重定位表的方法是我后来针对未知指令用的。对于在混淆规则内的指令,我处理重定位都是用shellcode里用的方法:
简化代码:
0x401000 call 0x401005
0x401005 sub dword[esp],0x1005
0x40100c pop eax
这种方法安全性比直接加进重定位表要更高,一来不会因为重定位数据而显示出来,二来可以更好地针对被重定位的指令做混淆。但是兼容性会更差/写的难度会变大。它的代码所处的地址不能乱动,如果被改动了,就要重新修复里面的偏移数据(例如上面第二条代码的0x1005)。
如果你是只管生成一次混淆代码,那写起来还算方便。如果要对第一次生成的混淆代码再做一次混淆,那就还要专门处理这些重定位代码。
4.跳转指令的处理
处理跳转指令可能是写混淆器最费脑子的事情,我以3种类型的jmp指令为例说一下我的写法(或许其他大佬也有更好的写法)。
4.1 Jmp Reg
Jmp Reg其实就是以下这几种根据Reg值跳转的。
jmp eax
jmp ebx
jmp ecx
...
这种指令由于reg的不确定性,对指令本身做不了什么变异,可以选择直接“照搬”过去。当然,还可以自己在指令的前面和后面加多分支干扰来加大保护强度
4.2 Jmp Mem
Jmp Mem有以下几种类型:
jmp [eax]
jmp [eax+ebx*1]
jmp [eax+ebx*2+0x12345678]
jmp [0x12345678]
jmp [eax+0x12345678]
这种类型的指令相比上一种类型,存在着更多种不同的情况。我们可以自己写变异代码将Mem的最终地址算出来(注意要检查处理disp的重定位),再读出地址中的数据,用push+ret的组合跳转过去。这里为了稳定性尽量不要用jmp reg跳转的方式,会损失一个寄存器。
贴一下我的部分代码:
a.pushfd();
a.push(rand0);
a.push(rand1);
a.mov(rand0, 0);
//如果imm偏移不为0
if (disp != 0) {
UINT temp = 0;
bool Re_flag = RelocData_imm_mem(address + disp_offset, rand0, &temp);
//如果中间调用的其他函数也用了x86::Assembler,之后就要重新声明一个x86::Assembler来用
x86::Assembler b(&Mut_Code);
//判断是否需要重定位
if (Re_flag)
b.add(rand0, temp);
else
b.add(rand0, (UINT)disp);
}
x86::Assembler b(&Mut_Code);
//如果base不为空
if (base != X86_REG_INVALID) {
b.add(rand0, to_asmjit_reg(base));
}
//如果index寄存器不为空,add过来
if (index != X86_REG_INVALID) {
while (scale--)
b.add(rand0, to_asmjit_reg(index));
}
b.push(rand1); //开一个空间
b.mov(rand1, ptr(x86::esp, 4));
b.mov(ptr(x86::esp), rand1);
b.mov(rand1, ptr(x86::esp, 8));
b.mov(ptr(x86::esp, 4), rand1);
b.mov(rand1, ptr(x86::esp, 12));
b.mov(ptr(x86::esp, 8), rand1);
b.mov(ptr(x86::esp, 12), rand0); //写入jmp目标地址
b.pop(rand1);
b.pop(rand0);
b.popfd();
b.ret();
4.3 Jmp Imm
Jmp Imm在指令上就下面这一个类型,不同于Jmp Reg和Jmp Mem,它的跳转目标地址是可以即时确定的,也不需要考虑重定位的情况。但它却是最难处理的。下面我们来一步步划分情况
jmp 0x12345678
1.先按照“目标跳转地址是否在保护范围内”划分:
以下面代码为例
0x401000 xor eax,eax
0x401002 ret
//变异保护开始
0x401003 jmp 0x401000
0x401005 jmp 0x402000
//变异保护结束
...
...
...
