「The Algorithm Design Manual」一书中提到,雅虎的 Chief Scientist ,Udi Manber 曾说过:
在 yahoo 所应用的算法中,最重要的三个是:Hash,Hash 和 Hash。
例如:git用sha1判断文件更改,密码用MD5生成摘要后加盐等等对Hash的应用可看出,Hash的在计算机世界扮演着多么重要的角色。无论是密码学、数据结构、现实生活中的应用,到处可以看到Hash的影子
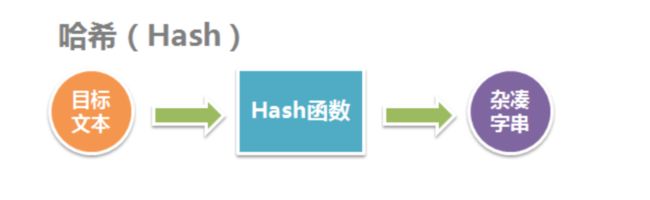
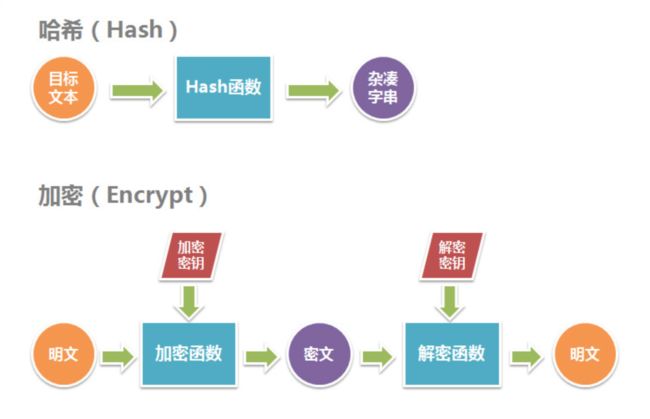
一切皆是映射:
哈希函数(Hash Function),也称为散列函数或杂凑函数。哈希函数是一个公开函数,可以将任意长度的消息M映射成为一个长度较短且长度固定的值H(M),称H(M)为哈希值、散列值(Hash Value)、杂凑值或者消息摘要(Message Digest)。它是一种单向密码体制,即一个从明文到密文的不可逆映射,只有加密过程,没有解密过程。
它的函数表达式为:h=H(m)
无论输入是什么数字格式、文件有多大,输出都是固定长度的比特串。以比特币使用的Sh256算法为例,无论输入是什么数据文件,输出就是256bit。
每个bit就是一位0或者1,256bit就是256个0或者1二进制数字串,用16进制数字表示的话,就是多少位呢?
16等于2的4次方,所以每一位16进制数字可以代表4位bit。那么,256位bit用16进制数字表示,当然是256除以4等于64位。
于是你通常看到的哈希值,就是这样的了:
00740f40257a13bf03b40f54a9fe398c79a664bb21cfa2870ab07888b21eeba8
二进制计算的一些基础知识
<< : 左移运算符,num << 1,相当于num乘以2 低位补0
>> : 右移运算符,num >> 1,相当于num除以2 高位补0
>>> : 无符号右移,忽略符号位,空位都以0补齐
% : 模运算 取余
^ : 位异或 第一个操作数的的第n位于第二个操作数的第n位相反,那么结果的第n为也为1,否则为0
& : 与运算 第一个操作数的的第n位于第二个操作数的第n位如果都是1,那么结果的第n为也为1,否则为0
| : 或运算 第一个操作数的的第n位于第二个操作数的第n位 只要有一个是1,那么结果的第n为也为1,否则为0
~ : 非运算 操作数的第n位为1,那么结果的第n位为0,反之,也就是取反运算(一元操作符:只操作一个数)
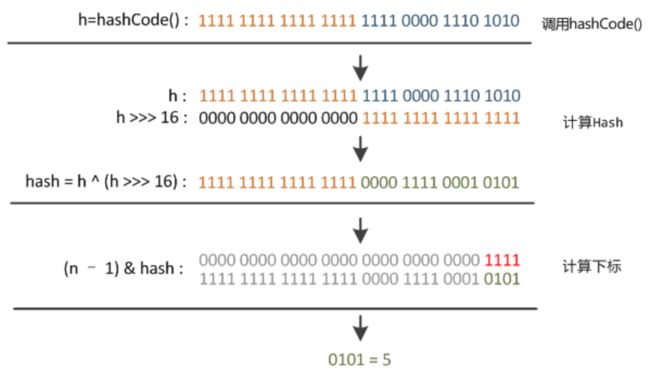
为什么使用 hashcode ,hashCode 存在的第一重要的原因就是在 HashMap(HashSet 其实就是HashMap) 中使用(其实Object 类的 hashCode 方法注释已经说明了 ),我知道,HashMap 之所以速度快,因为他使用的是散列表,根据 key 的 hashcode 值生成数组下标(通过内存地址直接查找,没有任何判断),时间复杂度完美情况下可以达到 O(1), 和数组相同,但是比数组用着爽多了,但是需要多出很多内存,相当于以空间换时间。
Horner计算字符串哈希值的方法,公式为:
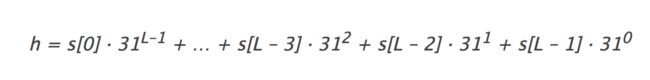
举个例子,比如要获取”call”的哈希值,字符串c对应的unicode为99,a对应的unicode为97,L对应的unicode为108,所以字符串”call”的哈希值为
3045982 = 99·313 + 97·312 + 108·311 + 108·310 = 108 + 31· (108 + 31 · (97 + 31 · (99)))
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
用 String 的 char 数组的数字每次乘以 31 再叠加最后返回,因此,每个不同的字符串,返回的 hashCode 肯定不一样。那么为什么使用 31 呢?
