大数据开发环境搭建系列二:Hadoop集群环境搭建
1. 写在前面
最近学习推荐系统, 想做一个类似于企业上的那种推荐系统(采用的阿里天池赛的一个电商数据集, 然后基于大数据的Lambda架构, 实现离线和在线相结合的实时推荐系统), 这样可以熟悉一下真实环境中的推荐系统流程, 但是这里面需要大数据的开发环境, 所以这里的这个系列是记录自己搭建大数据开发环境的整个过程, 这里面会涉及到Hadoop集群,Spark, zookeeper, HBase, Hive, Kafka等的相关安装和配置,当然后面也会整理目前学习到的关于前面这些东西的相关理论知识和最终的那个推荐系统, 经过这一段时间的摸索学习, 希望能对大数据开发和工业上的推荐系统流程有个宏观的初识,这一块涉及到技术上的细节偏多, 所以想记录一下, 方便以后查看和回练, 开始
上一篇文章已经把环境搭建前的准备和集群相关配置搞定, 目前是建立了一台虚拟机并完成了相关的设置工作, 这篇文章开始搭建Hadoop环境,这里打算分两块, 一块是单节点环境搭建,也就是只有一台服务器,所有的功能都集中一台服务器中。这里面涉及到Hadoop的一些基本配置, 并且这些配置在搭建多节点集群中也会用到,所以搭建完了这个,直接在克隆出两台来之后,省事很多。所以首先是Hadoop Single Node Cluster搭建, 然后是Hadoop Multi Node Cluster的搭建。
2. Hadoop Single Node Cluster安装
Hadoop Single Node Cluster只用一台机器建立Hadoop环境, 仍然可以使用Hadoop命令,但是无法使用多台机器的威力,但是对于硬件不足又想练习Hadoop的伙伴来讲是个不错的选择,既然前面已经搞了一台master,就顺带着基于这个机器搭一个单节点的Hadoop, 这样也方便后面多节点集群的搭建。单节点集群这样的感觉:
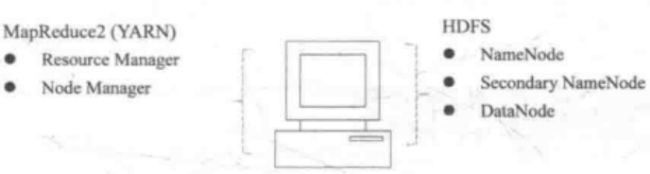
单节点比较简单,不用涉及到机器之间通信啥的,所以我们前面既然安了Java了,这里就可以直接装Hadoop了。
把hadoop安装包解压, 然后移动到opt/bigdata/hadoop/,并重新命名,三行命令:
tar zxvf hadoop-2.8.2.tar.gz
mkdir /opt/bigdata/hadoop/
mv hadoop-2.8.2 /opt/bigdata/hadoop/hadoop2.8.2
由于环境变量第一篇里面已经设置了,如果没有设置的话,这里要设置一下环境变量:
vim /etc/profile
# 环境变量
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop2.8
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
# 链接库的相关设置
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
# 加入到path
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 生效环境变量
source /etc/profile
这里对hadoop的目录进行一个说明:
- bin/: 各项运行文件, 包括Hadoop, HDFS, YARN等
- sbin/: 各项shell运行文件, 包括start-all.sh, stop-all.sh
- etc/: etc/hadoop 子目录包含Hadoop的配置文件, 例如hadoop-env.sh, core-site.xml, yarn-site.xml, mapred-site.xml, hdfs-site.xml
- lib/: Hadoop函数库
