elasticsearch&kibana从6.0升级到7.9完整过程记录
需求来源
公司当前使用的elasticsearch&kibana是6.0.0版本,这已经是快三年前的古老版本了,最新的7.9.X,出于性能上的提升以及漏洞的修复(客户爸爸对于漏洞扫描的结果表示了深切的担忧-_-!),所以近期将elasticsearch&kibana升级提上日程,由于我们公司是elasticsearch&kibana的重度用户,而且绝大多数有价值的数据都存在elasticsearch中,所以就先在一个单机版本的elasticsearch上进行试验填坑,成功后再复制到集群上,这也就是本文的来源
环境介绍
单机版本的elasticsearch&kibana,版本号为6.0.0,中途由于kibana无法正常使用,于是使用了cerebro进行集群状态确认和管理
升级目标
本着一步到位的原则,直接升级到最新的大版本7.9.0,一次升级解决未来两三年的需求
升级过程
elasticsearch升级
由于公司的集群既有公有云的集群部署,更多的是私有化或者私有云部署,所以每个集群的配置都各不相同,很多数据规模较小的客户elasticsearch只有一台server,而且index也没有配置replica,所以滚动升级在很多场景下是不可实现的,再加上我们的业务特点,数据不是特别敏感,所以短时间的停机是可以接受的,所以在此仅讨论停机升级,并尽量复用旧版本的配置,滚动升级的情况资料也相当多了,这里就不赘述了
首先优先说明,因为elasticsearch底层使用Lucene存储数据,而Lucene版本也在不断的升级,所以数据跨版本的兼容也只能尽量保证,数据在大多数情况下无法跨大版本直接升级(血与泪得到的教训与结论),所以本文采用的方式是6.0.0>>6.8.0>>7.9.0的升级方式
首先去官网上下载6.8.0以及7.9.0的elasticsearch安装包,上传到服务器解压缩,然后将现有的配置文件分发到新版本的config目录下待使用,下面就分两部分来介绍整个升级过程:
准备工作:
由于数据库升级存在很多的不确定性,而数据库里的数据一般来说都是一个公司最重要的资产,所以建议先对旧版本的es进行备份,建议生成一个snapshot用于数据恢复,以备不时之需。
snapshot可以通过kibana来生成,也可以通过cerebro来进行创建:
cerebro的图形化生成:
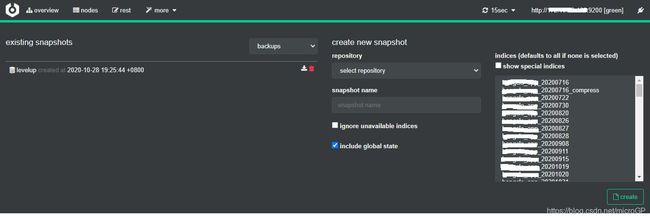
也可以使用kibana的dev tools来使用命令生成:
#创建一个类型为fs,名称为backups的repository(如果没有的话)
PUT _snapshot/backups
{
"type":"fs",
"settings": {
"location": "/bb_home/bb_es/backups"
}
}
#在repository下创建一个名称为levelup的snapshot
PUT _snapshot/backups/levelup?wait_for_completion=true
#查看该snapshot的详情
GET _snapshot/backups/levelup所谓有备无患,一向很懒的笔者这次的勤劳没有白费,开始笔者直接尝试停机直接从6.0.0升级到7.9.0,受到了技术铁锤的无情暴击,直接报了无数的错误,启动直接失败,这时候笔者想吃回头草,用6.0.0去启动,但是由于前面的操作,7.9.0的启动失败已经污染了之前的数据,导致数据无法被识别,这时候笔者心一横,直接将data目录下的数据全部删除,重新启动elasticsearch,然后使用snapshot进行恢复,中途经历了两个错误:第一个是由于data目录清空,所以之前创建的repository失效,这个问题重新创建repository即可解决;第二个问题时由于kibana还在启动,所以elasticsearch启动后,.kibana这个index自动创建了,所以直接恢复的命令失败了,后续使用配置将snapshot中的.kibana重命名后问题解决,elasticsearch恢复到升级之前的状态,恢复命令如下:
#直接使用snapshot进行数据恢复
POST _snapshot/backups/levelup/_restore?wait_for_completion=true
#报错repository missing exception,创建新的repository,与之前一致类型为fs,名称为backups
PUT _snapshot/backups
{
"type":"fs",
"settings": {
"location": "/bb_home/bb_es/backups"
}
}
#直接使用snapshot进行数据恢复
POST _snapshot/backups/levelup/_restore?wait_for_completion=true
#报错cannot restore index [.kibana] because it's open后的恢复,将snapshot中的.kibana重命名
POST _snapshot/backups/levelup/_restore?wait_for_completion=true
{
"indices": "*",
"ignore_unavailable": true,
"include_global_state": true,
"rename_pattern": ".kibana",
"rename_replacement": "restored_.kibana"
}痛定思痛,不能乱走捷径,还是要按部就班的进行,按照两步来升级
小版本升级:6.0.0>>6.8.0:
小版本升级相对容易,配置直接覆盖,停掉6.0.0的进程,启动6.8.0的进程即可,出现如下日志说明小版本升级完成:
![]()
查看cerebro:
机器版本已经升级到6.8.0,集群状态GREEN,shard,index以及数据量都正常,升级成功:

接下来elasticsearch内部的数据会进行数据格式的转换,由于笔者的环境是测试环境,数据量有限,所以转换速度很快,如果数据量很大,此处的时间可能会长些,在此过程中,server的日志会频繁的报cluster的healthy状态从RED到GREEN或者从YELLOW到GREEN,等此过程完毕后,则该阶段的升级完成
大版本升级:6.8.0>>7.9.0:
如果上面的小版本升级算是开胃菜的话,下面的大版本升级才是最关键的,也是最麻烦的,大概有下面几个问题需要解决:
1、jdk问题:
笔者第一次启动7.9.0,报了一个warn,大概的意思是elasticsearch后续版本可能会使用java11,而我当前版本的jdk是java8,建议升级jdk版本,java11?还没用上如此先进的版本,后来学些了下,7.9.0版本的elasticsearch自带了一个openjdk,所以最简单的办法就是直接注释掉环境变量中的jdk,使用elasticsearch自带的openjdk,但是问题时原本的jvm.options中的JVM相关的配置不生效,后续相关的配置优化需要额外的研究:
![]()
2、elasticsearch节点启动无法生成集群的问题:
报错如下:
先是:org.elasticsearch.discovery.MasterNotDiscoveredException: null
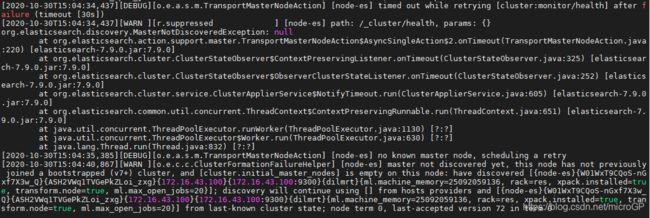
然后是:org.elasticsearch.node.NodeClosedException: node closed {node-es}

这个问题的产生第一个要保证有资格成为master的节点数达到需求,在7.X之前的版本,需要node.master都设置为true的节点数大于等于discovery.zen.minimum_master_nodes将这个配置的值。在本文中,由于只有一个节点,所以该节点必须设置node.master=true,并且discovery.zen.minimum_master_nodes将这个配置设置为1;但是7.X版本后该配置发生了变化,旧的配置已经失效,如果是滚动升级,则elasticsearch的集群引导会自动执行保证elasticsearch正常运行,后续在elasticsearch.yml中增加另外一个配置:cluster.initial_master_nodes: [node-es],但当前的升级模式下,则必须手动修改该配置,重启问题解决。
同样的问题也可能会有下面的报错信息:
ERROR: [1] bootstrap checks failed
[1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured在启动的时候check配置文件发现,这三个参数不能全量为空,而这三个参数其实对应的是之前版本的三个参数:
| 旧名称 | 新名称 |
|---|---|
discovery.zen.ping.unicast.hosts |
discovery.seed_hosts |
discovery.zen.hosts_provider |
discovery.seed_providers |
| discovery.zen.minimum_master_nodes | cluster.initial_master_nodes |
修改第三个参数cluster.initial_master_nodes: [node-es]即可,错误就解决了。
这两个问题解决之后,集群正常启动,和上面的一样的流程:
出现如下日志说明大版本升级完成:
![]()
查看cerebro:
机器版本已经升级到7.9.0,集群状态GREEN,shard,index以及数据量都正常,升级成功:
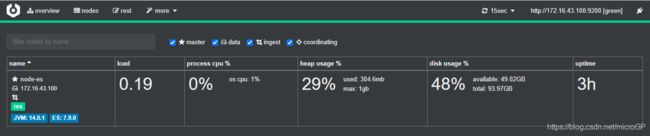
接下来elasticsearch内部的数据会进行数据格式的转换,由于笔者的环境是测试环境,数据量有限,所以转换速度很快,如果数据量很大,此处的时间可能会长些,在此过程中,server的日志会频繁的报cluster的healthy状态从RED到GREEN或者从YELLOW到GREEN,等此过程完毕后,则该阶段的升级完成
kibana升级
由于kibana的版本是强依赖elasticsearch的版本,所以kibana需要升级到7.9.0,由于我使用了cerebro,所以kibana不需要升级到6.8.0,直接升级到7.9.0即可
准备工作:
下载7.9.0的kibana到服务器,然后将旧版本的kibana.yml复制到新版本的config目录下
升级过程:
从6.0.0到7.9.0版本,尤其版本差距过大,导致部分配置项变更,直接启动会出现了如下的错误:
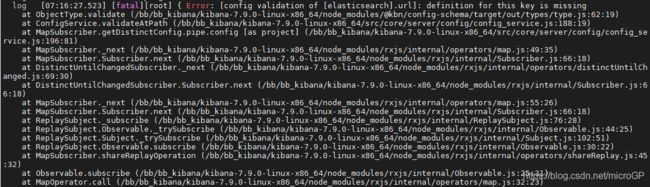
从日志来看是因为elasticsearch.url不可用,导致了启动报错,后来经过学习发现,由于版本的更迭,配置项发生了变更,需要用: elasticsearch.hosts, 而不是: elasticsearch.url,修改之后重新启动,kibana即启动成功,但是不得不说新版本的kibana和旧版本页面布局差别还不小,差点没认出来....
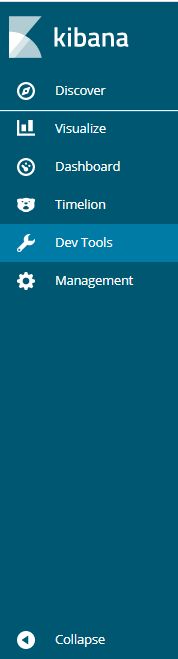
6.0.0版本的kibana工具栏:
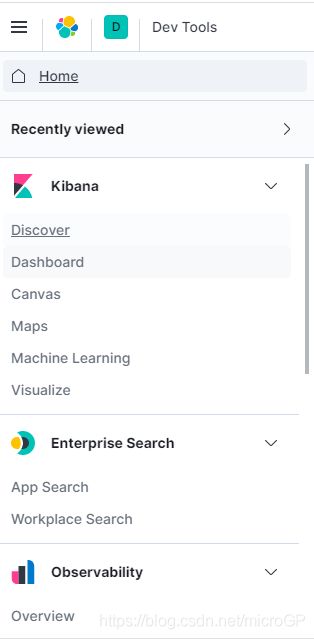
7.9.0版本的kibana工具栏:
后记
看到这里的小伙伴我在这里致以深深的谢意,但是如果你认为升级的任务已经完成了十有八九了,那你就真的图样图森破了,这仅仅是个开始,后续还需要在集群以及大数据量上进行测试,来填各种坑;另外,elasticsearch升级server端的任务仅仅这一部分,更大的任务是client端的适配,第一次重启后由于几个模块和elasticsearch有keepalive的请求链接,所以报了很多诸如以下的错误:

也就是说使用6.0.0的client api去请求7.9.0的server是不被允许的(后续证明是java的transport client存在该问题,但是java restful client不存在该问题,特此补充说明),server端会直接close connection,最低的版本也需要是6.8.0,所以server端升级伴随着client端也要升级,考虑到web服务无数的elasticsearch查询以及聚合接口和即将要被淘汰的java api,我直接就歇菜了,此时我无比怀念kafka的client端和server端双向兼容的优点,心中感慨万千(万驼奔腾),后续从长计议吧。可以预见的是,后续相当长的时间和精力需要投入到这件事情上,但愿投入产出比能对得起我们的付出吧,祈祷!!!