情感分析(Sentiment Analysis)是自然语言处理里面比较高阶的任务之一。仔细思考一下,这个任务的究极目标其实是想让计算机理解人类的情感世界。我们自己都不一定能完全控制和了解自己的情感,更别说机器了。
不过在人工智能的认知智能阶段(人工智能三阶段——计算智能,感知智能,认知智能),商家还是可以用它来做一些商品或服务的评论分析,继而有效地去优化商品或服务,为消费者们提供更好用户体验。
情感分析任务简介
情感分析任务其实是个分类任务,给模型输入一句话,让它判断这句话的情感是积极的,消极的,还是中性的。例子如下:
输入:的确是专业,用心做,出品方面都给好评。
输出:2
输出可以是[0,1,2]其中一个,0表示情感消极,1表示情感中性,2表示情感积极。
情感分析这个任务还有一个升级版——细腻度的情感分析。升级版希望模型不仅能识别出情感的好坏,而且还希望模型能识别出是由于什么原因导致这种情感发生。举个例子,"这家餐厅的地理位置不错,可惜菜不怎么好吃",我们就需要识别出,在地理位置这个aspect上情感是积极的,而在菜的味道这个aspect上情感是消极的。听起来是不是很难,所以实战部分我只简单介绍一下麻瓜版的情感分析任务——简单的分类。
情感分析算法简介
分类任务的算法,想必大家都很熟悉:SVM,Logistic,Tree等。可是对于文本分类来说,最重要的是如何将一句话的映射到向量空间,同时保持其语义特征。所以文本的向量化表示是最最重要的一个环节。而文本的向量化就是涉及到Word Embedding技术和深度学习(Deep Learning)技术。
Word Embedding指的是把文本转换成计算机能处理的向量,而其中难点的是:将文本向量化时如何保持句子原有的语义。早期word embedding使用的是Bag of Words,TF-IDF等,这些算法有个共同的特点:就是没有考虑语序以及上下文关系。而近几年发展出来的Word2Vector ,Glove等考虑到了文本的上下文关系。今年NLP领域大放异彩的BERT就是在文本向量化上做出了重大的突破。
人工特征的挖掘是个极为费脑费时的过程,深度学习模型可以将特征工程自动化,通过神经网络自动做特征的表示学习。在NLP领域中,RNN(LSTM,GRU),CNN,Transformer等各路深度学习模型各显神通,凭借他们强大的特征表示能力,在很多任务中都吊打人工特征(吹得 有些夸张了,没收住)。不过人工特征有时还是很重要的。
项目实战
本次的项目实战的总体架构可分为两个步骤:
(1)采用Word2Vector技术去训练词向量;
(2)采用BiLSTM去做特征的表示学习。
其项目架构如下图所示:
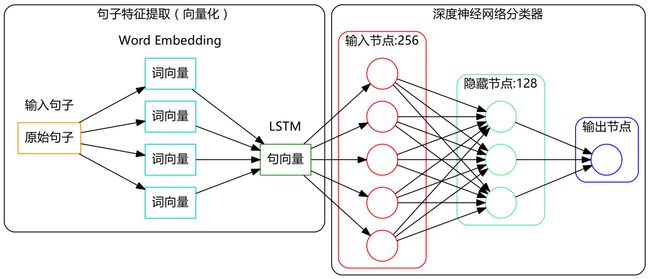
数据读取
数据格式如下:一句评论后面标记一个label,0表示消极情感,1表示中性情感,2表示积极情感。

这里针对笔者自己的数据集定义了一个数据读入函数。
import numpy as np
from gensim.models.word2vec import Word2Vec
from gensim.corpora.dictionary import Dictionary
from gensim import models
import pandas as pd
import jieba
import logging
from keras import Sequential
from keras.preprocessing.sequence import pad_sequences
from keras.layers import Bidirectional,LSTM,Dense,Embedding,Dropout,Activation,Softmax
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
def read_data(data_path):
senlist = []
labellist = []
with open(data_path, "r",encoding='gb2312',errors='ignore') as f:
for data in f.readlines():
data = data.strip()
sen = data.split("\t")[2]
label = data.split("\t")[3]
if sen != "" and (label =="0" or label=="1" or label=="2" ) :
senlist.append(sen)
labellist.append(label)
else:
pass
assert(len(senlist) == len(labellist))
return senlist ,labellist
