kafka集群 kubernetes_【kafaka】在Kubernetes上使用helm部署kafka
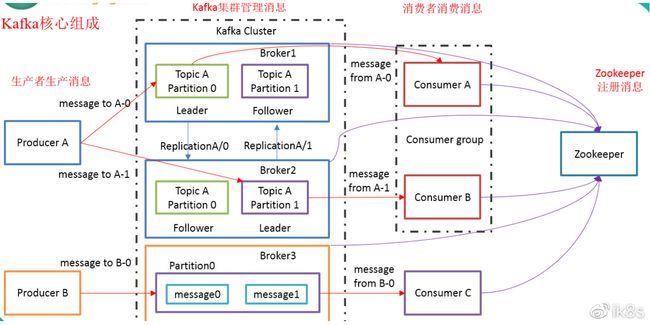
1、kafka整体架构
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
点击此处添加图片说明文字
Broker:是Kafka集群中包含的一个或多个服务器,这种服务器被称为broker。
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)
Partition:Partition是物理上的概念,每个Topic包含一个或多个Partition.
Producer负责发布消息到Kafka broker
Consumer:消息消费者,向Kafka broker读取消息的客户端。
Consumer Group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
2、部署kafka和zookeeper
1)添加incubator的helm仓库
通过执行下面的命令,添加incubator的helm仓库。
$ helm repo add incubator https://kubernetes-charts-incubator.storage.googleapis.com
2)获取chart
为了修改运行环境的参与,将incubator/kafka下载到本地。
$ helm fetch incubator/kafka –version 0.21.2
将此kafka-0.21.2.tgz解压缩到本地。
3)修改chart中的value.xml文件

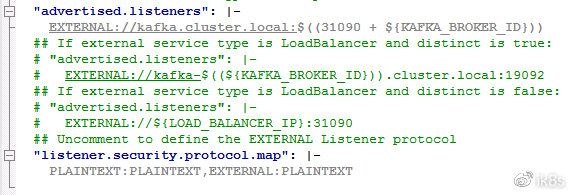
通过notepad++等工具,对values.yaml文件进行编辑。以通过NodePort模式对外暴露kafka服务,允许Kubernetes集群外的应用使用kafka服务。

3)修改zookeeper chart中的value.xml文件
通过notepad++等工具,对values.yaml文件进行编辑。以通过NodePort模式对外暴露zookeeper服务,允许Kubernetes集群外的应用使用zookeeper服务。
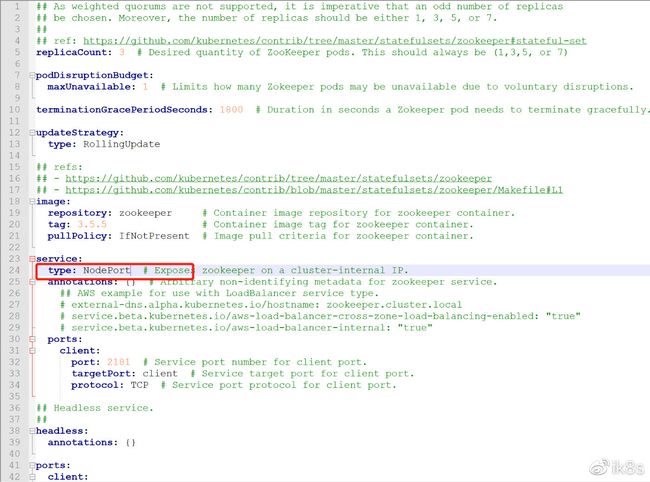
5)部署kafka到Kubernetes中
$ helm install kafka ./kafka-0.21.2/kafka –set external.enabled=true –set external.type=NodePort –namespace=kube-public
3、验证
3.1 安装kafka客户端
下载kafka_2.11-2.0.0.tgz:
$ wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.11-2.0.0.tgz
解压缩kafka_2.11-2.0.0.tgz:
$ tar zxvf kafka_2.11-2.0.0.tgz
进入 kafka_2.11-2.0.0目录:
$ cd kafka_2.11-2.0.0/
3.2 验证
3.2.1 客户端验证
通过kubectl get svc命令,获取kafka以NodePort方式对外暴露的端口。
$ kubectl get svc -n kube-public
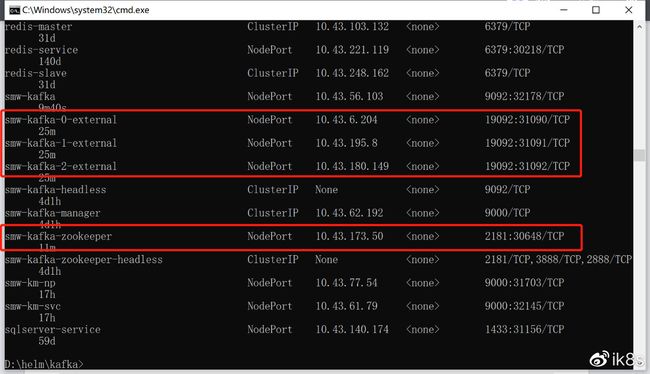
1)列示kafka中已有的topic
$ ./kafka-topics.sh –zookeeper 10.0.33.173:30648 –list

