一、索引的概述
1)什么是索引?
索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。更通俗的说,索引就相当于目录。当你在用新华字典时,帮你把目录撕掉了,你查询某个字开头的成语只能从第一页翻到第一千页。累!把目录还给你,则能快速定位!
2)索引的优缺点:
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。,且通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。但是,索引也是有缺点的:索引需要额外的维护成本;因为索引文件是单独存在的文件,对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。
二、索引的基本使用
1)创建索引:(三种方式)
第一种方式:

第二种方式:使用ALTER TABLE命令去增加索引:
ALTER TABLE用来创建普通索引、UNIQUE索引或PRIMARY KEY索引。

其中table_name是要增加索引的表名,column_list指出对哪些列进行索引,多列时各列之间用逗号分隔。
索引名index_name可自己命名,缺省时,MySQL将根据第一个索引列赋一个名称。另外,ALTER TABLE允许在单个语句中更改多个表,因此可以在同时创建多个索引。
第三种方式:使用CREATE INDEX命令创建
CREATE INDEX可对表增加普通索引或UNIQUE索引。(但是,不能创建PRIMARY KEY索引)

三、索引的基本原理
索引用来快速地寻找那些具有特定值的记录。如果没有索引,一般来说执行查询时遍历整张表。
索引的原理很简单,就是把无序的数据变成有序的查询
1、把创建了索引的列的内容进行排序
2、对排序结果生成倒排表
3、在倒排表内容上拼上数据地址链
4、在查询的时候,先拿到倒排表内容,再取出数据地址链,从而拿到具体数据
四、索引的数据结构(b树,hash)
1)B树索引
mysql通过存储引擎取数据,基本上90%的人用的就是InnoDB了,按照实现方式分,InnoDB的索引类型目前只有两种:BTREE(B树)索引和HASH索引。B树索引是Mysql数据库中使用最频繁的索引类型,基本所有存储引擎都支持BTree索引。通常我们说的索引不出意外指的就是(B树)索引(实际是用B+树实现的,因为在查看表索引时,mysql一律打印BTREE,所以简称为B树索引)

查询方式:
主键索引区:PI(关联保存的时数据的地址)按主键查询,
普通索引区:si(关联的id的地址,然后再到达上面的地址)。所以按主键查询,速度最快
B+tree性质:
1.)n棵子tree的节点包含n个关键字,不用来保存数据而是保存数据的索引。
2.)所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.)所有的非终端结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
4.)B+ 树中,数据对象的插入和删除仅在叶节点上进行。
5.)B+树有2个头指针,一个是树的根节点,一个是最小关键码的叶节点。
2)哈希索引
简要说下,类似于数据结构中简单实现的HASH表(散列表)一样,当我们在mysql中用哈希索引时,主要就是通过Hash算法(常见的Hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法),将数据库字段数据转换成定长的Hash值,与这条数据的行指针一并存入Hash表的对应位置;如果发生Hash碰撞(两个不同关键字的Hash值相同),则在对应Hash键下以链表形式存储。当然这只是简略模拟图。

ps:关于数据结构,有兴趣深入的朋友可以关注我后查看【数据结构】专题,这里不做详细讲解。
五、创建索引的原则(重中之重)
索引虽好,但也不是无限制的使用,最好符合一下几个原则
1) 最左前缀匹配原则,组合索引非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2)较频繁作为查询条件的字段才去创建索引
3)更新频繁字段不适合创建索引
4)若是不能有效区分数据的列不适合做索引列(如性别,男女未知,最多也就三种,区分度实在太低)
5)尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
6)定义有外键的数据列一定要建立索引。
7)对于那些查询中很少涉及的列,重复值比较多的列不要建立索引。
8)对于定义为text、image和bit的数据类型的列不要建立索引。
百万级别或以上的数据如何删除
关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。所以,在我们删除数据库百万级别数据的时候,查询MySQL官方手册得知删除数据的速度和创建的索引数量是成正比的。
