系统性能典型案例分析:高性能队列Disruptor,一文深入理解
背景
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
Disruptor是一款高性能的有界内存队列,其中包括Apache Storm、Camel、Log4j 2在内的很多知名项目都应用了Disruptor以获取高性能,Disruptor 项目团队曾经写过一篇论文,详细解释了其原因,可以总结为如下:
- 内存分配更加合理,使用 RingBuffer 数据结构,数组元素在初始化时一次性全部创建,提升缓存命中率;对象循环利用,避免频繁 GC。
- 能够避免伪共享,提升缓存利用率。3. 采用无锁算法,避免频繁加锁、解锁的性能消耗。
- 支持批量消费,消费者可以无锁方式消费多个消息。
今天我们先来聊一聊 Disruptor 怎么使用的,好让你们先对 Disruptor 有个提前的认识。
下面是官方出示的代码,我稍微修改了一下,相较而言,Disruptor 的使用比 Java SDK提供 BlockingQueue 要难懂一些,但是总体上来说是差不多的,其大致情况如下:
- 生产者生产的对象称为 Event,使用Disruptor 必须自定义 Event,例如示例代码的自定义 Event 是 LongEvent,这是在 Disruptor 中的。
- 需要传入一个 EventFactory才能构建 Disruptor 对象除了要指定队列大小,还示例代码中传入的是LongEvent::new;
- 消费 Disruptor 中的 Event 需要通过 handleEventsWith() 方法注册一个事件处理器,发布 Event 则需要通过 publishEvent() 方法。
/* 自定义 Event */
class LongEvent {
private long value;
public void set( long value )
{
this.value = value;
}
}
/* 指定 RingBuffer 大小, 9 // 必须是 2 的 N 次方 */
int bufferSize = 1024;
/* 构建 Disruptor */
Disruptor disruptor
= new Disruptor<>(
LongEvent: : new,
bufferSize,
DaemonThreadFactory.INSTANCE );
/* 注册事件处理器 */
disruptor.handleEventsWith(
(event, sequence, endOfBatch) - >
System.out.println( "E: " + event ) );
/* 启动 Disruptor */
disruptor.start();
/* 获取 RingBuffer */
RingBuffer ringBuffer
= disruptor.getRingBuffer();
/* 生产 Event */
ByteBuffer bb = ByteBuffer.allocate( 8 );
for ( long l = 0; true; l++ )
{
bb.putLong( 0, l );
/* 生产者生产消息 */
ringBuffer.publishEvent(
(event, sequence, buffer) - >
event.set( buffer.getLong( 0 ) ), bb );
Thread.sleep( 1000 );
}
RingBuffer 是怎样提升性能的?
Java SDK 中 ArrayBlockingQueue 使用数组作为底层的数据存储,而 Disruptor 是使用RingBuffer作为数据存储。RingBuffer 本质上也是数组,所以仅仅将数据存储从数组换成RingBuffer 并不能提升性能,但是 Disruptor 在 RingBuffer 的基础上还做了很多优化,其中一项优化就是和内存分配有关的。
