prometheus job 重复_一文详解 Prometheus 的高可用方案:Thanos


背景
在高可用 prometheus:问题集锦文章中有简单提到 Prometheus 的高可用方案,尝试了联邦、Remote Write 之后,我们最终选择了 Thanos 作为监控配套组件,利用其全局视图来管理我们的多地域、300+集群的监控数据。本文主要介绍 Thanos 的一些组件使用和心得体会。
Prometheus 官方的高可用有几种方案:- HA:即两套 Prometheus 采集完全一样的数据,外边挂负载均衡
- HA + 远程存储:除了基础的多副本 Prometheus,还通过 Remote write 写入到远程存储,解决存储持久化问题
- 联邦集群:即 Federation,按照功能进行分区,不同的 Shard 采集不同的数据,由 Global 节点来统一存放,解决监控数据规模的问题。
使用官方建议的多副本 + 联邦仍然会遇到一些问题,本质原因是 Prometheus 的本地存储没有数据同步能力,要在保证可用性的前提下再保持数据一致性是比较困难的,基本的多副本 Proxy 满足不了要求,比如:
Prometheus 集群的后端有 A 和 B 两个实例,A 和 B 之间没有数据同步。A 宕机一段时间,丢失了一部分数据,如果负载均衡正常轮询,请求打到A 上时,数据就会异常。
如果 A 和 B 的启动时间不同,时钟不同,那么采集同样的数据时间戳也不同,就多副本的数据不相同。就算用了远程存储,A 和 B 不能推送到同一个 TSDB,如果每人推送自己的 TSDB,数据查询走哪边就是问题
官方建议数据做 Shard,然后通过 Federation 来实现高可用,但是边缘节点和 Global 节点依然是单点,需要自行决定是否每一层都要使用双节点重复采集进行保活。也就是仍然会有单机瓶颈。
另外部分敏感报警尽量不要通过 Global 节点触发,毕竟从 Shard 节点到 Global 节点传输链路的稳定性会影响数据到达的效率,进而导致报警实效降低。
- 存储角度:如果使用 Remote Write 远程存储, A 和 B 后面可以都加一个 Adapter,Adapter 做选主逻辑,只有一份数据能推送到 TSDB,这样可以保证一个异常,另一个也能推送成功,数据不丢,同时远程存储只有一份,是共享数据。方案可以参考这篇文章
- 存储角度:仍然使用 Remote Write 远程存储,但是 A 和 B 分别写入 TSDB1 和 TSDB2 两个时序数据库,利用 Sync 的方式在 TSDB1 和 TSDB2 之间做数据同步,保证数据是全量的。
- 查询角度:上边的方案需要自己实现,有侵入性且有一定风险,因此大多数开源方案是在查询层面做文章,比如 Thanos 或者 Victoriametrics,仍然是两份数据,但是查询时做数据去重和 join。只是 Thanos是通过 Sidecar 把数据放在对象存储,Victoriametrics 是把数据 Remote Write 到自己的 Server 实例,但查询层 Thanos Query 和 Victor的 Promxy 的逻辑基本一致,都是为全局视图服务
实际需求
随着我们的集群规模越来越大,监控数据的种类和数量也越来越多:如Master/Node 机器监控、进程监控、4 大核心组件的性能监控,POD 资源监控、kube-stats-metrics、K8S events监控、插件监控等等。除了解决上面的高可用问题,我们还希望基于 Prometheus 构建全局视图,主要需求有:长期存储:1 个月左右的数据存储,每天可能新增几十G,希望存储的维护成本足够小,有容灾和迁移。考虑过使用 Influxdb,但 Influxdb 没有现成的集群方案,且需要人力维护。最好是存放在云上的 TSDB 或者对象存储、文件存储上。