所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
然后删除其中无用数据(此过程需要不到两分钟)
删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。
正文:表的设计及优化
优化①:创建规范化表,消除数据冗余
数据库范式是确保数据库结构合理,满足各种查询需要、避免数据库操作异常的数据库设计方式。满足范式要求的表,称为规范化表,范式产生于20世纪70年代初,一般表设计满足前三范式就可以,在这里简单介绍一下前三范式。
通俗的给大家解释一下(可能不是最科学、最准确的理解)
第一范式:属性(字段)的原子性约束,要求属性具有原子性,不可再分割;
第二范式:记录的惟一性约束,要求记录有惟一标识,每条记录需要有一个属性来做为实体的唯一标识。
第三范式:属性(字段)冗余性的约束,即任何字段不能由其他字段派生出来,在通俗点就是:主键没有直接关系的数据列必须消除(消除的办法就是再创建一个表来存放他们,当然外键除外)
当然,其实我们经常打破第三范式。。。且不可避免的,其实就是要在数据冗余和处理速度之间找到合适的平衡点 。
优化②:合适的字段属性
先举个例子:
以前我做过的电商项目中,关于资金流水类型的字段的选取。本来资金流水类型总共就那么十几种,基本固定死的,那我们就可以选择tinyint(4)就完全足够了,对应的是java的byte。 (要知道的是,tinyint的长度就是8位,tinyint(1)和tinyint(4)只是显示长度)
下面以下给出几个字段的建议:
0)数值型字段的比较比字符串的比较效率高得多,所以字段类型尽量使用最小、最简单的数据类型。如IP地址可以使用int类型,如我上面的例子。
1)建议不要使用DOUBLE,不仅仅只是存储长度的问题,同时还会存在精确性的问题。
2)对于整数的存储,在数据量较大的情况下,建议区分开 TINYINT / INT / BIGINT 的选择(当然,那已经是很老的事情了,现在其实不差这点性能)
3)char是固定长度,所以它的处理速度比varchar快得多,但缺点是浪费存储空间,不能在行尾保存空格。在MySQL中,MyISAM建议使用固定长度代替可变长度列;InnoDB建议使用varchar类型,因为在InnoDB中,内部行存储格式没有区分固定长度和可变长度。
4) 尽量不要允许NULL,除非必要,可以用NOT NULL+DEFAULT代替。
5)text与blob区别:blob保存二进制数据;text保存字符数据,有字符集。text和blob不能有默认值。
实际场景:text与blob主要区别是text用来保存字符数据(如文章,日记等),blob用来保存二进制数据(如照片等)。blob与text在执行了大量删除操作时候,有性能问题(产生大量的“空洞“),为提高性能建议定期optimize table 对这类表进行碎片整理。
6) 自增字段要慎用,不利于数据迁移
7)强烈反对在数据库中存放 LOB 类型数据,虽然数据库提供了这样的功能,但这不是他所擅长的,我们更应该让合适的工具做他擅长的事情,才能将其发挥到极致。(反正我么碰到过LOB类型数据)
8)尽量将表字段定义为NOT NULL约束,这时由于在MySQL中含有空值的列很难进行查询优化,NULL值会使索引以及索引的统计信息变得很复杂,可以使用0或者空字符串来代替。
9)尽量使用TIMESTAMP类型,因为其存储空间只需要 DATETIME 类型的一半,且日期类型中只有它能够和实际时区相对应。对于只需要精确到某一天的数据类型,建议使用DATE类型,因为他的存储空间只需要3个字节,比TIMESTAMP还少。(真的是技术文,欢迎补充)
优化③:索引
索引是一个表优化的重要指标,在表优化中占有极其重要的成分,所以上篇索引优化详解没看过的可以先看看,这里不再赘叙。
优化④:表的拆分(大表拆小表)
1、垂直拆分(其实就是列的拆分将原来的一个有很多列的表拆分成多张表)
注意:垂直拆分应该在数据表设计之初就执行的步骤,然后查询的时候用jion关键起来即可;
通常我们按以下原则进行垂直拆分:
把不常用的字段单独放在一张表;
把text,blob等大字段拆分出来放在附表中;
经常组合查询的列放在一张表中;
缺点也很明显,需要使用冗余字段,而且需要join操作。
2、水平拆分( 如果你发现某个表的记录太多,例如超过一千万条,则要对该表进行水平分割。水平分割的做法是,以该表主键的某个值为界线,将该表的记录水平分割为两个表。)

当然,我们还可以用增量法。如流水这类不会改变的数据,我们用增量查询。
1.创建一张日充值表,记录每天充值总额
2.每天用定时器对当前充值记录进行结算
3.创建每月充值表,每月最后一天用定时器计算总额
4.则要查询总额,则从月报表中汇总,再从日报表查询当天之前的数据汇总,再加上今天的使用当天流水表记录今天的流水,三张表加起来,汇总。这样子效率是极好的!