在介绍这项优化之前,你需要先了解一下程序的局部性原理。简单来讲,程序的局部性原理指的是在一段时间内程序的执行会限定在一个局部范围内。这里的“局部性”可以从两个方面来理解,一个是时间局部性,另一个是空间局部性。
首先是 ArrayBlockingQueue。生产者线程向 ArrayBlockingQueue 增加一个元素,每次增加元素 E 之前,都需要创建一个对象 E,如下图所示,ArrayBlockingQueue 内部有 6个元素这 6 个元素都是由生产者线程创建的,由于创建这些元素的时间基本上是离散的,所以这些元素的内存地址大概率也不是连续的。

接下来我们来看 Disruptor 是怎么处理的。Disruptor 内部的 RingBuffer 也是用数组实现的,但是这个数组中的所有元素在初始化时是一次性全部创建的,所以这些元素的内存地址大概率是连续的,相关的代码如下所示。
Disruptor 内部 RingBuffer 的结构可以简化成下图,那么数组中所有元素内存地址为什么能连续提升性能呢?因在消费者线程在消费时,遵循的是空间局部性原理的,消费完第 1 个元素,很快就会消费第 2 个元素;当消费第 1 个元素 E1 的时候,CPU 会把内存中 E1 后面的数据也加载进 Cache,如果 E1 和 E2 在内存中的地址是连续的,那么 E2 也就会被加载进 Cache 中,然后当消费第 2 个元素的时候,由于 E2 已经在Cache 中了,所以就不需要从内存中加载了,这样性能就能提升了

除此之外,在 Disruptor 中,生产者线程通过 publishEvent() 发布 Event 的时候,并不是创建一个新的 Event,而是通过 event.set() 方法修改 Event, 也就是说 RingBuffer 创建的 Event 是可以循环利用的,这样还能避免频繁创建、删除 Event 导致的频繁 GC 问题。
如何避免“伪共享”
什么是伪共享
ArrayBlockingQueue有三个成员变量: - takeIndex:需要被取走的元素下标 - putIndex:可被元素插入的位置的下标 - count:队列中元素的数量
这三个变量很容易放到一个缓存行中,但是之间修改没有太多的关联。所以每次修改,都会使之前缓存的数据失效,从而不能完全达到共享的效果。
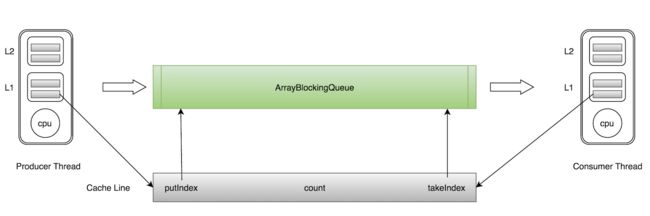
如上图所示,当生产者线程put一个元素到ArrayBlockingQueue时,putIndex会修改,从而导致消费者线程的缓存中的缓存行无效,需要从主存中重新读取。
这种无法充分使用缓存行特性的现象,称为伪共享。
对于伪共享,一般的解决方案是,增大数组元素的间隔使得由不同线程存取的元素位于不同的缓存行上,以空间换时间。
当 CPU 从内存中加载 takeIndex 的时候,会同时将 putIndex 以及 count 都加载进Cache。下图是某个时刻 CPU 中 Cache 的状况,为了简化,缓存行中我们仅列出了takeIndex 和 putIndex。
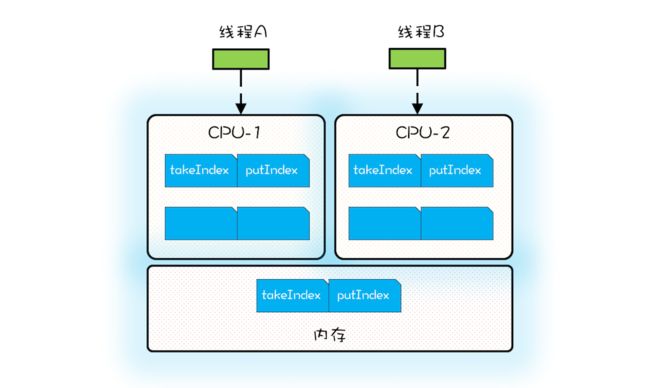
假设线程 A 运行在 CPU-1 上,执行入队操作,入队操作会修改 putIndex,而修改putIndex 会导致其所在的所有核上的缓存行均失效;此时假设运行在 CPU-2 上的线程执行出队操作,出队操作需要读取 takeIndex,由于 takeIndex 所在的缓存行已经失效,所以 CPU-2 必须从内存中重新读取。入队操作本不会修改 takeIndex,但是由于 takeIndex和 putIndex 共享的是一个缓存行,就导致出队操作不能很好地利用 Cache,这其实就是伪共享。简单来讲,伪共享指的是由于共享缓存行导致缓存无效的场景。
ArrayBlockingQueue 的入队和出队操作是用锁来保证互斥的,所以入队和出队不会同时发生。如果允许入队和出队同时发生,那就会导致线程 A 和线程 B 争用同一个缓存行,这样也会导致性能问题。所以为了更好地利用缓存,我们必须避免伪共享,那如何避免呢?
