视频内容理解在手淘逛逛中的应用与落地

随着多媒体技术的发展,直播、短视频、AR等多媒体内容表现形式层出不穷,异彩纷呈。视频内容的理解在视频生产感知,理解分发中有哪些应用,为淘宝电商带来哪些影响?这几年,手淘商品展示模式一直在变化。1998年做文本,2005年进入图文时代,2017年进入淘宝直播时代。发展到今天,手淘新的业务增长点在哪里?下面我会从视频内容理解的角度着手分享在手淘逛逛中的应用与落地。

淘宝探索人货场新形势的发展历程
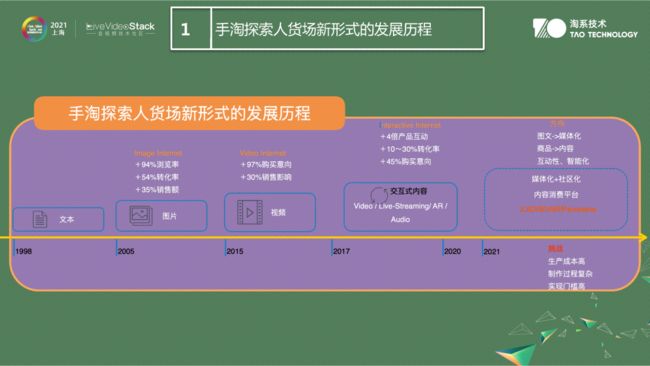
电商的表现形式在不断发生变化。友商像抖音、快手等内容厂商的DUA规模、用户时长都有快速增长;技术方面目前多媒体技术向内容化、社区化方向蓬勃发展。基于以上几个方面,手淘下一步要做以下几个方向:升级传统RGB直播的形式,从2.5D到3D再到AR形式做升级;手淘会探索内容业务的的增长点,从原来商品介绍转至对内容的介绍。当然万变不离其中就是通过多媒体形式做商品的表征。
逛逛的愿景

逛逛想要传达的理念,第一传达生活方式,例如构造真实消费的场景进行购物;第二由于是真实的人,每个人都有自己的人设,有自身人格化,希望逛逛产品传递人格化;第三逛逛产品不希望是高不可攀的,而希望是每个人都消费得起、性价比高的产品。上述就是逛逛的愿景。
逛逛内容业务面临的问题
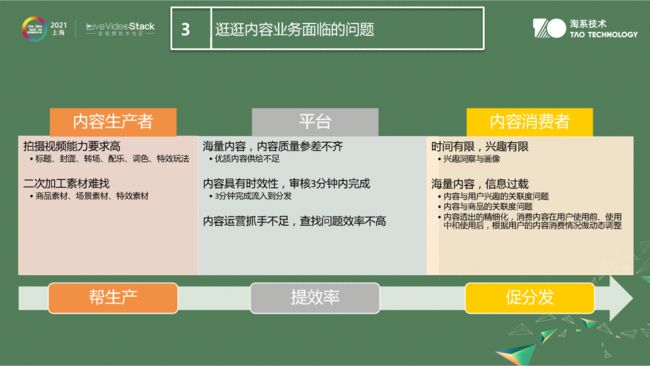
首先要有愿景做产品,最后落到技术上来看,面临技术挑战有以下几个部分:
生产者角度上的问题是:一是逛逛以短视频拍摄为主的产品,原来拍图片生产成本低,拍视频生产成本较高,需要选标题、封面图,做转场使视频生动有趣,做特效玩法(例如:张嘴、眨眼、口吐莲花);二是视频生产可以是视频内容的二次加工得来,那商品、场景、特效素材从哪里获取?
平台的角度上的问题是:所有生产的视频汇集成在平台侧,每日生产的视频量是一个海量的数据。一是海量内容参差不齐,如何对内容的快速审核、挑出优质视频内容;二是内容具有一定时效性。商品可以春夏秋冬卖一年,内容也会有热点信息,以及海量信息该如何进行快速处理?三是手淘商品有完整的结构化信息供运营,视频内容的raw data信息如何进行精细化运营?
消费者的角度上的问题是:每个人时间有限,除了工作,休闲时间刷刷抖音,看看逛逛的时间更加有限。另外对消费者而言,信息海量,例如,手淘每天产生几百万短视频,一个个看无法看完,如何形成消费者内容画像、根据消费者内容画像匹配合适内容就是我们要解决的问题。
面临上述三个问题,在算法上总结起来三句话:帮生产,加快生产效率;提效率,在平台上完成海量内容的结构化语义理解;促分发,让合适同学看见合适内容。后续我将围绕这些问题分享算法上解决上述问题的方式。
逛逛内容视觉算法的整体技术架构

