记录下hadoop2.6.5集群的整个搭建流程,以免自己忘了,集由于Hadoop是依赖java的,所以我们也需要准好jdk。
前期准备:
需要准备好服务器,jdk,hadoop安装包,可以去官网下载,在学习搭建的时候用的是centos6.8,jdk1.8,hadoop2.6.5,如果不知道怎么下载可以去下边的地址下载。
centos6.8的包:https://pan.baidu.com/s/1VTuIR7k8qXrL9tn5qJN-cA
jdk1.8安装包:https://pan.baidu.com/s/1t8b1g30gYYisQSuyKXvzAQ
hadoop安装包:https://pan.baidu.com/s/1B1g1S_rE5RiBzZDjtZguAQ
这些都是在默认装好了VM或者其他虚拟机的前提下进行的。
hadoop集群的规划

集群搭建的具体步骤:
注意:一下的步骤出了改主机名需要针对每台来设置外,其他的均只需要在第一台上设置就好了,配置好第一台之后,我们会用scp命令来远程copy到另外两台,因为搭建的集群,所有服务器的配置必须一样,这样可以减少错误。当然,主机名需要单独配置。
一、硬件准备
1、服务器准备
- VMware
- CentOS6.8 ,为了能呈现一个集群效果,所以至少准三台虚拟机(安装3个相同的centos)(hadoop01、hadoop02、hadoop03)。
2、网络环境准备
- 在装系统的时候,选择NAT模式,这是最简单的,只要宿主机器能上网就可以,省去设置IP地址、子网掩码、网关、DNS(外网)
二、linux系统环境的准备
1、 修改主机名(root用户下)
使用命令
[root@bogon ~]# vim /etc/sysconfig/network

修改完成,Esc热键进入末行模式,输入“:wq”保存退出。
2、配置ip地址(root用户)
(1)这里提供了两种利用命令来设置ip的方式
方法1、 直接修改配置文件,需要root权限
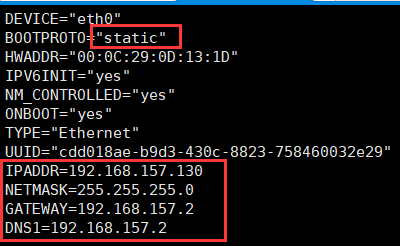
[root@hadoop01 ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" #这里把DHCP改为static
HWADDR="00:0C:29:0D:13:1D"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="cdd018ae-b9d3-430c-8823-758460032e29"
IPADDR=192.168.157.130 #设置ipv4地址,这个根据自己的实际ip来写
NETMASK=255.255.255.0 #子网掩码
GATEWAY=192.168.157.2 #默认网关,一般是ip的前三个字段.2
DNS1=192.168.157.2 #DNS服务器之一,就写成网关的地址就行
修改红框中部分,如果,如果没有这个条目,则添加,一个新的虚拟机系统,第一个框中是将dhcp修改为static,最后的红框中的所有都是需要自己添加的。
注意:这里的ip是根据自己的实际情况来设置的,每个人的是不一样的
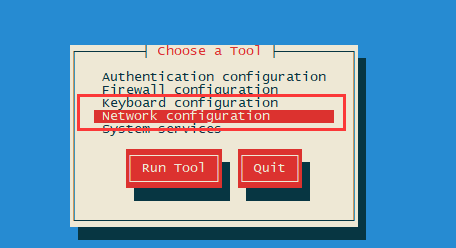
方法2、利用命令setup,在命令终端输入 setup 选择“Network Configuration” ,然后按回车键, 选择“Device Configuration”,按回车键,选中“eth0”,按回车键。
[root@hadoop01 ~]# setup
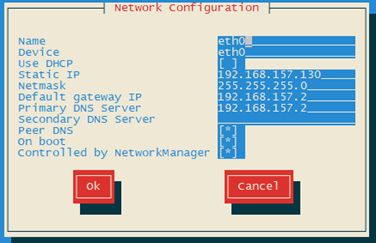

