打造大型分布式监控系统
打造云原生大型分布式监控系统
笑谈监控系统
随着时间的积累,出现故障的风险越来越高,事故的发生总是出人预料,如果采用人力运维的方式,对于故障定位、故障处理都是很大的挑战。故障的时间越长,面临的损失越大,所以在发展到一定程度的团队都需要一套完善的监控系统
 监控大屏
监控大屏
一套完善的监控系统最重要的就是本身永远不可以故障,即使平台故障也要确保监控可能告警出来,所以监控系统本身的高可用,是我们一直在追求的,先来看看一个完备的监控系统应该考虑哪些功能
监控系统设计面临什么问题
监控系统会对很多角色进行监控,我把他分为这几个大类:服务器、容器、服务或应用、网络、存储、中间件,根据业界的方案,不同的分类使用不同的采集器进行采集
在功能上要考虑哪些问题?
支持标记不同监控指标来源,方便理清楚业务来源
支持聚合运算,转换指标的含义、组合用来进行计算、汇总、分析
告警、报表、图形化大屏展示
保存历史数据便于溯源
在易用性上应该考虑
支持配置增减监控项,自定义监控
支持配置表达式进行计算
最好有自动发现,在新增服务器或新增pod等资源时自动纳入监控
支持配置告警策略定义告警范围与阈值,支持自定义告警
方案选型
从以上方面考虑,应该选用哪些开源方案呢?业界常见的有Elasticsearch、Nagios、zabbix、prometheus,其他方案比较小众不做讨论
 方案选型
方案选型
Elasticsearch是一个实时的分布式搜索和分析引擎,支持分片、搜索速度快,一般和Logstash、Kibana结合起来一起用,也就是ELK,更擅长文档日志的搜索分析Nagios: 优点是出错的服务器、应用和设备会自动重启,自动日志滚动;配置灵活,可以自定义 shell 脚本,通过分布式监控模式;并支持以冗余方式进行主机监控,报警设置多样,以及命令重新加载配置文件无需打扰 Nagios 的运行。缺点是事件控制台功能很弱,插件易用性差;对性能、流量等指标的处理不给力;看不到历史数据,只能看到报警事件,很难追查故障原因;配置复杂,初学者投入的时间、精力和成本比较大。