内容视觉算法分成两块:互动视觉和互动玩法来帮助内容分发;在内容理解方面拆成四部分:智能生产,智能审核,智能解锁,内容语义。本次分享重点讲的是智能生产、智能审核、智能解锁、智能语义。
智能生产
第一部分是内容生产面临的问题。
▐ 智能创作
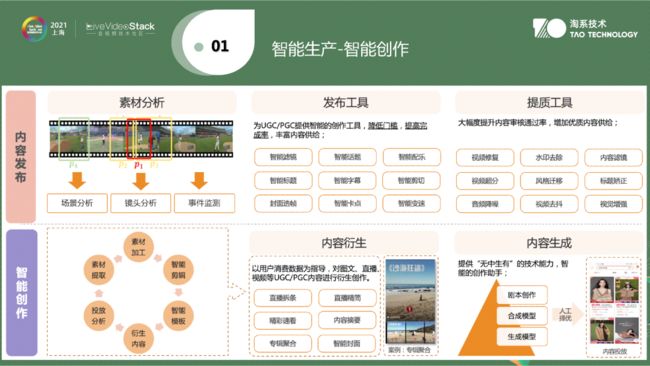
智能生产上述提到了一些问题,在问题之下,分享一下解决方案。解决方案分为两部分。
第一部分是提高视频的发布效率,如何让发布者更高效发布内容,生产短视频。自动生产一些滤镜、标题,自动生成一些可以打动人心的话题、自动调节色彩空间,提升视频发布的成功率。
第二部分是素材再加工。将原始拍摄的视频内容拆散开来,将商品、人物从原始视频中抽出。与智能模板,智能滤镜等结合,二次加工成短视频。
以上是智能生产这两部分要做的整体介绍。其中涉及内容很多,后续会挑选关键点讲一下具体如何来做到。
▐ 视觉元素解构

首先讲到关于智能生产中视觉元素解构。对内容重新编辑需要将原始内容从原有视频中拆出来。为了做到这些,我们构建了一套完整分割体系,从最简单的纯色分割、类目分割到头发分割、固定人像分割,到指甲、身体分割都可以将其分割出来。也就是说我们将商品或人从RGB信息中分离出来,后续根据商品的颜色和分发主题来搭配相应颜色空间(智能滤镜)等将其二次加工,快速生产想要的视频。那么完整的分割体系是保证视觉元素分拆的重要一步。
▐ 话题生产
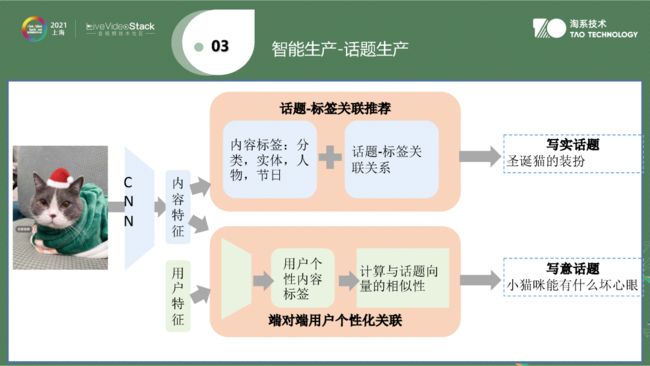
一是一个视频在分发过程中如何打动别人。对于话题(这个视频的内容),可以用深度学习方案将用户特征提取出来,打上个性化话题。
▐ 智能封面图

