2020-12-24《重学操作系统——上》林䭽 前阿里巴巴高级技术专家(P8)
目录
只做最精炼的知识,让记忆更加深刻,让面试见鬼去吧!!!
《重学操作系统》前阿里巴巴高级技术专家,高级架构师(P8)林䭽 ,为精炼重点,帮助快速消化吸收,整理出上下两部分。
开篇词 | 为什么大厂面试必考操作系统?(了解)
课前必读 | 构建知识体系,可以这样做!(知道)
课程内容&知识体系
我们先来看下这门课程的知识体系结构,分为 8 个模块,39 个课时,具体如下。
总的来说,模块四 ~ 模块七是我们这门课程的核心内容,也是面试的重点考区。设置这块内容的目的是借助操作系统的知识,帮你思考如何解决实战问题,比如我们反复提及的高并发、数据一致性、大数据存储和网络问题等。
梳理一下操作系统整体的知识框架,帮你扫除知识盲区。
思考:进程本身是做什么的?
学习方法:遇到不懂的,我该如何解决自己的问题(思维导图法)?
模块一:(前置知识)计算机组成原理
01 | 计算机是什么:“如何把程序写好”这个问题是可计算的吗?
02 | 程序的执行:相比 32 位,64 位的优势是什么?(上)
冯诺依曼模型
内存
CPU
控制单元和逻辑运算单元
寄存器
总线
输入、输出设备
1. 线路位宽问题第一个问题是,你可能会好奇数据如何通过线路传递。其实是通过操作电压,低电压是 0,高电压是 1。
2. 64 位和 32 位的计算第二个问题是,CPU 的位宽会对计算造成什么影响?
总结关于计算机组成和指令部分,我们就先学到这里。这节课我们通过图灵机和冯诺依曼模型学习了计算机的组成、CPU 的工作原理
03 | 程序的执行:相比 32 位,64 位的优势是什么?(下)
程序的执行过程
详解 a = 11 + 15 的执行过程
指令
总结
64 位和 32 位比较有哪些优势?
07 | 进程、重定向和管道指令:xargs 指令的作用是?
进程(基础篇)
进程相关指令
管道(Pipeline)
输入输出流
重定向
管道的作用和分类
FIFO
使用场景分析
排序
去重
筛选
数行数
中间结果
xargs
管道文件
总结
面试题目:xargs 的作用?
思考题:这段 Shell 程序的作用是什么?
参考解答:
10 | 软件的安装: 编译安装和包管理器安装有什么优势和劣势?
包管理器使用
自动依赖管理
yum
apt
编译安装 Nginx
总结
11 | 高级技巧之日志分析:利用 Linux 指令分析 Web 日志
12 | 高级技巧之集群部署:利用 Linux 指令同时在多台机器部署程序
第一步:搭建学习用的集群
第二步:循环遍历 IP 列表
第三步:创建集群管理账户
课后练习题最后我再给你出一道需要查阅资料的题目:~/.bashrc ~/.bash_profile, ~/.profile 和 /etc/profile 的区别是什么?
06 | 目录结构和文件管理指令:rm / -rf 指令的作用是?
总结
只做最精炼的知识,让记忆更加深刻,让面试见鬼去吧!!!
《重学操作系统》前阿里巴巴高级技术专家,高级架构师(P8)林䭽 ,为精炼重点,帮助快速消化吸收,整理出上下两部分。
开篇词 | 为什么大厂面试必考操作系统?(了解)
任何研发工具学下去也都会碰到操作系统,比如:
MySQL 深入学下去会碰到 InnoDB 文件系统;HBase 深入学下去会有 Hadoop 文件系统(HDFS);Redis 深入学下去会碰到 Linux 的I/O模型;
Docker 深入学下去有 Linux 的命名空间等;甚至 Spring 框架,也需要用到线程池和调度算法。
面试官,我们需要通过操作系统知识判断求职者的综合能力,你可以将这些语言、开发工具用到什么层次?是能够使用还是理解原理,甚至具备系统改造的能力?
学习目标有两个:一是帮助你顺利通过面试、跳槽涨薪;另一个是帮助你提升应对实际工作场景的能力,具体包括以下几点。
提升学习和理解能力:比如学习 Redis 可以理解到日志文件系统层面;学习 Java/Python/Node 等语言可以理解到语言最底层。
提升应用架构能力:比如可以将操作系统的微内核架构迁移到自己设计的系统中。
提升系统稳定性架构能力:比如在多线程设计上更出色,可以帮助同事找到设计漏洞。
提升运维能力:做到可以方便地管理集群和分析日志。
这门课程对标的是架构师层级的基础能力,看个人的接受程度,精选了 80 道左右的大厂面试题,国内大厂研发岗位最为关心的问题,也是大厂面试的热门问题,学完之后大概会在阿里的 P7 及以上层级。拉开个人薪资和团队整体水平差异的分水岭,根本原因就是计算机基础知识的掌握程度,个人能力的高低决定了收入的水平。
课前必读 | 构建知识体系,可以这样做!(知道)
课程内容&知识体系
我们先来看下这门课程的知识体系结构,分为 8 个模块,39 个课时,具体如下。
模块一:(前置知识)计算机组成原理。 如果你对计算机的组成原理中涉及的比如内存、寄存器工作原理、CPU 指令、总线都是怎么工作的这些基本问题,没有搞清楚,大概率会影响你后续对操作系统的学习。因此,在课程开始前,我先来给你一份操作系统的前置知识,帮助你更好地理解后续内容。
模块二:(初探)Linux 指令入门。 这个模块将介绍一些实用的知识,带你入门 Bash 编程,并通过日志分析、性能监控、集群管理等实战场景深入学习 Linux 指令。这些对于日常开发和运维人员来说,都会非常有帮助。
模块三:(总纲)操作系统概述。 这部分帮助你了解操作系统的整体设计,介绍内核、用户空间等基本概念,还会介绍操作系统的分类,以及对比一下市面上的操作系统(如 Windows、Linux、Unix、Android 等),让你对整个操作系统生态能有一个整体的认识。
总的来说,模块四 ~ 模块七是我们这门课程的核心内容,也是面试的重点考区。设置这块内容的目的是借助操作系统的知识,帮你思考如何解决实战问题,比如我们反复提及的高并发、数据一致性、大数据存储和网络问题等。
模块四:(面试重点)进程和线程。 我会针对大家在面试和工作中最常见的并发和数据同步问题,从进程原理、多线程编程、互斥和乐观锁、死锁和饥饿、调度算法、进程通信等多个方面,同时结合一些语言特性(比如 Java 的语言特性)讲解原理、思考方案及对策。
模块五:(面试重点)内存管理。 这部分我们是从页表和 MMU、虚拟化、内存的分配和回收、缓存置换、逃逸分析、三色算法、生代算法等方面入手,帮助你了解内存的工作原理,应对高并发带来的内存使用问题。
模块六:(面试重点)文件系统。 这部分内容我们将从两个方面入手,一方面是通过学习 Linux 的文件目录结构,了解 Linux 下不同的文件目录的功能和作用,帮助你把 Linux 用好;另一个方面,从文件系统的底层设计入手,帮助你了解文件系统的设计思路和原理,并且通过讲解数据库的文件系统,比如 MySQL 的 InnoDb、B+Tree 以及 Hadoop 的 HDFS,帮你把文件系统的知识应用到处理海量数据的领域。
模块七:(面试重点)网络与安全。 这部分讲解面试中常见的互联网协议群、TCP 和 UDP 协议、Linux 的 I/O 模型、公私钥加密体系,以及一些最基本的计算机网络安全知识,帮助你理解操作系统和网络之间的交互,从而更好地利用操作系统知识设计业务系统的网络架构。
模块八:(知识拓展)虚拟化和其他。 最后这部分,我们将从操作系统的角度学习容器化应用(比如 Kubernetes 和 Docker),还会深入讨论 Linux 架构及商业操作系统。这些知识一方面能够帮你和面试官产生更多的共鸣,另一方面还能帮你开拓视野、打开思路,看到未来的发展趋势。
梳理一下操作系统整体的知识框架,帮你扫除知识盲区。
从知识结构上来看,操作系统最核心的部分是进程,因为操作系统自己不能提供服务,它要想实现价值,就必须通过安装在系统中的应用程序。而安装好的应用程序,启动后就成了进程,所以说进程处在操作系统知识体系的核心。
了解了以上内容后,我们围绕进程继续梳理,可以发现:
进程往往要同时做很多事情,比如浏览器同时要处理网络、又要处理鼠标、还要展示内容,因此有了多线程的概念。
进程需要执行用的存储空间,比如需要存程序指令、需要堆栈存执行数据,因此需要内存。
进程需要将一部分数据持久的存储下来,因此需要文件系统。
进程需要和外界通信,其中一种途径就是网络。
开发过程中我们希望进程可以单独部署,于是需要容器。
操作系统内核本身也是一个程序,可以理解成一个进程,它同样是需要单独研究的。
所以,进程是核心,内核、多线程、内存、文件系统、网络、容器和虚拟是配套的能力。
思考:进程本身是做什么的?
答:进程是程序的执行副本,操作系统用进程来分配资源。(先记住,待补充)
学习方法:遇到不懂的,我该如何解决自己的问题(思维导图法)?
程序员最重要的是搜索知识的能力,我非常赞同这个说法,此外,我认为如果你想要长远发展,还应同时具备用结构化的思维去构建知识体系的能力。因为知识成体系后,会形成关联记忆和整体的理解,这种经过深度思考和梳理过的知识才能转化为自己的储备。
下面请你跟我一起进入到场景中,跟着我的思路把你的大脑运转起来。假设,在工作的过程中,我遇到了一块不懂的知识,其中有一个技术名词我不了解它的作用,比如 ReentrantLockLock,那么我该如何解决自己的问题呢?
注意: 你也可以把它替换成任意一个陌生的或者你不理解的技术名词。
首先我会去查阅它的官方文档,然后发现了以下这些线索:
构造函数上有个参数在配置锁的公平性;
ReentrantLockLock 是可重入的;
功能类似 synchronized 关键字,但是更灵活;
支持 lock、unlock、tryLock 等方法;
底层是 AbstractQueuedSynchronizer。
接着,根据我获得的知识,追溯 synchronized 关键字,发现 ReentrantLockLock 都说自己的底层是 AbstractQueuedSynchronizer(AQS),我感觉到 AQS 应该是一个重要的东西。
然后我会去查资料验证我的猜测。这时候,我又得到了一个新的信息:发现AQS是用来实现信号量、条件变量以及其他锁的一个编程框架。
假设我还不知道信号量、条件变量和锁是什么,于是我通过搜索资料,发现这些名词通通指向一门科学,也就是操作系统。
接下来,我会去挑选一门讲操作系统的在线课程或者买一本书来查阅,经过查阅发现这些名词出现在进程和多线程这个部分。然后我翻阅了这两个章节的内容,发现了更多我不知道的知识,比如死锁和饥饿、信号量、竞争条件和临界区、互斥的实现,以及最底层的 CPU 指令。
经过以上过程的推导,我开始在脑海中梳理这些知识点,然后动笔画出了一幅基于思考过程的思维导图,将这些知识点串联起来,如下图所示:

