基于卷积神经网络的垃圾分类
卷积神经网络 - 垃圾分类
代码和数据集可以在 我的AI学习笔记 - github 中获取
实验内容
自今年7月1日起,上海市将正式实施 《上海市生活垃圾管理条例》。垃圾分类,看似是微不足道的“小事”,实则关系到13亿多人生活环境的改善,理应大力提倡。
垃圾识别分类数据集中包括 glass、cardboard、metal、paper、plastic、trash,共6个类别。
生活垃圾由于种类繁多,具体分类缺乏统一标准,大多人在实际操作时会“选择困难”,基于深度学习技术建立准确的分类模型,利用技术手段改善人居环境。
数据集
该数据集包含了 2307 个生活垃圾图片。数据集的创建者将垃圾分为了 6 个类别,分别是:
| 序号 | 中文名 | 英文名 | 数据集大小 |
|---|---|---|---|
| 1 | 玻璃 | glass | 457 |
| 2 | 纸 | paper | 540 |
| 3 | 硬纸板 | cardboard | 370 |
| 4 | 塑料 | plastic | 445 |
| 5 | 金属 | metal | 380 |
| 6 | 一般垃圾 | trash | 115 |
物品都是放在白板上在日光/室内光源下拍摄的,压缩后的尺寸为 512 * 384.
实验要求
-
建立深度学习模型,并尽可能将其调到最佳状态
-
绘制深度学习模型图、绘制并分析学习曲线等
-
分析模型并试着调试不同学习率等超参数对模型的结果影响
本地环境:
GPU:
- NVIDIA Quadro P600
- 驱动程序版本:442.92
- CUDA:10.1(已添加到系统环境变量)
torch 1.5.0+cu101
torchvision 0.6.0+cu101
安装使用均没有报错,并可以使用GPU进行训练。
记录
DNN;开始给的示例代码模型, 一个简单的全连接神经网络
inputs = Input(shape=input_shape)
# 将输入展平
dnn = Flatten()(inputs)
# Dense 全连接层
dnn = Dense(6)(dnn)
dnn = BatchNormalization(axis=-1)(dnn)
dnn = Activation('sigmoid')(dnn)
dnn = Dropout(0.25)(dnn)
dnn = Dense(12)(dnn)
dnn = BatchNormalization(axis=-1)(dnn)
dnn = Activation('relu')(dnn)
dnn = Dropout(0.5)(dnn)
dnn = Dense(6)(dnn)
dnn = BatchNormalization(axis=-1)(dnn)
dnn = Activation('softmax')(dnn)
outputs = dnn
# 生成一个函数型模型
model = Model(inputs=inputs, outputs=outputs)
训练要好一会儿,模型正确率大概在0.3左右;
尝试了一个简单的卷积神经网络模型
随便找的
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(32, (5, 5), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(Flatten())
model.add(Dense(12, activation='relu'))
model.add(Dense(6))
model.add(BatchNormalization(axis=-1))
model.add(Activation('softmax'))
训练正确率大约在0.5 - 0.6,但发生了过拟合,在比赛数据集中只有30%的识别准确率。训练参数和示例一样(没改)
pytorch调参学习
由于是初次接触pytorch和除了samples以外实际上手调参,还是比较茫然的…
尝试过了从头训练神经网络和迁移学习两种方式;
resnet
def getRsn():
model = models.resnet18(pretrained=True)
num_fc_in = model.fc.in_features
model.fc = nn.Linear(num_fc_in, 6)
return model
MO上似乎加载resnet的话内存有可能会出现超限的问题(是不是我哪里操作不正确
mobilenet_v2
于是就尝试了一下mobilenet_v2,但可能由于过拟合的原因,实际在测试数据上表现并不好;
可以再尝试尝试;
def getMbnet():
model = models.mobilenet_v2(pretrained=True)
model.classifier = nn.Sequential(
nn.Linear(in_features=1280,out_features=64),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(in_features=64,out_features=6,bias=True),
)
return model
自己写的一个简单的CNN
大致就是普通CNN的结构,先多层卷积层池化层,然后用全连接层解决分类问题;
class MyCNN(nn.Module):
"""
网络模型
"""
def __init__(self, image_size, num_classes):
super(MyCNN, self).__init__()
# conv1: Conv2d -> BN -> ReLU -> MaxPool
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
# conv2: Conv2d -> BN -> ReLU -> MaxPool
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
# fully connected layer
self.dp1 = nn.Dropout(0.20)
self.fc1 = nn.Linear(4608, 256)
self.dp2 = nn.Dropout(0.50)
self.fc2 = nn.Linear(256, num_classes)
def forward(self, x):
"""
input: N * 3 * image_size * image_size
output: N * num_classes
"""
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
# view(x.size(0), -1): change tensor size from (N ,H , W) to (N, H*W)
x = x.view(x.size(0), -1)
x = self.dp1(x)
x = self.fc1(x)
x = self.dp2(x)
output = self.fc2(x)
return output
训练超参数:
batch_size = 20
num_epochs = 10
lr = 0.00007
num_classes = 6
image_size = 64
同时也对图片进行了一系列变换,如旋转、翻转、灰度化以增强稳定度;
输入的图片大小为64*64
最后提交的完整代码:
模型训练代码
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import time
import os
from torchvision import models
import matplotlib.pyplot as plt
