浅谈Java线程池(Executors四种方法、ThreadPoolExecutor七种参数、四种工作队列、四种拒绝策略、最大线程数的两种定义策略)
内容概述
一、Executors四种方法
二、ThreadPoolExecutor 七种构造参数、四种工作队列、四种拒绝策略
三、最大线程数的两种定义策略
线程池的优点
- 1、降低资源消耗
- 2、提高程序运行效率
- 3、方便对线程进行管理(可以控制最大的并发数,且线程可复用)
阿里的代码规范:
【强制】线程池不允许使用Executors 去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规 则,规避资源耗尽的风险。
说明: Executors返回的线程池对象的弊端如下:
1)FixedThreadPool和 SingleThreadPool:
允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。也可能导致栈溢出。
2) CachedThreadPool和 ScheduledThreadPool:
允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。也可能导致栈溢出。
Integer.MAX_VALUE
java int 类型整数的最大值是(2 的 31 次方) - 1 = 2147483648 - 1 = 2147483647(21亿多) (java中 int类型 4Byte(字节) = 32bit(位))
一、Executors工具类的四个方法
- 1、Executors.newSingleThreadExecutor()
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Demo_01 {
public static void main(String[] args) {
// 包含单个线程的线程池
ExecutorService threadPool1 = Executors.newSingleThreadExecutor();
try {
for (int i = 1; i <= 100; i++) {
// 使用线程池来创建线程
int finalI = i;
threadPool1.execute(()->{
System.out.println("循环次数"+ finalI +" 当前线程名称--->>>:"+Thread.currentThread().getName());
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 程序结束 关闭线程池
threadPool1.shutdown();
}
}
}
程序运行结果:

SingleThreadExecutor得到的是一个单个的线程,这个线程会保证你的任务执行完成,如果当前线程意外终止,会创建一个新线程继续执行任务。
- 2、ExecutorService threadPool2 = Executors.newFixedThreadPool(int nThreads);
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Demo_01 {
public static void main(String[] args) {
// 固定线程数量的线程池
ExecutorService threadPool2 = Executors.newFixedThreadPool(2);
try {
for (int i = 1; i <= 100; i++) {
// 使用线程池来执行任务
int finalI = i;
threadPool2.execute(()->{
System.out.println("循环次数"+ finalI +" 当前线程名称--->>>:"+Thread.currentThread().getName());
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 程序结束 关闭线程池
threadPool2.shutdown();
}
}
}
程序运行结果:

在FixedThreadPool中,有一个固定大小的池,如果当前需要执行的任务超过了池大小,那么多余的任务等待状态,直到有空闲下来的线程执行任务,而当执行的任务小于池大小,空闲的线程也不会去销毁。
- 3、Executors.newCachedThreadPool();
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Demo_01 {
public static void main(String[] args) {
// 线程数量可伸缩的线程池 (任务多就创建多一点线程,任务少就创建少一点线程)
ExecutorService threadPool3 = Executors.newCachedThreadPool();
try {
for (int i = 1; i <= 100; i++) {
// 使用线程池来执行任务
int finalI = i;
threadPool3.execute(()->{
System.out.println("循环次数"+ finalI +" 当前线程名称--->>>:"+Thread.currentThread().getName());
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 程序结束 关闭线程池
threadPool3.shutdown();
}
}
}
程序运行结果:

若把循环次数改为1000 (则会创建更多的线程去执行任务)
程序运行结果:

CachedThreadPool会创建一个缓存区,将初始化的线程缓存起来,如果线程有可用的,就使用之前创建好的线程,如果没有可用的,就新创建线程,终止并且从缓存中移除已有60秒未被使用的线程。
- 4、Executors.newScheduledThreadPool(int corePoolSize);
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class Demo_01 {
public static void main(String[] args) {
// 可安排在给定延迟时间后运行执行或者定期地执行的线程池
ExecutorService threadPool4 = Executors.newScheduledThreadPool(5);
try {
// 5秒后执行任务
((ScheduledExecutorService) threadPool4).schedule(() -> System.out.println("5秒后执行+++"), 5, TimeUnit.SECONDS);
// 5秒后执行任务,以后每2秒执行一次
((ScheduledExecutorService) threadPool4).scheduleAtFixedRate(() -> System.out.println("每隔两秒执行+++"), 5, 2, TimeUnit.SECONDS);
} catch (Exception e) {
e.printStackTrace();
} finally {
}
}
}

