程序其实就是对数据的增删改查 以及对我们所得的数据进行排序。既然涉及到数据的处理就肯定会要牵扯到排序的算法选择。今天我主要是想分享一下通过自己对一些比较基础的小算法的研究得出了一些算法的应用场景以及某些算法的优缺点。当然这是在特定环境下相对的。如最简单的冒泡排序,我们都知道冒泡排序的算法效率是很低的。但是如果在整个数据大部分已经是有序的情况下,那么它的效率比其他的算法就相对来说会要高出许多。通过这个我只是想阐述我的一个观点:没有最强的算法只有最适合的算法。
下面进入本节的正题,主要采用例子来说明。个人觉得这样更容易让我们联系到场景的应用:
快速简洁-桶排序
一个班级有五个人 他们的考试成绩 5 个同学分别考了 5分、3 分、5 分、2 分和 8 分 如果让您给这五位同学的考试成绩排序您会怎样做?
正常的思维 如果代码要求简单我们可能会采用冒泡排序,如果是对排序效率要求很高的同学可能会采用快速排序,但是当我们写好十几行代码给他们排序之后 我们可能会发现我们仅仅只是需要给五个数排序。有没有杀鸡用牛刀的感觉~~
通过上面的数字特点我们可以发现这些数字存在某些特点:数字都是小于10而且分数都是整数 离散区间比较小。这时我们何不定义一个从1-10的数组
int[ ] a = new int[10];
a[5] = a[5]+1;
a[3] = a[3]+1;
a[5] = a[5]+1;
a[2] = a[2]+1;
a[8] = a[8]+1;
这样我们只要循环一次这个数组即可 数组的值代表这个下标的值出现了几次 这样我们就给这一序列的数字排好序了。这也就是最简单的桶排序。桶排序从 1956 年就开始被使用,该算法的基本思想是由E.J.Issac 和 R.C.Singleton提出来的。当然桶排序也有它的缺陷,如果数的离散区间过大那么采用桶排序就显得有点浪费空间了。例如需要排序数的范围是 0~2100000000 之间,那你则需要申请 2100000001 个变量,也就是说要写成 int a[2100000001]。因为我们需要用 2100000001 个“桶”来存储 0~2100000000 之间每一个数出现的次数。即便只给你 5 个数进行排序(例如这 5 个数是 1、1912345678、2100000000、18000000 和 912345678),你也仍然需要 2100000001 个“桶”,这真是太浪费空间了!还有,如果现在需要排序的不再是整数而是一些小数,比如将 5.56789、2.12、1.1、3.123、4.1234这五个数进行从小到大排序又该怎么办呢?接下来我们就可以采用冒泡排序可以很好的解决这个问题
邻居好说话——冒泡排序
冒泡排序的基本思想是:每次比较两个相邻的元素,如果它们的顺序错误就把它们交换过来。
例如我们需要将 12 35 99 18 76 这 5个数进行从大到小的排序。
首先比较第 1 位和第 2 位的大小,现在第 1 位是 12,第 2 位是 35。发现 12比 35 要小,因为我们希望越小越靠后嘛,因此需要交换这两个数的位置。交换之后这 5 个数的顺序是35 12 99 18 76。按照刚才的方法,继续比较第 2 位和第 3 位的大小,第 2位是 12,第 3位是 99。12比99 要小,因此需要交换这两个数的位置。交换之后这 5 个数的顺序是 35 99 12 18 76。