二是在拍摄视频过程中,如果没有封面图,那么视频首帧就是封面图。但会有几个问题:视频首帧无法完整表达视频的整体含义;首帧容易黑屏、花屏。此时如何在拍摄的视频中精选最能够代表视频含义的帧就是我们所要做的事情。
▐ 互动玩活
三是如果有了封面图,并赋予它语义含义后,要将视频变好玩,需要互动玩法。例如,在友商的一些产品中,有眨一下眼睛就会出眼泪;一笑就会出桃花。这些互动玩法就可以快速将短视频变得生动有趣。而在这一板块,我们提供了一整套2D、3D的特效玩法。
智能审核
讲完了关于智能生产部分,第二部分分享智能审核。
▐ OCR

一是OCR。整个视频审核过程中是跨模态的,有语音信息、文本信息、视觉信息。在整个过程中,我们会把所有视频、图片含有的文字信息摘出,有了它可以做很多事情。上图是整个OCR链路体系。基本流程和普通图片OCR相似。
▐ 内容去劣
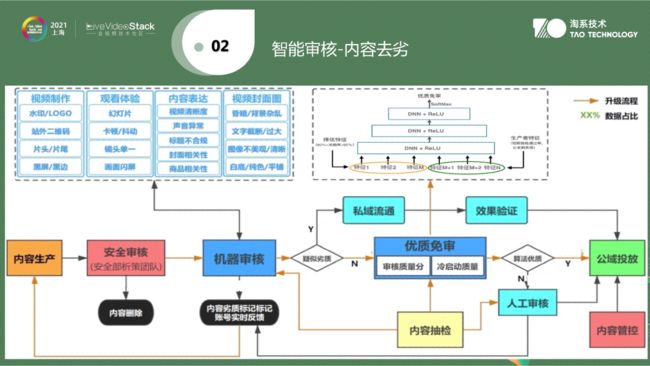
二是有了跨模态信息,智能审核分为两大步骤,第一步是内容去劣,第二部是内容择优。在整个视频中出现抖动、二维码LOGO不符合场景分发等情况时,则会对内容进行降权。这一块有60多种模型来解决内容去劣的问题。
▐ 内容择优

第二步是内容择优。所有短视频分发前都需要进行人工审核,在有限人力下,如何将好视频快速分发?内容择优就是通过算法优先找出相应的优质视频,找出后并不是直接分发,而是优先将其分配给人工进行审核,保证优质视频时效性,在最短时间在公域中流转。上述就是内容择优的内容。封面图不都是自己生成,会有用户上传封面图,但其与内容完全没有关系。那么可以在择优模型中,从商品人物一致性,商品调性出发,使用美学模型方法将优质视频挑选出来。
内容检索
第三部分是关于内容检索方面。
▐ 原子能力