class MyCNN(nn.Module):
"""
网络模型
"""
def __init__(self, image_size, num_classes):
super(MyCNN, self).__init__()
# conv1: Conv2d -> BN -> ReLU -> MaxPool
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
# conv2: Conv2d -> BN -> ReLU -> MaxPool
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
# fully connected layer
self.dp1 = nn.Dropout(0.20)
self.fc1 = nn.Linear(4608, 256)
self.dp2 = nn.Dropout(0.50)
self.fc2 = nn.Linear(256, num_classes)
def forward(self, x):
"""
input: N * 3 * image_size * image_size
output: N * num_classes
"""
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
# view(x.size(0), -1): change tensor size from (N ,H , W) to (N, H*W)
x = x.view(x.size(0), -1)
x = self.dp1(x)
x = self.fc1(x)
x = self.dp2(x)
output = self.fc2(x)
return output
def getRsn():
model = models.resnet18(pretrained=True)
num_fc_in = model.fc.in_features
model.fc = nn.Linear(num_fc_in, 6)
return model
def getMbnet():
model = models.mobilenet_v2(pretrained=True)
model.classifier = nn.Sequential(
nn.Linear(in_features=1280,out_features=64),
nn.Dropout(p=0.5,inplace=False),
nn.Linear(in_features=64,out_features=6,bias=True),
)
return model
def train(model, train_loader, loss_func, optimizer, device):
"""
训练模型
train model using loss_fn and optimizer in an epoch.
model: CNN networks
train_loader: a Dataloader object with training data
loss_func: loss function
device: train on cpu or gpu device
"""
total_loss = 0
# train the model using minibatch
for i, (images, targets) in enumerate(train_loader):
images = images.to(device)
targets = targets.to(device)
# forward
outputs = model(images)
_,preds = torch.max(outputs.data,1)
loss = loss_func(outputs, targets)
# backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
if (i + 1) % 100 == 0:
print ("Step [{}/{}] Train Loss: {:.4f} Train acc".format(i+1, len(train_loader), loss.item()))
save_model(model, save_path="results/cnn.pth")
return total_loss / len(train_loader)
def evaluate(model, val_loader, device, name):
"""
评估模型
model: CNN networks
val_loader: a Dataloader object with validation data
device: evaluate on cpu or gpu device
return classification accuracy of the model on val dataset
"""
# evaluate the model
model.eval()
# context-manager that disabled gradient computation
with torch.no_grad():
correct = 0
total = 0
for i, (images, targets) in enumerate(val_loader):
# device: cpu or gpu
images = images.to(device)
targets = targets.to(device)
outputs = model(images)
# return the maximum value of each row of the input tensor in the
# given dimension dim, the second return vale is the index location
# of each maxium value found(argmax)
_, predicted = torch.max(outputs.data, dim=1)
correct += (predicted == targets).sum().item()
total += targets.size(0)
accuracy = correct / total
print('Accuracy on '+name+' Set: {:.4f} %'.format(100 * accuracy))
return accuracy
def save_model(model, save_path="results/cnn.pth"):
'''保存模型'''
# save model
torch.save(model.state_dict(), save_path)
def show_curve(ys, title):
"""
plot curlve for Loss and Accuacy
Args:
ys: loss or acc list
title: loss or accuracy
"""
x = np.array(range(len(ys)))
y = np.array(ys)
plt.plot(x, y, c='b')
plt.axis()
plt.title('{} curve'.format(title))
plt.xlabel('epoch')
plt.ylabel('{}'.format(title))
plt.show()
def fit(model, num_epochs, optimizer, device):
"""
train and evaluate an classifier num_epochs times.
