【全网详解】从0到1搭建双十一实时交易数据展示平台——Spark+Kafka构建实时分析系统
目录
万事具备之巧借东风
预备知识
环境搭建
Spark安装
Kafka安装
Kafka核心知识介绍
Kafka开启及测试服务
Python依赖库
PyCharm安装
搭建总结
八仙过海之各显神通
数据预处理
运行效果代码
代码展示
神笔马良之画龙点睛
Spark Streaming实时处理数据
配置Spark开发Kafka环境
建立pyspark项目
华佗在世之妙手回春
结果展示之移花接木
app.py(直接运行)
index.html
总结
每文一语
万事具备之巧借东风
预备知识
Linux系统命令使用、了解如何安装Python库、安装kafka。
熟悉Linux基本操作、Pycharm的安装、Spark安装,Kafka安装
环境搭建
Spark安装
至于如何安装好spark,我这里就不详细介绍了,请点击标题,即可跳转到文章详情页,里面有spark的安装资料和教程。
Kafka安装
点击此处下载,下载kafka_2.11-2.4.0.tgz。此安装包内已经附带zookeeper,不需要额外安装zookeeper.按顺序执行如下步骤:
首先将下载好的安装包放在我们虚拟机里面(Ubuntu)
使用命令进行解压
sudo tar -zxf /home/hadoop/kafka/kafka_2.11-2.4.0.tgz -C /home/hadoop/kafka
解压成功之后,需要我们对其进行改名,方便我们后续的操作
cd /home/hadoop/kafkasudo mv kafka_2.11-2.4.0/ kafka
Kafka核心知识介绍
下面介绍Kafka相关概念,以便运行下面实例的同时,更好地理解Kafka.
1. Broker
Kafka集群包含一个或多个服务器,这种服务器被称为broker
2. Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
3. Partition
Partition是物理上的概念,每个Topic包含一个或多个Partition.
4. Producer
负责发布消息到Kafka broker
5. Consumer
消息消费者,向Kafka broker读取消息的客户端。
6. Consumer Group
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
Kafka开启及测试服务
接下来在Ubuntu系统环境下测试简单的实例。Mac系统请自己按照安装的位置,切换到相应的指令。按顺序执行如下命令:
进入kafka所在的目录
cd /home/hadoop/kafka/kafka输入该命令
bin/zookeeper-server-start.sh config/zookeeper.properties命令执行后不会返回Shell命令输入状态,zookeeper就会按照默认的配置文件启动服务,请千万不要关闭当前终端.启动新的终端,输入如下命令:
cd /home/hadoop/kafka/kafkabin/kafka-server-start.sh config/server.propertieskafka服务端就启动了,请千万不要关闭当前终端。启动另外一个终端,输入如下命令(测试):
cd /home/hadoop/kafka/kafkabin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dblab
注意上面的步骤顺序缺一不可:初学者,千万要记住,先启动zookeeper,再启动kafka,这个很重要,不然会出错,切记!!!
topic是发布消息发布的category,以单节点的配置创建了一个叫dblab的topic.可以用list列出所有创建的topics,来查看刚才创建的主题是否存在。
bin/kafka-topics.sh --list --zookeeper localhost:2181可以在结果中查看到dblab这个topic存在

接下来用producer生产点数据:
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic dblab并尝试输入如下信息:

然后再次开启新的终端或者直接按CTRL+C退出。然后使用consumer来接收数据,输入如下命令:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic dblab --from-beginning 便可以看到刚才产生的信息。说明kafka安装成功!!!