sentences,labels = read_data("data_train.csv")
数据读入之后,得到一个所有评论的sentences列表 ,和一个与之一一对应的labels列表。
sentences[1] :烤鸭还是不错的,别的菜没什么特殊的
labels[1] :1
训练词向量
将所有的评论文本数据用来训练词向量,这里使用的gensim中的Word2Vec,原理是的Skip-gram。这里对词向量的原理不多介绍,总之,这一步将一个词映射成一个100维的向量,并且考虑到了上下文的语义。这里直接将上一部得到的句子列表传给train_word2vec函数就可以了,同时需要定义一个词向量文件保存路径。模型保存后,以后使用就不需要再次训练,直接加载保存好的模型就可以啦。
def train_word2vec(sentences,save_path):
sentences_seg = []
sen_str = "\n".join(sentences)
res = jieba.lcut(sen_str)
seg_str = " ".join(res)
sen_list = seg_str.split("\n")
for i in sen_list:
sentences_seg.append(i.split())
print("开始训练词向量")
# logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = Word2Vec(sentences_seg,
size=100, # 词向量维度
min_count=5, # 词频阈值
window=5) # 窗口大小
model.save(save_path)
return model
model = train_word2vec(sentences,'word2vec.model')
数据预处理
这里定义了一些数据处理和变换方法。
def generate_id2wec(word2vec_model):
gensim_dict = Dictionary()
gensim_dict.doc2bow(model.wv.vocab.keys(), allow_update=True)
w2id = {v: k + 1 for k, v in gensim_dict.items()} # 词语的索引,从1开始编号
w2vec = {word: model[word] for word in w2id.keys()} # 词语的词向量
n_vocabs = len(w2id) + 1
embedding_weights = np.zeros((n_vocabs, 100))
for w, index in w2id.items(): # 从索引为1的词语开始,用词向量填充矩阵
embedding_weights[index, :] = w2vec[w]
return w2id,embedding_weights
def text_to_array(w2index, senlist): # 文本转为索引数字模式
sentences_array = []
for sen in senlist:
new_sen = [ w2index.get(word,0) for word in sen] # 单词转索引数字
sentences_array.append(new_sen)
return np.array(sentences_array)
def prepare_data(w2id,sentences,labels,max_len=200):
X_train, X_val, y_train, y_val = train_test_split(sentences,labels, test_size=0.2)
X_train = text_to_array(w2id, X_train)
X_val = text_to_array(w2id, X_val)
X_train = pad_sequences(X_train, maxlen=max_len)
X_val = pad_sequences(X_val, maxlen=max_len)
return np.array(X_train), np_utils.to_categorical(y_train) ,np.array(X_val), np_utils.to_categorical(y_val)
获取词向量矩阵和词典
w2id,embedding_weights = generate_id2wec(model)
这一步主要是为了拿到传给后续情感分析模型的词典(w2id)和词向量矩阵embedding_weights,
w2id格式如下:{
...
'一两天': 454,
'一两年': 455,
'一两次': 456,
'一个': 457,
'一个个': 458,
'一个劲': 459,
...