zabbix入门容易、上手简单、功能强大,容易配置和管理,但是深层次需求需要非常熟悉zabbix并进行大量的二次定制开发,二次开发太多是不可接受的prometheus几乎支撑了上面所有的需求,可视化展示可以接入grafana,可以用promSQL语言来做聚合查询,不需要定制;可以使用打tag的方式,对每个指标分类;强大的社区针对各种应用、网络、服务器等设备、角色都提供了采集方案以及无侵入式的高可用方案,这个就是今天讨论的重点
根据上面的种种原因,综合来看prometheus比较合适
prometheus与他的缺陷
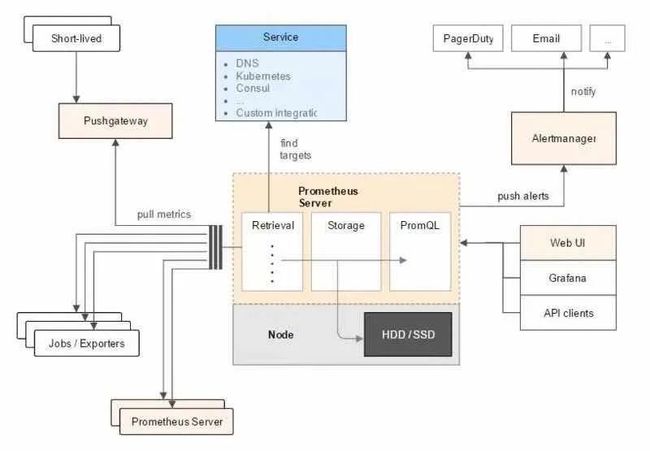 prometheus架构图
prometheus架构图
从上面的架构图可以看出,
prometheus是在客户端部署采集器(exporter)的形式来采集数据,服务端主动向prometheus通信来拉取数据客户端也可以通过推送数据到
PushGateway再交给prometheus拉取prometheus有自动发现的能力,简单配置以后就可以主动拉取平台接口获取监控范围:azure、consul、openstack等,并针对检测角色配置tag,如果和业务强相关,可以定制修改代码,拉取自己平台的接口来识别监控角色和动态打tagprometheus也有告警的能力,接入官方提供的
AlertManager组件可以检测产生告警,再使用webhook接入自己的告警邮件/短信通知平台-
这里的问题在于无法通过页面配置告警策略、也无法存储告警记录,可以在
AlertManager后面加一些组件来告警收敛、静默、分组、存储告警策略的动态配置,可以写程序根据策略生成告警配置、放到
prometheus指定目录下,并调用prometheus热更新接口
唯一要解决的就是负载量大时出现的性能问题以及高可用问题
单机prometheus的部署存在的问题

prometheus的架构决定是他更适合单机的部署方案,单机部署在压力过大时可以通过服务器升配的方式缓解压力,但是依然会存在共性的问题
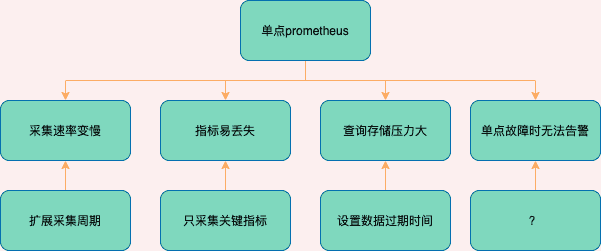 单点prometheus的问题
单点prometheus的问题