ScheduledThreadPool是一个固定大小的线程池,与FixedThreadPool类似,执行的任务是定时执行。
总结:
上面的四种线程池都是Executors工具类提供的。并且均是阿里的代码规范禁止使用的。我们可以去看下Executors是如何来创建这些线程池的。
二、线程池的七个参数
以Executors 工具类 的 newSingleThreadExecutor() 方法为例 看下创建线程池的 七个重要参数



-
参数1
int corePoolSize // 线程池核心线程数量
线程池中会维护一个最小的线程数量,即使这些线程处于空闲状态,也不会被销毁,除非设置了allowCoreThreadTimeOut=true。这里的最小线程数量即是corePoolSize。 -
参数2
int maximumPoolSize // 线程池最大线程数量
一个任务被提交到线程池以后,首先会找有没有空闲存活线程,如果有则直接执行,如果没有则会缓存到工作队列中,如果工作队列满了,才会创建一个新线程,然后从工作队列的头部取出一个任务交由新线程来处理,而将刚提交的任务放入工作队列尾部。线程池不会无限制的去创建新线程,它会有一个最大线程数量的限制,这个数量即由maximunPoolSize的数量减去corePoolSize的数量来确定,最多能达到maximunPoolSize即最大线程池线程数量。

-
参数3
long keepAliveTime // 空闲线程存活时间
一个线程如果处于空闲状态,并且当前的线程数量大于corePoolSize,那么在指定时间后,这个空闲线程会被销毁,这里的指定时间由keepAliveTime来设定 -
参数4
TimeUnit unit // 空闲线程存活时间单位
keepAliveTime参数的时间计量单位 -
参数5
BlockingQueue < Runnable > workQueue // 工作队列
新任务被提交后,会先进入到此工作队列中,任务调度时再从队列中取出任务。jdk中提供了四种工作队列:
①ArrayBlockingQueue
基于数组的有界阻塞队列,按FIFO排序。新任务进来后,会放到该队列的队尾,有界的数组可以防止资源耗尽问题。当线程池中线程数量达到corePoolSize后,再有新任务进来,则会将任务放入该队列的队尾,等待被调度。如果队列已经是满的,则创建一个新线程,如果线程数量已经达到maxPoolSize,则会执行拒绝策略。
②LinkedBlockingQuene
基于链表的无界阻塞队列(其实最大容量为Interger.MAX),按照FIFO排序。由于该队列的近似无界性,当线程池中线程数量达到corePoolSize后,再有新任务进来,会一直存入该队列,而不会去创建新线程直到maxPoolSize,因此使用该工作队列时,参数maxPoolSize其实是不起作用的。
③SynchronousQuene
一个不缓存任务的阻塞队列,生产者放入一个任务必须等到消费者取出这个任务。也就是说新任务进来时,不会缓存,而是直接被调度执行该任务,如果没有可用线程,则创建新线程,如果线程数量达到maxPoolSize,则执行拒绝策略。
④PriorityBlockingQueue
具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
- 参数6
ThreadFactory threadFactory // 线程工厂
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon(守护)线程等等
关于守护线程可参考https://blog.csdn.net/weixin_40304387/article/details/80507340
- 参数7
RejectedExecutionHandler handler // 拒绝策略
当工作队列中的任务已到达最大限制,并且线程池中的线程数量也达到最大限制,这时如果有新任务提交进来,该如何处理呢。这里的拒绝策略,就是解决这个问题的,jdk中提供了4中拒绝策略:
①CallerRunsPolicy
该策略下,在调用者线程中直接执行被拒绝任务的run方法,除非线程池已经shutdown,则直接抛弃任务。

②AbortPolicy
该策略下,直接丢弃任务,并抛出RejectedExecutionException异常。

③DiscardPolicy
该策略下,直接丢弃任务,什么都不做。
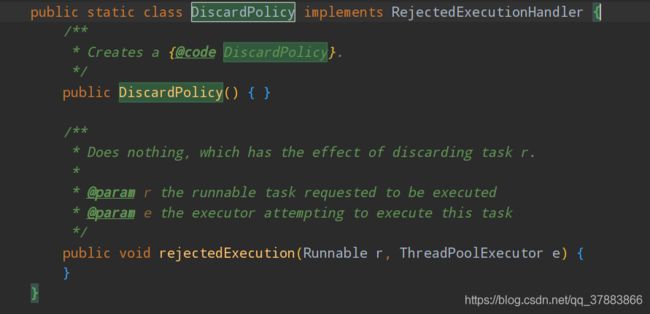
④DiscardOldestPolicy
该策略下,抛弃进入队列最早的那个任务,然后尝试把这次拒绝的任务放入队列