Python依赖库
本项目主要使用了两个Python库,Flask和Flask-SocketIO,这两个库的安装非常简单,请启动进入Ubuntu系统,打开一个命令行终端(可以使用快捷键Ctrl+Alt+T)。
Python之所以强大,其中一个原因是其丰富的第三方库。pip则是python第三方库的包管理工具。Python3对应的包管理工具是pip3。因此,需要首先在Ubuntu系统中安装pip3,命令如下
sudo apt-get install python3-pip安装完pip3以后,可以使用如下Shell命令完成Flask和Flask-SocketIO这两个Python第三方库的安装以及与Kafka相关的Python库的安装:
pip3 install flask
pip3 install flask-socketio
pip3 install kafka-python这些安装好的库在我们的程序文件的开头可以直接用来引用。比如下面的例子。
from flask import Flask
from flask_socketio import SocketIO
from kafka import KafkaConsumerfrom import 跟直接import的区别举个例子来说明。
import socket的话,要用socket.AF_INET,因为AF_INET这个值在socket的名称空间下。
from socket import* 是把socket下的所有名字引入当前名称空间。
但是对于本次项目,我们使用的是pycharm开发工具,所以可以不用这样,我们直接使用anaconda里面的安装命令,这样更加的快捷。
PyCharm安装
pycharm的详解安装步骤,在之前就已经介绍的非常详细了,这里只需要点击标题即可
搭建总结
搭建成功我们就可以把我们的项目引入进来
首先利用pycharm,我们要安装第三方库
pip --default-timeout=100 install kafka -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com安装其他的第三方库,反正没有的都可以自己安装!
pip install flask_socketio
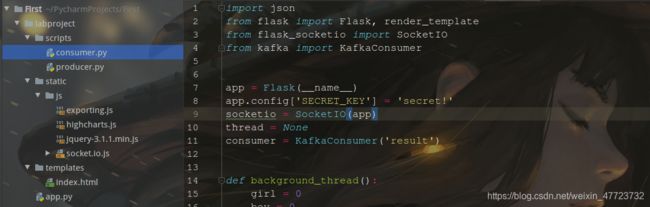
这里先给出本项目Python工程的目录结构,后续的操作可以根据这个目录进行操作
Python工程目录结构
- data目录存放的是用户日志数据;
- scripts目录存放的是Kafka生产者和消费者;
- static/js目录存放的是前端所需要的js框架;
- templates目录存放的是html页面;
- app.py为web服务器,接收Spark Streaming处理后的结果,并推送实时数据给浏览器;
至此,本项目需要的开发环境及搭建就介绍完毕!
八仙过海之各显神通
数据预处理
数据集介绍
本项目的数据集压缩包为data数据集,有需要的可以在评论区留言QQ邮箱:[email protected]
该数据集压缩包是淘宝2015年双11前6个月(包含双11)的交易数据(交易数据有偏移,但是不影响实验的结果),里面包含3个文件,分别是用户行为日志文件user_log.csv 、回头客训练集train.csv 、回头客测试集test.csv. 在这个项目中只是用user_log.csv这个文件,下面列出文件user_log.csv的数据格式定义:
用户行为日志user_log.csv,日志中的字段定义如下:
1. user_id | 买家id
2. item_id | 商品id
3. cat_id | 商品类别id
4. merchant_id | 卖家id
5. brand_id | 品牌id
6. month | 交易时间:月
7. day | 交易事件:日
8. action | 行为,取值范围{0,1,2,3},0表示点击,1表示加入购物车,2表示购买,3表示关注商品
9. age_range | 买家年龄分段:1表示年龄<18,2表示年龄在[18,24],3表示年龄在[25,29],4表示年龄在[30,34],5表示年龄在[35,39],6表示年龄在[40,49],7和8表示年龄>=50,0和NULL则表示未知
10. gender | 性别:0表示女性,1表示男性,2和NULL表示未知
11. province| 收获地址省份
数据具体格式如下:
user_id,item_id,cat_id,merchant_id,brand_id,month,day,action,age_range,gender,province328862,844400,1271,2882,2661,08,29,0,1,1,山西这个项目实时统计每秒中男女生购物人数,因此针对每条购物日志,我们只需要获取gender即可,然后发送给Kafka,接下来Spark Streaming再接收gender进行处理。
数据预处理
本项目使用Python对数据进行预处理,并将处理后的数据直接通过Kafka生产者发送给Kafka,这里需要先安装Python操作Kafka的代码库,请在Ubuntu中打开一个命令行终端,执行如下Shell命令来安装Python操作Kafka的代码库(备注:如果之前已经安装过,则这里不需要安装):
运行效果代码
注意:
在运行项目之前,首先要保证你的项目代码里面的第三方库是否已经全部安装完毕,如果没有,可以参考上面的步骤完成
其次在开启上述KafkaProducer和KafkaConsumer之前,需要先开启Kafka(分开执行,按照顺序,注意在开启kafka之前)
初学者,千万要记住,先启动zookeeper,再启动kafka,这个很重要,不然会出错,切记!!!
cd /home/hadoop/kafka/kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
代码展示
producer.py
# coding: utf-8
from kafka import KafkaProducer
import csv
import time
producer = KafkaProducer(bootstrap_servers='localhost:9092')
csvfile = open("../data/user_log.csv","r")
reader = csv.reader(csvfile)
for line in reader:
gender = line[9]
if gender == 'gender':
continue
print(line[9])
time.sleep(0.1)
producer.send('sex',line[9].encode('utf8'))

上述代码很简单,首先是先实例化一个Kafka生产者。然后读取用户日志文件,每次读取一行,接着每隔0.1秒发送给Kafka,这样1秒发送10条购物日志。这里发送给Kafka的topic为’sex’
consumer.py
from kafka import KafkaConsumer
consumer = KafkaConsumer('result')
for msg in consumer:
print((msg.value).decode('utf8'))
运行首先要运行producer.py,然后去运行consumer.py才可以正常展示和输出
如果报错:
报错原因:3.8版本中,async已经变成了关键字,所以导致不兼容
解决方案:执行 pip install kafka-python,就可以解决
pip install kafka-python运行上面这条命令以后,这时,你会看到屏幕上会输出一行又一行的数字,类似下面的样子:

如果有上述的输出,恭喜你,Python操作Kafka运行成功。接下来,第三部分将分析Spark Streaming如何处理Kafka的实时数据。
神笔马良之画龙点睛
Spark Streaming实时处理数据
Spark Streaming实时处理Kafka数据;
将处理后的结果发送给Kafka;
本项目在于实时统计每秒中男女生购物人数,而Spark Streaming接收的数据为1,1,0,2…,其中0代表女性,1代表男性,所以对于2或者null值,则不考虑。其实通过分析,可以发现这个就是典型的wordcount问题,而且是基于Spark流计算。女生的数量,即为0的个数,男生的数量,即为1的个数。
因此利用Spark Streaming接口reduceByKeyAndWindow,设置窗口大小为1,滑动步长为1,这样统计出的0和1的个数即为每秒男生女生的人数。
配置Spark开发Kafka环境
首先下载Spark连接Kafka的代码库。然后把下载的代码库放到目录
首先将:spark-streaming-kafka-0-8-assembly_2.11-2.4.4.jar这个文件直接复制粘贴在:/home/hadoop/spark/jars

然后在/home/hadoop/spark/jars目录下新建kafka目录,把/home/hadoop/kafka/kafka/libs下所有函数库复制到/home/hadoop/spark/jars/kafka目录下,命令如下:
cd /home/hadoop/spark/jarsmkdir kafka
cd kafkacp /home/hadoop/kafka/kafka/libs/* .
然后,修改 Spark 配置文件,命令如下
cd /home/hadoop/spark/confvim spark-env.sh把 Kafka 相关 jar 包的路径信息增加到 spark-env.sh,修改后的 spark-env.sh 类似如下:
export SPARK_DIST_CLASSPATH=$classpath:/home/hadoop/spark/jars/kafka/*:/home/hadoop/kafka/kafka/libs/*这就配置好了相关的参数
kafka_test.py
#!/home/hadoop/anaconda3/bin/python
from kafka import KafkaProducer
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
from pyspark import SparkConf, SparkContext
import json
import sys
def KafkaWordCount(zkQuorum, group, topics, numThreads):
spark_conf = SparkConf().setAppName("KafkaWordCount").set('spark.io.compresssion.codec', 'snappy')
sc = SparkContext(conf=spark_conf)
sc.setLogLevel("ERROR")
ssc = StreamingContext(sc, 1)
ssc.checkpoint(".")
# 这里表示把检查点文件写入分布式文件系统HDFS,所以要启动Hadoop
# ssc.checkpoint(".")
topicAry = topics.split(",")
# 将topic转换为hashmap形式,而python中字典就是一种hashmap
topicMap = {}
for topic in topicAry:
topicMap[topic] = numThreads
lines = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap).map(lambda x : x[1])
words = lines.flatMap(lambda x : x.split(" "))
wordcount = words.map(lambda x : (x, 1)).reduceByKeyAndWindow((lambda x,y : x+y), (lambda x,y : x-y), 1, 1, 1)
wordcount.foreachRDD(lambda x : sendmsg(x))
ssc.start()
ssc.awaitTermination()
# 格式转化,将[["1", 3], ["0", 4], ["2", 3]]变为[{'1': 3}, {'0': 4}, {'2': 3}],这样就不用修改第四个教程的代码了
def Get_dic(rdd_list):
res = []
for elm in rdd_list:
tmp = {elm[0]: elm[1]}
res.append(tmp)
return json.dumps(res)
def sendmsg(rdd):
if rdd.count != 0:
msg = Get_dic(rdd.collect())
# 实例化一个KafkaProducer示例,用于向Kafka投递消息
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send("result", msg.encode('utf8'))
# 很重要,不然不会更新
producer.flush()
if __name__ == '__main__':
# 输入的四个参数分别代表着
# 1.zkQuorum为zookeeper地址
# 2.group为消费者所在的组
# 3.topics该消费者所消费的topics
# 4.numThreads开启消费topic线程的个数
if (len(sys.argv) < 5):
print("Usage: KafkaWordCount ")
exit(1)
zkQuorum = sys.argv[1]
group = sys.argv[2]
topics = sys.argv[3]
numThreads = int(sys.argv[4])
print(group, topics)
KafkaWordCount(zkQuorum, group, topics, numThreads)
上述代码注释已经也很清楚了,下面在简要说明下:
1. 首先按每秒的频率读取Kafka消息;
2. 然后对每秒的数据执行wordcount算法,统计出0的个数,1的个数,2的个数;
3. 最后将上述结果封装成json发送给Kafka。
另外,需要注意,上面代码中有一行如下代码:
ssc.checkpoint(".") 这行代码表示把检查点文件写入分布式文件系统HDFS,所以一定要事先启动Hadoop。如果没有启动Hadoop,则后面运行时会出现“拒绝连接”的错误提示。如果你还没有启动Hadoop,则可以现在在Ubuntu终端中,使用如下Shell命令启动Hadoop:
cd /home/hadoop/hadoop./sbin/start-dfs.sh建立pyspark项目
新建一个项目
cd /home/hadoop/sparkmkdir mycodecp /home/hadoop/PycharmProjects/First/labproject/kafka_test.py /home/hadoop/spark/mycode