'不一会': 984,
'不上': 985,
'不下': 986,
'不严': 987,
'不为过': 988,
'不久': 989,
}
embedding_weights格式如下:
[[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[-1.1513499 , -0.00520114, 1.65645397, ..., 0.50586915,
-0.03466858, 0.84113288],
[ 0.01824509, -0.23613754, -0.47191045, ..., -0.16491373,
-0.25222906, -0.00384654],
...,
[ 0.10879639, 0.05459598, -0.02946772, ..., -0.17389177,
0.10144144, 0.21539673]]
这个矩阵保存了上面通过Word2Vector方法训练的词向量,每个词通过其在词典(w2id)中的index索引到对应得词向量,此矩阵将作为参数传给后续的情感分析模型。
数据变换
x_train,y_trian, x_val , y_val = prepare_data(w2id,sentences,labels,200)
将数据变换成模型能够处理的格式。
原始数据格式如下:
sen :不错,品种齐全,上菜很快,味道也不错
label :2
执行上面代码后句子数据变成如下格式:
输入:[0,0,0......,31,43,12,4,65,12,233,11,1391,131,4923,1233]
输出:[0,0,1]
构建模型
这里定义了一个Sentiment类,封装了模型的构建,训练和预测方法。
class Sentiment:
def __init__(self,w2id,embedding_weights,Embedding_dim,maxlen,labels_category):
self.Embedding_dim = Embedding_dim
self.embedding_weights = embedding_weights
self.vocab = w2id
self.labels_category = labels_category
self.maxlen = maxlen
self.model = self.build_model()
def build_model(self):
model = Sequential()
#input dim(140,100)
model.add(Embedding(output_dim = self.Embedding_dim,
input_dim=len(self.vocab)+1,
weights=[self.embedding_weights],
input_length=self.maxlen))
model.add(Bidirectional(LSTM(50),merge_mode='concat'))
model.add(Dropout(0.5))
model.add(Dense(self.labels_category))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.summary()
return model
def train(self,X_train, y_train,X_test, y_test,n_epoch=5 ):
self.model.fit(X_train, y_train, batch_size=32, epochs=n_epoch,
validation_data=(X_test, y_test))
self.model.save('sentiment.h5')
def predict(self,model_path,new_sen):
model = self.model
model.load_weights(model_path)
new_sen_list = jieba.lcut(new_sen)
sen2id =[ self.vocab.get(word,0) for word in new_sen_list]
sen_input = pad_sequences([sen2id], maxlen=self.maxlen)
res = model.predict(sen_input)[0]
return np.argmax(res)
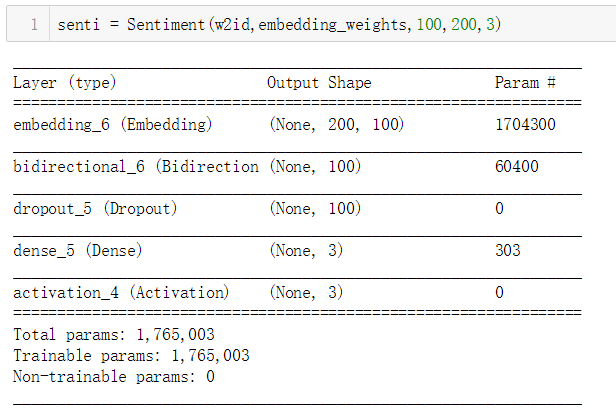
senti = Sentiment(w2id,embedding_weights,100,200,3)
构建模型,同时传人词典和词向量矩阵。
模型训练
senti.train(x_train,y_trian, x_val ,y_val,1)
运行上述代码让模型跑起来,笔者只是做个实验,所以只让模型训练了一个epoch。

模型预测
label_dic = {0:"消极的",1:"中性的",2:"积极的"}
sen_new = "现如今的公司能够做成这样已经很不错了,微订点单网站的信息更新很及时,内容来源很真实"
pre = senti.predict("./sentiment.h5",sen_new)
print("'{}'的情感是:\n{}".format(sen_new,label_dic.get(pre)))
模型训练完之后,接下来就是见证奇迹的时刻了。

笔者输入一句评论让模型去预测,结果如上图所示。只训练了一个epoch,就有这样的功力,不得不承认词向量+深度学习真是强。
结语
至此,我们通过深度学习技术让计算机学会人类世界中一些简单的情感判断。有没有觉得有那么一丝丝可怕,会不会真有一天,你在和一个计算机进行情感交流呢?
(想着想着,笔者先跑了)
参考:
https://github.com/Edward1Chou/SentimentAnalysis