采集速率会因为cpu/网络通信限制导致卡顿,采集速度变慢,指标在周期内未主动拉取的时候会丢失本次的指标,这里可以把采集周期拉长,后果是粒度变粗,不建议拉太长;另一种方式就是减少无用指标的采集
查询时也是因为同样的原因速度会受到限制,数据存储时间范围过多时,对磁盘会有很大的压力
单点故障时就完全没有办法了,直接服务不可用
单点高负载考虑什么方案?
参考前一次的文章,高负载的时候自动水平扩展,并做负载均衡,首先想到的水平扩展方式就是Prometheus提供的分组能力
 分片采集
分片采集
相应于把prometheus分片,通过配置的方式各采集部分节点,这种方式有三个问题
数据分散运维困难
要来回切换数据源,看不到全局视图
解决这个问题,考虑增加一个存储位置汇总数据(remote write)
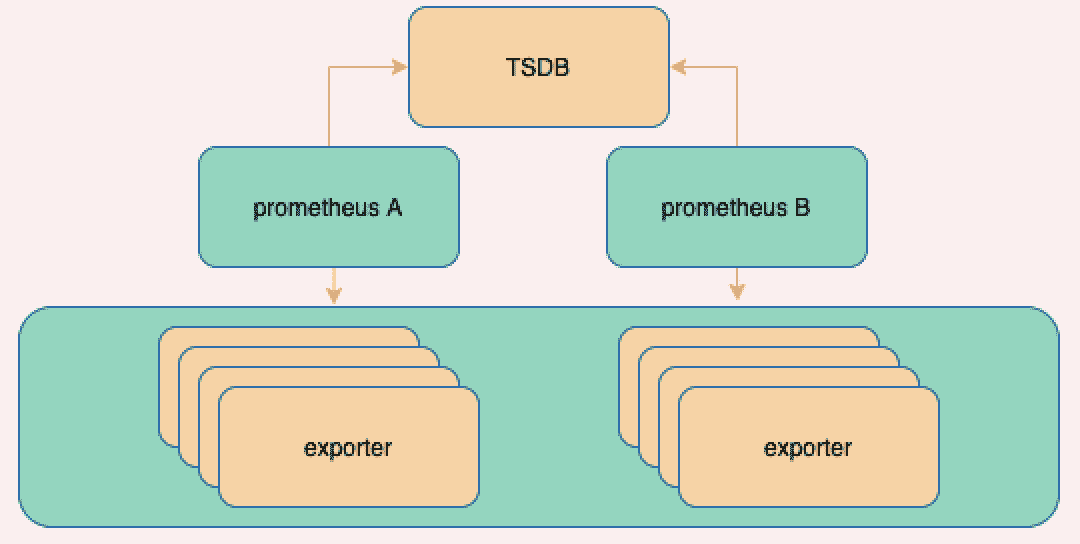 分片后汇总
分片后汇总
这里考虑使用TSDB汇总,需要支持扩容的、支持集群保证高可用的TSDB
但是需要在TSDB上层再加一个查询组件来做查询,会丧失原生的查询语句能力,可以考虑把TSDB替换成prometheus节点,用联邦的形式存储
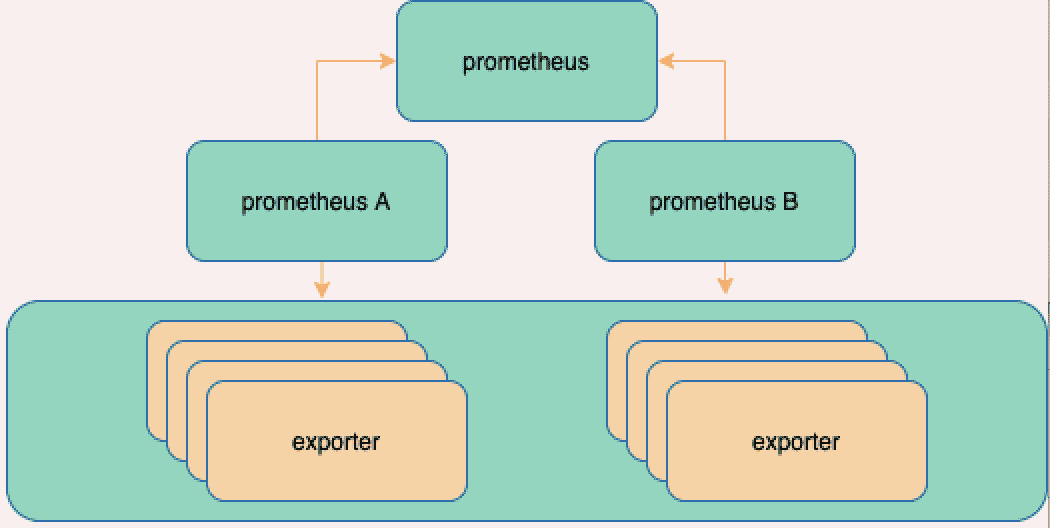 联邦
联邦
这种情况可以满足基本的使用要求,通过prometheus自监控来通知运维人员手动扩容修改分组,有没有更自动一点的方式呢?
弹性伸缩(自动水平伸缩)
弹性伸缩的前提有三个
要能监控当前节点负载状态,预判扩容时机
需要维护服务启停方式、自动创建服务并放到相应节点上
同时要能修改
prometheus各节点数据采集范围
上k8s做容器编排是最直接的方案,可以解决创建和销毁服务的问题,也是可以通过cpu使用率或自定义指标完成横向扩容的,但解决不了的问题是修改prometheus节点配置,动态分配采集范围,考虑使用以下方案
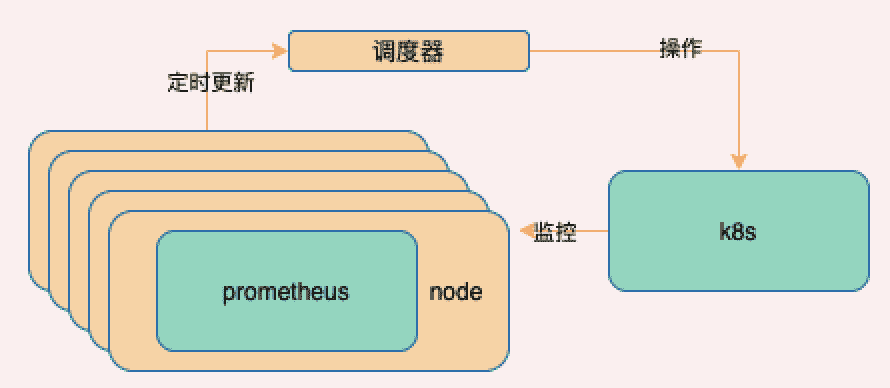 调度器
调度器
prometheus注意要配置节点反亲和性(k8s配置podAntiAffinity)写一个调度器通过
k8s api检测prometheus节点状态通过k8s检测节点故障以及负载情况,使用