- logs/: 系统日志, 可以查看系统运行原因, 运行有问题可从日志中找出错误原因
下面修改配置文件了, 主要有core-site.xml, hadoop-env.sh, hdfs-site.xml, mapred-site.xml等配置文件要修改。这些配置文件的主要作用:
- core-site.xml 指定hdfs的访问方式
- hdfs-site.xml 指定namenode 和 datanode 的数据存储位置
- mapred-site.xml 配置mapreduce
- yarn-site.xml 配置yarn
下面一一来配置,当然这里单节点和多节点会有些不一样, 这里我们先进行单节点的文件配置。
2.1 修改hadoop-env.sh
hadoop-env.sh是Hadoop的配置文件,这里需要设置Java的安装路径, 输入命令:
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/hadoop-env.sh
把JAVA_HOME这一行修改成Java JDK所在的位置:
export JAVA_HOME=${
JAVA_HOME}
# 改为
export JAVA_HOME=/opt/bigdata/java/jdk1.8
2.2 设置core-site.xml
这里面必须设置HDFS的默认名称, 当我们用命令或者程序存取HDFS的时候,可以使用此名称, 输入命令
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/core-site.xml
在里面加入:
fs.default.name</name>
hdfs://localhost:9000</value>
</property>
</configuration>
2.3 设置yarn-site.xml
文件中含有YARN的相关配置设置, 输入命令
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/yarn-site.xml
里面加入:
<!-- Site specific YARN configuration properties -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
2.4 设置mapred-site.xml
这个文件用于监控Map与Reduce程序的JobTrack任务分配情况以及TaskTracker任务运行情况, Hadoop提供了设置的模板文件, 复制修改。
复制模板文件到mapred-site.xml, 然后进行编辑
cp /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml.template /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml
后面加入:
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>
2.5 设置hdfs-site.xml
设置备份副本数量, namenode和datanode的存储目录等, 输入命令:
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/hdfs-site.xml
在里面加入:
dfs.replication</name>
3</value> # 备份数量
</property>
# namenode数据存储目录
dfs.namenode.name.dir</name>
file:/opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/namenode</value>
</property>