//变异保护开始
0x402000 xor eax,eax
0x402002 ret
//变异保护结束
其中0x401003的的jmp跳向0x401000,而0x401000这段代码不在保护范围内。所以该指令的目标跳转地址不在保护范围内。
而0x401005的jmp跳向0x402000,这段代码在保护范围内,尽管他们不在同一段保护范围内,我们也依然认为该指令跳向了保护范围内的代码。
2.如果目标地址不在保护范围内:
我们可以直接照搬该指令,或者改用push+ret的方式,或者改用其他的混淆方法。不管如何,我们只要在保证寄存器、堆栈环境不被破坏的前提下能正常跳转到目的地即可。
//判断目标跳转地址是不是在Mutation保护标志范围内
for (auto iter = Mut_Mark.begin(); iter != Mut_Mark.end(); iter++) {
//在保护范围
if (Target_JumpAddr >= (DWORD)iter->Protected_Start && Target_JumpAddr <= (DWORD)iter->Protected_End) {
flag = true;
break;
}
}
//目标跳转地址不在保护范围内
if (flag == false)
{
a.jmp(Jcc_ActuAddr(Target_JumpAddr));
}
3.如果目标地址在保护范围内:
此时原目标地址的代码已经被我们保护了,原地址已经是完全作废了,不能再直截了当地跳转过去,而是要跳转到该代码所对应的混淆代码。
所以我们要继续判断“对目标地址的代码是否已经生成了混淆代码”:
如果已经生成,那我们可以直接跳转过去。
如果没有生成,那我们等待后续目标混淆代码出现了再跳转过去。
这里说一下我的老的实现思路,以及后面针对性地改进后的思路:
每次针对一个指令生成混淆代码时,我都用struct保存他们的信息,并装进vector里。
//对单行指令生成的变异代码段
typedef struct _Single_MutCode
{
//原指令地址
DWORD Raw_CodeAddr;
//变异代码块起始地址
DWORD Mut_CodeStartAddr;
//变异代码块偏移地址
DWORD Mut_CodeOffsetAddr;
//变异代码块大小
size_t Mut_CodeSize;
//变异代码块尾部(下一个变异代码块的起始处)
DWORD Mut_CodeEndAddr;
//重定位基地址
DWORD BaseAddr;
} Single_MutCode, *PSingle_MutCode;
待到jcc指令时就可以遍历vector里每一个struct的信息,如果找到了目标跳转地址的变异代码段,那我们直接跳过去就是了(混淆什么的另说)。
//2.1判断是否已经生成目标地址
bool flag_2 = false;
for (auto iter = SingMut.begin(); iter != SingMut.end(); iter++) {
//已经生成,修改目标跳转地址
if (Target_JumpAddr == iter->Raw_CodeAddr) {
flag_2 = true;
Target_JumpAddr = iter->BaseAddr;
break;
}
}
如果没有找到,就说明还没有生成混淆代码。那我们就只能等待后续保护到这个代码时,才能确定他的地址(在asmjit上暂时只能这样做。如果是用纯汇编写混淆规则,或许可以写个函数直接计算一下后续混淆代码的size,然后直接跳转过去)。
具体如何实现?我的办法是先提前写好一个jmp unknown(jmp 0xFFFFFFFF),并把jmp unknown的相关信息写进一个vector里面。同时在每次生成变异代码之前都对这个vector做一个遍历检查,看看有没有哪些jmp unknown跳转到了我要保护的指令,我们把他们修改成正确的跳转。
以下是对一个指令保护的流程代码:
//1.变异前先判断 该代码地址是否为jmp的目标跳转地址
Fix_JmpOffset();
Mut_Code.init(CodeInfo(ArchInfo::kIdHost));
//1.分析指令类型,生成变异代码
result = Analyze_InsnType();
//遇上不能变异的指令,直接copy过去
if (result == -1)
{
Resolve_UnknownInsn();
return -1;
}
//2.将单行指令的变异代码重定位后写到Final空间,并填写CodeSection结构体
Copy_MutCodes_to_FinalMem();
//3.清除这次存入CodeHolder的代码
Mut_Code.reset();
以下是对jmp unknown_vector的检查函数