这时候,我发现公平锁、可重入锁其实都是锁的一种实现,而 Java 中实现锁这个机制用的是 AQS,而 AQS 最基本的问题是要解决资源竞争的问题。
通过学习,我发现资源竞争的问题在操作系统里叫作竞争条件,解决方案是让临界区互斥。让临界区互斥可以用算法的实现,但是为了执行效率,更多的情况是利用 CPU 指令。Java 里用于实现互斥的原子操作 CAS,也是基于 CPU 指令的。
操作系统在解决了互斥问题的基础上,还提供了解决更复杂问题的数据结构,比如说信号量、竞争条件等;而程序语言也提供了数据结构,比如说可重入锁、公平锁。

模块一:(前置知识)计算机组成原理
01 | 计算机是什么:“如何把程序写好”这个问题是可计算的吗?
答:计算机能力也是有边界的。哥德尔的不完备性定理,让大家看到了世界上还有大量不可计算的问题。哪些问题可以被计算,哪些不可以被计算,这就是可计算性理论,我们可以把世界上想解决的事情都称作问题,解决问题往往需要消耗芯片的计算能力,这通常称作时间开销,另外解决问题还需要消耗内存,称作空间开销。从绝对的对错角度去看,这是一个不可计算问题,因为它没有办法被完全解决;但是从图灵测试层面来看,虽然目前无法解决这个问题,但是我们有理由相信,在未来,计算机对这个问题的解决方案,是可以超过人类的。
02 | 程序的执行:相比 32 位,64 位的优势是什么?(上)
答:没有说清楚 32、64 位指的是操作系统、是软件、还是 CPU?如果是软件,那么我们的数据库有 32 位和 64 位版本;如果是操作系统,那么在阿里云上选择 Centos 和 Debian 版本的时候,也会有 32/64 版本;如果是 CPU,那么有 32 位 CPU,也有 64 位 CPU。
冯诺依曼模型