We use optimizer and cross entropy loss to train the model.
Args:
model: CNN network
num_epochs: the number of training epochs
optimizer: optimize the loss function
"""
# loss and optimizer
loss_func = nn.CrossEntropyLoss()
model.to(device)
loss_func.to(device)
# log train loss and test accuracy
losses = []
accs = []
accst = []
for epoch in range(num_epochs):
print('Epoch {}/{}:'.format(epoch + 1, num_epochs))
# train step
loss = train(model, train_loader, loss_func, optimizer, device)
losses.append(loss)
# evaluate step
accuracy = evaluate(model, test_loader, device, 'test')
accuracy1 = evaluate(model, train_loader, device, 'train')
accs.append(accuracy)
accst.append(accuracy1)
# show curve
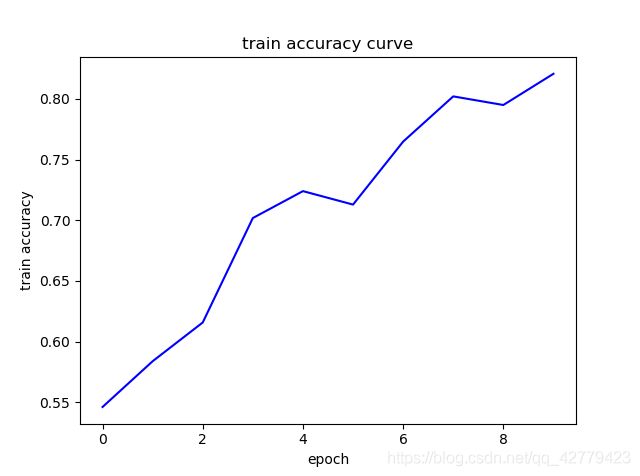
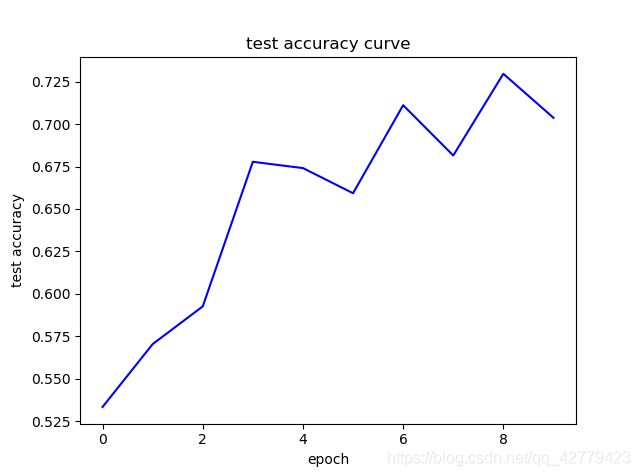
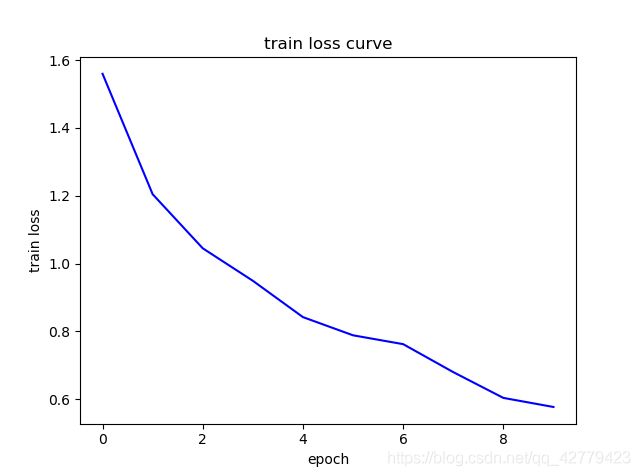
show_curve(losses, "train loss")
show_curve(accs, "test accuracy")
show_curve(accst, "train accuracy")
# model = models.vgg16_bn(pretrained=True)
# model_ft= models.resnet18(pretrained=True)
import numpy as np
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torch
from torchvision import datasets, transforms
from torch.utils import model_zoo
from torch.optim import lr_scheduler
# #hyper parameter
batch_size = 16
num_epochs = 20
lr = 0.00007
num_classes = 6
image_size = 64
path = "datasets/la1ji1fe1nle4ishu4ju4ji22-momodel/dataset-resized"
transform = transforms.Compose([
transforms.Resize((64,64)),
transforms.RandomRotation((30,30)),
transforms.RandomVerticalFlip(0.1),
transforms.RandomGrayscale(0.1),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
dataset = datasets.ImageFolder(path, transform=transform)
print("dataset.classes",dataset.classes)
print("dataset.class_to_idx",dataset.class_to_idx)
idx_to_class = dict((v, k) for k, v in dataset.class_to_idx.items())
print("idx_to_class",idx_to_class)
print('len(dataset)', len(dataset))
"""将训练集划分为训练集和验证集"""
train_db, val_db = torch.utils.data.random_split(dataset, [2257, 270])
print('train:', len(train_db), 'validation:', len(val_db))
# 训练集
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,
shuffle=True,
drop_last=False)
test_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size,
shuffle=True)
classes = set(['cardboard', 'glass', 'metal', 'paper', 'plastic', 'trash'])
# declare and define an objet of MyCNN
mycnn = MyCNN(image_size, num_classes)
# mycnn = getRsn()
# mycnn = getMbnet()
print(mycnn)
# device = torch.device('cuda:0')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
optimizer = torch.optim.Adam(mycnn.parameters(), lr=lr)
# start training on cifar10 dataset
fit(mycnn, num_epochs, optimizer, device)
测试代码:
丢弃了Dropout层;
对图片不进行变换;
import torch