# datanode数据存储目录
dfs.datanode.data.dir</name>
file:/opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
好了,相关配置完毕, 下面创建并格式化HDFS
2.6 创建并格式化HDFS目录
创建NameNode数据存储目录和DataNode数据存储目录:
mkdir -p /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/namenode
mkdir -p /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/datanode
将HDFS进行格式化:
hadoop namenode -format
2.7 启动Hadoop
上面工作做完,就可以启动Hadoop了, 两种方式:
- 分别启动HDFS, YARN, 使用start-dfs.sh和start-yarn.sh
- 同时启动HDFS和YARN: start-all.sh
这里采用了第二种方式启动, 输入
start-all.sh
等待,然后就起来了, 用jps查看已经启动的进程如下:
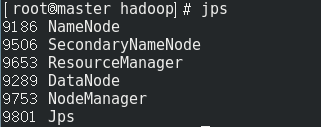
因为只有一台服务器,所以所有功能集中在一台服务中, 可以看到:
- HDFS功能: NameNode、SecondaryNameNode、DataNode启动
- YARN: Resource Manager、NodeManager启动
这样就能愉快的玩Hdfs命令了在单机上:

这里又探索了一下, 发现了两个问题:
- root用户至高无上
- 如果切换成普通用户icss, 使用
hadoop fs -mkdir, 会显示权限拒绝,不能创建文件, 这时候要么切换成root用户操作,要么就用root身份修改操作的文件夹权限hadoop fs -chmod 777 /test, 要不然上面那个hello文件夹用icss的身份创建不出来。
启动了之后,也可以打开相应的界面。
- 打开Hadoop Resource Manager Web界面
这个界面可以查看当前Hadoop的状态, Node节点,应用程序和进程运行状态。浏览器输入网址:http://loaclhost:8088/
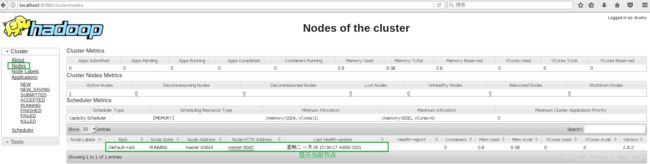
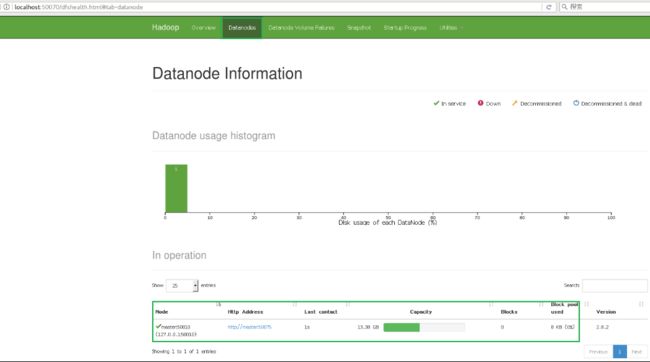
- NameNode HDFS Web界面
这个界面可以检查当前HDFS与DataNode的运行情况。浏览器输入:http:localhost:50070/
到这里,单节点集群搭建完毕,配置一定不能出错,这个逻辑也要清楚, 感觉这些东西之间的逻辑关系非常重要,懂了这个之后, 配置起来就容易多了,也不用管是否操作系统一致,版本是否和一样(兼容即可), 存储路径等问题了。 记得第一次走的时候,我是跟着一本书, 那时候完全就是人家是啥路径起啥名,我也跟着啥路径起啥名,生怕出错,而现在,大体上知道了逻辑之后, 有些文件路径和名称,或者操作系统, 版本,环境变量的配置等,做起来就比较自信了,其实出了错,也大体知道是哪里的问题,因为这个地方一般出错,都是配置文件可能哪个地方不小心打错东西了。
好了,下面开始多节点的Hadoop环境搭建了,终于玩集群环境了, 我这也是第一次基于CentOS搭建, 且并没有参考权威的博文啥的,完全是凭借之前跟着一本书在Ubuntu上走了一遍搭建流程之后,凭借着他们的逻辑关系摸索, 这里的版本和之前也不一样, 系统也不一样, 包括各种安装路径,安装包等都不一样, 并且之前我只到了Spark集群的摸索,而这里又尝试HBase, Hive,Kafka,mysql等, 所以我也没有把握一次就能搞定, 只能慢慢摸索和试错, 谁让咱好奇心和想玩这个的心太重呢哈哈 ,还好是虚拟机,大不了重来一遍, 相信通过试错也能学到不少新东西, 不说了,开始正题。