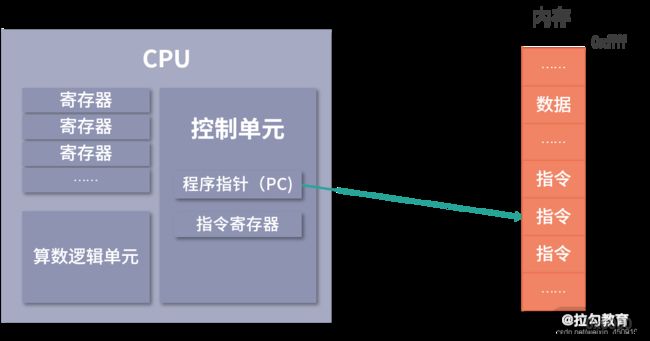
计算机结构分成以下 5 个部分:输入设备;输出设备;内存;中央处理器;总线。这个模型也被称为冯诺依曼模型,下面我们具体来看看这 5 部分的作用。
内存
在冯诺依曼模型中,程序和数据被存储在一个被称作内存的线性排列存储区域。存储的数据单位是一个二进制位,英文是 bit。最小的存储单位叫作字节,也就是 8 位,英文是 byte,每一个字节都对应一个内存地址。内存地址由 0 开始编号,比如第 1 个地址是 0,第 2 个地址是 1, 然后自增排列,最后一个地址是内存中的字节数减 1。
我们通常说的内存都是随机存取器,也就是读取任何一个地址数据的速度是一样的,写入任何一个地址数据的速度也是一样的。
CPU
冯诺依曼模型中 CPU 负责控制和计算。为了方便计算较大的数值,CPU 每次可以计算多个字节的数据。
如果 CPU 每次可以计算 4 个 byte,那么我们称作 32 位 CPU;如果 CPU 每次可以计算 8 个 byte,那么我们称作 64 位 CPU。这里的 32 和 64,称作 CPU 的位宽。
为什么 CPU 要这样设计呢? 因为一个 byte 最大的表示范围就是 0~255。比如要计算 20000*50,就超出了byte 最大的表示范围了。因此,CPU 需要支持多个 byte 一起计算。当然,CPU 位数越大,可以计算的数值就越大。但是在现实生活中不一定需要计算这么大的数值。比如说 32 位 CPU 能计算的最大整数是 4294967295,这已经非常大了。
控制单元和逻辑运算单元
CPU 中有一个控制单元专门负责控制 CPU 工作;还有逻辑运算单元专门负责计算。具体的工作原理我们在指令部分给大家分析。
寄存器
CPU 要进行计算,比如最简单的加和两个数字时,因为 CPU 离内存太远,所以需要一种离自己近的存储来存储将要被计算的数字。这种存储就是寄存器。寄存器就在 CPU 里,控制单元和逻辑运算单元非常近,因此速度很快。
寄存器中有一部分是可供用户编程用的,比如用来存加和指令的两个参数,是通用寄存器。
还有一部分寄存器有特殊的用途,叫作特殊寄存器。比如程序指针,就是一个特殊寄存器。它存储了 CPU 要执行的下一条指令所在的内存地址。注意,程序指针不是存储了下一条要执行的指令,此时指令还在内存中,程序指针只是存储了下一条指令的地址。
下一条要执行的指令,会从内存读入到另一个特殊的寄存器中,这个寄存器叫作指令寄存器。指令被执行完成之前,指令都存储在这里。
总线
CPU 和内存以及其他设备之间,也需要通信,因此我们用一种特殊的设备进行控制,就是总线。总线分成 3 种:
一种是地址总线,专门用来指定 CPU 将要操作的内存地址。还有一种是数据总线,用来读写内存中的数据。当 CPU 需要读写内存的时候,先要通过地址总线来指定内存地址,再通过数据总线来传输数据。最后一种总线叫作控制总线,用来发送和接收关键信号,比如后面我们会学到的中断信号,还有设备复位、就绪等信号,都是通过控制总线传输。同样的,CPU 需要对这些信号进行响应,这也需要控制总线。
输入、输出设备
输入设备向计算机输入数据,计算机经过计算,将结果通过输出设备向外界传达。如果输入设备、输出设备想要和 CPU 进行交互,比如说用户按键需要 CPU 响应,这时候就需要用到控制总线。
到这里,相信你已经对冯诺依曼模型的构造有了一定的了解。这里我再强调几个问题:
1. 线路位宽问题
第一个问题是,你可能会好奇数据如何通过线路传递。其实是通过操作电压,低电压是 0,高电压是 1。
如果只有一条线路,每次只能传递 1 个信号,因为你必须在 0,1 中选一个。比如你构造高高低低这样的信号,其实就是 1100,相当于你传了一个数字 10 过去。大家注意,这种传递是相当慢的,因为你需要传递 4 次。
这种一个 bit 一个 bit 发送的方式,我们叫作串行。如果希望每次多传一些数据,就需要增加线路,也就是需要并行。
如果只有 1 条地址总线,那每次只能表示 0-1 两种情况,所以只能操作 2 个内存地址;如果有 10 条地址总线,一次就可以表示 210 种情况,也就是可以操作 1024 个内存地址;如果你希望操作 4G 的内存,那么就需要 32 条线,因为 232 是 4G。
到这里,你可能会问,那我串行发送行不行?当然也不是不行,只是速度会很慢,因为每多增加一条线路速度就会翻倍。
2. 64 位和 32 位的计算
第二个问题是,CPU 的位宽会对计算造成什么影响?
我们来看一个具体场景:要用 32 位宽的 CPU,加和两个 64 位的数字。
32 位宽的 CPU 控制 40 位宽的地址总线、数据总线工作会非常麻烦,需要双方制定协议。 因此通常 32 位宽 CPU 最多操作 32 位宽的地址总线和数据总线。
因此必须把两个 64 位数字拆成 2 个 32 位数字来计算,这样就需要一个算法,比如用像小时候做加法竖式一样,先加和两个低位的 32 位数字,算出进位,然后加和两个高位的 32 位数字,最后再加上进位。
而 64 位的 CPU 就可以一次读入 64 位的数字,同时 64 位的 CPU 内部的逻辑计算单元,也支持 64 位的数字进行计算。但是你千万不要仅仅因为位宽的区别,就认为 64 位 CPU 性能比 32 位高很多。
要知道大部分应用不需要计算超过 32 位的数字,比如你做一个电商网站,用户的金额通常是 10 万以下的,而 32 位有符号整数,最大可以到 20 亿。所以这样的计算在 32 位还是 64 位中没有什么区别。
还有一点要注意,32 位宽的 CPU 没办法控制超过 32 位的地址总线、数据总线工作。比如说你有一条 40 位的地址总线(其实就是 40 条线),32 位的 CPU 没有办法一次给 40 个信号,因为它最多只有 32 位的寄存器。因此 32 位宽的 CPU 最多操作 232 个内存地址,也就是 4G 内存地址。
总结
关于计算机组成和指令部分,我们就先学到这里。这节课我们通过图灵机和冯诺依曼模型学习了计算机的组成、CPU 的工作原理
03 | 程序的执行:相比 32 位,64 位的优势是什么?(下)
程序的执行过程
当 CPU 执行程序的时候:
1.首先,CPU 读取 PC 指针指向的指令,将它导入指令寄存器。具体来说,完成读取指令这件事情有 3 个步骤:
步骤 1:CPU 的控制单元操作地址总线指定需要访问的内存地址(简单理解,就是把 PC 指针中的值拷贝到地址总线中)。
步骤 2:CPU 通知内存设备准备数据(内存设备准备好了,就通过数据总线将数据传送给 CPU)。
步骤 3:CPU 收到内存传来的数据后,将这个数据存入指令寄存器。
完成以上 3 步,CPU 成功读取了 PC 指针指向指令,存入了指令寄存器。
2.然后,CPU 分析指令寄存器中的指令,确定指令的类型和参数。
3.如果是计算类型的指令,那么就交给逻辑运算单元计算;如果是存储类型的指令,那么由控制单元执行。
4.PC 指针自增,并准备获取下一条指令。
比如在 32 位的机器上,指令是 32 位 4 个字节,需要 4 个内存地址存储,因此 PC 指针会自增 4。
内存虽然是一个随机存取器,但是我们通常不会把指令和数据存在一起,这是为了安全起见。具体的原因我会在模块四进程部分展开讲解,欢迎大家在本课时的留言区讨论起来,我会结合你们留言的内容做后续的课程设计。
程序指针也是一个寄存器,64 位的 CPU 会提供 64 位的寄存器,这样就可以使用更多内存地址。特别要说明的是,64 位的寄存器可以寻址的范围非常大,但是也会受到地址总线条数的限制。比如和 64 位 CPU 配套工作的地址总线只有 40 条,那么可以寻址的范围就只有 1T,也就是 240。
从 PC 指针读取指令、到执行、再到下一条指令,构成了一个循环,这个不断循环的过程叫作CPU 的指令周期,下面我们会详细讲解这个概念。
详解 a = 11 + 15 的执行过程
上面我们了解了基本的程序执行过程,接下来我们来看看如果用冯诺依曼模型执行a=11+15是一个怎样的过程。
我们再 Review 下这个问题:程序员写的程序a=11+15是字符串,CPU 不能执行字符串,只能执行指令。所以这里需要用到一种特殊的程序——编译器。编译器的核心能力是翻译,它把一种程序翻译成另一种程序语言。
这里,我们需要编译器将程序员写的程序翻译成 CPU 认识的指令(指令我们认为是一种低级语言,我们平时书写的是高级语言)。你可以先跟我完整地学完操作系统,再去深入了解编译原理的内容。
下面我们来详细阐述 a=11+15 的执行过程:
1.编译器通过分析,发现 11 和 15 是数据,因此编译好的程序启动时,会在内存中开辟出一个专门的区域存这样的常数,这个专门用来存储常数的区域,就是数据段,如下图所示:
11 被存储到了地址 0x100;
15 被存储到了地址 0x104;
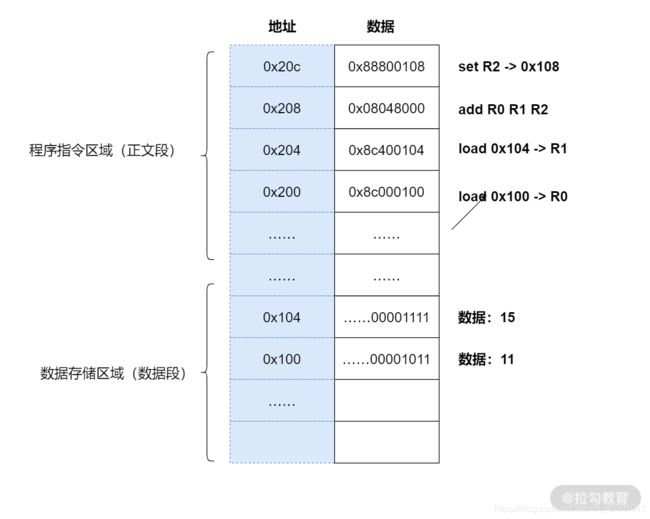
2.编译器将a=11+15转换成了 4 条指令,程序启动后,这些指令被导入了一个专门用来存储指令的区域,也就是正文段。如上图所示,这 4 条指令被存储到了 0x200-0x20c 的区域中:
0x200 位置的 load 指令将地址 0x100 中的数据 11 导入寄存器 R0;
0x204 位置的 load 指令将地址 0x104 中的数据 15 导入寄存器 R1;
0x208 位置的 add 指令将寄存器 R0 和 R1 中的值相加,存入寄存器 R2;
0x20c 位置的 store 指令将寄存器 R2 中的值存回数据区域中的 0x1108 位置。
3.具体执行的时候,PC 指针先指向 0x200 位置,然后依次执行这 4 条指令。
这里还有几个问题要说明一下:
变量 a 实际上是内存中的一个地址,a 是给程序员的助记符。
为什么 0x200 中代表加载数据到寄存器的指令是 0x8c000100,我们会在下面详细讨论。
不知道细心的同学是否发现,在上面的例子中,我们每次操作 4 个地址,也就是 32 位,这是因为我们在用 32 位宽的 CPU 举例。在 32 位宽的 CPU 中,指令也是 32 位的。但是数据可以小于 32 位,比如可以加和两个 8 位的字节。
关于数据段和正文段的内容,会在模块四进程和线程部分继续讲解。
指令
接下来我会带你具体分析指令的执行过程。
在上面的例子中,load 指令将内存中的数据导入寄存器,我们写成了 16 进制:0x8c000100,拆分成二进制就是:
这里大家还是看下图,需要看一下才能明白。

最左边的 6 位,叫作操作码,英文是 OpCode,100011 代表 load 指令;
中间的 4 位 0000是寄存器的编号,这里代表寄存器 R0;
后面的 22 位代表要读取的地址,也就是 0x100。
所以我们是把操作码、寄存器的编号、要读取的地址合并到了一个 32 位的指令中。
我们再来看一条求加法运算的 add 指令,16 进制表示是 0x08048000,换算成二进制就是:

最左边的 6 位是指令编码,代表指令 add;
紧接着的 4 位 0000 代表寄存器 R0;
然后再接着的 4 位 0001 代表寄存器 R1;
再接着的 4 位 0010 代表寄存器 R2;
最后剩下的 14 位没有被使用。
构造指令的过程,叫作指令的编码,通常由编译器完成;解析指令的过程,叫作指令的解码,由 CPU 完成。由此可见 CPU 内部有一个循环:
首先 CPU 通过 PC 指针读取对应内存地址的指令,我们将这个步骤叫作 Fetch,就是获取的意思。
CPU 对指令进行解码,我们将这个部分叫作 Decode。
CPU 执行指令,我们将这个部分叫作 Execution。
CPU 将结果存回寄存器或者将寄存器存入内存,我们将这个步骤叫作 Store。
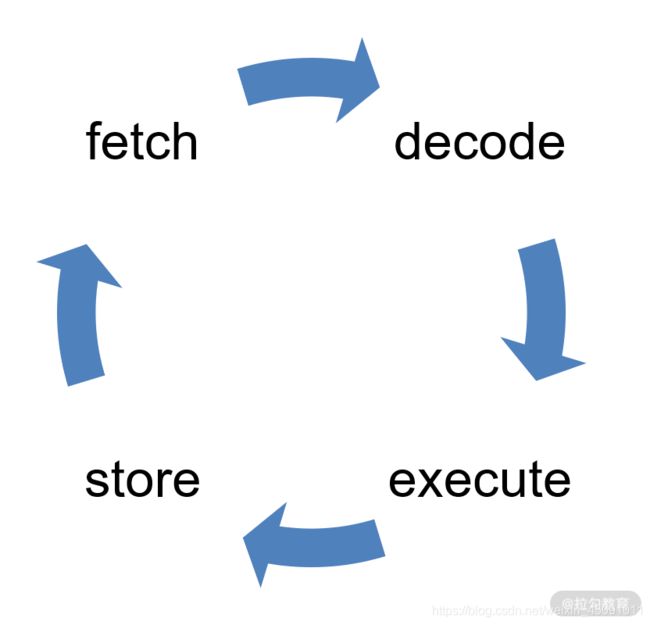
上面 4 个步骤,我们叫作 CPU 的指令周期。CPU 的工作就是一个周期接着一个周期,周而复始。
指令的类型
通过上面的例子,你会发现不同类型(不同 OpCode)的指令、参数个数、每个参数的位宽,都不一样。而参数可以是以下这三种类型:
寄存器;
内存地址;
数值(一般是整数和浮点)。
当然,无论是寄存器、内存地址还是数值,它们都是数字。
指令从功能角度来划分,大概有以下 5 类:
I/O 类型的指令,比如处理和内存间数据交换的指令 store/load 等;再比如将一个内存地址的数据转移到另一个内存地址的 mov 指令。
计算类型的指令,最多只能处理两个寄存器,比如加减乘除、位运算、比较大小等。
跳转类型的指令,用处就是修改 PC 指针。比如编程中大家经常会遇到需要条件判断+跳转的逻辑,比如 if-else,swtich-case、函数调用等。
信号类型的指令,比如发送中断的指令 trap。
闲置 CPU 的指令 nop,一般 CPU 都有这样一条指令,执行后 CPU 会空转一个周期。
指令还有一个分法,就是寻址模式,比如同样是求和指令,可能会有 2 个版本:
将两个寄存器的值相加的 add 指令。
将一个寄存器和一个整数相加的 addi 指令。
另外,同样是加载内存中的数据到寄存器的 load 指令也有不同的寻址模式:
比如直接加载一个内存地址中的数据到寄存器的指令la,叫作直接寻址。
直接将一个数值导入寄存器的指令li,叫作寄存器寻址。
将一个寄存器中的数值作为地址,然后再去加载这个地址中数据的指令lw,叫作间接寻址。
因此寻址模式是从指令如何获取数据的角度,对指令的一种分类,目的是给编写指令的人更多选择。
了解了指令的类型后,我再强调几个细节问题:
关于寻址模式和所有的指令,只要你不是嵌入式开发人员,就不需要记忆,理解即可。
不同 CPU 的指令和寄存器名称都不一样,因此这些名称也不需要你记忆。
有几个寄存器在所有 CPU 里名字都一样,比如 PC 指针、指令寄存器等。
指令的执行速度
之前我们提到过 CPU 是用石英晶体产生的脉冲转化为时钟信号驱动的,每一次时钟信号高低电平的转换就是一个周期,我们称为时钟周期。CPU 的主频,说的就是时钟信号的频率。比如一个 1GHz 的 CPU,说的是时钟信号的频率是 1G。
到这里你可能会有疑问:是不是每个时钟周期都可以执行一条指令?其实,不是的,多数指令不能在一个时钟周期完成,通常需要 2 个、4 个、6 个时钟周期。
总结
接下来我们来做一个总结。这节课我们深入讨论了指令和指令的分类。接下来,我们来看一看在 02 课时中留下的问题:
64 位和 32 位比较有哪些优势?
【解析】 其实,这个问题需要分类讨论:
如果说的是 64 位宽 CPU,那么有 2 个优势:
优势 1:64 位 CPU 可以执行更大数字的运算,这个优势在普通应用上不明显,但是对于数值计算较多的应用就非常明显。
优势 2:64 位 CPU 可以寻址更大的内存空间
如果 32 位/64 位说的是程序,那么说的是指令是 64 位还是 32 位的。32 位指令在 64 位机器上执行,困难不大,可以兼容。 如果是 64 位指令,在 32 位机器上执行就困难了。因为 32 位指令在 64 位机器执行的时候,需要的是一套兼容机制;但是 64 位指令在 32 位机器上执行,32 位的寄存器都存不下指令的参数。
操作系统也是一种程序,如果是 64 位操作系统,也就是操作系统中程序的指令都是 64 位指令,因此不能安装在 32 位机器上。
思考题
最后再给你出一道思考题:CPU 中有没有求对数的指令?如果没有那么程序如何去计算?
04 | 构造复杂的程序:将一个递归函数转成非递归函数的通用方法
05 | 存储器分级:L1 Cache 比内存和 SSD 快多少倍?
加餐 | 练习题详解(一)
模块二: Linux 指令入门
06 | 目录结构和文件管理指令:rm / -rf 指令的作用是?
07 | 进程、重定向和管道指令:xargs 指令的作用是?
这个指令是和管道一起使用,因此就引出了这节课的主题:管道。学习管道相关的内容,还需要你理解进程、标准流和重定向。
进程(基础篇)
应用的可执行文件是放在文件系统里,(定义:)把可执行文件启动,就会在操作系统的内存中形成一个应用的副本,这个副本就是进程。
面试题:什么是进程?可以回答:进程是应用的执行副本;而不要回答进程是操作系统分配资源的最小单位。前者是定义,后者是作用*。
*ps如果你要看当前的进程,可以用ps指令。p 代表 processes,也就是进程;s 代表 snapshot,也就是快照。所谓快照,就是像拍照一样。不带任何参数的ps指令显示的是同一个电传打字机(TTY上)的进程。TTY 是一个输入输出终端的概念,比如用户打开 bash,操作系统就为用户分配了一个输入输出终端。没有加任何参数的ps只显示在同一个 TTY 的进程。想看到所有的进程,可以用ps -e,-e没有特殊含义,只是为了和-A区分开。我们通常不直接用ps -e而是用ps -ef,这是因为-f可以带上更多的描述字段,ps aux,它和ps -ef能力差不多,但是是 BSD 风格的。top和ps能力差不多,但是显示的不是快照而是实时更新数据的top指令。(第四张)htop的指令,需在centos7中安装 htop:yum install -y 为什么 Linux 的 htop 命令完胜 top 命令,htop,top加强版,颜色显示不同参数,且支持鼠标操作。

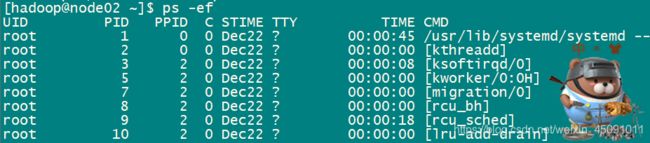

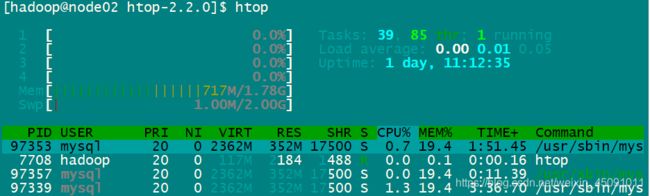
| UID | 进程的所有者 | STIME | 开始时间 |
| PID | 进程的唯一标识 | TIME | 时间 |
| PPID | 进程的父进程 | TTY | 进程所在的 TTY,如果没有 TTY 就是? |
| C | CPU占用 | CMD | 进程启动时的命令。如果不是一个 Shell 命令,而是用方括号括起来,那就是系统进程或者内核过程。 |
进程相关指令

我们从上往下对这张表进行讲解:
top 命令可以做到实时显示系统中各个进程的资源占用状况,后面是它的使用用例,如 top 或 top -p pid 对应的 pid 来展示某一个进程的使用状态。
ps 命令,它也用来展示进程的状态,不过它是显示瞬间进程的状态 。我们可以通过 ps –ef、ps -aux 参数把某一个时态的操作系统的进程状态全部获取出来。
strace 命令主要用来跟踪一个进程调用系统底层模块的过程,我们可以通过 strace+ 具体进程执行的命令,去跟踪对应进程对系统的调用。
free 命令统计系统内存使用情况。
iostat 主要用来监视操作系统上,磁盘操作的活动情况。
vmstat 主要用来监控内存、进程、CPU 的活动状态。
ldd 用来监控一个进程在启动运行时所需要的一些共享库。后面有一个用例,比如我们这里执行 ldd test 这个命令,那么它就会查看 test 进程在启用时,需要调用到操作系统的哪些共享库。
管道(Pipeline)
作用是在命令和命令之间,传递数据。比如说一个命令的结果,就可以作为另一个命令的输入。这里说的命令就是进程。更准确地说,管道在进程间传递数据。
输入输出流
每个进程拥有自己的标准输入流、标准输出流、标准错误流。这几个标准流说起来很复杂,但其实都是文件。
标准输入流(用 0 表示)可以作为进程执行的上下文(进程执行可以从输入流中获取数据)。
标准输出流(用 1 表示)中写入的结果会被打印到屏幕上。如果进程在执行过程中发生异常,那么异常信息会被记录到标准错误流(用 2 表示)中。
重定向
我们执行一个指令,比如ls -l,结果会写入标准输出流,进而被打印。这时可以用重定向符将结果重定向到一个文件,比如说ls -l > out,这样out文件就会有ls -l的结果;而屏幕上也不会再打印ls -l的结果。

>符号叫作覆盖重定向,每次都会把目标文件覆盖;>>叫作追加重定向,在目标文件中追加。比如你每次启动一个程序日志都写入/var/log/somelogfile中,可以这样操作,每次执行程序日志就不会被覆盖了:
start.sh >> /var/log/somelogfile
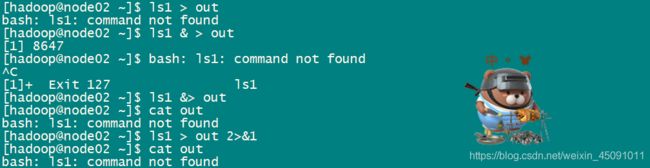
还有一种情况,比如我们输入ls1> out ,结果并不会存入out文件,因为ls1指令是不存在的。结果会输出到标准错误流中,仍然在屏幕上。
ls1 > out这里我们可以把标准错误流也重定向到标准输出流,然后再重定向到文件。ls1 &> out 写法等价于:ls1 > out 2>&1,因为ls1 >out出错了,所以标准错误流被定向到了标准输出流,而 2>&1相当于把ls1 的标准输出流重定向到out文件,&代表一种引用关系,具体代表的是ls1 >out的标准输出流。
管道的作用和分类
管道(Pipeline)将一个进程的输出流定向到另一个进程的输入流,就像水管一样,作用就是把这两个文件接起来。如果一个进程输出了一个字符 X,那么另一个进程就会获得 X 这个输入。
管道和重定向很像,但是管道是一个连接一个进行计算,重定向是将一个文件的内容定向到另一个文件,这二者经常会结合使用。
Linux 中的管道也是文件,有两种类型的管道:
匿名管道(Unnamed Pipeline),这种管道也在文件系统中,但是它只是一个存储节点,不属于任何一个目录。说白了,就是没有路径。命名管道(Named Pipeline),这种管道就是一个文件,有自己的路径。
FIFO
管道具有 FIFO(First In First Out),FIFO 和排队场景一样,先排到的先获得。所以先流入管道文件的数据,也会先流出去传递给管道下游的进程。
使用场景分析
排序
用ls,希望按照文件名排序倒序,可以使用匿名管道,将ls的结果传递给sort指令去排序。