from torch import nn
import random
import numpy as np
from PIL import Image
from torchvision.transforms import transforms
import torchvision.transforms.functional as TF
import os
import torch.utils.data as Data
import torchvision
from torchvision import models
class MyCNN(nn.Module):
"""
网络模型
"""
def __init__(self, image_size, num_classes):
super(MyCNN, self).__init__()
# conv1: Conv2d -> BN -> ReLU -> MaxPool
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=16, out_channels=16, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
# conv2: Conv2d -> BN -> ReLU -> MaxPool
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=1),
)
# fully connected layer
self.dp1 = nn.Dropout(0.20)
self.fc1 = nn.Linear(4608, 256)
self.dp2 = nn.Dropout(0.50)
self.fc2 = nn.Linear(256, num_classes)
def forward(self, x):
"""
input: N * 3 * image_size * image_size
output: N * num_classes
"""
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
# view(x.size(0), -1): change tensor size from (N ,H , W) to (N, H*W)
x = x.view(x.size(0), -1)
##x = self.dp1(x)
x = self.fc1(x)
##x = self.dp2(x)
output = self.fc2(x)
return output
def getRsn():
model = models.resnet18(pretrained=False)
num_fc_in = model.fc.in_features
model.fc = nn.Linear(num_fc_in, 6)
return model
def getMbnet():
model = models.mobilenet_v2(pretrained=True)
print(model)
model.classifier = nn.Sequential(
nn.Linear(in_features=1280,out_features=64),
nn.Dropout(p=0.5, inplace=False),
nn.Linear(in_features=64,out_features=6,bias=True),
)
return model
def load_model(model_path, device):
# net = getRsn()
net = MyCNN(64, 6)
## net = getMbnet()
print('loading the model from %s' % model_path)
state_dict = torch.load(model_path, map_location=str(device))
if hasattr(state_dict, '_metadata'):
del state_dict._metadata
net.load_state_dict(state_dict)
return net
# 加载模型,加载请注意 model_path 是相对路径, 与当前文件同级。
# 如果你的模型是在 results 文件夹下的 dnn.h5 模型,则 model_path = 'results/dnn.h5'
model_path = 'results/cnn.pth'
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = load_model(model_path, device).to(device)
model.eval()
def predict(img):
"""
:param img: PIL.Image 对象
:return: string, 模型识别图片的类别,
共 'cardboard','glass','metal','paper','plastic','trash' 6 个类别
"""
transform = transforms.Compose([
##transforms.RandomCrop(size=(384,512), padding=10),
transforms.Resize((64,64)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
img = transform(img)
classes=['cardboard','glass','metal','paper','plastic','trash']
img = img.to(device).unsqueeze(0)
pred_cate = model(img)
preds = pred_cate.argmax(dim=1)
# -------------------------------------------------------------------------
y_predict = classes[preds]
# 返回图片的类别
return y_predict