把这个加入到我们执行文件里面
/home/hadoop/spark/bin/spark-submit /home/hadoop/spark/mycode/kafka_test.py localhost:2181 1 sex 1
按照我们最初的想法,我们直接使用执行命令就可以执行了
./startup.sh殊不知,就这样一步一步的走向深渊.......
下面是解决方法
华佗在世之妙手回春
1.首先我们发现执行之后,报错找不到这个文件路径,或者找不到这个文件,不存在这个文件
使用权限加入:chmod 777 startup.sh 或者 chmod +x startup.sh 给我们的执行文件加入可行性权限
2.接下来它依然报错,说无法找到,为什么呢?
注意要给你的Python加上可执行环境,我是使用的anaconda编译环境,anaconda比较的方便,推荐使用
sudo update-alternatives --install /usr/bin/python python /home/hadoop/anaconda3/bin/python 4
3.版本不兼容导致的问题
根据报错的信息我们可以得出,我们的spark里面的有一个文件和我们之前加入的一个文件包有冲突,所以我们的解决方法是在删除这个包(net)


其他报错可以自己参考网络解法,有一个小小的建议,遇到报错之后,很多人都喜欢直接复制报错信息提交给百度君,但是!
不建议这样,因为每一步的过程可能别人和你不一样,或者你们的环境也不同,最正确的解决方法是,你自己阅读报错信息,安装报错来解决,可以参考CSDN里面解决方法。
再次执行



执行OK!到此为止,Spark Streaming程序编写完成,下篇文章将分析如何处理得到的最终结果。
结果展示之移花接木
做好了充分的准备工作,直接可以贴代码运行了!
web展示数据
数据是动态的,不断产生,因此利用Flask-SocketIO实时推送数据 socket.io.js实时获取数据 highlights.js展示数据
目录结构:
kafka-exp
├── app.py
├── static
│ └── js
│ ├── exporting.js
│ ├── highcharts.js
│ ├── jquery-3.1.1.min.js
│ ├── socket.io.js
│ └── socket.io.js.map
└── templates
└── index.html
app.py(直接运行)
import json
from flask import Flask, render_template
from flask_socketio import SocketIO
from kafka import KafkaConsumer
#因为第一步骤安装好了flask,所以这里可以引用
app = Flask(__name__)
app.config['SECRET_KEY'] = 'secret!'
socketio = SocketIO(app)
thread = None
# 实例化一个consumer,接收topic为result的消息
consumer = KafkaConsumer('result')
# 一个后台线程,持续接收Kafka消息,并发送给客户端浏览器
def background_thread():
girl = 0
boy = 0
for msg in consumer:
data_json = msg.value.decode('utf8')
data_list = json.loads(data_json)
for data in data_list:
if '0' in data.keys():
girl = data['0']
elif '1' in data.keys():
boy = data['1']
else:
continue
result = str(girl) + ',' + str(boy)
print(result)
socketio.emit('test_message',{'data':result})
socketio.sleep(1)
# 客户端发送connect事件时的处理函数
@socketio.on('test_connect')
def connect(message):
print(message)
global thread
if thread is None:
# 单独开启一个线程给客户端发送数据
thread = socketio.start_background_task(target=background_thread)
socketio.emit('connected', {'data': 'Connected'})
# 通过访问http://127.0.0.1:5000/访问index.html
@app.route("/")
def handle_mes():
return render_template("index.html")
# main函数
if __name__ == '__main__':
socketio.run(app,debug=True)index.html
DashBoard
Girl:
Boy:
依次运行(保证之前的服务全部开启)


总结
在spark里面使用Python对大数据进行实时展示,是当今互联网技术的革新和必然发展,无论是淘宝、京东、拼多多还是其他各类的电商,他们都会使用这项技术,未来Python和hadoop/spark将会在大数据的时代,创造出更多未知的惊喜和迎接新的挑战!
每文一语
眼下即最好,未来方可期!