在多节点环境搭建之前,关闭上面的集群环境,然后关机。
stop-all.sh
shutdow -h now
3. Hadoop Multi Node Cluster的安装
Hadoop Multi Node Cluster由多台计算机组成:
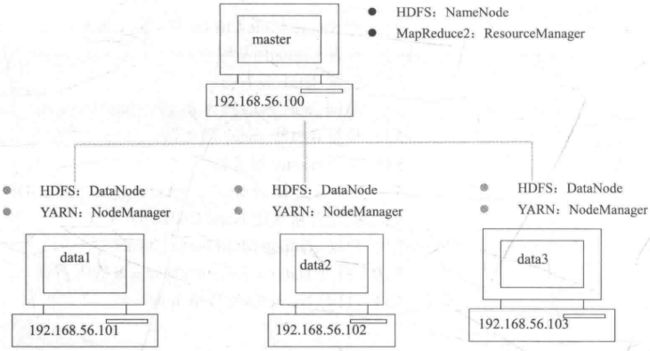
- 一台主要的计算机Master, 在HDFS中担任Name Node的角色, 在YARN中担任Resource Manager角色
- 多台计算机slave01, slave02, 在HDFS中担任Data Node的角色, YARN中担任Node Manager角色
就是搞这样的一个东西, 这个图片来自Hadoop+Spark大数据巨量分析的一本书, 这里是三个data节点一个master节点, 我这里硬件的原因,并且后面还要跑Python的一些框架, 所以去掉了一个data节点, 名字和IP也和这个都不一样了,感觉没有必要完全复制人家的,咱要学习思想:
那说一说我们实现的思路了, 目前我们是有了一台虚拟机master, 并且是搭建好了单节点的Hadoop环境, 由于有些公共的操作,比如虚拟机的相关设置, 集群准备的环境相关配置等,要这些机器都保持一致,所以这里为了省事, 我直接基于这个master,先按照多节点集群的配置进行修改一波,毕竟多节点和单节点关于Hadoop的那些文件上差距还是挺大的, 然后复制出两台和master一模一样的机器,然后再分别对于这三个进行配置。
3.1 把master按照多节点集群进行修改配置
首先, 将master重命名成slave01, 也就是先看作其中的一个DataNode节点进行配置,这个会简单一些, 右击虚拟机-> 设置->常规->改为slave01,然后启动。 注意, 上面的单节点环境搭建是顺带着走一遍的,这里我没有保存那个虚拟机(直接改为slave01,按照多节点环境进行修改配置),因为一般很少用到单节点的Hadoop, 如果想保存的话,那就可以把master进行复制一份叫做slave01,然后再进行下面操作。
3.1.1 设置网卡
第一个步骤是设置网卡,就是一台虚拟机两个网卡的配置,这个在第一篇里面设置完了, 看下面这个图应该更加清晰我们之前的设置原理:
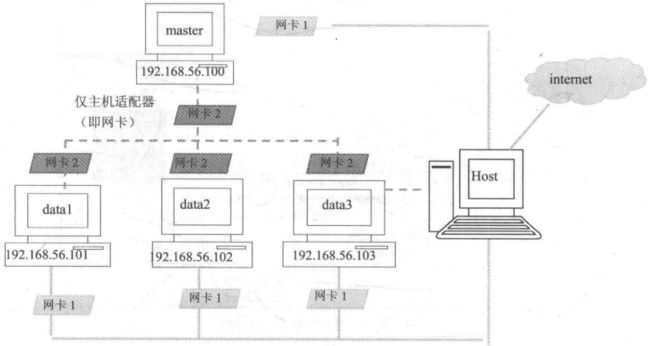
两块网卡,一个负责内部网络中的集群连接, 连接方式Host-Only, 静态设置ip, 而另一个负责外部通信,动态设置ip, 连接方式NAT模式。这一步跳过去。
3.1.2 设置slave01服务器
这里我们需要改一下静态ip地址,因为之前是按照master那个设置的192.168.56.101, 这个既然要当做slave01了,我们设置成192.168.56.102. 直接修改配置文件吧这里:
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
# ip最后改成102
# 重启网络服务
service network restart
这样看下效果:
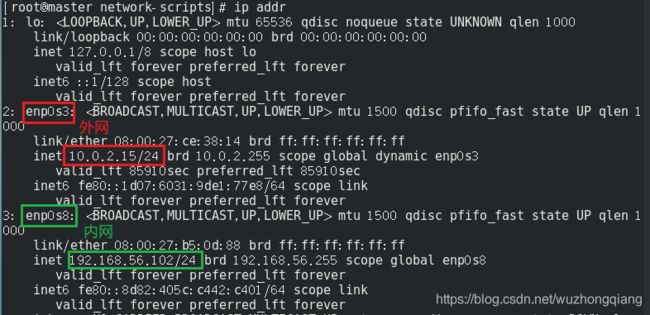
3.1.3 Host主机名修改
前面我们是改了虚拟机的名称,我们的主机名可还是master呀,我们需要改一下主机名,改成slave01,命令
vim /etc/hostname # master改成slave01
显示如下:
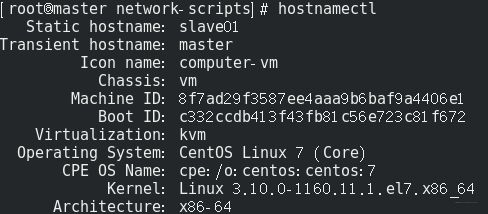
这样,主机名就改过来了, 重开一个命令行。
3.1.4 编辑core-site.xml