然后选择save&quit,这样退出来之后,重启网络,这样一样是可以改ip的。
改完之后可以ping一下看看是否成功,如果不成功,看一下网关、子网掩码、DNS是否配置正确。这样一般就不会有问题了。
(2按照上述步骤之一修改完成,重启网络服务,使用命令:
[root@hadoop01 ~]#service network restart
(3)检查是否修改成功,使用命令:
[root@hadoop01 ~]#ifconfig
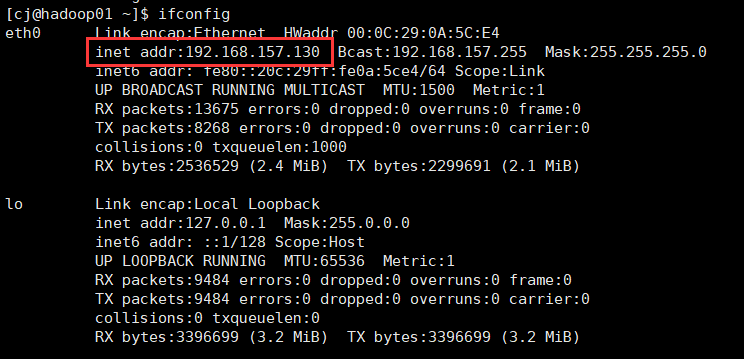
如果ip改过来了,则说明成功了。
3、关闭防火墙(root用户)
(1)查看防火墙状态:service iptables status
[root@hadoop01 ~]# service iptables status

(2)关闭防火墙:service iptables stop
[root@hadoop01 ~]# service iptables stop
这种方式是一次性的,重启虚拟机之后失效

(3)开机不启动:
chkconfig iptables off(永久有效)
[root@hadoop01 ~]# chkconfig iptables off

4、添加内网域名映射(root用户)
修改配置文件,使用命令:vim /etc/hosts
格式:IP地址 [至少一个空格]主机名
[root@hadoop01 ~]# vim /etc/hosts

5、同步网络时间(root用户)
一般如果我们没有做任何设置,时间是不对的,所以需要改一下时间。
(1)修改时区,使用命令:
针对我们需要的时区,里边只有上海的时区(并不是只有这一个时区),没有北京,所以我们就用上海也是一样的
[root@hadoop01 ~]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
把本地的时区修改为上海,直接把/usr/share/zoneinfo/Asia/里的Shanghai复制过去就行
(2)同步网络时间,使用命令:ntpdate cn.pool.ntp.org(中国国家授时中心服务器地址)
[root@hadoop01 ~]# ntpdate cn.pool.ntp.org
(3)查看系统当前时间进行测试,使用命令:
[root@hadoop01 ~]# date

6、安装jdk(普通用户,我的是cj)
这里用普通用户的原因是:如果是在公司里边,公司的服务器一般是不会只有自己一个人用,可能别人不需要jdk这些环境,所以用普通用户,配置用户自己需要的环境变量,当然也可以通过配置/etc/profile来设置这个环境变量,按需求来就好。
(1)准备软件:jdk-8u73-linux-x64.tar.gz
(2)把软件传到 Linux 服务器上去(我的上传目录是/home/cj/Desktop/software)
(3)把软件解包解压缩到当前目录下,使用命令:
[cj@hadoop01 software]$ tar -zxvf jdk-8u73-linux-x64.tar.gz
(4)配置环境变量,使用命令:
[cj@hadoop01 software]$ vim /home/cj/.bash_profile
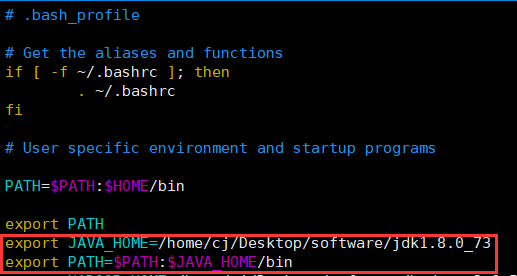
(5)让配置文件立即生效,使用命令:
[cj@hadoop01 software]$ source /home/cj/.bash_profile
注意:
(1)修改 /etc/profile 文件当本机仅仅作为开发使用时推荐使用这种方法,因为此种配置时所有用户的 Shell 都有权使用这些环境变量,可能会给系统带来安全性问题。
(2)export 是把这三个变量导出为全局变量。
(3)大小写必须严格区分。
(6)检测JDK是否安装成功,使用命令:
[cj@hadoop01 software]$ java -version