无限拓展:我们有300+集群,几千节点,上万个服务,单机 Prometheus 无法满足,且为了隔离性,最好按功能做 Shard,如 Master 组件性能监控与 POD 资源等业务监控分开、主机监控与日志监控也分开。或者按租户、业务类型分开(实时业务、离线业务)。
全局视图:按类型分开之后,虽然数据分散了,但监控视图需要整合在一起,一个 Grafana 里 n 个面板就可以看到所有地域+集群 + POD 的监控数据,操作更方便,不用多个 Grafana 切来切去,或者 Grafana 中多个 Datasource 切来切去。
无侵入性:不要对已有的 Prometheus 做过多的修改,因为 Prometheus 是开源项目,版本也在快速迭代,我们最早使用过 1.x,可1.x 和 2.x的版本升级也就不到一年时间,2.x 的存储结构查询速度等都有了明显提升,1.x 已经没人使用了。因此我们需要跟着社区走,及时迭代新版本。因此不能对 Prometheus 本身代码做修改,最好做封装,对最上层用户透明。
Thanos 架构
Thanos 的默认模式:sidecar 方式
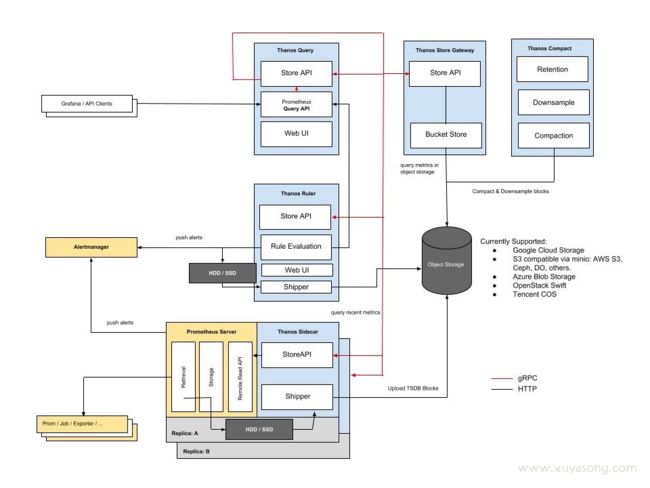
- Bucket
- Check
- Compactor
- Query
- Rule
- Sidecar
- Store
receive
downsample
组件与配置
下面会介绍如何组合 Thanos 组件,来快速实现你的 Prometheus 高可用,因为是快速介绍,和官方的 quick start有一部分雷同,不过会给出推荐配置,且本文截止2020.1 月的版本,不知道以后会 Thanos 会迭代成什么样子第1步:确认已有的 Prometheus
thanos 是无侵入的,只是上层套件,因此你还是需要部署你的 Prometheus,这里不再赘述,默认你已经有一个单机的 Prometheus 在运行,可以是 pod 也可以是主机部署,取决于你的运行环境,我们是在 k8s 集群外,因此是主机部署。Prometheus 采集的是地域A的监控数据。你的 Prometheus 配置可以是: 启动配置:"./prometheus--config.file=prometheus.yml \--log.level=info \--storage.tsdb.path=data/prometheus \--web.listen-address='0.0.0.0:9090' \--storage.tsdb.max-block-duration=2h \--storage.tsdb.min-block-duration=2h \--storage.tsdb.wal-compression \--storage.tsdb.retention.time=2h \--web.enable-lifecycle"web.enable-lifecycle一定要开,用于热加载时 reload 你的配置,retention 保留 2 小时,Prometheus 默认 2 小时会生成一个 block,Thanos 会把这个 block 上传到对象存储。
采集配置:prometheus.yml
global: scrape_interval: 60s evaluation_interval: 60s external_labels: region: 'A' replica: 0rule_files:scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['0.0.0.0:9090'] - job_name: 'demo-scrape' metrics_path: '/metrics' params: ...2.2.1 版本以上