设置HDFS的默认名称, 当使用命令或者程序来存取HDFS时, 可以使用此名称, 单节点那里我们是一台计算机,所以用了localhost, 而多台计算机的话,要指明主机名, 直接切成root进行下面的写入操作:
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/core-site.xml
把localhost改成master。
fs.default.name</name>
hdfs://master:9000</value>
</property>
</configuration>
之后当程序存取HDFS时, 会使用hdfs://master:9000这个目标存取HDFS。
3.1.5 编辑yarn-site.xml
这个涉及到调度的配置,所以这个很重要,这里要修改相关配置了
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/yarn-site.xml
后面加入(下面为了理解加了注释,在真文件中去掉):
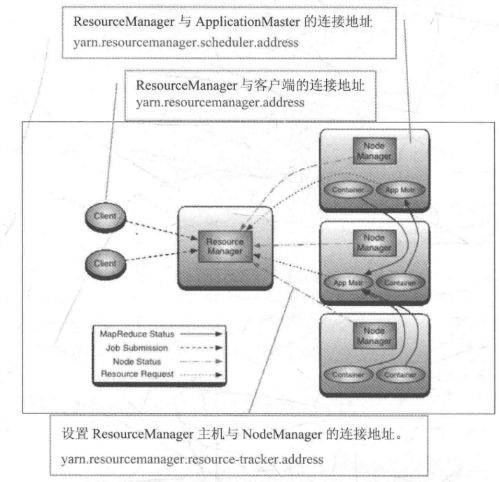
# ResourceManager主机与NodeManager的连接地址, 通过这个地址, NondManager向ResourceManager汇报运行情况
yarn.resourcemanager.resource-tracker.address</name>
master:8025</value>
</property>
# ResourceManager与ApplicationMaster连接地址,通过这个,ApplicationMaster向ResourceManager申请资源,释放资源
yarn.resourcemanager.scheduler.address</name>
master:8030</value>
</property>
# ResourceManager与客户端的连接地址,通过这个,客户端向ResourceManager注册应用程序,删除应用程序等
yarn.resourcemanager.address</name>
master:8050</value>
</property>
yarn.resourcemanager.admin.address</name>
master:8033</value>
</property>
yarn.scheduler.maximum-allocation-mb</name>
8182</value>
</property>
yarn.nodemanager.vmem-pmem-ratio</name>
2.1</value>
</property>
yarn.nodemanager.resource.memory-mb</name>
2048</value>
</property>
# 这个对于虚拟机来说很重要,尤其是内存不足的时候, 如果不加,很可能虚拟内存爆掉
yarn.nodemanager.vmem-check-enabled</name>
false</value>
</property>
yarn.nodemanager.pmem-check-enabled</name>
false</value>
</property>
关于设置,看下YARN的架构图:
3.1.6 编辑mapred-site.xml
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/mapred-site.xml
修改设置map reduce job tracker的连接地址master:54311
mapred.job.tracker</name>
master:54311</value>
</property>
</configuration>
3.1.7 编辑hdfs-site.xml