根据刚才的规则,继续比较第 3 位和第 4 位的大小,如果第 3 位比第 4 位小,则交换位置。交换之后这 5 个数的顺序是 35 99 18 12 76。最后,比较第 4 位和第 5 位。4 次比较之后 5 个数的顺序是 35 99 18 76 12。经过 4 次比较后我们发现最小的一个数已经就位(已经在最后一位,请注意 12 这个数的移动过程),是不是很神奇。现在再来回忆一下刚才比较的过程。每次都是比较相邻的两个数,如果后面的数比前面的数大,则交换这两个数的位置。一直比较下去直到最后两个数比较完毕后,最小的数就在最后一个了。就如同是一个气泡,一步一步往后“翻滚”,直到最后一位。所以这个排序的方法有一个很好听的名字“冒泡排序”。“冒泡排序”的原理是:每一趟只能确定将一个数归位。
代码实现:
#includeint main()
{
int a[100],i,j,t,n;
scanf("%d",&n); //输入一个数n,表示接下来有n个数
for(i=1;i<=n;i++) //循环读入n个数到数组a中
scanf("%d",&a[i]);
//冒泡排序的核心部分
for(i=1;i<=n-1;i++) //n个数排序,只用进行n-1趟
{
for(j=1;j<=n-i;j++)
//从第1位开始比较直到最后一个尚未归位的数,想一想为什么到n-i就可以了。
{
if(a[j] >a[j+1]) //比较大小并交换
{ t=a[j]; a[j]=a[j+1]; a[j+1]=t; }
}
}
for(i=1;i<=n;i++) //输出结果
printf("%d ",a[i]);
getchar();getchar();
return 0;
}
注意:冒泡排序的核心部分是双重嵌套循环。不难看出冒泡排序的时间复杂度是 O(N 2 )。这是一个非常高的时间复杂度。这里可以看出冒泡排序在处理一般的排序的时候,时间复杂度是相当 高的一般情况是不推荐的,那么肯定有人会问那为什么要说,那是因为冒泡排序在大多数情况下效率低下,但是在如果一个数列本身大部分已经高度有序的情况下,那么它在这种情况下排序的效率又是惊人的。所以说任何事物没有绝对的好坏,存在即有它的道理。看到这里读者可能已经被这简单的排序弄得昏昏欲睡了,不是难而是太小儿科了。看官不要走开接下来还有:
最常用的排序——快速排序
上面的冒泡排序虽然解决了桶排序的空间浪费问题,但是在算法效率上却牺牲了很多它的时间复杂度达到了 O(N 2 )。假如我们的计算机每秒钟可以运行 10 亿次,那么对 1 亿个数进行排序,桶排序只需要 0.1 秒,而冒泡排序则需要 1 千万秒,达到 115 天之久,是不是很吓人?快速排序在这样的情况下就应运而生。即解决了效率低下又浪费空间的问题。可以说快速排序是19实际最伟大的算法之一,一直到现在我们都可以看到很多程序中依然采用这个排序方法。
快速排序之所以比较快,是因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样只能在相邻的数之间进行交换,交换的距离就大得多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的,都是 O(N 2 ),它的平均时间复杂度为 O (NlogN)。其实快速排序是基于一种叫做“二分”的思想。
好了话不多说 让我们采用鲜活的例子来助大家理解:
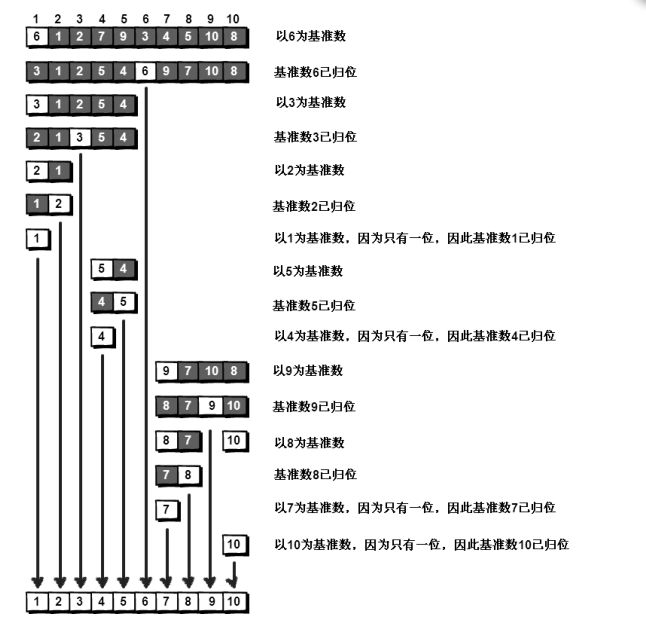
假设我们现在对“6 1 2 7 9 3 4 5 10 8”这 10个数进行排序。首先在这个序列中随便找一个数作为基准数(不要被这个名词吓到了,这就是一个用来参照的数,待会儿你就知道它用来做啥了)。为了方便,就让第一个数 6 作为基准数吧。接下来,需要将这个序列中所有比基准数大的数放在 6 的右边,比基准数小的数放在 6 的左边,类似下面这种排列。
3 1 2 5 4 6 9 7 10 8
在初始状态下,数字 6在序列的第 1 位。我们的目标是将 6挪到序列中间的某个位置,假设这个位置是 k。现在就需要寻找这个 k,并且以第 k 位为分界点,左边的数都小于等于 6,右边的数都大于等于 6。想一想,你有办法可以做到这点吗?方法其实很简单:分别从初始序列“6 1 2 7 9 3 4 5 10 8”两端开始“探测”。先从右往左找一个小于 6 的数,再从左往右找一个大于 6 的数,然后交换它们。这里可以用两个变量 i 和 j,分别指向序列最左边和最右边。我们为这两个变量起个好听的名字“哨兵 i”和“哨兵 j”。刚开始的时候让哨兵 i 指向序列的最左边(即 i=1),指向数字 6。让哨兵 j 指向序列的最右边(即 j=10),指向数字 8。
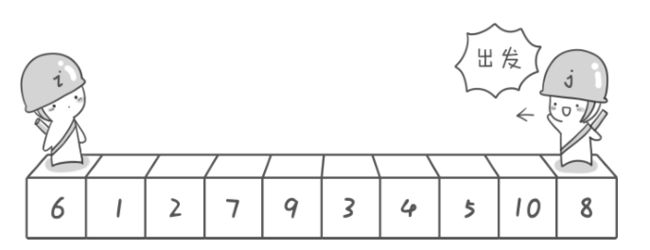
首先哨兵 j 开始出动。因为此处设置的基准数是最左边的数,所以需要让哨兵 j 先出动,这一点非常重要(请自己想一想为什么)。哨兵 j 一步一步地向左挪动(即 j),直到找到一个小于 6的数停下来。接下来哨兵 i 再一步一步向右挪动(即 i++),直到找到一个大于 6的数停下来。最后哨兵 j 停在了数字 5 面前,哨兵 i 停在了数字 7 面前。
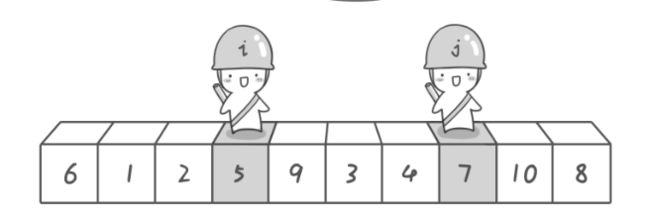
现在交换哨兵 i 和哨兵 j所指向的元素的值。交换之后的序列如下。
6 1 2 5 9 3 4 7 10 8
到此,第一次交换结束。接下来哨兵 j 继续向左挪动(再次友情提醒,每次必须是哨兵j 先出发)。他发现了 4(比基准数 6 要小,满足要求)之后停了下来。哨兵 i 也继续向右挪动,他发现了 9(比基准数 6 要大,满足要求)之后停了下来。此时再次进行交换,交换之后的序列如下。
6 1 2 5 4 3 9 7 10 8

第二次交换结束,“探测”继续。哨兵 j 继续向左挪动,他发现了 3(比基准数 6 要小,满足要求)之后又停了下来。哨兵 i 继续向右移动,糟啦!此时哨兵 i 和哨兵 j 相遇了,哨兵 i 和哨兵 j 都走到 3 面前。说明此时“探测”结束。我们将基准数 6 和 3 进行交换。交换之后的序列如下。
3 1 2 5 4 6 9 7 10 8
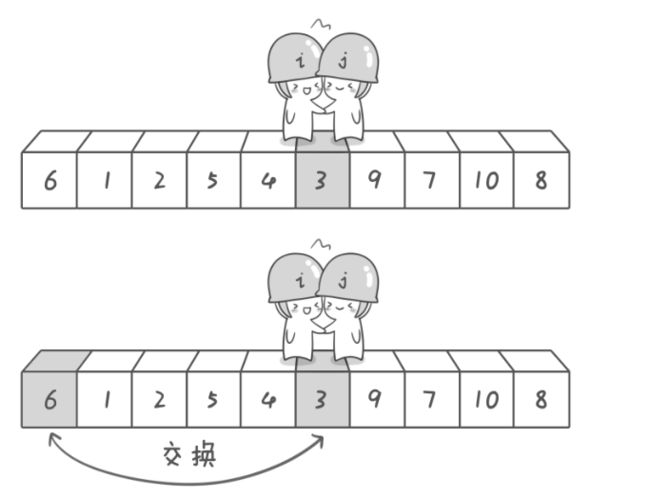