声明你的 external_labels
启用 –web.enable-admin-api
启用 –web.enable-lifecycle
第2步:部署 Sidecar 组件
关键的步骤来了,最核心莫过于 sidecar 组件。sidecar是 k8s 中的一种模式 Sidecar 组件与 Prometheus server 部署于同一个 pod 中。他有两个作用:- 它使用 Prometheus 的 Remote Read API,实现了 Thanos 的 Store API。这使后面要介绍的Query 组件可以将 Prometheus 服务器视为时间序列数据的另一个来源,而无需直接与 Prometheus API交互(这就是 Sidecar 的拦截作用)
- 可选配置:在 Prometheus 每2小时生成一次 TSDB 块时,Sidecar 将 TSDB 块上载到对象存储桶中。这使得 Prometheus 服务器可以以较低的保留时间运行,同时使历史数据持久且可通过对象存储查询。
./thanos sidecar \--Prometheus.url="http://localhost:8090" \--objstore.config-file=./conf/bos.yaml \--tsdb.path=/home/work/opdir/monitor/Prometheus/data/Prometheus/"type: GCSconfig: bucket: "" service_account: ""因为 Thanos 默认还不支持我们的云存储,因此我们在 Thanos 代码中加入了相应的实现,并向官方提交了 PR。
需要注意的是:别忘了为你的另外两个副本 1号 和 2号 Prometheus 都搭配一个 sidecar。如果是 pod运行可以加一个 container,127 访问,如果是主机部署,指定 Prometheus 端口就行。
另外 sidecar 是无状态的,也可以多副本,多个 sidecar 可以访问一份 Prometheus 数据,保证 sidecar 本身的拓展性,不过如果是 pod 运行也就没有这个必要了,sidecar 和 Prometheus 同生共死就行了。
sidecar 会读取 Prometheus 每个 block 中的 meta.json 信息,然后扩展这个 json 文件,加入了 Thanos 所特有的 metadata 信息。而后上传到块存储上。上传后写入 thanos.shipper.json 中
第3步:部署 query 组件
sidecar 部署完成了,也有了3个一样的数据副本,这个时候如果想直接展示数据,可以安装 query 组件 Query 组件(也称为“查询”)实现了 Prometheus 的 HTTP v1 API,可以像 Prometheus 的 graph一样,通过 PromQL 查询 Thanos 集群中的数据。 简而言之,sidecar 暴露了 StoreAPI,Query 从多个 StoreAPI 中收集数据,查询并返回结果。Query 是完全无状态的,可以水平扩展。 配置:"./thanos query \--http-address="0.0.0.0:8090" \--store=relica0:10901 \--store=relica1:10901 \--store=relica2:10901 \--store=127.0.0.1:19914 \"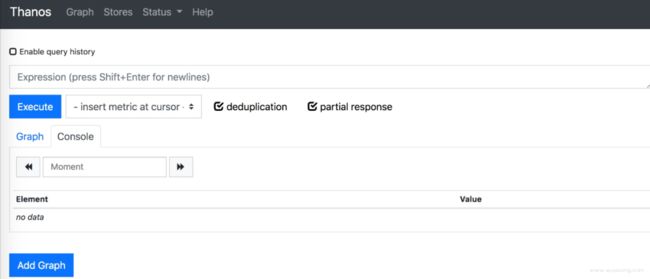
和 Prometheus 几乎一样对吧,有了这个页面你就不需要关心最初的 Prometheus 了,可以放在这里查询。
