Java篇--JVM三(垃圾回收GC)
文章目录
-
-
-
- 一、前言
- 二、垃圾回收算法
-
- 1.判定对象是否是垃圾的标准
- 2.判定对象是否是垃圾的算法
-
- (1)引用计数算法
- (2)可达性分析算法
- 3.谈谈你所了解的垃圾回收算法
-
- (1)标记-清除算法:Mark and Sweep
- (2)复制:Copying
- (3)标记-整理算法:
- (4)分代收集算法:
- 三、垃圾收集器
-
- 1.串行收集器:
-
- (1)Serial
- (2)Serial Old
- 2.并行收集器(吞吐量优先):
-
- (1)ParNew
- (2)Parallel Scavenge
- (3)Parallel Old
- 3.并发收集器(停顿时间优先):
-
- (1)CMS收集器(Concurrent Mark Sweep)
- (2)G1(Garbage-First)收集器
- 四、总结
-
- 1.Minor GC 和 Full GC 有什么区别?
- 2.内存分配规则:
- 3.优秀的编程习惯:
- 4.XX参数语法:
-
-
一、前言
垃圾收集Garbage Collection通常被称为“GC”,顾名思义就是释放垃圾占用的空间,防止内存泄露。在jvm中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于Java堆和方法区中,在程序运行期间,这部分内存的分配和使用都是动态的。
为什么要进行垃圾回收?随着程序的运行,内存中存在的实例对象、变量等信息占据的内存越来越多,如果不及时进行垃圾回收,必然会带来程序性能的下降,甚至会因为可用内存不足造成一些不必要的系统异常。
二、垃圾回收算法
1.判定对象是否是垃圾的标准
一个对象是否被其他对象所引用。
2.判定对象是否是垃圾的算法
(1)引用计数算法
每个对象添加一个引用计数器,每被引用一次,计数器加1,失去引用,计数器减1,当计数器在一段时间内保持为0时,该对象就认为是可以被回收得了。(在JDK1.2之前,使用的是该算法)
缺点:无法解决循环引用的问题。当两个对象A、B相互引用的时候,当其他所有的引用都消失之后,A和B还有一个相互引用,此时计数器各为1,而实际上这两个对象都已经没有额外的引用了,已经是垃圾了。但是却不会被回收。举例:
public class ReferenceCountingGC {
public Object instance;
public ReferenceCountingGC(String name) {
}
public static void testGC(){
ReferenceCountingGC a = new ReferenceCountingGC("objA");
ReferenceCountingGC b = new ReferenceCountingGC("objB");
a.instance = b;
b.instance = a;
a = null;
b = null;
}
}
(2)可达性分析算法
程序把所有的引用关系看作一张图,从一个节点GC ROOT 开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点。

目前java 中可作为GC Root 的对象有:
- 虚拟机栈中引用的对象。比如:各个线程当中被调用的方法中使用到的参数、局部变量等。
- 方法区中静态属性引用的对象。比如:Java类的引用类型静态变量
- 方法区中常量引用的对象。
- 本地方法栈中引用的对象(Native Object)
3.谈谈你所了解的垃圾回收算法
在确定了哪些垃圾可以被回收后,垃圾收集器要做的事情就是开始进行垃圾回收,但是这里面涉及到一个问题是:如何高效地进行垃圾回收。这里我们讨论几种常见的垃圾收集算法的核心思想。
评价一个垃圾收集GC算法的两个标准:吞吐量(throughput)越高算法越好;暂停时间(pause times)越短算法越好
(1)标记-清除算法:Mark and Sweep

标记清除算法(Mark-Sweep)是最基础的一种垃圾回收算法,它分为2部分,先把内存区域中的这些对象进行标记,哪些属于可回收标记出来,然后把这些垃圾拎出来清理掉。就像上图一样,清理掉的垃圾就变成未使用的内存区域,等待被再次使用。但它存在一个很大的问题,那就是内存碎片。
上图中等方块的假设是2M,小一些的是1M,大一些的是4M。等我们回收完,内存就会切成了很多段。我们知道开辟内存空间时,需要的是连续的内存区域,这时候我们需要一个2M的内存区域,其中有2个1M是没法用的。这样就导致,其实我们本身还有这么多的内存的,但却用不了。
(2)复制:Copying
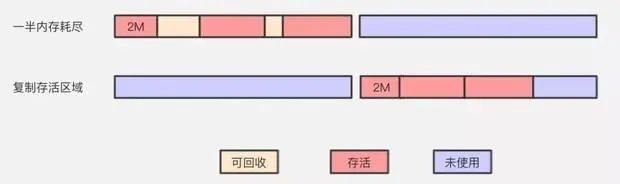
复制算法(Copying)是在标记清除算法基础上演化而来,解决标记清除算法的内存碎片问题。它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。保证了内存的连续可用,内存分配时也就不用考虑内存碎片等复杂情况。复制算法暴露了另一个问题,例如硬盘本来有500G,但却只能用200G,代价实在太高。
对象存活率低的场景:年轻代。java中新生代的from和to空间就是使用这个算法
(3)标记-整理算法:

标记-整理算法标记过程仍然与标记-清除算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,再清理掉端边界以外的内存区域。
标记整理算法解决了内存碎片的问题,也规避了复制算法只能利用一半内存区域的弊端。标记整理算法对内存变动更频繁,需要整理所有存活对象的引用地址,在效率上比复制算法要差很多。
适用于对象存活率比较高的场景:老年代
(4)分代收集算法:
分代收集算法,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点使用不同的回收算法,以提高垃圾回收的效率。
在Java程序运行的过程中,会产生大量的对象,其中有些对象是与业务信息相关,比如Http请求中的Session对象、线程、Socket连接, 这类对象跟业务直接挂钩,因此生命周期比较长。但是还有一些对象,主要是程序运行过程中生成的临时变量,这些对象生命周期会比较短,比如: String对象, 由于其不变类的特性,系统会产生大量的这些对象,有些对象甚至只用一次即可回收。
在新生代中,每次垃圾收集时都发现有大批对象死去(回收频率很高),只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。其中,新生代又细分为三个区:Eden,From Survivor,ToSurviver,比例是8:1:1。
老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
分代的思想被现有的虚拟机广泛使用。几乎所有的垃圾回收器都区分新生代和老年代。
三、垃圾收集器
前面所讲的垃圾回收算法还停留在算法层面,有算法我们就得有类似的实现,我们要使用编程语言把这个算法实现出来,这就是我们所谓的垃圾收集器。
1.串行收集器:
使用单线程进行垃圾回收的收集器,每次回收时,串行收集器只有一个工作线程,对于并行能力较弱的计算机来说,串行收集器的专注性和独占性往往有更好的性能表现。串行收集器可以在新生代和老年代中使用,根据作用于不同的堆空间,分为新生代串行收集器和老年代串行收集器。
-XX:+UseSerialGC:新生代串行
-XX:+UseSerialOldGC:老年代串行
(1)Serial
是一个新生代收集器,单线程执行,使用复制算法。它在进行垃圾收集时,必须暂停其他所有的工作线程(用户线程)。是Jvm client模式下默认的新生代收集器。对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。
(2)Serial Old
Serial收集器的老年代版本,它同样是一个单线程收集器,使用“标记-整理”算法。
2.并行收集器(吞吐量优先):
指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
-XX:+UseParNewGC:新生代并行(ParNew),老年代串行(Serial Old)
-XX:+UseParallelGC:新生代使用并行回收收集器,老年代使用串行收集器
-XX:+UseParallelOldGC:新生代和老年代都使用并行回收收集器
(1)ParNew
新生代,复制算法
(2)Parallel Scavenge
新生代,复制算法
(3)Parallel Old
老年代,标记整理算法
3.并发收集器(停顿时间优先):
指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行,而垃圾收集程序运行于另一个CPU上。适用于响应时间有要求的场景web。
-XX:+UseConcurrentMarkSweepGC
-XX:+UseG1GC
(1)CMS收集器(Concurrent Mark Sweep)
老年代,标记清除算法
(2)G1(Garbage-First)收集器
当今收集器技术发展的最前沿成果之一。2004年Sun发表了第一篇G1的论文,到2006年左右,在JDK6内集成进去了。JDK7才放出来。
优势(集中了前面所有收集器的优点):G1能充分利用了多核的并行特点,能缩短停顿时间(充分利用多CPU、多核环境下的硬件优势);分代收集(不需要其他收集器配合就能独立管理整个GC堆);空间整合(类似于标记清理算法);可预测的停顿(能让使用者明确指定在一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得超过N毫秒)
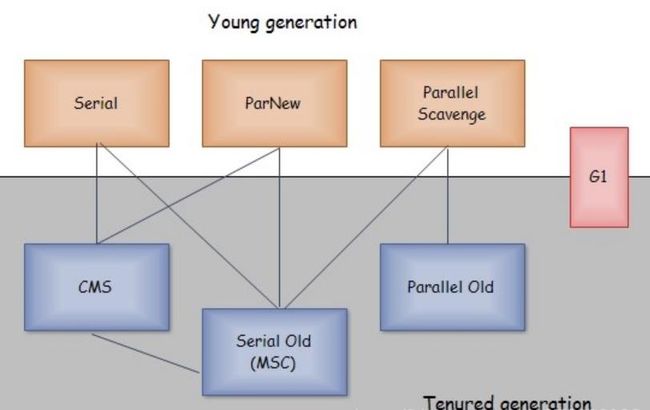
上面有7种收集器,分为两块,上面为新生代收集器,下面是老年代收集器。如果两个收集器之间存在连线,就说明它们可以搭配使用。
四、总结
1.Minor GC 和 Full GC 有什么区别?
新生代 GC (Minor GC) :发生在新生代的垃圾收集动作。Minor GC 非常频繁,回收速度比较快。
老年代 GC (Major GC/Full GC):发生在老年代的 GC, Major GC 一般比 Minor GC 慢 10 倍以上。
2.内存分配规则:
对象优先在 Eden 分配。大多数情况下,对象在新生代 Eden 区中分配。当 Eden 区没有足够空间进行分配时,虚拟机将发起 Minor GC。
3.优秀的编程习惯:
(1)避免在循环体中创建对象,即使该对象占用内存空间不大。
(2)尽量及时使对象符合垃圾回收标准。
(3)不要采用过深的继承层次。
(4)访问本地变量优于访问类中的变量。
4.XX参数语法:
所有的XX参数都以”-XX:”开始,但是随后的语法不同,取决于参数的类型。
对于布尔类型的参数,我们有”+”或”-“,然后才设置JVM选项的实际名称。例如,-XX:+用于激活选项,而-XX:-用于注销选项。
对于需要非布尔值的参数,如string或者integer,我们先写参数的名称,后面加上”=”,最后赋值。例如, -XX:=给赋值。
参考:
https://www.cnblogs.com/godoforange/p/11552865.html
https://www.cnblogs.com/yanl55555/p/13355350.html
https://blog.csdn.net/w372426096/article/details/81360083
https://www.jianshu.com/p/23f8249886c6