到此第一轮“探测”真正结束。此时以基准数 6 为分界点,6 左边的数都小于等于 6,6右边的数都大于等于 6。回顾一下刚才的过程,其实哨兵 j 的使命就是要找小于基准数的数,而哨兵 i 的使命就是要找大于基准数的数,直到 i 和 j 碰头为止。OK,解释完毕。现在基准数 6 已经归位,它正好处在序列的第 6 位。此时我们已经将原来的序列,以 6 为分界点拆分成了两个序列,左边的序列是“3 1 2 5 4”,右边的序列是“9 7 10 8”。接下来还需要分别处理这两个序列,因为 6 左边和右边的序列目前都还是很混乱的。不过不要紧,我们已经掌握了方法,接下来只要模拟刚才的方法分别处理 6 左边和右边的序列即可。现在先来处理 6 左边的序列吧。左边的序列是“3 1 2 5 4”。请将这个序列以 3为基准数进行调整,使得 3 左边的数都小于等于 3,3 右边的数都大于等于 3
上一个排序的过程图:
由于上面冒泡采用的是c写的所以下面用java代码:
int[] a = {3 ,1, 2 ,5, 4,6,9 ,7 ,10, 8}
public static void quickF(int[] a,int start,int end){
if(start < end){
// 如果左边下标小于右边下标则可以继续
int mid = QuickSort.getMid(a, start, end);
quickF(a,start,mid);
quickF(a,mid+1,end);
}
}
public static int getMid(int[] a,int start,int end ){
// 经过第一次循环将以左边的基准点的数为准 将比这个数大的 和比这个数小的数进行区分开
int low = start;
int tmp = a[start];// 以这个数作为基准数
while(start < end ){
// 首先先从右边的数开始比较
while(start < end && a[end] >= tmp){
end--;
}
// 以左边的数开始比较
while(start < end && a[start] <= tmp){
start++;
}
// 将两个数进行交换
int t = 0;
t = a[end];
a[end] = a[start];
a[start] = t;
}
// 全部交换完了 最后在将基准点的数 与左边的数进行交换
a[low] = a[end];
a[end] = tmp;
return end;
}
public static void main(String[] args) {
long startTime=System.nanoTime(); //获取开始时间
QuickSort.quickF(a, 0, a.length-1);
for (int i : a) {
System.out.print(i+",");
}
long endTime=System.nanoTime(); //获取结束时间
System.out.println("程序运行时间: "+(endTime-startTime)+"ms");
}
简介:快速排序由 C. A. R. Hoare(东尼·霍尔,Charles Antony Richard Hoare)在 1960 年提出,之后又有许多人做了进一步的优化。如果你对快速排序感兴趣,可以去看看东尼·霍尔1962 年在 Computer Journal 发表的论文“Quicksort”以及《算法导论》的第七章。
由于时间的缘故本来还要唠嗑一下堆排序,这个也是号称有最高效排序之称,仅仅比快速排序低一点点,但是在插入数据 删除数据之后在排序,那几乎是无人可敌。这个经典的算法下一期在介绍。如果您对我的有任何意见欢迎您给我留言。