优化⑤:传说中的‘三少原则’
①:数据库的表越少越好
②:表的字段越少越好
③:字段中的组合主键、组合索引越少越好
当然这里的少是相对的,是减少数据冗余的重要设计理念。
一、MYSQL储存过程简介:
储存过程是一个可编程的函数,它在数据库中创建并保存。它可以由SQL语句和一些特殊的控制结构组成。当希望在不同的应用程序或平台上执行相同的函数,或者封装特定功能时,存储过程是非常有用的。数据库中的存储过程可以看做是对编程中面向对象方法的模拟。它允许控制数据的访问方式。存储过程通常有以下优点:
1)存储过程能实现较快的执行速度。
如果某一操作包含大量的Transaction-SQL代码或分别被多次执行,那么存储过程要比批处理的执行速度快很多。因为存储过程是预编译的。在首次运行一个存储过程时查询,优化器对其进行分析优化,并且给出最终被存储在系统表中的执行计划。而批处理的Transaction-SQL语句在每次运行时都要进行编译和优化,速度相对要慢一些。
心得:编译优化,快!
2)存储过程允许标准组件是编程。
存储过程被创建后,可以在程序中被多次调用,而不必重新编写该存储过程的SQL语句。而且数据库专业人员可以随时对存储过程进行修改,对应用程序源代码毫无影响。
心得:封装与抽象,简单调用
3)存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
心得:功能强大,逻辑强大
4)存储过程可被作为一种安全机制来充分利用。
系统管理员通过执行某一存储过程的权限进行限制,能够实现对相应的数据的访问权限的限制,避免了非授权用户对数据的访问,保证了数据的安全。
心得:限制与安全
5)存储过程能过减少网络流量。
减少网络流量是指减少与客户端之间的交互,在服务器上执行运算,最后只把结果反给客户端,所以流量少
执行速度:
存储过程在首次执行的时候会进行预编译,查询优化器会对其进行分析,优化,并给出最终被存在系统表中的执行计划.而批处理的sql语句在每次运行时都要进行编译和优化,因此速度相对要慢.
网络流量:
调用存储过程只需要传几个参数,而SQL语句可能会是N多条,自然网络流量会差很多.
