使用Faster RCNN训练自己的数据集
使用Faster RCNN训练自己的数据集,过程不太顺利,踩坑数次,所以把流程记录一下。
所使用的代码版本:faster-rcnn.pytorch
1.源码及环境配置
原Github版本使用的Pytorch==0.4.0,但是看了网上的博客记录这个版本有较多错误无法解决,建议使用Pytorch==1.0.0及以上版本;
- 源码
Pytorch0.4.0版源码:https://github.com/jwyang/faster-rcnn.pytorch.git
Pytorch1.0.0版源码:https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0
- 环境配置
Ubuntu16.04
Python==3.6 + Pytorch==1.2.0
由于CUDA版本向下兼容,所以这里不作特殊说明.
- 使用Anaconda安装虚拟环境
conda create -n faster-rcnn python=3.6在Pytorch官网中找到对应的Pytorch与torchvision版本:
# CUDA 10.0
conda install pytorch==1.2.0 torchvision==0.4.0如图所示,此时cudatoolkit=10.0也会自动安装。

- 安装其他环境依赖
pip install -r requirements.txt2.预训练模型编译
- 新建文件夹
(注:本文将原文件夹重命名为faster-rcnn)在文件夹中新建data文件夹
cd faster-rcnn && mkdir data在data文件夹中新建pretrained_model文件夹
mkdir pretrained_model- 下载预训练模型VGG16与ResNet-101
预训练模型VGG16:VGG16
预训练模型ResNet-101:ResNet-101
将下载好的预训练模型放到pretrained_model文件夹中
- 执行编译
cd lib
python setup.py build develop
cd ..编译完成,如图所示

如果执行编译后,训练自己的数据集仍然报错:
ImportError: cannot import name '_mask'则是缺少COCO API,需要执行以下指令
cd data
git clone https://github.com/pdollar/coco.git
cd coco/PythonAPI
make
cd ../../..如图所示

可以看到'_mask.o'已经编译成功
- Scipy降版本
使用pip查看已经安装的Python库
pip list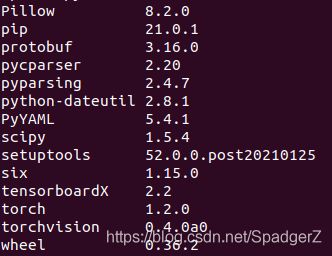
可以看到其中Scipy与Pillow版本分别问scipy==1.5.4与Pillow==8.2.0,由于Scipy版本自身的变动原因,需要对Scipy进行降版本,否则在训练中会报错
ImportError: cannot import name 'imread' 首先卸载以上两个版本
pip uninstall scipy
pip uninstall pillow然后安装指定版本即可
pip install scipy == 1.2.1
pip install pillow == 6.1.03.数据集准备
本文训练的数据集是VOC格式
- 新建文件夹
cd data && mkdir VOCdevkit2007将之前标注得到的数据集放到VOCdevkit2007文件夹中,并重命名为VOC2007
VOC文件夹格式
---VOC2007
------Annotations
------ImagesSet
-------Main
----trainval.txt
----train.txt
----val.txt
----test.txt
------JPEGImages
本文训练集/验证集/测试集比例为6:2:2
- 修改数据集类别
首先进入到文件夹
cd lib/datasets/
vim pascal_voc.py将第48行'self._classes'改成自己的类别
# before
self._classes = ('__background__', # always index 0
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor')
# after
self._classes = ('__background__', # always index 0
'xxx', 'yyy', 'zzz')将第243行'cls'中的.lower()去掉,这是由于有些标注数据集类别中存在大写,在训练过程中会报错(或者全部使用小写标注)
# before
cls = self._class_to_ind[obj.find('name').text.lower().strip()]
# after
cls = self._class_to_ind[obj.find('name').text.strip()]以上就是我遇到的问题,都解决之后就可以开始训练了
4.训练
训练指令
# train
$ CUDA_VISIBLE_DEVICES=1 python trainval_net.py --dataset pascal_voc --net vgg16 --bs 16 --nw 4 --cuda --epochs 100
参数解释
CUDA_VISIBLE_DEVICES # GPU ID,即使用哪块GPU进行训练
-dataset # 数据集类型,就以pascal-voc为例
-net # 所使用的backbone网络,以vgg16为例
–bs # 指的batch size,以16为例,显存不够就调小bs
–nw # 指的是worker number,取决于你的Gpu能力,以4为例,稍微差一些的gpu可以选小一点的值
–cuda # 指的是使用GPU训练
-epochs # 此处设为100,估计需要跑很久训好的model会存到models文件夹中
等待训练完成ing
参考博客
使用faster-rcnn.pytorch训练自己数据集(完整版)
运行faster-rcnn/pytorch/jwyang版本出现的错误
faster-rcnn.pytorch问题汇总和解决
Faster-RCNN 训练自己数据集的坑记录
Faster-RCNN+ZF用自己的数据集训练模型(Python版本)
Faster RCNN CPU模式下进行训练
Pytorch版Faster R-CNN训练自己数据集
使用pytorch版faster-rcnn训练自己数据集