看到如上图的信息,则说明jdk配置成功
7、配置SSH免密登录(普通用户cj)
这是因为后期集群会操作一些从节点,所以配置一下免密登录。只需要配置hadoop01到另外两台的免密登录就可以了。如果需要配置hadoop02或者hadoop03到另外两台的免密登录,那这时候要注意个问题,在写authorized_keys的时候,需要追加(>>),别把原本的覆盖了.
(1)在3台虚拟机开启的情况下,在主节点 hadoop01 上使用命令:
[cj@hadoop01 ~]$ ssh-keygen 或 ssh-keygen -t rsa
之后会发现在hadoop01的/home/cj/.ssh目录下生成了公钥文件。
(2)复制公钥文件到授权列表文件 authorized_keys中,使用命令:
[cj@hadoop01 .ssh]$ cp id_rsa.pub authorized_keys
(3)修改授权列表文件权限,使用命令:
[cj@hadoop01 .ssh]$chmod 600 ./authorized_keys

(4)将该授权列表文件 authorized_keys 复制到hadoop02和hadoop03上,使用命令:$PWD代表(远程主机的(hadoop02 or hadoop03))当前路径(/home/cj/.ssh/)
[cj@hadoop01 .ssh]$scp authorized_keys cj@hadoop02:$PWD
[cj@hadoop01 .ssh]$scp authorized_keys cj@hadoop03:$PWD
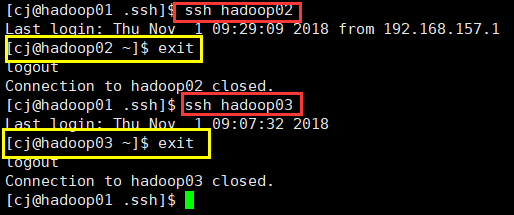
达到这个效果则说明ssh免密登录设置成功了。
到此,hadoop集群的准备工作就已经完成了,接下来就是hadoop集群的正式搭建。
三、Hadoop2.6.5 分布式集群搭建
1、集群的简介
1. hadoop集群
(1) HDFS集群(负责海量数据的存储)
NameNode(老大)
DataNode(小弟)
(2)YARN集群(负责海量数据运算时的资源调度)
ResourceManager (老大)
NodeManager(小弟)
为什么没有MapReduce集群呢?
因为它是一个应用程序开发包
2.集群规划

2、安装包准备
(1)准备安装包:hadoop-2.6.5.tar.gz
(2)上传到 Linux 服务器上去(我的上传目录是/home/cj/Desktop/software/)
(3)把软件解包解压缩到当前目录下,使用命令:
[cj@hadoop01 software]$ tar -zxvf hadoop-2.6.5.tar.gz
3、主要配置文件详解
配置文件所在路径:/home/cj/Desktop/software/hadoop-2.6.5/etc/hadoop
进入到配置文件所在路径
[cj@hadoop01 ~]$cd /home/cj/Desktop/software/hadoop-2.6.5/etc/hadoop
(1)配置环境变量 hadoop-env.sh
编辑配置文件,使用命令:
[cj@hadoop01 hadoop]$ vim hadoop-env.sh

修改完成后保存退出
(2)配置核心组件 core-site.xml
编辑配置文件,使用命令:
[cj@hadoop01 hadoop]$ vim core-site.xml
将如下代码添加到
core-site.xml
fs.defaultFS
hdfs://hadoop01:9000 #HDFS文件系统路径(NameNode所在的路径),默认为file:///
hadoop.tmp.dir
/home/cj/hadoopData/temp #Hadoop运行时产生文件的临时存储目录