HDFS分布式文件系统的相关设置,之前单节点只有一台服务器, 身兼DataNode和NameNode, 而这里的slave01只有DataNode身份,所以需要删除掉NameNode的设置,只保留DataNode的设置。
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/hdfs-site.xml
这里把Namenode那块删除就行。这样, slave01就设置好了。 重启一下看看ip和外网能不能进去。
没有问题了,关机。
3.2 slave01克隆出两台主机master和slave02并分别设置
slave01设置好之后, 接下来就是复制slave01, 单击右键复制, 修改名称slave02, 勾选初始化所有网卡的MAC地址, 下一步,选择完全复制即可。 然后再复制出一台master来。
3.2.1 设置slave02服务器
关于slave02, 由于和slave01的作用一样,这里不需要设置太多东西了已经, 主要改一下主机名和静态ip即可。
启动slave02, 首先,设置固定的ip地址:192.168.56.103。 具体设置方法和上面一模一样
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
# ip最后改成103
# 重启网络服务
service network restart
这里发现重启网络服务会报错Job for network.service failed because the control process exited with error code.:

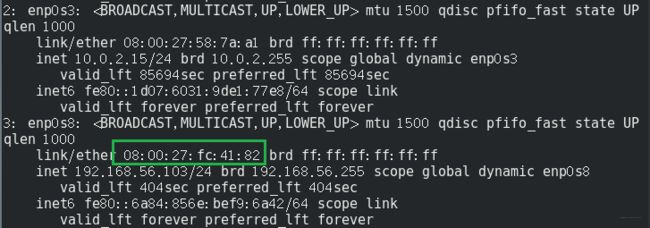
我这里的原因是enp0s8网卡的Mac地址没有匹配上,原因也很简单,因为我们是从slave01直接复制过来的ifcfg-enp0s8, 那么这里面的Mac地址是slave01的, 而我们复制的时候有个选项是重新初始化所有网卡的Mac地址,那肯定匹配不上了呀。 所以我们用ip addr,看一下enp0s8的Mac地址,然后将配置文件里面的HWADDR改成新的Mac地址即可。
修改主机名:
vi /etc/hostname # 把01改成02
这样slave02设置完成,关机即可。
3.2.3 设置master服务器
这里面需要设置ip地址, 主机名称, hdfs-site.xml, masters, salves, 毕竟这个是集群中的老大。启动master。
设置ip地址和上面一样:
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
# ip最后改成101
# 同样需要修改Mac地址
# 重启网络服务
service network restart
设置主机名:
vi /etc/hostname # 把slave01改成master
设置hdfs-site.xml, 这里由于master是NameNode, 所以这里删除DataNode的设置,加上NameNode的设置。
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/hdfs-site.xml
修改成下面这样:
dfs.namenode.name.dir</name>
file:/opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/namenode</value>
</property>
</configuration>
这里还要编辑master文件,告诉Hadoop系统哪一台服务器是NameNode
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/masters
里面加入master
同时也要编辑slaves文件,告诉Hadoop系统哪些是DataNode。