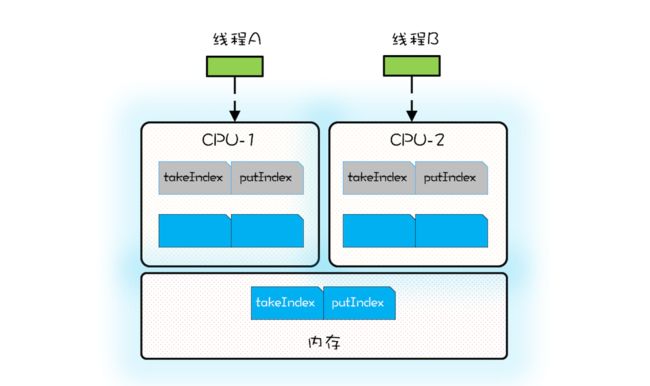
方案很简单,每个变量独占一个缓存行、不共享缓存行就可以了,具体技术是缓存行填充。
/* 前:填充 56 字节 */
class LhsPadding {
long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
volatile long value;
}
/* 后:填充 56 字节 */
class RhsPadding extends Value {
long p9, p10, p11, p12, p13, p14, p15;
}
class Sequence extends RhsPadding {
/* 省略实现 */
}
Disruptor 中的无锁算法
ArrayBlockingQueue 是利用管程实现的,中规中矩,生产、消费操作都需要加锁,实现起来简单,但是性能并不十分理想。Disruptor 采用的是无锁算法,很复杂,但是核心无非是生产和消费两个操作。Disruptor 中最复杂的是入队操作,所以我们重点来看看入队操作是如何实现的。
对于入队操作,最关键的要求是不能覆盖没有消费的元素;对于出队操作,最关键的要求是不能读取没有写入的元素,所以 Disruptor 中也一定会维护类似出队索引和入队索引这样两个关键变量。Disruptor 中的 RingBuffer 维护了入队索引,但是并没有维护出队索引,这是因为在 Disruptor 中多个消费者可以同时消费,每个消费者都会有一个出队索引,所以 RingBuffer 的出队索引是所有消费者里面最小的那一个。
下面是 Disruptor 生产者入队操作的核心代码,看上去很复杂,其实逻辑很简单:如果没有足够的空余位置,就出让 CPU 使用权,然后重新计算;反之则用 CAS 设置入队索引。
/* 生产者获取 n 个写入位置 */
do
{
/* cursor 类似于入队索引,指的是上次生产到这里 */
current = cursor.get();
/*
* 目标是在生产 n 个 6 next = current + n;
* 减掉一个循环
*/
long wrapPoint = next - bufferSize;
/* 获取上一次的最小消费位置 */
long cachedGatingSequence = gatingSequenceCache.get();
/* 没有足够的空余位置 */
if ( wrapPoint > cachedGatingSequence || cachedGatingSequence > current )
{
/* 重新计算所有消费者里面的最小值位置 */
long gatingSequence = Util.getMinimumSequence(
gatingSequences, current );
/* 仍然没有足够的空余位置,出让 CPU 使用权,重新执行下一循环 */
if ( wrapPoint > gatingSequence )
{
LockSupport.parkNanos( 1 );
continue;
}
/* 从新设置上一次的最小消费位置 */
gatingSequenceCache.set( gatingSequence );
} else if ( cursor.compareAndSet( current, next ) )
{
/* 获取写入位置成功,跳出循环 */
break;
}
}
while ( true );
加锁
现实编程过程中,加锁通常会严重地影响性能。线程会因为竞争不到锁而被挂起,等锁被释放的时候,线程又会被恢复,这个过程中存在着很大的开销,并且通常会有较长时间的中断,因为当一个线程正在等待锁时,它不能做任何其他事情。如果一个线程在持有锁的情况下被延迟执行,例如发生了缺页错误、调度延迟或者其它类似情况,那么所有需要这个锁的线程都无法执行下去。如果被阻塞线程的优先级较高,而持有锁的线程优先级较低,就会发生优先级反转。
Disruptor论文中讲述了一个实验:
这个测试程序调用了一个函数,该函数会对一个64位的计数器循环自增5亿次。
机器环境:2.4G 6核
运算: 64位的计数器累加5亿次
|Method | Time (ms) | |— | —| |Single thread | 300| |Single thread with CAS | 5,700| |Single thread with lock | 10,000| |Single thread with volatile write | 4,700| |Two threads with CAS | 30,000| |Two threads with lock | 224,000|
CAS操作比单线程无锁慢了1个数量级;有锁且多线程并发的情况下,速度比单线程无锁慢3个数量级。可见无锁速度最快。
单线程情况下,不加锁的性能 > CAS操作的性能 > 加锁的性能。
在多线程情况下,为了保证线程安全,必须使用CAS或锁,这种情况下,CAS的性能超过锁的性能,前者大约是后者的8倍。
综上可知,加锁的性能是最差的。
总结
Disruptor 在优化并发性能方面可谓是做到了极致,优化的思路大体是两个方面,一个是利用无锁算法避免锁的争用,另外一个则是将硬件(CPU)的性能发挥到极致。尤其是后者,在 Java 领域基本上属于经典之作了。
由于伪共享问题如此重要,所以 Java 也开始重视它了,比如 Java 8 中,提供了避免伪共享的注解:@sun.misc.Contended,通过这个注解就能轻松避免伪共享(需要设置 JVM参数 -XX:-RestrictContended)。不过避免伪共享是以牺牲内存为代价的,所以具体使用的时候还是需要仔细斟酌。