Java集合类简介
Java集合类主要由两个接口派生而出: Collection 和 Map 。Java集合大致可以分为Set、List、Queue和Map四种体系。其继承树关系如图:
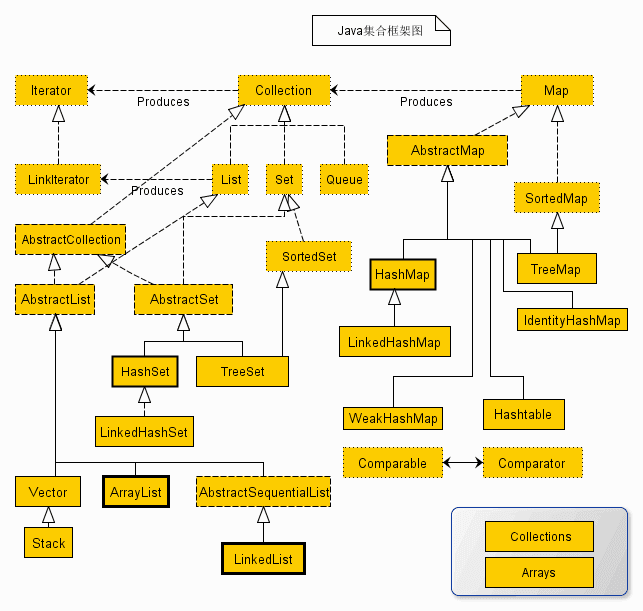
上述类图中,实线边框的是实现类,比如ArrayList,LinkedList,HashMap等,折线边框的是抽象类,比如AbstractCollection,AbstractList,AbstractMap等,而点线边框的是接口,比如Collection,Iterator,List等。各体系集合的特点概述如下:
- Set体系集合:代表无序、不可重复的集合;
- List体系集合:代表有序、重复的集合;
- Map体系集合:代表具有映射关系的集合;
- Queue体系集合,代表一种队列集合实现。(Java 5 增加)
Java集合和数组的区别
1、数组长度在初始化时指定,意味着只能保存定长的数据。而集合可以保存数量不确定的数据。同时可以保存具有映射关系的数据(即关联数组,键值对 key-value)。
2、数组元素即可以是基本类型的值,也可以是对象。集合里只能保存对象(实际上只是保存对象的引用变量),基本数据类型的变量要转换成对应的包装类才能放入集合类中。Java 5 增加泛型以后还可以记住容器中对象的数据类型。
集合的遍历
通用方式
Iterator it = list.iterator();
while(it.hasNext()) {
Object obj = it.next();
}
Map遍历方式
1、通过获取所有的key按照key来遍历
//Set set = map.keySet(); //得到所有key的集合
for (Integer in : map.keySet()) {
String str = map.get(in);//得到每个key多对用value的值
}
2、通过Map.entrySet使用iterator遍历key和value
Iterator> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
3、通过Map.entrySet遍历key和value,推荐,尤其是容量大时
for (Map.Entry entry : map.entrySet()) {
//Map.entry 映射项(键-值对) 有几个方法:用上面的名字entry
//entry.getKey() ;entry.getValue(); entry.setValue();
//map.entrySet() 返回此映射中包含的映射关系的 Set视图。
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
4、通过Map.values()遍历所有的value,但不能遍历key
for (String v : map.values()) {
System.out.println("value= " + v);
}
List遍历方式
第一种:
Iterator iterator = list.iterator();
for(iterator.hasNext();){
int i = (Integer) iterator.next();
System.out.println(i);
}
第二种:
Iterator iterator = list.iterator();
while(iterator.hasNext()){
int i = (Integer) iterator.next();
System.out.println(i);
}
第三种:
for (Object object : list) {
System.out.println(object);
}
第四种:
for(int i = 0 ;i数据元素是怎样在内存中存放的?
主要有2种存储方式:
1、顺序存储,Random Access(Direct Access):
这种方式,相邻的数据元素存放于相邻的内存地址中,整块内存地址是连续的。可以根据元素的位置直接计算出内存地址,直接进行读取。读取一个特定位置元素的平均时间复杂度为O(1)。正常来说,只有基于数组实现的集合,才有这种特性。Java中以ArrayList为代表。
2、链式存储,Sequential Access:
这种方式,每一个数据元素,在内存中都不要求处于相邻的位置,每个数据元素包含它下一个元素的内存地址。不可以根据元素的位置直接计算出内存地址,只能按顺序读取元素。读取一个特定位置元素的平均时间复杂度为O(n)。主要以链表为代表。Java中以LinkedList为代表。
每个遍历方法的实现原理是什么?
1、传统的for循环遍历,基于计数器的:
遍历者自己在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后,停止。主要就是需要按元素的位置来读取元素。
2、迭代器遍历,Iterator:
每一个具体实现的数据集合,一般都需要提供相应的Iterator。相比于传统for循环,Iterator取缔了显式的遍历计数器。所以基于顺序存储集合的Iterator可以直接按位置访问数据。而基于链式存储集合的Iterator,正常的实现,都是需要保存当前遍历的位置。然后根据当前位置来向前或者向后移动指针。
3、foreach循环遍历:
根据反编译的字节码可以发现,foreach内部也是采用了Iterator的方式实现,只不过Java编译器帮我们生成了这些代码。
各遍历方式的适用于什么场合?
1、传统的for循环遍历,基于计数器的:
顺序存储:读取特定元素平均时间复杂度是O(1),遍历则只需平均时间复杂度是O(n)。因此读取性能比较高。适用于遍历顺序存储集合。
链式存储:查找特定元素平均时间复杂度是O(n),遍历则只需平均时间复杂度是O(n^2)。因此时间复杂度太大,不适用于遍历链式存储的集合。
2、迭代器遍历,Iterator:
顺序存储:增加了额外的操作,额外的运作时间,没有太大的意义。若想要代码更加简洁,可以使用。
链式存储:因为Iterator内部维护了当前遍历的位置,使查找特定元素(移动指针指向下一个)的平均时间复杂度降为O(n),即总遍历的平均时间复杂度降为O(n)。因此所以推荐此种遍历方式。
3、foreach循环遍历:
foreach能使代码更加简洁了,但是它有一些缺点,就是遍历过程中不能操作数据集合(删除等),所以有些场合不使用。其本身就是基于Iterator实现的,由于类型转换的问题,所以会比直接使用Iterator慢一点,但是还好,时间复杂度都是一样的。
Java的最佳实践是什么?
Java数据集合框架中,提供了一个RandomAccess接口,该接口没有方法,只是一个标记。通常被List接口的实现使用,用来标记该List的实现是否支持Random Access。
一个数据集合实现了该接口,就意味着它支持Random Access,按位置读取元素的平均时间复杂度为O(1)。比如ArrayList。
而没有实现该接口的,就表示不支持Random Access。比如LinkedList。
所以看来JDK开发者也是注意到这个问题的,那么推荐的做法就是,如果想要遍历一个List,那么先判断是否支持Random Access,也就是 list instanceof RandomAccess。
比如:
if (list instanceof RandomAccess) {
//顺序存储结构,使用传统的for循环遍历。
} else {
//非顺序存储结构,使用Iterator或者foreach。
}
参考文章:https://www.cnblogs.com/leskang/p/6031282.html