点击 store,可以看到对接了哪些 sidecar。
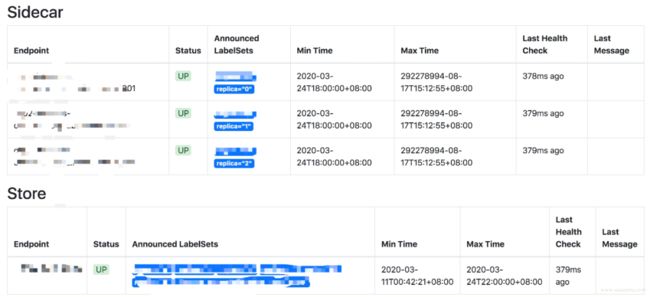
query 页面有两个勾选框,含义是:
deduplication:是否去重。默认勾选代表去重,同样的数据只会出现一条,否则 replica0 和 1、2 完全相同的数据会查出来 3 条。
partial response:是否允许部分响应,默认允许,这里有一致性的折中,比如 0、1、2 三副本有一个挂掉或者超时了,查询时就会有一个没有响应,如果允许返回用户剩下的 2 份,数据就没有很强的一致性,但因为一个超时就完全不返回,就丢掉了可用性,因此默认允许部分响应。
第4步:部署 store gateway 组件
你可能注意到了,在第 3 步里,./thanos query 有一条–store是 xxx:19914,并不是一直提到的 3 副本,这个 19914 就是接下来要说的 store gateway组件。 在第 2 步的 sidecar 配置中,如果你配置了对象存储 objstore.config-file,你的数据就会定时上传到 bucket 中,本地只留 2 小时,那么要想查询 2 小时前的数据怎么办呢?数据不被 Prometheus 控制了,应该如何从 bucket 中拿回来,并提供一模一样的查询呢? Store gateway 组件:store gateway 主要与对象存储交互,从对象存储获取已经持久化的数据。与sidecar一样,store gateway也实现了 store api,query 组可以从 store gateway 查询历史数据。 配置如下:
./thanos store \--data-dir=./thanos-store-gateway/tmp/store \--objstore.config-file=./thanos-store-gateway/conf/bos.yaml \--http-address=0.0.0.0:19904 \--grpc-address=0.0.0.0:19914 \--index-cache-size=250MB \--sync-block-duration=5m \--min-time=-2w \--max-time=-1h \grpc-address 就是 store api 暴露的端口,也就是 query 中–store 是 xxx:19914的配置。
因为Store gateway需要从网络上拉取大量历史数据加载到内存,因此会大量消耗 cpu 和内存,这个组件也是 thanos 面世时被质疑过的组件,不过当前的性能还算可以,遇到的一些问题后面会提到。 Store gateway也可以无限拓展,拉取同一份 bucket 数据。 放个示意图,一个 Thanos 副本,挂了多个地域的 store 组件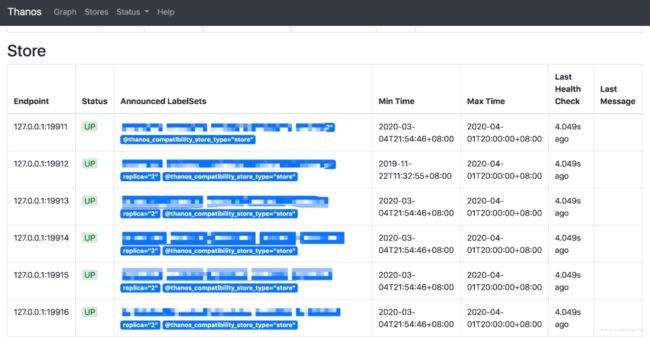
其中一个地域的数据统计:
查询一个月历史数据速度还可以,主要是数据持久化没有运维压力,随意扩展,成本低。
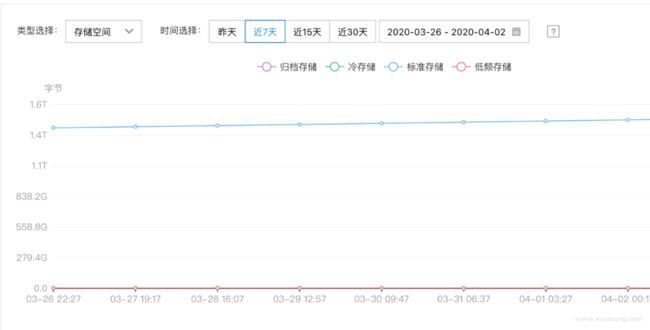
到这里,Thanos 的基本使用就结束了,至于 compact 压缩和 bucket 校验,不是核心功能,compact的资源消耗也特别大,rule组件我们没有使用,就不做介绍了。
第5步:查看数据
有了多地域多副本的数据,就可以结合 Grafana 做全局视图了,比如:
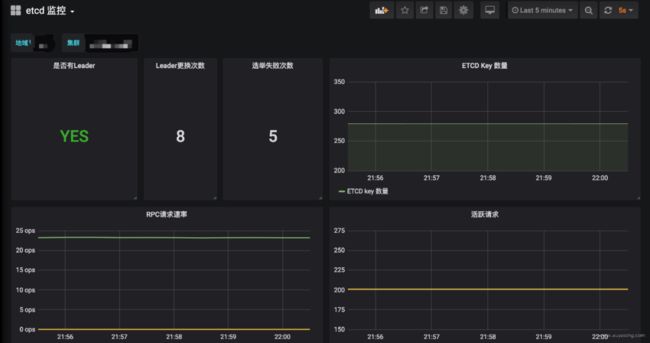
按地域和集群查看 ETCD 的性能指标:
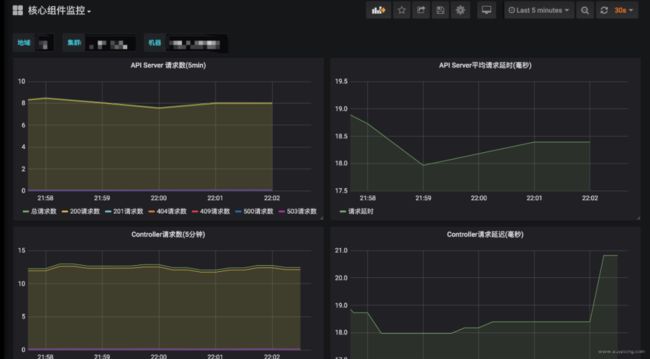