去重
另一个比较常见的场景是去重,比如有一个字典文件,里面都是词语。如下所示:
Apple
Banana
Apple
Banana
Cat
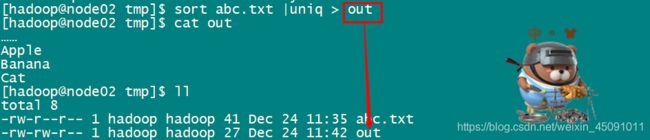
……如果我们想要去重可以使用uniq指令,uniq指令能够找到文件中相邻的重复行,然后去重。但是我们上面的文件重复行是交替的,所以不可以直接用uniq,因此可以先sort这个文件,然后管道将sort的结果重定向到uniq指令。指令如下:

还可以输出到结果文件:
筛选
根据正则模式筛选对应的内容。比如想找到项目文件下所有文件名中含有Spring的文件。就可以利用grep指令,操作如下:
#find ./递归列出当前目录下所有目录中的文件。grep从find的输出流中找出含有Spring关键字的行
find ./ |grep Spring
#包含Spring但不包含MyBatis,grep -v是匹配不包含 MyBatis 的结果
find ./ | grep Spring | grep -v MyBatis 数行数
想知道文件里面有多少行,就可以使用wc -l指令,如下所示:
但是如果你想知道当前目录下有多少个文件,可以用ls | wc -l,如下所示:

当前java的项目目录下有多少行代码?使用下面这个指令:
中间结果
管道一个接着一个,是一个计算逻辑。有时候我们想要把中间的结果保存下来,这就需要用到tee指令。tee指令从标准输入流中读取数据到标准输出流。tee还能利用这个过程把输入流中读取到的数据存到文件中。比如下面这条指令:
# 从当前目录中找到所有含有 Spring 关键字的 Java 文件
find ./ -i "*.java" | tee JavaList | grep Spring
# tee 本身不影响指令的执行,但是 tee 会把 find 指令的结果保存到 JavaList 文件中。tee这个执行就像英文字母中的 T 一样,连通管道两端,下面又开了口。这个开口,在函数式编程里面叫作副作用。
xargs
xargs指令从标准数据流中构造并执行一行行的指令。即从输入流获取字符串,然后利用空白、换行符等切割字符串,在这些字符串的基础上构造指令,最后一行行执行这些指令。
如果我们重命名当前目录下的所有 .a 的文件,想在这些文件前面加一个前缀prefix_。比如说x.a文件需要重命名成prefix_x.a,我们就可以用xargs指令构造模块化的指令。
现在我们有x.a、y.a、z.a三个文件,然后使用下图中的指令构造我们需要的指令:

-
我们用
ls找到所有的文件; -
-I参数是查找替换符,这里我们用GG替代ls找到的结果;-I GG后面的字符串 GG 会被替换为x.a、x.b或x.z; -
echo是一个在命令行打印字符串的指令。使用echo主要是为了安全,帮助我们检查指令是否有错误。
我们用xargs构造了 3 条指令。如果你没有用xargs指令,而是用一条条mv指令去敲,这样就叫做样板代码。
最后去掉 echo,就是我们想要的结果,如下所示:

管道文件
匿名管道,用|就可以创造和使用,利用了文件系统的能力,是一种文件结构。当你学到模块六文件系统的内容,会知道匿名管道拥有一个自己的inode,但不属于任何一个文件夹。
还有一种管道叫作命名管道(Named Pipeline)。命名管道是要挂到文件夹中的,因此需要创建。用mkfifo指令可以创建一个命名管道,下面我们来创建一个叫作pipe1的命名管道,如下图所示:

命名管道和匿名管道能力类似,可以连接一个输出流到另一个输入流,也是 First In First Out。当执行cat pipe1的时候,你可以观察到,当前的终端处于等待状态。因为我们cat pipe1的时候pipe1中没有内容,另开一个终端去写一点东西到pipe中,比如:

这个时候,cat pipe1就会返回,并打印出xxx。我们可以在cat pipe1后面增加了一个&符号,代表指令在后台执行,不会阻塞用户继续输入。然后我们通过echo指令往pipe1中写入东西,接着就会看到xxx被打印出来。
总结
这节课我们为了学习管道,先简单接触了进程的概念,然后学习了重定向。之后我们学习了匿名管道的应用场景,匿名管道帮助我们把 Linux 指令串联起来形成很强的计算能力。特别是xargs指令支持模板化的生成指令,拓展了指令的能力。最后我们还学习了命名管道,命名管道让我们可以真实拿到一个管道文件,让多个程序之间可以方便地进行通信。
面试题目:xargs 的作用?
【解析】 xargs 将标准输入流中的字符串分割成一条条子字符串,然后再按照我们自己想要的方式构建成一条条指令,大大拓展了 Linux 指令的能力。比如我们可以用来按照某种特定的方式逐个处理一个目录下所有的文件;根据一个 IP 地址列表逐个 ping 这些 IP,收集到每个 IP 地址的延迟等。
思考题:这段 Shell 程序的作用是什么?
mkfifo pipe1
mkfifo pipe2
echo -n run | cat - pipe1 > pipe2 &
cat pipe1