针对同一个数据库对象的操作(如查询、修改),如果这一操作所涉及的Transaction-SQL语句被组织程存储过程,那么当在客户计算机上调用该存储过程时,网络中传送的只是该调用语句,从而大大增加了网络流量并降低了网络负载。
心得:减少网络流量(封装的好)
二、那存储函数(自定义函数)又是什么呢?:
封装一段sql代码,完成一种特定的功能,必须返回结果。其余特性基本跟存储过程相同。
三、存储函数与存储过程的区别:
1) 存储函数有且只有一个返回值,而存储过程不能有返回值。就是说能不能使用return。(函数可返回返回值或者表对象,绝对不能返回结果集)

2) 函数只能有输入参数,而且不能带in, 而存储过程可以有多个in,out,inout参数。
3) 存储过程中的语句功能更强大,存储过程可以实现很复杂的业务逻辑,而函数有很多限制,如不能在函数中使用insert,update,delete,create等语句;存储函数只完成查询的工作,可接受输入参数并返回一个结果,也就是函数实现的功能针对性比较强。比如:工期计算、价格计算。
4)存储过程可以调用存储函数。但函数不能调用存储过程。
5)存储过程一般是作为一个独立的部分来执行(call调用)。而函数可以作为查询语句的一个部分来调用。
四、MySQL 创建一个最简单的存储过程:
“pr_add” 是个简单的 MySQL 存储过程,这个存储过程有两个 int 类型的输入参数 “a”、“b”,返回这两个参数的和。
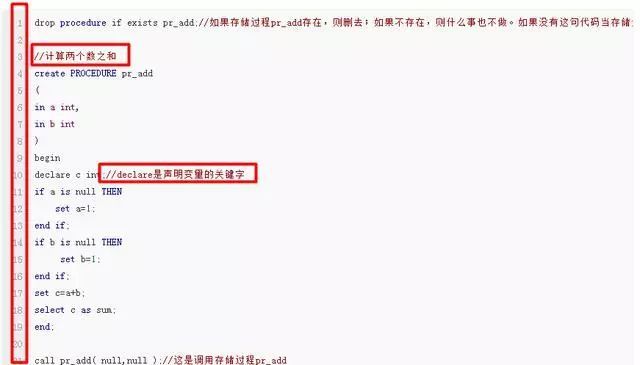
五、MySQL 存储过程特点:
创建 MySQL 存储过程的简单语法为:
create procedure 存储过程名字()
(
[in|out|inout] 参数 datatype
)
begin
MySQL 语句;
end;
MySQL 存储过程参数如果不显式指定“in”、“out”、“inout”,则默认为“in”。习惯上,对于是“in” 的参数,我们都不会显式指定。
1 MySQL 存储过程名字后面的“()”是必须的,即使没有一个参数,也需要“()”
2 MySQL 存储过程参数,不能在参数名称前加“@”,如:“@a int”。下面的创建存储过程语法在 MySQL 中是错误的(在 SQL Server 中是正确的)。 MySQL 存储过程中的变量,不需要在变量名字前加“@”,虽然 MySQL 客户端用户变量要加个“@”。
create procedure pr_add( @a int,// 错误 b int //正确)
3 MySQL 存储过程的参数不能指定默认值。
4 MySQL 存储过程不需要在 procedure body 前面加 “as”。而 SQL Server 存储过程必须加 “as” 关键字。
create procedure pr_add( a int, b int)as - 错误,MySQL 不需要 “as”begin mysql statement ...;end;
5 如果 MySQL 存储过程中包含多条 MySQL 语句,则需要 begin end 关键字。
create procedure pr_add( a int, b int)begin mysql statement 1 ...; mysql statement 2 ...;end;
6 MySQL 存储过程中的每条语句的末尾,都要加上分号 “;”
... declare c int; if a is null then set a = 0; end if; ...end;
7 不能在 MySQL 存储过程中使用 “return” 关键字。
set c = a + b;select c as sum; /* return c;- 不能在 MySQL 存储过程中使用。return 只能出现在函数中。 */end;
8 调用 MySQL 存储过程时候,需要在过程名字后面加“()”,即使没有一个参数,也需要“()”,调用out及inout参数格式为@arguments_name形式。
call pr_no_param();
9 因为 MySQL 存储过程参数没有默认值,所以在调用 MySQL 存储过程时候,不能省略参数。可以用 null 来替代。
call pr_add(10, null);
1,实战前提(技术文):
需要MySQL 5及以上 ,我用的是MYSQL的客户端Navicat Premium,贴出的代码都是我变异没有错误的。如果读者没有安装客户端或者在你的电脑上报错,这里需要用到是DELIMITER //和DELIMITER ;两句,DELIMITER是分割符的意思,因为MySQL默认以”;”为分隔符,如果我们没有声明分割符,那么编译器会把存储过程当成SQL语句进行处理,则存储过程的编译过程会报错,所以要事先用DELIMITER关键字申明当前段分隔符,这样MySQL才会将”;”当做存储过程中的代码,不会执行这些代码,用完了之后要把分隔符还原
2,变量
使用DECLARE来声明,DEFAULT赋默认值,SET赋值
Java代码 复制代码
DECLARE counter INT DEFAULT 0; SET counter = counter+1;
3,条件判断
IF THEN、ELSEIF、ELSE、END IF
DROP PROCEDURE IF EXISTS discounted_price; CREATE PROCEDURE discounted_price(normal_price NUMERIC(8, 2), OUT discount_price NUMERIC(8, 2)) BEGIN IF (normal_price > 500) THEN SET discount_price = normal_price * 0.8; ELSEIF (normal_price > 100 and normal_price<=500) THEN SET discount_price = normal_price * 0.9; ELSE SET discount_price = normal_price; END IF; select discount_price as price; END;call discounted_price(600.0,@discount);//out参数调用时可以用@任意字符串
4,循环
LOOP、END LOOP
drop procedure if exists simple_loop;create procedure simple_loop(out counter int)BEGIN declare temp int default 0; set counter=0; my_loop:LOOP set counter=counter+1; set temp=temp+1; if counter=10 THEN leave my_loop; end if; end loop my_loop; select temp as result;end;call simple_loop(@a);
5、WHILE DO、END WHILE
DROP PROCEDURE IF EXISTS simple_while; CREATE PROCEDURE simple_while(OUT counter INT) BEGIN declare temp int default 0; SET counter =0; WHILE counter != 10 DO SET counter =counter+1; set temp =temp+1; END WHILE; select counter as temp1; END; call simple_while(@a);
6、REPEAT、UNTILL
drop PROCEDURE if exists simple_repeat;create procedure simple_repeat(out counter int)BEGIN set counter=0; REPEAT set counter=counter+1; until counter=10 end repeat; select counter as temp;end;call simple_repeat(@q);
7,存储方法
存储方法与存储过程的区别
1,存储方法的参数列表只允许IN类型的参数,而且没必要也不允许指定IN关键字
2,存储方法返回一个单一的值,值的类型在存储方法的头部定义
3,存储方法可以在SQL语句内部调用
4,存储方法不能返回结果集
语法:
create function 函数([函数参数[,….]]) Returns 返回类型Begin If Return (返回的数据)Else Return (返回的数据)end if; end;
一个简单的存储函数实例
drop function if exists purchase_and_redeem_function;CREATE function purchase_and_redeem_function(date int) returns varchar(80) BEGIN return (SELECT tbalance FROM user_purchase_and_redeem WHERE report_date=date); //这里面的SQL语句根据自己数据库表编写 END;select purchase_and_redeem_function(20140501);//这是调用存储函数
8,触发器
触发器在INSERT、UPDATE或DELETE等DML语句修改数据库表时触发
触发器的典型应用场景是重要的业务逻辑、提高性能、监控表的修改等
触发器可以在DML语句执行前或后触发
DROP TRIGGER sales_trigger;CREATE TRIGGER sales_triggerBEFORE INSERT ON salesFOR EACH ROWBEGINIF NEW.sale_value > 500 THENSET NEW.free_shipping = 'Y';ELSESET NEW.free_shipping = 'N';END IF;IF NEW.sale_value > 1000 THENSET NEW.discount = NEW.sale_value * .15;ELSESET NEW.discount = 0;END IF;END;