按地域、集群、机器查看核心组件监控,如多副本 Master 机器上的各种性能
数据聚合在一起之后,可以将所有视图都集中展示,比如还有这些面板:
机器监控:node-exporter、process-exporter
POD资源使用: Cadvisor
Docker、kube-proxy、kubelet 监控
scheduler、controller-manager、etcd、apiserver 监控
kube-state-metrics 元信息
K8S Events
mtail 等日志监控
Receive 模式
前面提到的所有组件都是基于 sidecar 模式配置的,但 Thanos 还有一种 Receive 模式,不太常用,只是在Proposals中出现
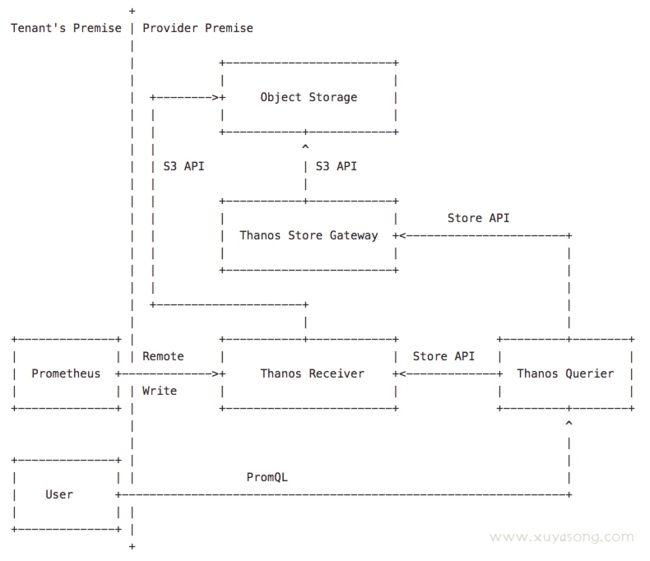
- sidecar 模式有一个缺点:就是2 小时内的数据仍然需要通过 sidecar->Prometheus来获取,也就是仍然依赖 Prometheus,并不是完全的数据在外部存储。如果你的网络只允许你查询特定的存储数据,无法访问到集群内的 Prometheus,那这 2 小时的数据就丢失了,而 Receive 模式采用了remote write 就没有所谓的 2 小时 block 的问题了。
- sidecar 模式对网络连通性是有要求的,如果你是多租户环境或者是云厂商,对象存储(历史数据)query 组件一般在控制面,方便做权限校验和接口服务封装,而 sidecar 和 Prometheus 却在集群内,也就是用户侧。控制面和用户侧的网络有时候会有限制,是不通的,这个时候会有一些限制导致你无法使用 sidecar
- 租户和控制面隔离,和第2条类似,希望数据完全存在控制面,我一直觉得 Receive 就是为了云厂商服务的。。不过 Receive 毕竟不是默认方案,如果不是特别需要还是用默认的 sidecar 为好
一些问题
Prometheus 压缩
压缩:官方文档有提到,使用 sidecar 时,需要将 Prometheus 的 –storage.tsdb.min-block-duration 和 –storage.tsdb.max-block-duration 这两个值设置为2h,两个参数相等才能保证Prometheus 关闭了本地压缩,其实这两个参数在 Prometheus -help 中并没有体现,Prometheus 作者也说明这只是为了开发测试才用的参数,不建议用户修改。而 Thanos 要求关闭压缩是因为 Prometheus 默认会以2,25,25*5的周期进行压缩,如果不关闭,可能会导致 thanos 刚要上传一个 block,这个 block 却被压缩中,导致上传失败。
不过你也不必担心,因为在 sidecar 启动时,会检查这两个参数,如果不合适,sidecar会启动失败
![]()
store-gateway
store-gateway: store 组件资源消耗是最大的,毕竟他要拉取远程数据,并加载到本地供查询,如果你想控制历史数据和缓存周期,可以修改相应的配置,如:
--index-cache-size=250MB \--sync-block-duration=5m \ --min-time=-2w \ 最大查询 1 周--max-time=-1h \store-gateway 默认支持索引缓存,来加快 TSDB 块的查找速度,但有时候启动会占用了大量的内存,在 0.11.0之后的版本做了修复,可以查看这个issue
Prometheus 2.0 已经对存储层进行了优化。例如按照时间和指标名字,连续的尽量放在一起。而 store gateway可以获取存储文件的结构,因此可以很好的将指标存储的请求翻译为最少的 object storage 请求。对于那种大查询,一次可以拿成百上千个 Chunks 数据。