参考解答:
前 2 行代码创建了两个管道文件。
从第 3 行开始,代码变得复杂。echo -n run就是向输出流中写入一个run字符串(不带回车,所以用-n)。通过管道,将这个结果传递给了cat。cat是 concatenate 的缩写,意思是把文件粘在一起。
当cat用>重定向输出到一个管道文件时,如果没有其他进程从管道文件中读取内容,cat会阻塞。
当cat用<读取一个管道内容时,如果管道中没有输入,也会阻塞。
从这个角度来看,总共有 3 次重定向:
将-也就是输入流的内容和pipe1内容合并重定向到pipe2;将pipe2内容重定向到cat;将cat的内容重定向到pipe1。
仔细观察下路径:pipe1->pipe2->pipe1,构成了一个循环。 这样导致管道pipe1管道pipe2中总是有数据(没有数据的时间太短)。于是,就构成了一个无限循环。我们打开执行这个程序后,可以用htop查看当前的 CPU 使用情况,会发现 CPU 占用率很高。
上次学习
08 | 用户和权限管理指令: 请简述 Linux 权限划分的原则?
09 | Linux 中的网络指令:如何查看一个域名有哪些 NS 记录?
10 | 软件的安装: 编译安装和包管理器安装有什么优势和劣势?
Linux 上安装程序大概有 2 种思路:直接编译源代码;使用包管理器。实战的例子:如何编译安装nginx
包管理器使用
Linux 下的应用程序多数以软件包的形式发布,用户拿到对应的包之后,使用包管理器进行安装。说到包管理器,就要提到dpkg和rpm。Linux 下两大主流的包就是rpm和dpkg。
dpkg(debian package),linux一个主流的社区分支开发出来的。一般衍生于debian的 Linux 版本都支持dpkg,如ubuntu。
rpm(redhatpackage manager)red hat公司的包管理。
dpkg还是rpm都抽象了自己的包格式,就是以.dpkg或者.rpm结尾的文件。
dpkg和rpm也都提供了类似的能力:
-
查询是否已经安装了某个软件包;查询目前安装了什么软件包;给定一个软件包,进行安装;删除一个安装好的软件包。
关于dpkg和rpm的具体用法,你可以用man进行学习。
自动依赖管理
Linux 是一个开源生态,因此工具非常多。工具在给用户使用之前,需要先打成dpkg或者rpm包。 有的时候一个包会依赖很多其他的包,而dpkg和rpm不会对这种情况进行管理,有时为了装一个包需要先装十几个依赖的包,过程非常艰辛!因此现在多数情况用yum和apt。
yum
yum的全名Yellodog Updator,Modified。基于Yellodog Updator软件修改的。yum是 Python 开发的,提供的是rpm包,因此只有redhat系的 Linux,比如 Fedora,Centos 支持yum。yum的主要能力就是帮你解决下载和依赖两个问题。
如用户想安装vim,只需要输入sudo yum insall vim就可以安装了。另一方面,yum帮助用户解决了很多依赖,比如用户安装一个软件依赖了 10 个其他的软件,yum会把这 11 个软件一次性的装好。关于yum的具体用法,你可以使用man工具进行学习。
apt
与yum 的用法是差不多的, man 一下。apt全名是 Advanced Packaging Tools,由于advanced(先进)是相对于dpkg而言的,它也能够提供和yum类似的下载和依赖管理能力。比如在没有vim的机器上,我们可以用sudo apt insall vim指令安装vim。
dpkg指令查看 vim 的状态是ii。第一个i代表期望状态是已安装,第二个i代表实际状态是已安装。
编译安装 Nginx
第一步:下载源码。ubuntu使用wget下载nginx源码包
第二步:解压。
第三步:配置和解决依赖。解压完,我们进入nginx的目录,执行 configure 打包工具进行配置,./configure --help看到所有的配置项,包管理器,安装gcc,安装完成之后,再执行./configure
第四步:编译和安装。通常配置完之后,我们输入make && sudo make install进行编译和安装。make是linux下面一个强大的构建工具。autoconf也就是./configure会在当前目录下生成一个 MakeFile 文件。make会根据MakeFile文件编译整个项目。编译完成后,能够形成和当前操作系统以及 CPU 指令集兼容的二进制可执行文件。然后再用make install安装。&&符号代表执行完make再去执行make installl。
可以看到编译是个非常慢的活。等待了差不多 1 分钟,终于结束了。nginx被安装到了/usr/local/nginx中,如果需要让nginx全局执行,可以设置一个软连接到/usr/local/bin,具体如下:
ln -sf /usr/local/nginx/sbin/nginx /usr/local/sbin/nginx总结
这节课我们学习了在 Linux 上安装软件,简要介绍了dpkg和rpm,然后介绍了能够解决依赖和帮助用户下载的yum和apt。重点带你使用了apt,在这个过程中看到了强大的包管理机制,今天的maven、npm、pip都继承了这样一个特性。最后我们还尝试了一件高难度的事情,就是编译安装nginx。
那么通过这节课的学习,你现在可以来回答本节关联的面试题目:编译安装和包管理安装有什么优势和劣势了吗?
老规矩,请你先在脑海里构思下给面试官的表述,并把你的思考写在留言区,然后再来看我接下来的分析。
【解析】 包管理安装很方便,但是有两点劣势。
第一点是需要提前将包编译好,因此有一个发布的过程,如果某个包没有发布版本,或者在某个平台上找不到对应的发布版本,就需要编译安装。
第二点就是如果一个软件的定制程度很高,可能会在编译阶段传入参数,比如利用configure传入配置参数,这种时候就需要编译安装。
11 | 高级技巧之日志分析:利用 Linux 指令分析 Web 日志
利用 Linux 指令分析 Web 日志,这其中包含很多小技巧,掌握了本课时的内容,将对你将来分析线上日志、了解用户行为和查找问题有非常大地帮助。本课时将用到一个大概有 5W 多条记录的nginx日志文件,你可以在 GitHub上下载。 下面就请你和我一起,通过分析这个nginx日志文件。
第一步:能不能这样做?
当我们想要分析一个线上文件的时候,首先要思考,能不能这样做? 这里你可以先用htop指令看一下当前的负载。如果你的机器上没有htop,可以考虑用yum或者apt去安装。
如上图所示,我的机器上 8 个 CPU 都是 0 负载,2G的内存用了一半多,还有富余。 我们用wget将目标文件下载到本地(如果你没有 wget,可以用yum或者apt安装)。
复制代码
wget 某网址(自己替代)
然后我们用ls查看文件大小。发现这只是一个 7M 的文件,因此对线上的影响可以忽略不计。如果文件太大,建议你用scp指令将文件拷贝到闲置服务器再分析。下图中我使用了--block-size让ls以M为单位显示文件大小。
确定了当前机器的CPU和内存允许我进行分析后,我们就可以开始第二步操作了。
第二步:LESS 日志文件
在分析日志前,给你提个醒,记得要less一下,看看日志里面的内容。之前我们说过,尽量使用less这种不需要读取全部文件的指令,因为在线上执行cat是一件非常危险的事情,这可能导致线上服务器资源不足。
如上图所示,我们看到nginx的access_log每一行都是一次用户的访问,从左到右依次是:
IP 地址;
时间;
HTTP 请求的方法、路径和协议版本、返回的状态码;
User Agent。
第三步:PV 分析
PV(Page View),用户每访问一个页面就是一次Page View。对于nginx的acess_log来说,分析 PV 非常简单,我们直接使用wc -l就可以看到整体的PV。
如上图所示:我们看到了一共有 51462 条 PV。
第四步:PV 分组
通常一个日志中可能有几天的 PV,为了得到更加直观的数据,有时候需要按天进行分组。为了简化这个问题,我们先来看看日志中都有哪些天的日志。
使用awk '{print $4}' access.log | less可以看到如下结果。awk是一个处理文本的领域专有语言。这里就牵扯到领域专有语言这个概念,英文是Domain Specific Language。领域专有语言,就是为了处理某个领域专门设计的语言。比如awk是用来分析处理文本的DSL,html是专门用来描述网页的DSL,SQL是专门用来查询数据的DSL……大家还可以根据自己的业务设计某种针对业务的DSL。
你可以看到我们用$4代表文本的第 4 列,也就是时间所在的这一列,如下图所示:
我们想要按天统计,可以利用 awk提供的字符串截取的能力。
上图中,我们使用awk的substr函数,数字2代表从第 2 个字符开始,数字11代表截取 11 个字符。
接下来我们就可以分组统计每天的日志条数了。
上图中,使用sort进行排序,然后使用uniq -c进行统计。你可以看到从 2015 年 5 月 17 号一直到 6 月 4 号的日志,还可以看到每天的 PV 量大概是在 2000~3000 之间。
第五步:分析 UV
接下来我们分析 UV。UV(Uniq Visitor),也就是统计访问人数。通常确定用户的身份是一个复杂的事情,但是我们可以用 IP 访问来近似统计 UV。
上图中,我们使用 awk 去打印$1也就是第一列,接着sort排序,然后用uniq去重,最后用wc -l查看条数。 这样我们就知道日志文件中一共有2660个 IP,也就是2660个 UV。
第六步:分组分析 UV
接下来我们尝试按天分组分析每天的 UV 情况。这个情况比较复杂,需要较多的指令,我们先创建一个叫作sum.sh的bash脚本文件,写入如下内容:
复制代码
#!/usr/bin/bash
awk '{print substr($4, 2, 11) " " $1}' access.log |\
sort | uniq |\
awk '{uv[$1]++;next}END{for (ip in uv) print ip, uv[ip]}'
具体分析如下。
文件首部我们使用#!,表示我们将使用后面的/usr/bin/bash执行这个文件。
第一次awk我们将第 4 列的日期和第 1 列的ip地址拼接在一起。
下面的sort是把整个文件进行一次字典序排序,相当于先根据日期排序,再根据 IP 排序。
接下来我们用uniq去重,日期 +IP 相同的行就只保留一个。
最后的awk我们再根据第 1 列的时间和第 2 列的 IP 进行统计。
为了理解最后这一行描述,我们先来简单了解下awk的原理。
awk本身是逐行进行处理的。因此我们的next关键字是提醒awk跳转到下一行输入。 对每一行输入,awk会根据第 1 列的字符串(也就是日期)进行累加。之后的END关键字代表一个触发器,就是 END 后面用 {} 括起来的语句会在所有输入都处理完之后执行——当所有输入都执行完,结果被累加到uv中后,通过foreach遍历uv中所有的key,去打印ip和ip对应的数量。
编写完上面的脚本之后,我们保存退出编辑器。接着执行chmod +x ./sum.sh,给sum.sh增加执行权限。然后我们可以像下图这样执行,获得结果:
如上图,IP地址已经按天进行统计好了。
总结
今天我们结合一个简单的实战场景——Web 日志分析与统计练习了之前学过的指令,提高熟练程度。此外,我们还一起学习了新知识——功能强大的awk文本处理语言。在实战中,我们对一个nginx的access_log进行了简单的数据分析,直观地获得了这个网站的访问情况。
我们在日常的工作中会遇到各种各样的日志,除了 nginx 的日志,还有应用日志、前端日志、监控日志等等。你都可以利用今天学习的方法,去做数据分析,然后从中得出结论。