修改完成后保存退出。
(3)配置文件系统 hdfs-site.xml
将下面的代码加入
hdfs-site.xml
dfs.namenode.name.dir
/home/cj/hadoopData/name # NameNode存放元数据和日志位置
dfs.datanode.data.dir
/home/cj/hadoopData/data # DataNode存储数据块的目录
dfs.replication
2 # 数据块副本的数量,默认保存3份
dfs.secondary.http.address
hadoop02:50090 # SecondaryNameNode安装节点和默认的web管理端口
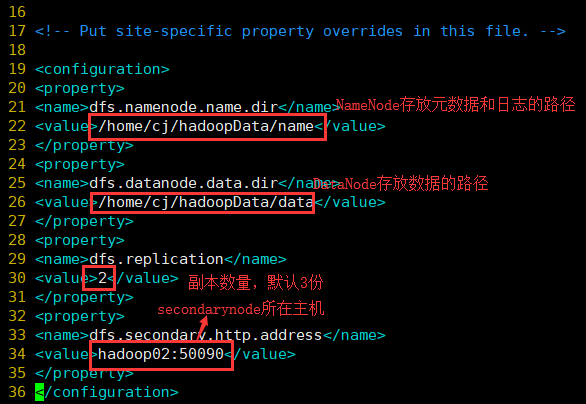
修改好后保存退出。
(4)配置计算框架 mapred-site.xml
1)复制文件,因为目录下只有mapred-site.xml.template,所以我们需要复制一份,使用命令:
[cj@hadoop01 hadoop]$ cp mapred-site.xml.template mapred-site.xml
- 编辑配置文件,使用命令:
[cj@hadoop01 hadoop]$ vim mapred-site.xml
3)将下面的代码加入
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.framework.name:指定使用YARN运行MapReduce程序,默认为local
4)添加完成,保存退出

(5)配置YARN系统 yarn-site.xml
1)编辑配置文件,使用命令:
[cj@hadoop01 hadoop]$ vim yarn-site.xml
2)将下面的代码加入
yarn-site.xml
yarn.resourcemanager.hostname
hadoop01
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname:指定YARN集群老大所在节点
yarn.nodemanager.aux-services:NodeManager上运行的附属服务,也可以理解为reduce获取数据的方式
3)添加完成,保存退出。
如图:

(6) 配置slaves文件
1)编辑配置文件,使用命令:
[cj@hadoop01 hadoop]$ vim slaves
2)将内容修改为(里边会有个localhost,把它删掉):
slaves
hadoop01
hadoop02
hadoop03
记录的是集群里所有DataNode节点
3)修改完成,保存退出。
4、分发到从节点
分别分发到从节点hadoop02和hadoop03上,使用命令:
[cj@hadoop01 Desktop]$ scp -r /home/cj/Desktop/sorftware/ hadoop02:$PWD
[cj@hadoop01 Desktop]$ scp -r /home/cj/Desktop/sorftware/ hadoop03:$PWD
或者用
[cj@hadoop01 ~]$ scp -r /home/cj/Desktop/software/ cj@hadoop02:/home/cj/Desktop/
[cj@hadoop01 ~]$ scp -r /home/cj/Desktop/sorftware cj@hadoop03:/home/cj/Desktop/
两种方式都是可以的
5、配置Hadoop系统环境变量
[cj@hadoop01 ~]$ vim /home/cj/.bash_profile
添加hadoop的安装目录
我的安装目录是/home/cj/Desktop/software/hadoop-2.6.5

添加好后,保存退出。
让配置文件立即生效,使用命令:
[cj@hadoop01 ~]$ source /home/cj/.bash_profile
此时,jdk和hadoop的环境变量都已经配置好了,这时候,就可以把.bash_profiile文件通过scp拷贝给hadoop02和hadoop03了。
[cj@hadoop01 ~]$ scp .bash_profile cj@hadoop02:$PWD
[cj@hadoop01 ~]$ scp .bash_profile cj@hadoop03:$PWD
6、启动Hadoop集群
初始化文件系统
(1)该操作需要在主节点hadoop01上执行,使用命令:
[cj@hadoop01 ~]$ hdfs namenode -format