hash分摊压力,扩展prometheus的sd自动发现功能,带上自己的hostname来获取调度器提供的数据范围
用这种方式就不需要修改配置文件了,因为是prometheus接口端定时更新监控范围
根据具体运行情况伸缩prometheus,不需要再配置configmap
到这里你可能有一个疑问,假如我监控服务器用上面的方式,那么多接收端,再加一个redis集群的监控,应该放到哪个节点上呢?答案是可以专门创建独立于此自动伸缩方案的prometheus来进行少量数据监控,或者直接放到所有节点上,在上层再考虑去重的问题,这个我们一会讨论。
到目前为止分片以后分散了压力,但还没有解决的问题是数据分散无法汇总查询、单点故障数据丢失的问题。
汇总查询可能你会想到刚刚说的联邦部署,但压力又汇总到一点上了,不能根本的解决问题;解决单点故障应该使用冗余的形式部署,给每个监控范围分配2个及以上监控节点,但会导致客户端拉取次数翻倍,也不建议。
如何保证单点故障数据不丢失
为了避免无法汇总查询、单点故障数据丢失的问题,这里打算接入一个高可用方案thanos,把prometheus设置为无状态应用,并开启远程写把数据推送到thanos
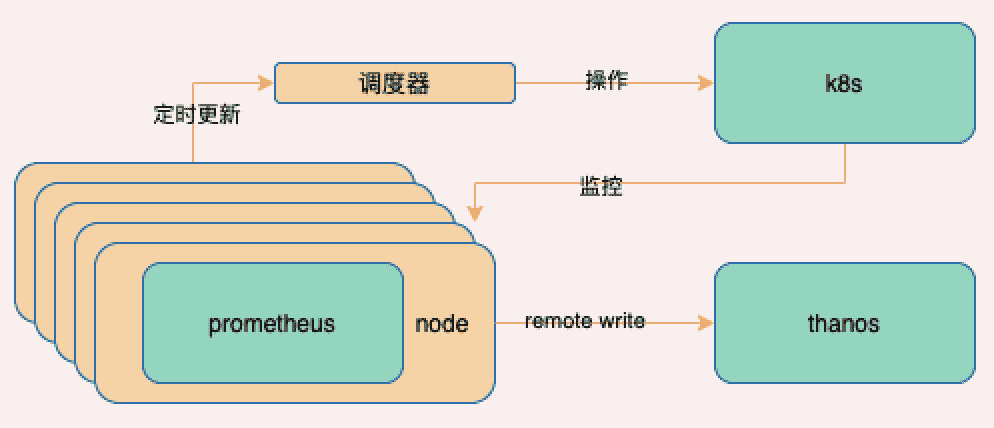 推送到thanos
推送到thanos
这样的话prometheus本身不存储数据,即使挂掉部分节点,只要保证node够多也会再自动伸缩出新的节点,期间读取到的采集范围会先负载变大,然后又得到缓解,整个过程在2个周期内解决
PS: ,Prometheus在将采集到的指标写入远程存储之前,会先缓存在内存队列中,然后打包发送给远端存储,以减少连接数量,要提高写入速率需要修改配置项queue_config
简单介绍下thanos,thanos是无侵入式的高可用方案,负责对prometheus产生的数据进行汇总、计算、去重、压缩、存储、查询、告警,他实现了prometheus提供的查询接口,对外部而言查询prometheus还是查询thanos的效果完全一样,是无感知的
一起来实现分布式高可用监控系统
如何让我们来实现一个这样的组件,你会怎么做呢?
