论文笔记 | Multi-Grained Named Entity Recognition
作者:任重灿
单位:燕山大学
目录
- 论文概述
-
- 引言
-
- 命名实体识别是什么?
- 问题
- 提出的框架
-
- 检测器
-
- 词处理器
- 句处理器
- 检测网络
- 分类器
-
- 词处理器
- 实体处理器
- 分类网络
- 实验
-
- 嵌套NER任务
- 非重叠NER任务
论文概述
论文来源
该论文来自于ACL,发表于2019年。
提出了一种用于多粒度命名实体识别的神经网络框架MGNER,该框架允许句子中的多个实体(entities)或实体提及(entity mentions)不重叠或完全嵌套。MGNER框架具有高度模块化的特点,每个组件都可以采用多种神经网络实现。实验结果表明,无论是嵌套的NER任务还是传统的非重叠NER任务,MGNER都能得到最先进的效果。
引言
命名实体识别是什么?
命名实体识别(Named Entity Recognition, NER),即从原始文本中识别有意义的实体,如人名,地名等专有名词,NER对理解自然语言的语义起着至关重要的作用,是NLP的基本任务之一。提取的命名实体可以便于后续的各种NLP任务,包括语法解析、问答和关系抽取。
问题
以往的研究将NER看作是一个序列标记问题。例如,将RNN与条件随机场(CRF)相结合,在NER任务上可取得不错的性能。然而,这样只识别原始文本上的单一序列扫描中不重叠的实体,而无法检测嵌套的命名实体,这些实体被嵌入较长的实体提到中,如图所示:

可见句中两个实体(Chinese,France)嵌套在一个实体(the Chinese embassy in France)中。
由于自然语言的语义结构,嵌套实体可能无处不在。在过去数年也有许多用于提取嵌套命名实体的方法被提出。这些模型显式地设计用于识别嵌套的命名实体。但与序列标记模型相比,它们在非重叠命名实体识别方面表现不佳。
为了解决以上问题,该文提出了一种新的神经网络框架MGNER,用于多粒度命名实体识别。同时适用于处理嵌套NER和非重叠NER。
提出的框架
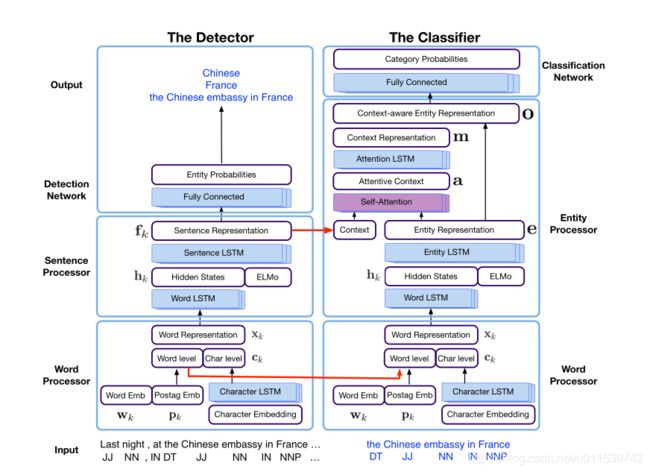
上图概述了用于多粒度实体识别的MGNER框架,MGNER的思想即:首先通过检测器检测不同粒度的实体位置,然后通过分类器将这些实体分类到不同的预定义类别中。MGNER有五种类型的模块:词处理器,句处理器,实体处理器,检测网络,分类网络。且每个模块都可以采用多种神经网络结构。
MGNER包括两个子网络:检测器和分类器。其中检测器检测所有可能的实体位置,而分类器的目的是将检测到的实体分类到预定义的实体类别。
MGNER中的每个模块都可以用各种不同的神经网络来替代。例如,BERT可以用作文字处理器,胶囊模型可以集成到分类网络中。
为了提高学习速度和MGNER的性能,该模型使用一系列共享的输入特征对检测器和分类器进行训练,包括预先训练的单词嵌入和预先训练的语言模型特征。在检测器中训练的句子级语义特征也被转移到分类器中,以引入和利用上下文信息。
检测器
该检测器包含三个模块:提取词级语义特征的词处理器,为每个语句学习上下文信息的句子处理器,判断词段是否为实体的检测网络。
目的是在每个语句中检测可能的实体位置。它以一个语句作为输入,并输出一组候选实体。检测器的体系结构如框架图左侧所示。即,通过预先训练的词嵌入、POS标签信息和字符级的单词信息,生成有语义意义的词表示。词表示被连接在一起,从而产生上下文感知的句表示。然后在检测网络中检查每个可能的词段,并决定是否接受它作为一个实体。
词处理器
词处理器为每个token提取语义上有意义的词表示。给定一个有K个token的输入句子,每个token通过将预先训练好的词嵌入 w k \textbf{w}_k wk、POS标签(词性标注)嵌入 p k \textbf{p}_k pk、和字符级的单词信息 c k \textbf{c}_k ck连接起来,每个token就表示为:
x k = [ w k ; p k ; c k ] \textbf{x}_k=[\textbf{w}_k;\textbf{p}_k;\textbf{c}_k] xk=[wk;pk;ck]
通过GloVe得到预训练词向量 w k \textbf{w}_k wk,通过双向LSTM层捕获形态信息,得到字符级单词信息 c k \textbf{c}_k ck。如上图底部所示,字符嵌入被输入到character LSTM中。来自前向和后向character LSTM的最终隐藏状态被连接为字符级单词信息 c k \textbf{c}_k ck。这些词性标注嵌入和字符嵌入是在学习过程中随机初始化和学习的。
句处理器
为了从每个句子中学习上下文信息,采用另一种双向LSTM(word LSTM)对语句进行序列编码。对于每个token,前向隐藏状态和后向隐藏状态被连接为隐藏状态 h k \textbf{h}_k hk。word LSTM的隐藏状态维数为 D w l D_{wl} Dwl
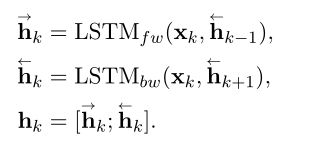
此外,利用预训练的语言模型ELMo,预训练的ELMo嵌入和word LSTM中的隐藏状态是串联,从而每个token的串联隐藏状态 h k \textbf{h}_k hk可以重新表述为:

其中使用三层的bi-LSTM神经网络作为语言模型。因为低层的LSTM隐藏状态能对语法属性进行建模,而高级LSTM隐藏状态可以捕获上下文信息。
在连接后的隐藏状态 h k \textbf{h}_k hk上有一个sentence LSTM层。这个sentence LSTM中的前向和后向隐藏状态被连接为每个token的最终句表示 f k \textbf{f}_k fk。
检测网络
利用 f k \textbf{f}_k fk中获得的语义特征,我们可以识别出每个语句中的候选实体。
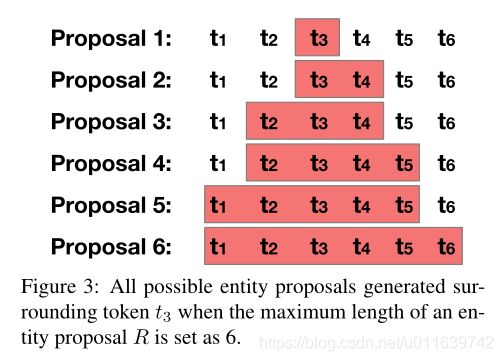
为了枚举所有候选实体,在每个token周围生成不同长度的候选实体。对于每个token位置,生成长度从1到最大长度R的R个候选实体,如图:
下式用于计算每个实体的概率:
s k = s o f t m a x ( f k W p + b p ) \textbf{s}_k= softmax (\textbf{f}_k\textbf{W}_p+ \textbf{b}_p) sk=softmax(fkWp+bp)
其中, W p \textbf{W}_p Wp和 b p \textbf{b}_p bp分别是权值和偏置项; s k \textbf{s}_k sk包含2R个分数,其中R个分表示是实体的概率,另R个分表示不是位置k的实体的概率。
检测器中使用的交叉熵损失函数如下:

其中, y k r \textbf{y}_k^r ykr是位置k上的候选类型r的标签, s k r \textbf{s}_k^r skr是位置k是候选类型r的实体的概率。
分类器
分类器的目的是将从检测器中获得的候选实体分类到预定义的不同实体类别中。框架图的右侧显示了分类器的框架,它由三个模块组成:与检测器中具有相同结构的字处理器,获取实体特征的实体处理器,以及将实体分类到预定义类别的分类网络。
对于嵌套NER任务,所有候选实体将被保存并输入到分类器中。对于具有非重叠实体的NER任务,利用非最大抑制(NMS)算法来处理冗余、重叠实体候选并输出真正的实体。NMS的思想:选择概率最大的候选实体,删除冲突实体提议,重复前面的过程,直到处理完所有提议。最后,得到这些非冲突的候选实体作为分类器的输入。
为了理解所提实体的上下文信息,利用句子级上下文信息和自注意力机制来帮助模型聚焦实体相关的上下文token。
词处理器
使用与检测器中相同的词处理器,将单词级嵌入从检测器中的词处理器中转移出来,以提高性能而加快学习过程。
实体处理器
将词表示输入到双向LSTM中,并将隐藏状态与ELMo语言模型嵌入连接作为实体特征。在实体特征上用一个双向LSTM来捕获实体词之间的序列信息。前向和后向实体LSTM的最后隐藏状态被连接为实体表示 e \textbf{e} e。
同一个词在不同的上下文中可能有不同的语义,为此当学习候选实体的语义表示时,需要将上下文信息考虑在内。从同一语句中的其他词中获取上下文信息。 c \textbf{c} c表示这些上下文词的上下文特征向量,可以从检测器的句子表示中提取。
建模上下文单词的一种简单方法是连接所有单词表示或平均它们。然而,当存在大量不相关的上下文词时,这种方法便不合适。为了选择相关度高的语境词并学习准确的语境表示,使用了自注意力机制来模拟并动态控制语境与实体之间的关系。自注意力模块采用实体表示 e \textbf{e} e和所有上下文特征 C \textbf{C} C作为输入,输出一个注意力权向量 a \textbf{a} a:
a = s o f t m a x ( CWe T ) \textbf{a} = softmax(\textbf{CWe}^T) a=softmax(CWeT)
其中 W \textbf{W} W为自注意力层的权重矩阵, a \textbf{a} a为不同语境词的自注意力权重。为了帮助模型聚焦于实体相关的上下文,计算注意向量 C a t t \textbf{C}^{att} Catt作为注意力加权上下文:
C a t t = a ∗ C \textbf{C}^{att}=\textbf{a}*\textbf{C} Catt=a∗C
注意力上下文的长度在不同语境中有所不同,而分类网络的目标是对候选实体进行分类,因此需要固定的嵌入大小,通过添加另一个LSTM层来实现这一点。使用一个Attention LSTM,并将前向和后向LSTM层的最后的隐藏状态连接,作为上下文表示 m \textbf{m} m。
将上下文表示 m \textbf{m} m和实体表示 e \textbf{e} e连接在一起作为上下文感知的实体表示 o \textbf{o} o,来对候选实体进行分类:
o = [ m ; e ] \textbf{o}= [\textbf{m};\textbf{e}] o=[m;e]
分类网络
采用两层全连接神经网络将候选对象分类为预先定义的类别:
p = s o f t m a x ( W c 2 ( σ ( oW c 1 + b c 1 ) ) + b c 2 ) \textbf{p} = softmax (\textbf{W}_{c2}(σ (\textbf{oW}_{c1}+ \textbf{b}_{c1})) + \textbf{b}_{c2}) p=softmax(Wc2(σ(oWc1+bc1))+bc2)
实际上,这个分类函数将候选实体分类为预设实体数+1个类型,多出来的一个类型表示候选实体不是真实实体。
最后,在分类网络中采用hinge loss:

其中 p w p_w pw是错误标签 y w y_w yw的概率, p r p_r pr是正确标签 y r y_r yr的概率。hinge loss使得正确标签的概率高于错误标签的概率,提高了分类性能。
实验
为了证明该框架在命名实体识别中的有效性,分别在嵌套的NER任务和传统的非重叠NER任务上进行实验。
对于嵌套命名实体识别任务,使用ACE-2004和ACE2005数据集,ACE数据集包含了人、设施、武器和车辆等七种不同类型的实体。
对于传统的NER任务,使用CoNLL-2003数据集,包含四种命名实体类型:位置、组织、人员和其他。
这三个数据集的概述如下表所示。可以观察到,大多数实体小于或等于6个token,因此选择最大实体长度R = 6。

嵌套NER任务
所提出的MGNER在识别嵌套命名实体的任务上表现良好,因为每一个可能的实体都会被检查和分类。下表为MGNER与一些基线模型在ACE-2004和ACE-2005数据集上的比较。其中,为了研究不同模块的影响,进行了消融实验,在上表底部,MGNER w/o attention去掉了自注意力机制,而MGNER w/o context去掉了所有的上下文信息。

以往的嵌套NER方法也能识别非重叠实体,但性能较差。为了分析本文提出的模型在重叠和非重叠实体上的表现分别如何,将测试数据分成两部分:有重叠实体的句子和没有重叠实体的句子。在ACE-2005数据集上,与四种最先进的嵌套NER模型比较。如下表所示,在两种情况下,MGNER都比基线表现得更好,尤其是不重叠的部分。

非重叠NER任务
对非重叠实体的NER任务,评估了提出的MGNER框架。这里比较了两种基线模型:专为非重叠NER任务设计的序列标记模型和嵌套NER模型,其中嵌套NER模型也提供了检测非重叠提及的能力。表中前四行为嵌套模型,中间五行为序列标记模型。可见MGNER优于所有基线模型。
同样也可以通过消融实验的结果观察到上下文信息和注意力机制的影响:单纯加入上下文信息,CoNLL-2003测试集上的F1评分从92.23提高到92.26,再加入注意力机制,F1评分提高到92.28。