之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5) - i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
哈希表就是一种以 键-值(key-indexed) 存储数据的结构,我们只要输入待查找的值即key,即可查找到其对应的值。
哈希的思路很简单,如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现:将键作为索引,值即为其对应的值,这样就可以快速访问任意键的值。这是对于简单的键的情况,我们将其扩展到可以处理更加复杂的类型的键。
使用哈希查找有两个步骤:
1.使用哈希函数将被查找的键转换为数组的索引。在理想的情况下,不同的键会被转换为不同的索引值,但是在有些情况下我们需要处理多个键被哈希到同一个索引值的情况。所以哈希查找的第二个步骤就是处理冲突
2.处理哈希碰撞冲突。有很多处理哈希碰撞冲突的方法,本文后面会介绍拉链法和线性探测法。
哈希表是一个在时间和空间上做出权衡的经典例子。如果没有内存限制,那么可以直接将键作为数组的索引。那么所有的查找时间复杂度为O(1);如果没有时间限制,那么我们可以使用无序数组并进行顺序查找,这样只需要很少的内存。哈希表使用了适度的时间和空间来在这两个极端之间找到了平衡。只需要调整哈希函数算法即可在时间和空间上做出取舍。
通过哈希函数,我们可以将键转换为数组的索引(0-M-1),但是对于两个或者多个键具有相同索引值的情况,我们需要有一种方法来处理这种冲突。
一种比较直接的办法就是,将大小为M 的数组的每一个元素指向一个条链表,链表中的每一个节点都存储散列值为该索引的键值对,这就是拉链法。
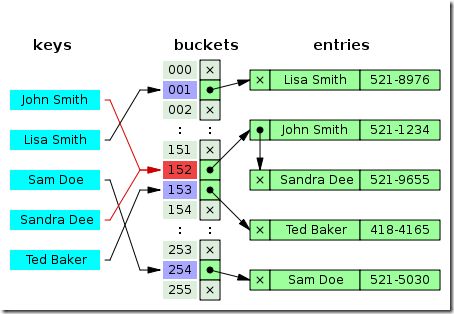
Hash有哪些流行的算法?
目前流行的 Hash 算法包括 MD5、SHA-1 和 SHA-2。
MD4(RFC 1320)是 MIT 的 Ronald L. Rivest 在 1990 年设计的,MD 是 Message Digest 的缩写。其输出为 128 位。MD4 已证明不够安全。
MD5(RFC 1321)是 Rivest 于1991年对 MD4 的改进版本。它对输入仍以 512 位分组,其输出是 128 位。MD5 比 MD4 复杂,并且计算速度要慢一点,更安全一些。MD5 已被证明不具备”强抗碰撞性”。
SHA (Secure Hash Algorithm)是一个 Hash 函数族,由 NIST(National Institute of Standards and Technology)于 1993 年发布第一个算法。目前知名的 SHA-1 在 1995 年面世,它的输出为长度 160 位的 hash 值,因此抗穷举性更好。SHA-1 设计时基于和 MD4 相同原理,并且模仿了该算法。SHA-1 已被证明不具”强抗碰撞性”。
为了提高安全性,NIST 还设计出了 SHA-224、SHA-256、SHA-384,和 SHA-512 算法(统称为 SHA-2),跟 SHA-1 算法原理类似。SHA-3 相关算法也已被提出。
可以看出,上面这几种流行的算法,它们最重要的一点区别就是”强抗碰撞性”。
HashMap与ArrayList和LinkedList在数据复杂度上有什么区别?
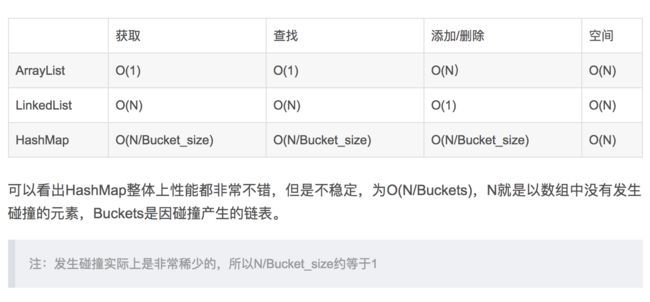
HashMap是对Array与Link的折衷处理,Array与Link可以说是两个速度方向的极端,Array注重于数据的获取,而处理修改(添加/删除)的效率非常低;Link由于是每个对象都保持着下一个对象的指针,查找某个数据需要遍历之前所有的数据,所以效率比较低,而在修改操作中比较快。