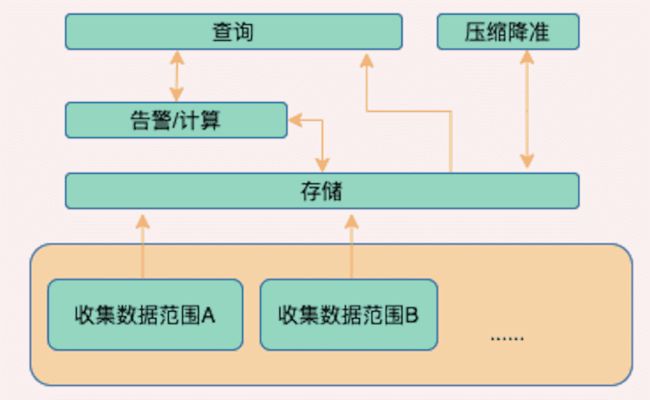 汇总存储,上层完成其他功能
汇总存储,上层完成其他功能
把分片数据写入到存储,其他组件和存储通信,thanos的主流方案也是这么做的
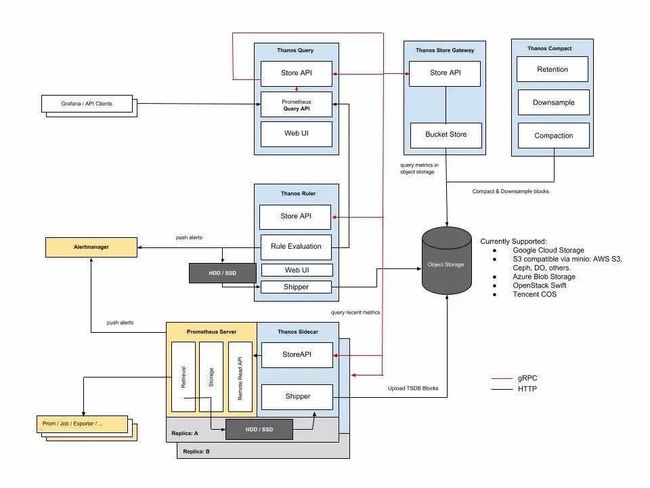 thanos架构图
thanos架构图
如上图所示所有的组件都会与对象存储通信,完成数据存储或者读取的功能
使用对象存储做存储引擎
和
prometheus节点一同部署sidecar,每个节点对应一个,定期放数据推送到对象存储Ruler负责判定告警以及根据规则做指标聚合运算Compact负责降准压缩,一份数据变三份,一般是分为1分钟、5分钟、1小时写回存储,查询时间粒度越大呈现指标粒度越粗,防止前端数据刷爆Query与其他组件通过grpc的方式进行通信读取数据,它不和对象存储直接通信,而是在中间加了一层gateway网关上图的方案
sidecar不是我这次的架构,其他是一样的,sidecar的原理是把采集到的数据使用缓存到本地(默认2小时数据为热数据),冷数据才推送,近期数据存储本地,查询时再做汇总会有一定的压力,同时单点故障问题还是没有解决
如果是小规模集群无网络压力可以使用sidercar
不要在接收端存储
和prometheus部署在一起的sidercar违背了容器中的简单性原则,也提高存储压力,把他们剥离开试试?
