动态网页 —— 逆向分析法 + 案例
引入 : 本章主要讲解的是动态网页爬取的相关技术。动态网页的爬取呢,主要有逆向分析法和模拟法。我们今天主要介绍逆向分析法,后面会重点介绍模拟法中selenium库的使用。

动态网页
一、动态网页概述
1.1 什么是动态网页
动态网页是基本的html语法规范与Python、Java、C#等高级程序设计语言、数据库编程等多种技术的融合,以期实现对网站内容和风格的高效、动态和交互式的管理。因此,从这个意义上来讲,凡是结合了HTML以外的高级程序设计语言和数据库技术进行的网页编程技术生成的网页都是动态网页。

这是在网上搜到的定义 ,那么通俗一点的说法是什么呢 ?就是 你要找的东西在网页源代码可能是不会出现的。
1.2 动态网页的常用技术
动态网页经常Ajax、动态HTML等相关技术实现前后台数据的交互。对于传统的Web应用,当我们提交一个表单请求给服务器,服务器接收到请求之后,返回一个新的页面给浏览器,这种方式不仅浪费网络带宽,还会极大地影响用户体验,因为原网页和发送请求后获得的新页面两者中大部分的HTML内容是相同的,而且每次用户的交互都需要向服务器发送请求,并且刷新整个网页。这种问题的存在催生出了Ajax技术。
Ajax的全称是Asynchronous JavaScript and
XML,中文名称为异步的JavaScript和XML,是JavaScript异步加载技术、XML以及Dom,还有表现技术XHTML和CSS等技术的组合。使用
Ajax技术不必刷新整个页面,只需对页面的局部进行更新,Ajax只取回一些必需的数据,它使用SOAP、XML或者支持JSON的Web
Service接口,我们在客户端利用JavaScript处理来自服务器的响应,这样客户端和服务器之间的数据交互就减少了,访问速度和用户体验都得到了提升。如注册邮箱时使用的用户名唯一性验证普遍采用的就是Ajax技术,服务端返回的数据格式通常为json或xml,而不是HTML格式。
1.3 动态网页的判定方法
静态网页 :
静态网页是以.html、.htm、.html、.shtml、.xml作为后缀的网页。静态网页的内容是固定的,每个页面都是独立的页面不会根据浏览者的不同需求而改变。
动态网页 :
使用ASP 或PHP 或 JSP 等作为后缀的网页。动态网页以数据库技术为基础,可以大大降低网站维护的工作量。
判定方法:
1.右键查看网页源代码,如果数据在网页中即说明是静态网页,否则是动态网页。
2.也可使用Request.get()爬取,返回r.text。如果数据全部在文本里则是静态网页,否则是动态网页或者动态和静态结合的网页,部分数据在网页里,部分数据不在网页上。
1.4 动态网页的爬取方法
动态网页的爬取方法一般分为逆向分析法和模拟法。逆向分析法难度较高,通过拦截网站发送的请求,找出真正的请求地址,要求爬虫爱好者熟悉前端特别是JavaScript相关技术。模拟法是使用第三方库如Selenium模拟浏览器的行为,解决页面加载和渲染的问题。
二、案例
案例网址 :重庆名医堂
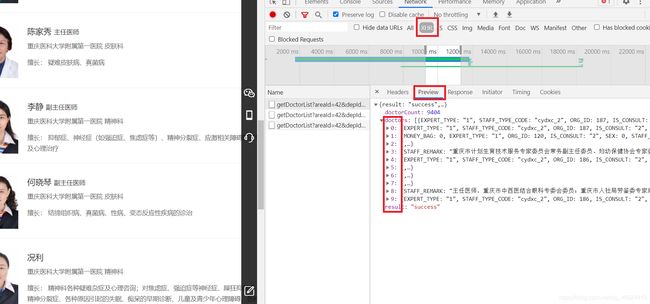
还是原来的操作 ,f12 查看源代码,注意圈红,这次式XHR ,具体情况要具体分析。
观察! 格式式json格式!这里我们在解析的时候要转换成字典很好用!
import requests
import json
import pymysql
import time
def get_html(url,headers,time=10): #get请求通用函数,去掉了user-agent简化代码
try:
r = requests.get(url, headers=headers,timeout=time) # 发送请求
r.encoding = r.apparent_encoding # 设置返回内容的字符集编码
r.raise_for_status() # 返回的状态码不等于200抛出异常
return r.text # 返回网页的文本内容
except Exception as error:
print(error)
out_list=[]
def parser(json_txt):
txt = json.loads(json_txt)
global row_count
row_count=txt["doctorCount"] #总行数
for row in txt["doctors"]: #医生信息列表
staff_name=row.get("STAFF_NAME") #医生姓名
if staff_name is None:
staff_name=""
staff_type=row.get("STAFF_TYPE") #职称
if staff_type is None:
staff_type=""
remark=row.get("STAFF_REMARK") #简介
if remark is None:
remark=""
#简单清洗,去除掉简介中的html标签