思考题
接下来我给你出 2 个场景思考题,帮助你继续练习使用 Linux 指令。
根据今天的 access_log 分析出有哪些终端访问了这个网站,并给出分组统计结果。
根据今天的 access_log 分析出访问量 Top 前三的网页。
12 | 高级技巧之集群部署:利用 Linux 指令同时在多台机器部署程序
用 Linux 指令管理一个集群。通过把简单的指令组合起来,分层组织成最终的多个脚本文件,解决一个复杂的工程问题:在成百上千的集群中安装一个 Java 环境。
第一步:搭建学习用的集群
第一步我们先搭建一个学习用的集群。这里简化一下模型。我在自己的电脑上装一个ubuntu桌面版的虚拟机,然后再装两个ubuntu服务器版的虚拟机。
相对于桌面版,服务器版对资源的消耗会少很多。我将教学材料中桌面版的ubuntu命名为u1,两个用来被管理的服务器版ubuntu叫作v1和v2。
用桌面版的原因是:我喜欢ubuntu漂亮的开源字体,这样会让我在给你准备素材的时候拥有一个好心情。如果你对此感兴趣,可以搜索ubuntu mono,尝试把这个字体安装到自己的文本编辑器中。不过我还是觉得在ubuntu中敲代码更有感觉。
注意,我在这里只用了 3 台服务器,但是接下来我们要写的脚本是可以在很多台服务器之间复用的。
第二步:循环遍历 IP 列表
你可以想象一个局域网中有很多服务器需要管理,它们彼此之间网络互通,我们通过一台主服务器对它们进行操作,即通过u1操作v1和v2。
在主服务器上我们维护一个ip地址的列表,保存成一个文件,如下图所示:
目前iplist中只有两项,但是如果我们有足够的机器,可以在里面放成百上千项。接下来,请你思考shell如何遍历这些ip?
你可以先尝试实现一个最简单的程序,从文件iplist中读出这些ip并尝试用for循环遍历这些ip,具体程序如下:
#!/usr/bin/bash
readarray -t ips < iplist
for ip in ${ips[@]}
do
echo $ip
done首行的#!叫作 Shebang。Linux 的程序加载器会分析 Shebang 的内容,决定执行脚本的程序。这里我们希望用bash来执行这段程序,因为我们用到的 readarray 指令是bash 4.0后才增加的能力。
readarray指令将 iplist 文件中的每一行读取到变量ips中。ips是一个数组,可以用echo ${ips[@]}打印其中全部的内容:@代表取数组中的全部内容;$符号是一个求值符号。不带$的话,ips[@]会被认为是一个字符串,而不是表达式。
for循环遍历数组中的每个ip地址,echo把地址打印到屏幕上。
如果用shell执行上面的程序会报错,因为readarray是bash 4.0后支持的能力,因此我们用chomd为foreach.sh增加执行权限,然后直接利用shebang的能力用bash执行,如下图所示:
第三步:创建集群管理账户
为了方便集群管理,通常使用统一的用户名管理集群。这个账号在所有的集群中都需要保持命名一致。比如这个集群账号的名字就叫作lagou。接下来我们探索一下如何创建这个账户lagou,如下图所示:
上面我们创建了lagou账号,然后把lagou加入sudo分组。这样lagou就有了sudo成为root的能力,如下图所示:
接下来,我们设置lagou用户的初始化shell是bash,如下图所示:
这个时候如果使用命令su lagou,可以切换到lagou账号,但是你会发现命令行没有了颜色。因此我们可以将原来用户下面的.bashrc文件拷贝到/home/lagou目录下,如下图所示:
这样,我们就把一些自己平时用的设置拷贝了过去,包括终端颜色的设置。.bashrc是启动bash的时候会默认执行的一个脚本文件。
接下来,我们编辑一下/etc/sudoers文件,增加一行lagou ALL=(ALL) NOPASSWD:ALL表示lagou账号 sudo 时可以免去密码输入环节,如下图所示:
我们可以把上面的完整过程整理成指令文件,create_lagou.sh:
复制代码
sudo useradd -m -d /home/lagou lagou
sudo passwd lagou
sudo usermod -G sudo lagou
sudo usermod --shell /bin/bash lagou
sudo cp ~/.bashrc /home/lagou/
sudo chown lagou.lagou /home/lagou/.bashrc
sduo sh -c 'echo "lagou ALL=(ALL) NOPASSWD:ALL">>/etc/sudoers'
你可以删除用户lagou,并清理/etc/sudoers文件最后一行。用指令userdel lagou删除账户,然后执行create_lagou.sh重新创建回lagou账户。如果发现结果一致,就代表create_lagou.sh功能没有问题。
最后我们想在v1``v2上都执行create_logou.sh这个脚本。但是你不要忘记,我们的目标是让程序在成百上千台机器上传播,因此还需要一个脚本将create_lagou.sh拷贝到需要执行的机器上去。
这里,可以对foreach.sh稍做修改,然后分发create_lagou.sh文件。
foreach.sh
复制代码
#!/usr/bin/bash
readarray -t ips < iplist
for ip in ${ips[@]}
do
scp ~/remote/create_lagou.sh ramroll@$ip:~/create_lagou.sh
done
这里,我们在循环中用scp进行文件拷贝,然后分别去每台机器上执行create_lagou.sh。
如果你的机器非常多,上述过程会变得非常烦琐。你可以先带着这个问题学习下面的Step 4,然后再返回来重新思考这个问题,当然你也可以远程执行脚本。另外,还有一个叫作sshpass的工具,可以帮你把密码传递给要远程执行的指令,如果你对这块内容感兴趣,可以自己研究下这个工具。
第四步: 打通集群权限
接下来我们需要打通从主服务器到v1和v2的权限。当然也可以每次都用ssh输入用户名密码的方式登录,但这并不是长久之计。 如果我们有成百上千台服务器,输入用户名密码就成为一件繁重的工作。
这时候,你可以考虑利用主服务器的公钥在各个服务器间登录,避免输入密码。接下来我们聊聊具体的操作步骤:
首先,需要在u1上用ssh-keygen生成一个公私钥对,然后把公钥写入需要管理的每一台机器的authorized_keys文件中。如下图所示:我们使用ssh-keygen在主服务器u1中生成公私钥对。
然后使用mkdir -p创建~/.ssh目录,-p的优势是当目录不存在时,才需要创建,且不会报错。~代表当前家目录。 如果文件和目录名前面带有一个.,就代表该文件或目录是一个需要隐藏的文件。平时用ls的时候,并不会查看到该文件,通常这种文件拥有特别的含义,比如~/.ssh目录下是对ssh的配置。
我们用cd切换到.ssh目录,然后执行ssh-keygen。这样会在~/.ssh目录中生成两个文件,id_rsa.pub公钥文件和is_rsa私钥文件。 如下图所示:
可以看到id_rsa.pub文件中是加密的字符串,我们可以把这些字符串拷贝到其他机器对应用户的~/.ssh/authorized_keys文件中,当ssh登录其他机器的时候,就不用重新输入密码了。 这个传播公钥的能力,可以用一个shell脚本执行,这里我用transfer_key.sh实现。
我们修改一下foreach.sh,并写一个transfer_key.sh配合foreach.sh的工作。transfer_key.sh内容如下:
foreach.sh
复制代码
#!/usr/bin/bash
readarray -t ips < iplist
for ip in ${ips[@]}
do
sh ./transfer_key.sh $ip
done
tranfer_key.sh
复制代码
ip=$1
pubkey=$(cat ~/.ssh/id_rsa.pub)
echo "execute on .. $ip"
ssh lagou@$ip "
mkdir -p ~/.ssh
echo $pubkey >> ~/.ssh/authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
"
在foreach.sh中我们执行 transfer_key.sh,并且将 IP 地址通过参数传递过去。在 transfer_key.sh 中,用$1读出 IP 地址参数, 再将公钥写入变量pubkey,然后登录到对应的服务器,执行多行指令。用mkdir指令检查.ssh目录,如不存在就创建这个目录。最后我们将公钥追加写入目标机器的~/.ssh/authorized_keys中。
chmod 700和chmod 600是因为某些特定的linux版本需要.ssh的目录为可读写执行,authorized_keys文件的权限为只可读写。而为了保证安全性,组用户、所有用户都不可以访问这个文件。
此前,我们执行foreach.sh需要输入两次密码。完成上述操作后,我们再登录这两台服务器就不需要输入密码了。
接下来,我们尝试一下免密登录,如下图所示:
可以发现,我们登录任何一台机器,都不再需要输入用户名和密码了。
第五步:单机安装 Java 环境
在远程部署 Java 环境之前,我们先单机完成以下 Java 环境的安装,用来收集需要执行的脚本。
在ubuntu上安装java环境可以直接用apt。
我们通过下面几个步骤脚本配置 Java 环境:
复制代码
sudo apt install openjdk-11-jdk
经过一番等待我们已经安装好了java,然后执行下面的脚本确认java安装。
复制代码
which java
java --version
根据最小权限原则,执行 Java 程序我们考虑再创建一个用户ujava。
复制代码
sudo useradd -m -d /opt/ujava ujava
sudo usermod --shell /bin/bash lagou
这个用户可以不设置密码,因为我们不会真的登录到这个用户下去做任何事情。接下来我们为用户配置 Java 环境变量,如下图所示:
通过两次 ls 追查,可以发现java可执行文件软连接到/etc/alternatives/java然后再次软连接到/usr/lib/jvm/java-11-openjdk-amd64下。
这样我们就可以通过下面的语句设置 JAVA_HOME 环境变量了。
复制代码
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
Linux 的环境变量就好比全局可见的数据,这里我们使用 export 设置JAVA_HOME环境变量的指向。如果你想看所有的环境变量的指向,可以使用env指令。
其中有一个环境变量比较重要,就是PATH。
如上图,我们可以使用shell查看PATH的值,PATH中用:分割,每一个目录都是linux查找执行文件的目录。当用户在命令行输入一个命令,Linux 就会在PATH中寻找对应的执行文件。
当然我们不希望JAVA_HOME配置后重启一次电脑就消失,因此可以把这个环境变量加入ujava用户的profile中。这样只要发生用户登录,就有这个环境变量。
复制代码
sudo sh -c 'echo "export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/" >> /opt/ujava/.bash_profile'
将JAVA_HOME加入bash_profile,这样后续远程执行java指令时就可以使用JAVA_HOME环境变量了。