 汇总再转存
汇总再转存
我的想法是收集数据推送,然后进行存储,由其他组件完成与存储的通信
 receive方案
receive方案
如上图,Receive组件实现了remote write接口,Prometheus可以将数据实时推送到Receive上;Receive本身实际上相当于一个没有收集功能的Prometheus,那此时Prometheus就不再需要存储数据,之前的方案就可以实施了
对象存储中的数据具有不可修改特性,也就是说一旦写入就变成只读了
Prometheus本地存储的原理是接受到的数据写到本地文件存储里面组成WAL文件列表,Receive也是这么做的,然后超过一定时限后生成block,这些block会上传到对象存储Query组件来近期数据(默认2小时内)查询recevie,过期后使用对象存储receive使用k8s的dnssrv功能做服务发现,便于下游拉取数据而不要使用k8s的service:ip自带的负载均衡receive自带了hash算法,可以把上游远程写过来的流量均匀分布在各个节点上,这里可以采用k8s的service自动轮训,recevie会把请求route到相应节点上
为防止prometheus挂掉一个导致的数据丢失问题,给prometheus加一个副本,然后在query时去重,主要由query的--query.replica-label 参数和Prometheus 配置的 prometheus_replica参数来实现,如下图
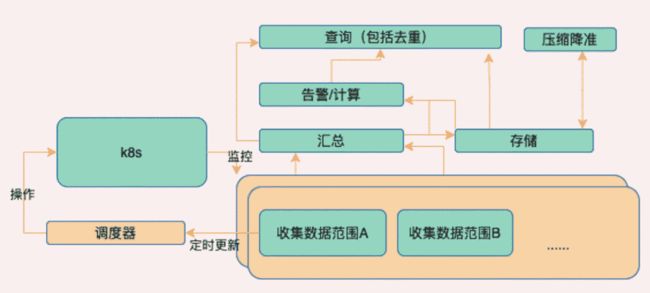 概览
概览
同样的其他组件,如ruler也可以配置冗余部署rule_replica就不展开讲了
还好recevie自带了分布式一致性算法,不然就要自己实现一个了,到此我们解决了
数据接收端能应对海量数据的压力均衡
解决了prometheus部署在不同集群上时查询延迟高的问题
解决了跨节点数据复合运算(
ruler)解决了数据压缩降准
hashring真的是分布式一致性算法吗
我们知道分布式一致性算法可以解决下面的问题
在压力增加时做到自动扩容,压力减小时自动缩容
扩缩容时必须要保障数据不丢失,单点故障时数据也不可以丢失
扩缩容时数据映射落点要一致,不然会出现数据断连
但是实际使用过程中,不难发现,还是会发生数据丢失,这引起了我的兴趣
这一块的官网介绍很少,hashring 的endpoints参考下面的代码,你会发现0 1 2 的方式就是k8s的statefulset为pod 分配的name,所以recevie要以sts的方式部署,并提前把副本数与配置关系对应起来,3节点已经可以支撑很大数量的数据处理了
thanos-receive-hashrings.json: |
[
{
"hashring": "soft-tenants",
"endpoints":
[
"thanos-receive-0.thanos-receive.thanos.svc.cluster.local:10901",
"thanos-receive-1.thanos-receive.thanos.svc.cluster.local:10901",
"thanos-receive-2.thanos-receive.thanos.svc.cluster.local:10901"
]
}
]
在源码里发现,实际上这里并没有使用分布式一致性算法!! 在hashring.go函数里可以看到,这是一个简单的hash mod,所以hashring是有误导性的
func (s simpleHashring) GetN(tenant string, ts *prompb.TimeSeries, n uint64) (string, error) {
if n >= uint64(len(s)) {
return "", &insufficientNodesError{have: uint64(len(s)), want: n + 1}
}
return s[(hash(tenant, ts)+n)%uint64(len(s))], nil
}
提炼出来是这样的hash算法
hash(string(tenant_id) + sort(timeseries.labelset).join())
tenant_id是指数据源带上租户,可以给不同租户分配自己的hash具体的
hash算法使用xxHash参考文末资料5
解决的办法也有了,可以通过配置多副本冗余的方式,把receive的数据冗余到其他位置,设置receive.replication-factor配置,然后拉取数据的时候因为使用的是服务发现,和所有服务通信的方式,可以在一定程序上保证数据不丢失