UINT x86Insn_Mutation::Fix_JmpOffset()
{
UINT result = 0;
DWORD jcc_offset = 0;
DWORD jcc_addr = 0;
uint8_t imm_offset = 0;
//从vector中遍历 并判断 是否有jmp跳转到了当前指令地址
for (auto &c : Fix_Offset) {
if (c.Target_JumpAddr == insn.address) {
result = 1;
jcc_addr = c.address;
imm_offset = c.imm_offset;
//让jmp重定位跳向 当前指令的变异代码的地址
//公式: jcc_addr + imm_offset + imm_size + jcc_offset = target_addr(SingMut_Sec.Mut_CodeStartAddr)
jcc_offset = SingMut_Sec.Mut_CodeStartAddr - imm_offset - 4 - jcc_addr;
//写入jmp的offset
memcpy_s((void*)(jcc_addr + imm_offset), 4, &jcc_offset, 4);
}
}
return result;
}
后来发现有些地方可以改进效率:
第一个是每次保护代码都要对jmp unknown_vector做一次遍历检查。当保护代码达到数万至数十万行时(由于我写的是二次变异+乱序,这种情况很常见)时间消耗非常恐怖。所以我从vector改用了map,以jcc的目标跳转地址为key进行查找
UINT x86Insn_Mutation::Fix_JmpOffset()
{
UINT result = 0;
DWORD jcc_offset = 0;
DWORD jcc_addr = 0;
uint8_t imm_offset = 0;
//以当前指令地址为key,从map中查找是否有jcc/jmp需要跳转到当前指令地址
auto search = Fix_Offset.find(insn.address);
if (search != Fix_Offset.end()) {
result = 1;
for (auto& c : search->second) {
jcc_addr = c.address;
imm_offset = c.imm_offset;
//公式: jcc_addr + imm_offset + imm_size + jcc_offset = target_addr(SingMut_Sec.Mut_CodeStartAddr)
jcc_offset = SingMut_Sec.Mut_CodeStartAddr - imm_offset - 4 - jcc_addr;
//写入jcc/jmp的offset
memcpy_s((void*)(jcc_addr + imm_offset), 4, &jcc_offset, 4);
}
}
return result;
}
第二个是我发现我的加密写法是单线程从上往下线性加密的。所以当一个jcc指令的目标跳转地址在保护范围内时,我们可以先判断他是“向上跳”还是“向下跳”或者是”跳向自己“,而不是直接浪费时间遍历vector。
如果是“向上跳”:此时目标地址的混淆代码肯定已经生成了,我们直接从vector里取出来他的地址。
如果是“跳向自己”:我们直接照搬即可。
如果是“向下跳”:此时目标地址的混淆代码肯定还没生成,我们以目标地址为key写进map < DWORD, vector>里。
相关代码:
UINT rand_order::_jmp_imm(x86_jcc* jcc0)
{
#define jcc jmp
DWORD address = jcc0->address;
uint8_t imm_offset = jcc0->imm_offset;
uint8_t imm_size = jcc0->imm_size;
DWORD Target_JumpAddr = jcc0->Target_JumpAddr;
x86::Assembler a(&Mut_Code);
bool flag = false;
//取出jcc的offset地址和offset
DWORD offset_Addr = address + imm_offset;
DWORD offset = 0;
memcpy_s(&offset, imm_size, (void*)offset_Addr, imm_size);
//判断目标跳转地址是不是在Mutation保护标志范围内
for (auto iter = Mut_Mark.begin(); iter != Mut_Mark.end(); iter++) {