2)创建新的topic
./kafka-topics.sh –zookeeper 10.0.33.173:30648 –topic topnew002 –create –partitions 3 –replication-factor 1

3)生产消息
./kafka-console-producer.sh –broker-list 10.0.33.173:31091 –topic topnew002

4)消费信息
./kafka-console-consumer.sh –bootstrap-server 10.0.33.173:31091 –topic topnew002 –from-beginning
3.2.2 go验证
在$GOPATH/src目录下创建conn_kafka.go文件,此文件用于向kafka发送信息。
package main
import (
"github.com/Shopify/sarama"
"time"
"log"
"fmt"
"os"
)
//定义kafka的地址
var Address = []string{"10.0.33.203:31090","10.0.33.203:31092","10.0.33.203:31093"}
func main() {
syncProducer(Address)
}
//同步消息模式
func syncProducer(address []string) {
config := sarama.NewConfig()
config.Producer.Return.Successes = true
config.Producer.Timeout = 5 * time.Second
//构建消息生产者
p, err := sarama.NewSyncProducer(address, config)
if err != nil {
log.Printf("sarama.NewSyncProducer err, message=%s \n", err)
return
}
defer p.Close()
//定义topic
topic := "test2020"
srcValue := "sync: 这是测试的信息. index=%d"
//通过for循环,发送信息
for i:=0; i<10; i++ {
value := fmt.Sprintf(srcValue, i)
msg := &sarama.ProducerMessage{
Topic:topic, Value:sarama.ByteEncoder(value),
}
part, offset, err := p.SendMessage(msg)
if err != nil {
log.Printf("send message(%s) err=%s \n", value, err)
}else {
fmt.Fprintf(os.Stdout, value + ";发送成功!,partition=%d, offset=%d \n", part, offset)
}
time.Sleep(2*time.Second)
}
}
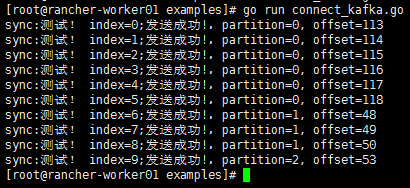
通过执行下面的命令,运行conn_kafka.go向kafka发送信息。
$ go run conn_kafka.go
4、部署kafka manager
通过执行下面的命令安装kafka manager,安装的命名空间为kube-public。zookeeper的地址为kafka-zookeeper:2181,kafka-zookeeper是在Kubernetes中的服务名称。
$ helm install kafka-manager stable/kafka-manager –set zkHosts=kafka-zookeeper:2181 –namespace=kube-public

5、 基于Prometheus和Grafana进行监控
5.1 部署kafka_exporter
通过helm3部署kafka的指标暴露应用。
helm repo add gkarthiks https://gkarthiks.github.io/helm-charts
helm install kafka-exporter gkarthiks/prometheus-kafka-exporter –set kafkaServer=kafka:9092 –namespace=kube-public
5.2 Prometheus配置
在Prometheus的配置文件(/etc/prometheus/prometheus.yml)的最后面增加下面的内容。
– job_name: ‘redis-ha-exporter’
static_configs:
– targets: [‘http://kafka-exporter-prometheus-kafka-exporter.kube-public:9308’]
5.3 Grafana监控
在Grafana中导入kafka-exporter-overview_rev5.json(下载地址:https://grafana.com/grafana/dashboards/7589),通过此DashBoard就能监控kafka运行的相关指标。

作者简介:季向远,本文版权归原作者所有。微博:ik8s