启动HDFS集群
(1)使用命令:
[cj@hadoop01 ~]$ start-dfs.sh
(2)使用jps查看集群的状态
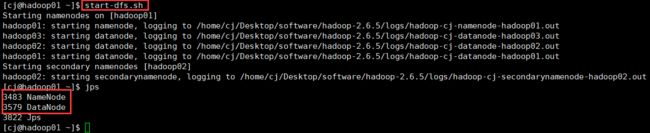
在主节点hadoop01上启动了NameNode守护进程
在3个节点上都启动了DataNode守护进程
在配置的一个特定节点hadoop02上启动SecondaryNameNode 进程

也可以通过UI页面查看:http://hadoop01:50070
或者:http://192.168.157.130:50070,这里的ip是NameNode所在的ip。我的NameNode是放在hadoop01(192.168.157.130)上的。
要想直接用主机名(hadoop01)代替ip,那么除了在linux中的地址映射,还需要在windows的hosts文件中也添加地址映射,windows的hosts配置文件在C:\Windows\System32\drivers\etc下,打开,加入如图红框中的内容
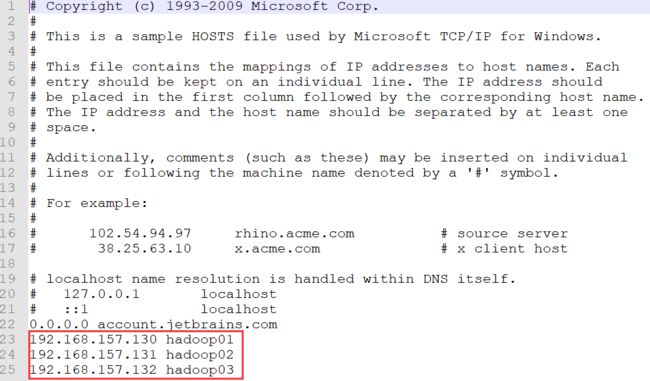
这里这个配置是和linux里的地址映射要保持一致,否则容易乱套了。
添加完成过后,保存。
如果改windows的hosts文件时,提示说权限不够的话,可以先把hosts文件拷贝到桌面,然后再打开加入要加入的,然后再拷贝回去覆盖原来的hosts文件即可。
这时候,就可以通过UI界面查看集群状态了。
输入地址:http://hadoop01:50070
看到的效果:


可以发现这跟我们直接使用命令看到的效果是一样的。
启动yarn集群
使用命令:
[cj@hadoop01 ~]$ start-yarn.sh

可以发现yarn集群的ResourceManager和NodeManager都已经启动起来了。

也可以使用地址:http://hadoop01:8088 通过UI界面来查看集群的信息
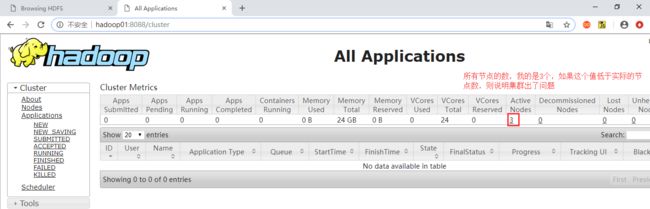
这样hadoop的整个集群就算是跑起来了,也可以去做个例子实验一下,hadoop自带了一些例子,路径是hadoop里边的/share/hadoop/mapreduce/,我的是在/home/cj/Desktop/software/hadoop-2.6.5/share/hadoop/mapreduce,因为我把hadoop解压(安装)到了Desktop的software里边。进入这个路径,可以看到有如下的文件:
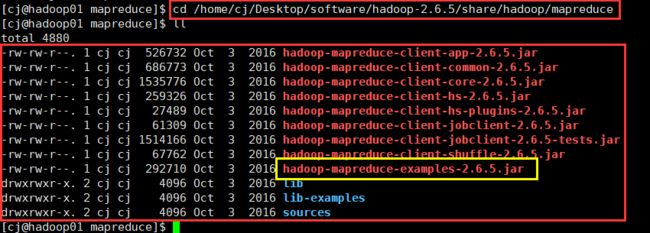
这里用example这个文件做个例子,用来算一下π的值,命令如下:
[cj@hadoop01 ~]$ hadoop jar /home/cj/Desktop/software/hadoop-2.6.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 1 1

这样,hadoop集群就算是搭建完成了。