最后,我们将上面所有的指令整理起来,形成一个install_java.sh。
复制代码
sudo apt -y install openjdk-11-jdk
sudo useradd -m -d /opt/ujava ujava
sudo usermod --shell /bin/bash ujava
sudo sh -c 'echo "export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/" >> /opt/ujava/.bash_profile'
apt后面增了一个-y是为了让执行过程不弹出确认提示。
第六步:远程安装 Java 环境
终于到了远程安装 Java 环境这一步,我们又需要用到foreach.sh。为了避免每次修改,你可以考虑允许foreach.sh带一个文件参数,指定需要远程执行的脚本。
foreach.sh
复制代码
#!/usr/bin/bash
readarray -t ips < iplist
script=$1
for ip in ${ips[@]}
do
ssh $ip 'bash -s' < $script
done
改写后的foreach会读取第一个执行参数作为远程执行的脚本文件。 而bash -s会提示使用标准输入流作为命令的输入;< $script负责将脚本文件内容重定向到远程bash的标准输入流。
然后我们执行foreach.sh install_java.sh,机器等待 1 分钟左右,在执行结束后,可以用下面这个脚本检测两个机器中的安装情况。
check.sh
复制代码
sudo -u ujava -i /bin/bash -c 'echo $JAVA_HOME'
sudo -u ujava -i java --version
check.sh中我们切换到ujava用户去检查JAVA_HOME环境变量和 Java 版本。执行的结果如下图所示:
总结
这节课我们所讲的场景是自动化运维的一些皮毛。通过这样的场景练习,我们复习了很多之前学过的 Linux 指令。在尝试用脚本文件构建一个又一个小工具的过程中,可以发现复用很重要。
在工作中,优秀的工程师,总是善于积累和复用,而shell脚本就是积累和复用的利器。如果你第一次安装java环境,可以把今天的安装脚本保存在自己的笔记本中,下次再安装就能自动化完成了。除了积累和总结,另一个非常重要的就是你要尝试自己去查资料,包括使用man工具熟悉各种指令的使用方法,用搜索引擎查阅资料等。
课后练习题
最后我再给你出一道需要查阅资料的题目:~/.bashrc ~/.bash_profile, ~/.profile 和 /etc/profile 的区别是什么?
06 | 目录结构和文件管理指令:rm / -rf 指令的作用是?
【问题】 搜索文件系统中所有以包含 std字符串且以.h扩展名结尾的文件。
【解析】 我自己只写了一种方法,没想到留言中有挺多不错的方案,那我们一起来看下。
下面是我的方案,你学完模块二的内容后,应该知道查看全部文件需要sudo,以管理员身份:
sudo find / -name "*std*.h"
# 也可以结合 grep 语句, 用管道实现
sudo find / -name "*.h" |grep std我在留言中看到有的同学用的是-iname,这样也是可以的,只是忽略了大小写。
sudo find / -name "*.h" |grep std
07 | 进程、重定向和管道指令:xargs 指令的作用是?
【问题】 请问下面这段 Shell 程序的作用是什么?
复制代码
mkfifo pipe1
mkfifo pipe2
echo -n run | cat - pipe1 > pipe2 &
cat < pipe2 > pipe1【解析】 这个题目是我在网上看到的一个比较有趣的问题。前 2 行代码创建了两个管道文件。
从第 3 行开始,代码变得复杂。echo -n run就是向输出流中写入一个run字符串(不带回车,所以用-n)。通过管道,将这个结果传递给了cat。cat是 concatenate 的缩写,意思是把文件粘在一起。
-
当
cat用>重定向输出到一个管道文件时,如果没有其他进程从管道文件中读取内容,cat会阻塞。 -
当
cat用<读取一个管道内容时,如果管道中没有输入,也会阻塞。
从这个角度来看,总共有 3 次重定向:
-
将
-也就是输入流的内容和pipe1内容合并重定向到pipe2; -
将
pipe2内容重定向到cat; -
将
cat的内容重定向到pipe1。
仔细观察下路径:pipe1->pipe2->pipe1,构成了一个循环。 这样导致管道pipe1管道pipe2中总是有数据(没有数据的时间太短)。于是,就构成了一个无限循环。我们打开执行这个程序后,可以用htop查看当前的 CPU 使用情况,会发现 CPU 占用率很高。
08 | 用户和权限管理指令: 请简述 Linux 权限划分的原则?
【问题】 如果一个目录是只读权限,那么这个目录下面的文件还可写吗?
【解析】 这类问题,你一定要去尝试,观察现象再得到结果。你可以看到上图中,foo 目录不可读了,下面的foo/bar文件还可以写。 即便它不可写了,下面的foo/bar文件还是可以写。但是想要创建新文件就会出现报错,因为创建新文件也需要改目录文件。这个例子说明 Linux 中的文件内容并没有存在目录中,目录中却有文件清单。
09 | Linux 中的网络指令:如何查看一个域名有哪些 NS 记录?
【问题】 如何查看正在 TIME_WAIT 状态的连接数量?
【解析】 注意,这里有个小坑,就是 netstat 会有两行表头,这两行可以用 tail 过滤掉,下面tail -n +3就是告诉你 tail 从第 3 行开始显示。-a代表显示所有的 socket。
10 | 软件的安装: 编译安装和包管理器安装有什么优势和劣势?
【问题】 如果你在编译安装 MySQL 时,发现找不到libcrypt.so ,应该如何处理?
【解析】 遇到这类问题,首先应该去查资料。 比如查 StackOverflow,搜索关键词:libcrypt.so not found,或者带上自己的操作系统ubuntu。下图是关于 Stackoverflow 的一个解答:
11 | 高级技巧之日志分析:利用 Linux 指令分析 Web 日志
【问题 1 】 根据今天的 access_log 分析出有哪些终端访问了这个网站,并给出分组统计结果。
【解析】access_log中有Debian和Ubuntu等等。我们可以利用下面的指令看到,第 12 列是终端,如下图所示:我们还可以使用sort和uniq查看有哪些终端,如下图所示:最后需要写一个脚本,进行统计:
【问题 2】 根据今天的 access_log 分析出访问量 Top 前三的网页。
如果不需要 Substring 等复杂的处理,也可以使用sort和uniq的组合。如下图所示:12 | 高级技巧之集群部署:利用 Linux 指令同时在多台机器部署程序
【问题】~/.bashrc ~/.bash_profile, ~/.profile 和 /etc/profile 的区别是什么?
【解析】 执行一个 shell 的时候分成login shell和non-login shell。顾名思义我们使用了sudo``su切换到某个用户身份执行 shell,也就是login shell。还有 ssh 远程执行指令也是 login shell,也就是伴随登录的意思——login shell 会触发很多文件执行,路径如下:
如果以当前用户身份正常执行一个 shell,比如说./a.sh,就是一个non-login的模式。 这时候不会触发上述的完整逻辑。
另外shell还有另一种分法,就是interactive和non-interactive。interactive 是交互式的意思,当用户打开一个终端命令行工具后,会进入一个输入命令得到结果的交互界面,这个时候,就是interactive shell。
baserc文件通常只在interactive模式下才会执行,这是因为~/.bashrc文件中通常有这样的语句,如下图所示:
这个语句通过$-看到当前shell的执行环境,如下图所示:
带 i 字符的就是interactive,没有带i字符就不是。
因此, 如果你需要通过 ssh 远程 shell 执行一个文件,你就不是在 interactive 模式下,bashrc 不会触发。但是因为登录的原因,login shell 都会触发,也就是说 profile 文件依然会执行。
总结
这个模块我们学习了 Linux 指令。我带大家入了个门,也和你一起感受了一次 Linux 指令的博大精深。Linux 虽然没有上下五千年的历史,但每次使用,依然让我感受到了它浓郁的历史气息,悠久的文化传承,自由的创造精神。希望这块知识可以陪伴大家,鼓励你成为优秀的程序员。虽然我们已经学了几十个指令,但还是沧海一粟。后续就需要你多查资料,多用man手册,继续深造了。
好的,Linux 指令部分就告一段落。下一节课,我们将开启操作系统核心知识学习,请和我一起来学习“模块三:操作系统基础知识”吧。
12 | 高级技巧之集群部署:利用 Linux 指令同时在多台机器部署程序
加餐 | 练习题详解(二)
模块三:操作系统基础知识
13 | 操作系统内核:Linux 内核和 Windows 内核有什么区别?
14 | 用户态和内核态:用户态线程和内核态线程有什么区别?
15 | 中断和中断向量:Java/js 等语言为什么可以捕获到键盘输入?
16 | Win/Mac/Unix/Linux 的区别和联系:为什么 Debian 漏洞排名第一还这么多人用?
加餐 | 练习题详解(三)
模块四: 进程和线程
17 | 进程和线程:进程的开销比线程大在了哪里?
18 | 锁、信号量和分布式锁:如何控制同一时间只有 2 个线程运行?
19 | 乐观锁、区块链:除了上锁还有哪些并发控制方法?
20 | 进程的调度:进程调度都有哪些方法?
21 | 哲学家就餐问题:什么情况下会触发饥饿和死锁?
22 | 进程间通信: 进程间通信都有哪些方法?
23 | 分析服务的特性:我的服务应该开多少个进程、多少个线程?
加餐 | 练习题详解(四)
模块五:内存管理
24 | 虚拟内存 :一个程序最多能使用多少内存?
25 | 内存管理单元: 什么情况下使用大内存分页?
26 | 缓存置换算法: LRU 用什么数据结构实现更合理?
27 | 内存回收上篇:如何解决内存的循环引用问题?
28 | 内存回收下篇:三色标记-清除算法是怎么回事?
加餐 | 练习题详解(五)
模块六:文件系统
29 | Linux 下的各个目录有什么作用?
30 | 文件系统的底层实现:FAT、NTFS 和 Ext3 有什么区别?
待更新
31 | 数据库文件系统实例:MySQL 中 B 树和 B+ 树有什么区别?
待更新
32 | HDFS 介绍:分布式文件系统是怎么回事?
待更新
加餐 | 练习题详解(六)
待更新
模块七: 网络与安全
33 | 互联网协议群(TCP/IP):多路复用是怎么回事?
待更新
34 | UDP 协议:UDP 和 TCP 相比快在哪里?
待更新
35 | Linux 的 I/O 模式:select/poll/epoll 有什么区别?
待更新
36 | 公私钥体系和网络安全:什么是中间人攻击?
待更新
加餐 | 练习题详解(七)
待更新
模块八:虚拟化和其他
37 | 虚拟化技术介绍:VMware 和 Docker 的区别?
待更新
38 | 容器编排技术:如何利用 K8s 和 Docker Swarm 管理微服务?
待更新
39 | Linux 架构优秀在哪里?
待更新
40 | 商业操作系统:电商操作系统是不是一个噱头?
待更新
加餐 | 练习题详解(八)