remark=remark.replace(""
,"").replace("","")
#去除空白字符
remark=remark.strip()
org_name=row.get("ORG_NAME") #所属医院
org_name=org_name if org_name is not None else ""
org_grade_name=row.get("ORG_GRADE_NAME")#医院等级
org_grade_name = org_grade_name if org_grade_name is not None else ""
good_at=row.get("GOOT_AT") #擅长领域
good_at= good_at if good_at is not None else ""
row_list=(
staff_name,
staff_type,
remark,
org_name,
org_grade_name,
good_at
)
out_list.append(row_list)
def save_mysql(sql, val, **dbinfo): #通用数据存储mysql函数
try:
connect = pymysql.connect(**dbinfo) # 创建数据库链接
cursor = connect.cursor() # 获取游标对象
cursor.executemany(sql, val) # 执行多条SQL
connect.commit() # 事务提交
except Exception as err:
connect.rollback() # 事务回滚
print(err)
finally:
cursor.close()
connect.close()
if __name__ == '__main__':
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64)\
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/89.0.4389.82 Safari/537.36"
} #设置用户代理,应对简单反爬虫
#为了得到总共数据条数,先爬一次得到row_count放入全局变量
page_size=10 #每页的数据行数
url='https://www.jkwin.com.cn/yst_web/doctor/getDoctorList?areaId=42&depId=&hasDuty=&pageNo=1&pageSize=10'
json_txt=get_html(url,head) #发送请求
print(json_txt) #查看是否有数据
parser(json_txt) #解析函数
print(out_list) #查看是否有数据
page=row_count//page_size #总共页数 页面太多速度太慢,以5页列,6改为page即可爬所有页面
for i in range(2,6):
url="https://www.jkwin.com.cn/yst_web/doctor/getDoctorList?areaId=42&depId=&hasDuty=&pageNo={0}&pageSize={1}".format(i,page_size)
json_txt=get_html(url,head) #发送请求
parser(json_txt) #解析函数
#解析完数据了,然后一次性批量保存到MySQL数据库
parms = {
#数据库连接参数
"host": "--",
"user": "root",
"password": "123456",
"db": "---",
"charset": "utf8",
}
sql = "INSERT into doctorinfo(staff_name,staff_type,remark,\
org_name,org_grade_name,good_at)\
VALUES(%s,%s,%s,%s,%s,%s)" # 带占位符的SQL
save_mysql(sql, out_list, **parms) # 调用函数,注意**不能省略
注意!要修改自己的数据库信息!

结果:
sql语句:
CREATE TABLE `doctorinfo` (
`staff_name` varchar(255) DEFAULT NULL,
`staff_type` varchar(255) DEFAULT NULL,
`remark` varchar(10000) DEFAULT NULL,
`org_name` varchar(255) DEFAULT NULL,
`org_grade_name` varchar(255) DEFAULT NULL,
`good_at` varchar(255) DEFAULT NULL
)
remark 那里的长度 我是随意设的 ,因为第一次跑出来 跳了一个提示 是长度不够!
我就加长设置了!
拜~