线程池的任务调度:

实践 手动创建一个线程池
给线程池命名
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
默认情况下创建的线程名字类似 pool-1-thread-n 这样的,没有业务含义,不利于我们定位问题。
给线程池里的线程命名通常有下面两种方式:
1.利用 guava 的 ThreadFactoryBuilder
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("MyThreadPool"+ "-%d").build();
ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
2.自己实现 ThreadFactor。
import java.util.concurrent.Executors;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 线程工厂,它设置线程名称,有利于我们定位问题。
*/
public final class NamingThreadFactory implements ThreadFactory {
private final AtomicInteger threadNum = new AtomicInteger();
private final ThreadFactory delegate;
private final String name;
/**
* 创建一个带名字的线程池生产工厂
*/
public NamingThreadFactory(ThreadFactory delegate, String name) {
this.delegate = delegate;
this.name = name;
}
@Override
public Thread newThread(Runnable r) {
Thread t = delegate.newThread(r);
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
return t;
}
}
手动创建一个线程池
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
public class Demo_02 {
// 使用自定义线程工厂
static NamingThreadFactory threadFactory = new NamingThreadFactory(Executors.defaultThreadFactory(),"MyThreadPool" );
public static void main(String[] args) {
ThreadPoolExecutor myThreadPoolExecutor = new ThreadPoolExecutor(3, // 线程池核心线程数量 (3)
5, // 线程池最大线程数量 (5)
6, // 空闲线程存活时间 (6)
TimeUnit.SECONDS, // 空闲线程存活时间单位 (秒)
new LinkedBlockingDeque<>(5), // 工作队列 (基于链表的无界阻塞队列)
threadFactory, // 线程工厂(默认)
new ThreadPoolExecutor.AbortPolicy() // 拒绝策略 (该策略下,直接丢弃任务,并抛出RejectedExecutionException异常)
);
try {
for (int i = 1; i <= 10; i++) {
int finalI = i;
myThreadPoolExecutor.execute(()->{
System.out.println("循环次数"+ finalI + " " +Thread.currentThread().getName());
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
myThreadPoolExecutor.shutdown();
}
System.out.println(Runtime.getRuntime().availableProcessors());
}
/**
* 线程工厂,它设置线程名称,有利于我们定位问题。
*/
public static final class NamingThreadFactory implements ThreadFactory {
private final AtomicInteger threadNum = new AtomicInteger();
private final ThreadFactory delegate;
private final String name;
/**
* 创建一个带名字的线程池生产工厂
*/
public NamingThreadFactory(ThreadFactory delegate, String name) {
this.delegate = delegate;
this.name = name;
}
@Override
public Thread newThread(Runnable r) {
Thread t = delegate.newThread(r);
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
return t;
}
}
}
处理十个任务(等于最大承载量):
程序执行结果:

将for循环修改为 循环11次
处理十一个任务(大于最大承载量):
程序执行结果:

三、核心线程数的两种定义策略(仅供参考 实际情况并非这么简单下面两种方式仅为参考值 具体需要根据业务场景配置)
线程池的七个参数中 corePoolSize // 线程池核心线程数量 该如何指定?
-
1、CPU密集型
设置corePoolSize 等于 运行该程序的物理机CPU核心数量+1 例如服务器CPU为下图配置则 corePoolSize = 28+1 =29
这种方式可以保持CPU的效率最高

在java代码中 Runtime.getRuntime().availableProcessors() 可返回CPU核心数
注意 该方法有时候并不一定能准确的返回真实的CPU核心数
参考https://blog.csdn.net/zhanghongzheng3213/article/details/83376571 -
2、IO密集型
IO密集型:(分两种):
1.由于IO密集型任务的线程并不是一直在执行任务,则应配置尽可能多的线程,如CPU核数*2+1
2.IO密集型,即任务需要大量的IO,即大量的阻塞。在单线程上运行IO密集型的任务会导致浪费大量的CPU运算能力浪费在等待。所以在IO密集型任务中使用多线程可以大大的加速程序运行。故需要·多配置线程数:
参考公式:CPU核数/(1-阻塞系数 ) 阻塞系数在(0.8-0.9)之间
比如8核CPU:8/(1-0.9) = 80个线程数
最后如果感兴趣可以看看美团的骚操作
Java线程池实现原理及其在美团业务中的实践