gedit /opt/bigdata/hadoop/hadoop2.8/etc/hadoop/slaves
里面加入slave01、slave02.

这样master配置完毕, 关机。
3.3 三台机器之间的SSH免密登录
在第一篇文章中并没有记录三台机器之间的SSH免密登录,因为那时候只有一台虚拟机,而这里三台了,需要记录一下免密登录是怎么弄的, 因为如果不免密登录的话,后面开启多节点集群会总是让输入密码,很烦。 这个地方其实又进了一个坑,开始的时候,我是从上面那台虚拟机里面设置了免密登录的,然后进行复制了两台,可是后面连接的时候,竟然发现这样不起作用(Ubuntu的时候我记得是起作用的,可以看Hadoop+spark海量数据分析那本书里面,就是那样弄得)。所以这里又卡了好久才搞定。
接下来看看三台机器之间的SSH免密登录真正是咋做的:
首先,先从三台机器上各自的执行下面命令:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
这样分别在各自机器的~/.ssh目录下同时生成id_rsa(私钥)和id_rsa.pub(公钥)两个文件。 然后如果master想免密访问slave01的时候,需要输入下面的命令, 也就是把自己的公钥文件传给slave01:
# -i是追加
ssh-copy-id -i ~/.ssh/id_rsa.pub icss@slave01
# 同理,如果想免密访问slave02
ssh-copy-id -i ~/.ssh/id_rsa.pub icss@slave02
# 同理,如果想免密访问master
ssh-copy-id -i ~/.ssh/id_rsa.pub icss@master
这三行代码, 能够分别从slave01, slave02和master的~/.ssh/下面自动生成一个authorized_keys文件, 然后里面都追加上master的id_rsa.pub的内容。
同样的原理, 如果想让他们彼此访问的话,上面的三行代码在slave01和slave02上也执行一遍,这样authorized_keys文件中就有了三台机器的公钥,这时候就可以互相免密登录访问了。
即可以在master下:

但是有时候,ssh的时候会报这样的一个错误:sign_and_send_pubkey: signing failed: agent refused operation。这时候,先执行以下下面的这两句中的一句(目前测试发现一句就能解决问题)
ssh-add
eval "$(ssh-agent -s)"
这样, 三台机器之间就能正常通信了。 当然,我第一次的时候,在刚开始连接的时候还不是直接就发现免密登录不起作用,而是先出现的下面这个问题。
3.4 master连接到slave01,slave02并创建HDFS目录
通过上面的步骤,我们已经搭建完了Hadoop集群,并完成了相关配置,下面我们就来准备启动了,快到见证奇迹的时刻, 当然启动之前还要做点类似于打火的两个小工作。
第一个就是检验一下ssh免密登录好使不, 首先, Windows关机,释放一下所有的内存和一些垃圾文件(内存太紧张了), 然后把三台虚拟机同时开起来。
下面就只在master上操作了:
3.4.1 连接到slave01
这里连接的时候又出现了一些问题, master没法连接到slave01, 报了个port 22-No route to host的问题, 然后就发现master没法ping通两个slave, slave也没法ping通master了。这里又卡了我好久,明明之前配置好了啊,这个问题依然是出现在内部网卡上面,还是内部网卡enp0s8的问题, 还是Mac地址对应不上的问题。 所以我又查了一下master的Mac,再对比了一下配置里面的前两个,发现确实不一样, 注意是前两个:
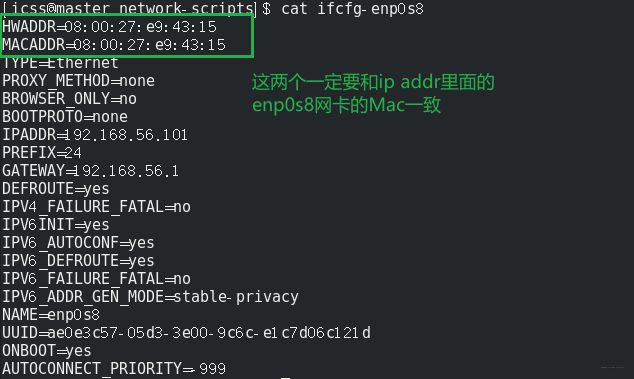
否则, 这个网卡会有问题, 所以master和slave02都是这里的问题,而他俩正好都是slave01克隆出来的, Mac地址用的是slave01的。 本来想省点事,结果在这里又掉进去了。 不过最后总算解决。
解决了这个问题之后,接着往下走就行了:
# 连接slave01
ssh slave01
# 删除hdfs所有目录
sudo rm -rf /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs
# 创建DataNode存储目录
mkdir -p /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/datanode
# 将目录的所有者更改为icss
sudo chown -R icss:icss /opt/bigdata/hadoop/hadoop2.8
# 回到master
exit
在这里,我又发现了免密登录其实没有起作用,连接slave01的时候发现依然需要密码, 这时候我又开始解决免密登录的问题,就是3.3, 解决完了这个,才一切正常了。
3.4.2 连接到slave02
# 连接slave02
ssh slave02
# 删除hdfs所有目录
sudo rm -rf /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs
# 创建DataNode存储目录
mkdir -p /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/datanode
# 将目录的所有者更改为icss
sudo chown -R icss:icss /opt/bigdata/hadoop/hadoop2.8
# 回到master
exit
看下效果:
3.5 创建并格式化NameNode HDFS目录
# 删除之前的HDFS目录
sudo rm -rf /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs
# 创建NameNode目录
mkdir -p /opt/bigdata/hadoop/hadoop2.8/hadoop_data/hdfs/namenode
# 将目录的所有者更为icss
sudo chown -R icss:icss /opt/bigdata/hadoop/hadoop2.8
下面格式化NameNode HDFS目录
hadoop namenode -format
3.6 启动Hadoop Multi Node Cluster
下面是见证奇迹的时刻了:
start-all.sh
在master上, jps查看进程:
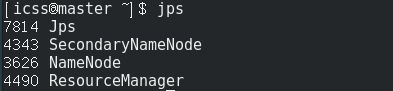
发现HDFS的功能和YARN的管理功能都已启动。
在slave01和slave02上查看进程:
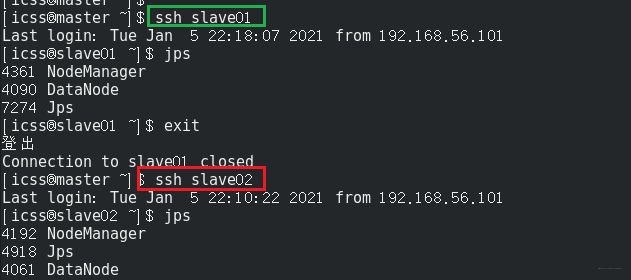
DataNode也启动了起来。
3.7 界面查看
ResourceManager Web界面: http://master:8088/
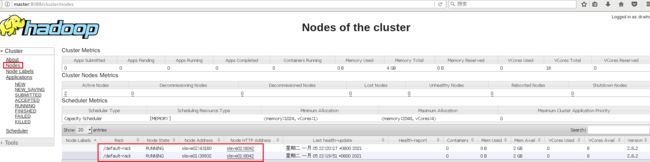
NameNode Web界面: http://master:50070/
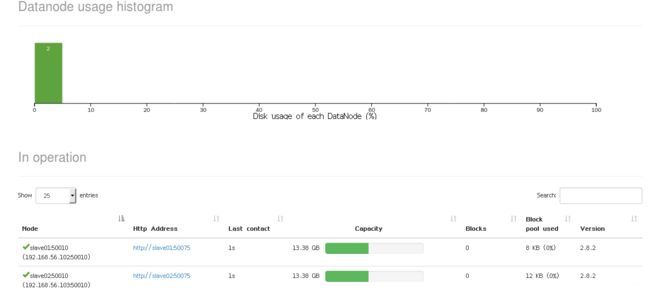
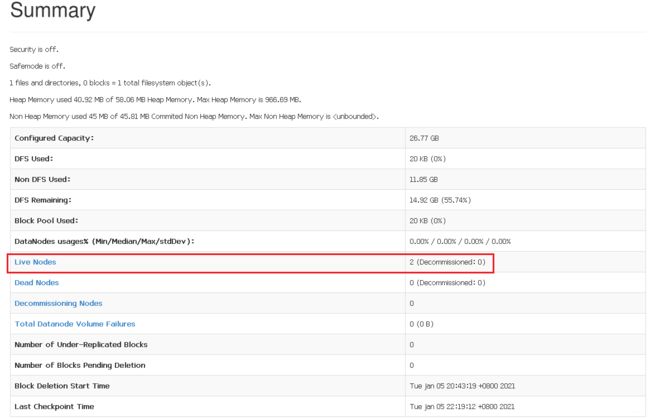
用了整整一天的时间,从建立虚拟机,配环境, 到这里的搭建Hadoop集群, 不停的摸索和报错, 终于搞定了, Hadoop环境搞定之后,接下来就是Spark了,继续Rush