而在 store 的本地,只有 Index 数据是放入 Cache 的,Chunk 数据虽然也可以,但是就要大几个数量级了。目前,从对象存储获取 Chunk 数据只有很小的延时,因此也没什么动力去将 Chunk 数据给 Cache起来,毕竟这个对资源的需求很大。
store-gateway中的数据:

每个文件夹中其实是一个个的索引文件 index.cache.json
compactor组件
Prometheus 数据越来越多,查询一定会越来越慢,Thanos 提供了一个 compactor 组件来处理,他有两个功能,
一个是做压缩,就是把旧的数据不断的合并。
一个是降采样,他会把存储的数据,按照一定的时间,算出最大,最小等值,会根据查询的间隔,进行控制,返回采样的数据,而不是真实的点,在查询特别长的时间的数据的时候,看的主要是趋势,精度是可以选择下降的。
注意的是 Compactor 并不会减少磁盘占用,反而会增加磁盘占用(做了更高维度的聚合)。
thanos 组件的优化并不是万能的,因为业务数据总在增长,这时候可能要考虑业务拆分了。我们需要对业务有一定的划分,不同的业务监控放在不同bucket里(需要改造或者多部署几个 sidecar)。例如有5个 bucket ,再准备5个 store gateway 进行代理查询。减少单个 store 数据过大的问题。
第二个方案是时间切片,也就是上面提到的 store gateway,可以选择查询多长时间的数据。store gateway配置支持两种表达式,一种是基于相对时间的,例如–max-time 是3d前到5d前的。一种是基于绝对时间的,如19年3月1号到19年5月1号。例如想查询3个月的数据,一个 store 可以代理一个月的数据,那么就需要部署3个store来合作。
query 的去重
query 组件启动时,默认会根据 query.replica-label 字段做重复数据的去重,你也可以在页面上勾选deduplication 来决定。query 的结果会根据你的 query.replica-label的 label 选择副本中的一个进行展示。可如果 0,1,2 三个副本都返回了数据,且值不同,query 会选择哪一个展示呢?
Thanos 会基于打分机制,选择更为稳定的 replica 数据, 具体逻辑在:https://github.com/thanos-io/thanos/blob/55cb8ca38b3539381dc6a781e637df15c694e50a/pkg/query/iter.go
参考
https://thanos.io/
https://www.percona.com/blog/2018/09/20/Prometheus-2-times-series-storage-performance-analyses/
https://qianyongchao.blog/2019/01/03/Prometheus-thanos-design-%E4%BB%8B%E7%BB%8D/
https://github.com/thanos-io/thanos/issues/405
https://katacoda.com/bwplotka/courses/thanos
https://medium.com/faun/comparing-thanos-to-victoriametrics-cluster-b193bea1683
https://www.youtube.com/watch?v=qQN0N14HXPM
来源:http://www.xuyasong.com/?p=1925

近期好文: