三维重建的常用方法:
1. 立体视觉方法(双目、多目立体),Structure from Motion
2. 光度方法(Shape from Shading、Photometric Stereo、 Multispectral Photometric Stereo)
3. 深度学习预测
4. 结构光
5. 还有一些基于硬件传感器的比如深度相机、TOF等。
目前成型的“实用”方法有两类:结构光 和 SFM(立体视觉),结构光适合室内高精度重建,商业产品较多。SFM比结构光更方便,但精度稍差些。
就初步了解,大多数三维重建的数据源是RGB图像,或者RGBD这种带有图像深度信息的图像(用kinect之类的特殊特备拍出来的)。
主要的流程:(我觉得这个流程应该都是针对SFM的,SFM是最经典的三维重建方案)
1.特征提取(SIFT, SURF, FAST等一堆方法)
2.配准(主流是RANSAC和它的改进版)
3.全局优化bundle adjustment
4.数据融合(这个还没搞清楚,之后看看吧)
百度百科说的很细:
三维重建的步骤:
(1) 图像获取:在进行图像处理之前,先要用摄像机获取三维物体的二维图像。光照条件、相机的几何特性等对后续的图像处理造成很大的影响。【就是照张像,推荐使用好的相机】
(2)摄像机标定:通过摄像机标定来建立有效的成像模型,求解出摄像机的内外参数,这样就可以结合图像的匹配结果得到空间中的三维点坐标,从而达到进行三维重建的目的。【内参数顾名思义是相机内部的参数(焦距,光心坐标),外参数是相机外部的参数(对象的旋转平移矩阵,4x3大小的,其中3x3是旋转,1x3是平移)】讲摄像机标定的博主
(3)特征提取:特征主要包括特征点、特征线和区域。大多数情况下都是以特征点为匹配基元,特征点以何种形式提取与用何种匹配策略紧密联系。因此在进行特征点的提取时需要先确定用哪种匹配方法。
【特征点提取算法可以总结为:基于方向导数的方法,基于图像亮度对比关系的方法,基于数学形态学的方法三种。】
特征点就是用于定位的关键点,这一步是找出来,下一步是一一对应上。
(4)立体匹配:立体匹配是指根据所提取的特征来建立图像对之间的一种对应关系,也就是将同一物理空间点在两幅不同图像中的成像点进行一一对应起来。在进行匹配时要注意场景中一些因素的干扰,比如光照条件、噪声干扰、景物几何形状畸变、表面物理特性以及摄像机机特性等诸多变化因素。
(5)三维重建:有了比较精确的匹配结果,结合摄像机标定的内外参数,就可以恢复出三维场景信息。由于三维重建精度受匹配精度,摄像机的内外参数误差等因素的影响,因此首先需要做好前面几个步骤的工作,使得各个环节的精度高,误差小,这样才能设计出一个比较精确的立体视觉系统
想着要动手试下基础的SFM三维重建。
摄像机标定理解之后觉得挺简单,下一步:特征点提取,因为要求两个相机的相对关系,需要两幅照片中的对应点,这就演变成了特征点的提取和匹配问题。
对于图像差别较大的情况,推荐使用SIFT特征。因为sift对旋转,尺度,透视都有比较好的鲁棒性。
那么问题来了!!Opencv3.0将sift包含在了扩展部分中,竟然还是一个只能从github上下载的东西!!下载完之后还要重新编译opencv(我的天啊畏难情绪max了,公司的windows我咋重新编译啊,Linux还好说一点这是windows啊还没开始就觉得会有大坑怎么办!!啊硬着头皮也得上!!!)
吸取在windows上摔过的无数大坑,我还是选择先调研一下别人怎么做的:
1.博主大大是用官方教程编译的,他从github上下了opencv_contrib。https://github.com/opencv/opencv_contrib
照着这些命令在Linux里头解决了。然而公司电脑没有Linux!!
linux+opencv(c++)
2.我怀抱一线希望跑去找了3.2.0版本的opencv(盼着它能自带sift= =)。因为博主大大做的时候只有3.0.0么。然后呢我发现了一个叫opencv_sfm的模块,╮(╯▽╰)╭?可以直接用??定睛一看(only ubuntu!!)http://docs.opencv.org/3.2.0/db/db8/tutorial_sfm_installation.html
linux +opencv
3.VS2010+SIFT+windows
这个sift跟博主大大说的不一样,博主大大说的是opencv扩展包里的sift实现,这个博主说的是Rob Hess 可能是个人实现的sift模块。它教人怎么把这个移植到自己的vs里去。教程在这里http://blog.csdn.net/lanbing510/article/details/8507341
4.python+opencv+ubuntu
这个博主说opencv3版本和2相比移走了一些函数(包括我们要的sift surf这些),把他们放在了opencv_contrib里。感觉和1中的一样,就是官方教程的中文详解版,还是只适用于ubuntu
http://www.cnblogs.com/asmer-stone/p/5090263.html
(关键在于这个是第一个Python示例,我想可能之后也会用python来搞)
5.windows+opencv_contrib 配置,在win下CMAKE的教程。
(我觉得这个还挺值得一试的)
准备4个东西:
桌面版github(是一个通用工具啦,就是可以在桌面用git clone 。。。。)
opencv3.0(下好opencv for Windows)
opencv_contrib(这还真是只有Github上有)
cmake_gui (有个win32 installer,桌面版的cmake??)
http://www.tuicool.com/articles/juM3ArZ
地址文中都有给出。
6.opencv2.x版本中直接用surf和sift做实验
http://www.cnblogs.com/ronny/p/opencv_road_9.html
这个博主的评论栏很有意思,虽然我还没开始实验但有人问如果surfFeatureDetector显示未定义的话,要确认是不是用了opencv3.0
http://blog.jobbole.com/84227/(这人转载了上文)
7.这人做了sift的实验(用Opencv2.x)用的C++
http://www.cnblogs.com/dragonfive/p/4498644.html
好了我大概懂了,就是opencv3把本来2里有的surf sift当作不稳定因素拿到opencv_contrib里头了,这个扩展包需要去Github下载(唯一下载源)并且重新编译opencv(CMAKE),windows下也可以下一个CMAKE for windows用GUI进行重新编译。翻了一下我那本opencv3教程,里头又个最后一节就是特征点检测的(附带了一点点配准)我觉得可以先试试那个教程。
了解了一些基础中的基础之后,我还是考虑了一下和深度学习结合的可能性。
首先查了一下包含关键字的文章。
最新的是在2016年的一个会议上,一篇用神经网络来提升人脸三维重建的面部配准精度。
再就是很找到了几篇2000年初使用神经网络做三维重建(各种)的文章。
我大致看了一下2000年初的神经网络做三维重建,输入是传统方法预处理好的关键数据,神经网络比较简单(深度网络都比较新潮吧)
深度学习和神经网络的差别,首先是它层数多,其次是它主打的是端到端的学习,就是给进去的输入特别的直白浅显(比如风格化里就给一张RGB图),然后让卷积网络一层层的自行理解它的意义,而稍早些的神经网络的办法,输入应该是经过仔细处理提取出的各类数学信息。
在知乎翻到了一个问题:
计算机图形学与机器学习(深度学习)怎么结合起来?
是一个浙大新近博士问的问题,将CG和DL怎么结合一下。
我感觉比较有参考价值的回答:
1. 喂进去很离线渲染的场景和渲染结果,训练神经网络(充当渲染功能,这样实现对任意场景快速渲染)
2.Data-Driven Approaches(CG里近年来有很多data driven的文章,里面会用到很多统计学工具以及unsupervised learning什么的。就是说最初的CG把各种图形处理工具和算法研制出来后,素材一直是靠艺术家来创作的。最近几年,大数据流行起来了,CG从业的艺术家们通过十几年的努力也创作了大批大批的成品,那么研究人员就开始想着利用这些数据来给今后艺术家们的创作带来方便,所以CG就朝data driven迈步了。)
data driven的文章用得比较多的就是PCA降维一个数据库里的数据,然后使得用户得到的结果是和他的简单输入最相似的在数据库形成的数据空间里的一点。
作者举例就是说的三维重建:给了篇论文,我打不开(gravis.dmi.unibas.ch/publications/Sigg99/morphmod2.pdf )
用单张人脸正面照片做3D人脸重建,基于3D人脸模型数据库。
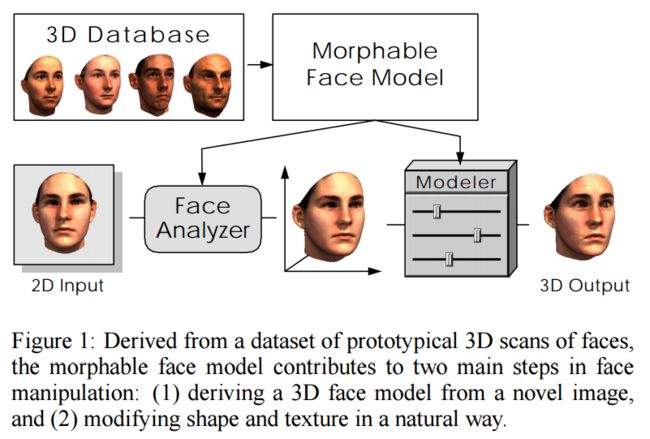
这应该算是单图进行三维重建的一个特例吧,因为它限定了一个数据集广泛且有共性的的重建对象,就是人脸