PS: 冗余也会有点问题,算法是先选hash mod后的节点,比如是第n个,然后如果factor是2,就再选n+1和n+2,然后发请求给n,这个时候如果n挂了其实会失败,相对而言n+1或者n+2节点挂了的话不会对这部分的数据有影响
当receive出现故障是怎么处理的
当发生扩缩容的时候,由于hashring发生变化,所有的节点需要将write-ahead-log的数据flush到TSDB块并上传到OSS中(如果配置了的话),因为这些节点之后将有一个新的分配。之前已存在节点上的时间序列不需要作调整,只是后面过来的请求按新的分发来寻找该去的receiver节点。
这个过程不需要重启receive,代码里有watch,可以检测hashring的变化
注意,这种情况发生的flush可能会产生较小的TSDB块,但compactor模块可以将它们优化合并,因此不会有什么问题。
当有receiver节点发生故障时,prometheus的远程写会在后端目标无响应或503时进行重试,因此,receiver一定时间的服务挂掉是可以容忍的。如果这种挂机时间是不可接受的话,可以将副本数配置为 3 或以上,这样即使有一个receiver节点挂掉,还有其他receiver节点来接收写请求
业务指标计算问题
如果有非常复杂的业务指标,需要从其他地方采集推送,最好的方式是写成采集器exporter,在ruler进行复合运算,当然也有可能出现表达式写不出来的尴尬问题
考虑写成k8s的job定时任务,把数据推送到PushGateway,再交给prometheus去拉取
PS1: 注意按exporter的开发标准,不允许出现重复指标哦
PS2:如果要删除过期的垃圾数据可以调用PushGateway的http://%s/metrics/job/%s/instance/%s/host/接口进行删除
告警策略动态更新/告警记录储存的问题
要动态生成告警策略,可以写一个服务接收请求,调用k8s生成configmap,并通知ruler进行热更新
更新策略配置文件configmap(同步更新到pod里会有一定的延迟,使用
subPath是无法热更新的,注意configMapAndSecretChangeDetectionStrategy: Watch参数必须为默认参数Watch)把configmap挂载相应的ruler上面
全景视图
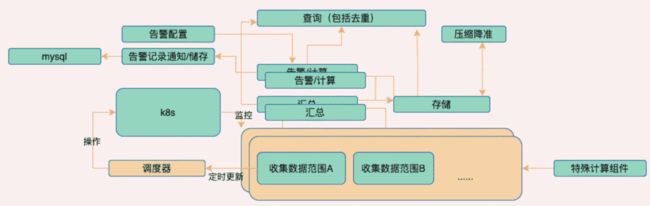 全景视图
全景视图
最后
当然对于一个成熟的监控系统来说,除了发现故障及时告警以外,还应该有更多的功能,这不是本次讨论的范围,如果有时间未来会写写
运营故障报表和资源日报周报月报等用于趋势分析
低负载报表用于分析服务器利用率,防止资源浪费
有了故障趋势和更多的重要指标覆盖,可以结合AI进行故障预测,在故障发生前提前预测
最后的最后
针对全k8s的集群监控来说,还有更简单的方式来监控,那就是Prometheus Operator,可以非常简单的创建k8s的资源,比如收集器Prometheus、采集器的抽象ServiceMonitor、AlertManager等,要监控什么数据就变成直接操作k8s集群的资源对象了
监控可能为其他应用的水平伸缩服务服务,使用Prometheus Adpater来自定义监控某些指标,来达到自动扩缩容的目的
监控还可以为运维平台服务,提供故障自动修复
一句话,只要监控运维平台做得足够好,运维人员都得失业
引用与拓展资料
1、7 款你不得不了解的开源云监控工具
2、Thanos在TKEStack中的实践 - Even - A super concise theme for Hugo
3、Prometheus Remote Write配置 - 时序数据库 TSDB - 阿里云
4、Thanos - Highly available Prometheus setup with long term storage capabilities
5、xxHash - Extremely fast non-cryptographic hash algorithm
—————END—————
推荐阅读:
SpringBoot+vue.js搭建图书管理系统
i++ 是线程安全的吗?
IDEA 卡成球了 !咋优化 ?
最美的Vue+Element开源后台管理系统
基于SpringBoot的迷你商城系统,附源码!
IntelliJ IDEA 2020.2.4款 神级超级牛逼插件推荐

最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。获取方式:关注公众号并回复 java 领取,更多内容陆续奉上。
明天见(。・ω・。)ノ♡