//在保护范围
if (Target_JumpAddr >= (DWORD)iter->Protected_Start && Target_JumpAddr <= (DWORD)iter->Protected_End) {
flag = true;
break;
}
}
//目标跳转地址不在保护范围内
if (flag == false)
{
//*这里要根据每个jcc指令修改,
a.jcc(Jcc_ActuAddr(Target_JumpAddr));
}
CodeBuffer& buffer = Mut_Code.sectionById(0)->buffer();
//目标跳转地址在保护范围内
if (flag == true)
{
//----------------------------------------------------------------------------------------------------------------
//2.1判断3种情况
//向上跳(此时目标地址的变异代码已经生成)
if (Target_JumpAddr < insn.address)
{
for (auto iter = SingMut.begin(); iter != SingMut.end(); iter++) {
//已经生成,修改目标跳转地址
if (Target_JumpAddr == iter->Raw_CodeAddr) {
Target_JumpAddr = iter->BaseAddr;
break;
}
}
a.jcc(Target_JumpAddr);
}
//向自己跳(直接当做未知指令,留给后续函数copy过去)
if (Target_JumpAddr == insn.address)
{
return -1;
}
//向下跳(此时目标地址的变异代码还没生成)
if (Target_JumpAddr > insn.address)
{
a.jcc(Unknown_Address);
size_t Temp_CodeSize = Mut_Code.codeSize();
//将当前jcc信息写入vector,在Target_JumpAddr地址的指令变异前会对jcc_offset修复
FixOffset FO_Struct = { 0 };
FO_Struct.address = SingMut_Sec.Mut_CodeStartAddr + Temp_CodeSize - 5;
FO_Struct.Target_JumpAddr = Target_JumpAddr;
FO_Struct.imm_offset = 1;
Fix_Offset[Target_JumpAddr].push_back(FO_Struct);
}
}
return jmp_imm;
#undef jcc
}
4.4对jcc的转换
最后再稍微提一下我对jcc做的一点保护:把所有jcc全部转成jns/jnp。
具体操作就是将当前jcc指令所用到的eflag通过左移/右移,移动到SF/PF标志位,然后用jns/jnp触发跳转到一个用来“善后”的jmp分支,jmp分支恢复完环境就跳转到真实的目的地。
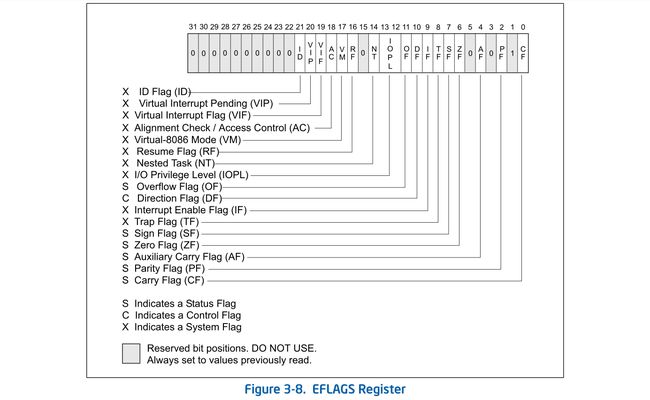
je指令相关代码:
//随机选jns,jnp
if (rand() & 1) {
a.push(rand0);
a.rcr(rand0, eflag_offset); //ZF标志位移到CF
a.xor_(rand0, 1); //je转换到jns
a.rcl(rand0, 7); //从CF移7位到SF
a.and_(rand0, 0xEFF); //将TF变成0,避免误开启调试模式导致崩溃 0xEFF=1110 1111 1111
a.push(rand0);
a.popfd();
a.pop(rand0);
a.jns(Jump_Success); //跳转成功走Jump_Success
}
else {
a.push(rand0);
a.rcr(rand0, eflag_offset); //ZF标志位移到CF
a.xor_(rand0, 1); //je转换到jnp
a.rcl(rand0, 2); //从CF移2位到PF
a.and_(rand0, 0xEFF); //将TF变成0,避免误开启调试模式导致崩溃 0xEFF=1110 1111 1111
a.push(rand0);
a.popfd();
a.pop(rand0);
a.jnp(Jump_Success); //跳转成功走Jump_Success
}
源码:
https://github.com/Lixinist/Mutation
https://wwx.lanzoux.com/inj2Okcreng