第一需要构建完整内容检索的原子能力。最早在深度学习之前,运用SIFT特征(SLAM中运用ORB特征使之更快)把局部特征构建成全局特征做检索。深度学习后,全局特征很好提,那么局部特征怎么提呢?我们构建了局部特征算子,整个检索有局部和全局特征。构建后做整个上层检索,以文本搜图片或视频,以图像搜视频,以视频搜视频等各种应用。检索技术是通用的,但运用场景不同,则上层会形成几种产品:直播看点,解决商品搜索过程;内容去重,在整个视频中会有很多重复,调整分辨率帧率或是轻微裁剪,颜色空间变化,本质上内容一致,如何做内容去重;明星识别,识别视频中出现的人物,人物关系;视频推荐,如何与视频检索结合。上述是内容检索中的原子能力。后续会围绕着上层能力做详细介绍。
▐ 内容看点
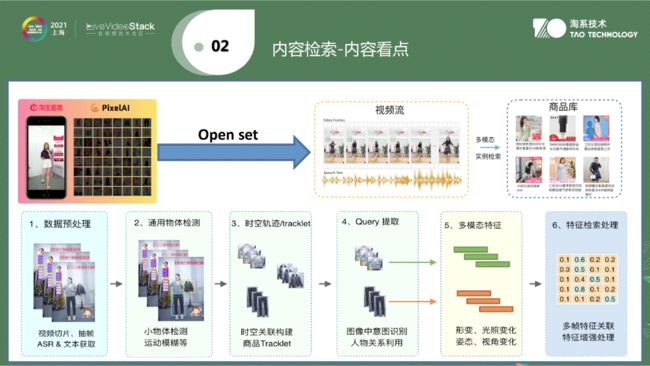
第二是直播看点,内容看点。有很多用过淘宝直播的用户知道回放时会有看点。它是在小的闭集上做商品检索。过程如上图:第一步是数据预处理,一段视频中不是每帧信息都是有用的,将有用帧挑选出来;第二步是通用物体检测,检测出每段具体卖的商品,;第三步是时空轨迹/tracklet,在直播商品的过程中,主播卖的商品与时间前后和空间有关,例如卖手机,左手展示,商品展示与物理空间有关;第四步是Query提取,从音频信息到OCR信息;第五步是文本信息与视觉信息结合,进行多模态提商品特征。第六步是在闭环内对商品特征做检索处理。
▐ 明星检索
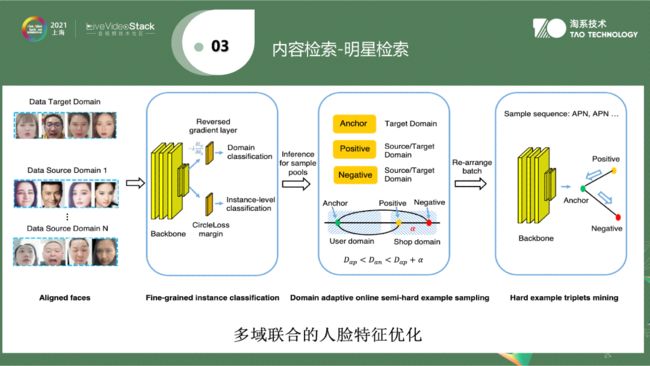
第三是明星检索。在拍短视频或整个直播过程中,出现哪些人,这些人是谁。也许不知道这个人的名字,但我们会给他Face ID,不管在哪个视频中出现,都会被完整提取出来。其核心在于一方面是多域联合,另一方面现在支持的是千万级别到亿级别的,在lost function这一块去做arcface loss。
▐ 内容去重
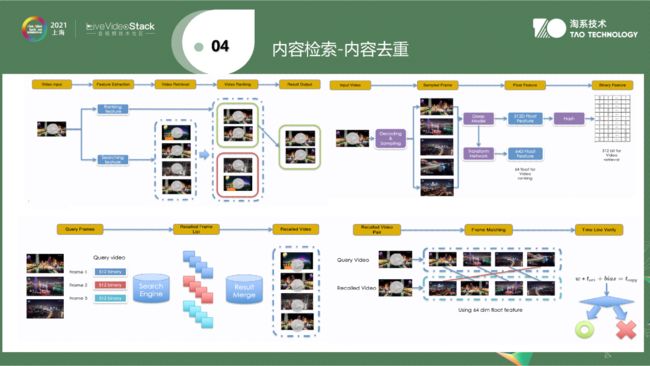
第四是内容去重。分享一下内容去重需要解决的问题,淘宝有分佣机制。当一个视频可以返利时,会有人盗取视频并加入自己的商品链接。视频中会进行裁帧处理,分辨率变化等形变。我们需要将作弊的视频检索出来,以上是内容去重需要做的事情。叫内容不叫视频的原因是现在我们对文本、图片、视频、帖子等形式的去重都支持。
内容语义
讲完了内容检索后,第四部分来分享一下我们在内容语义方面做的事。
▐ 视频分类
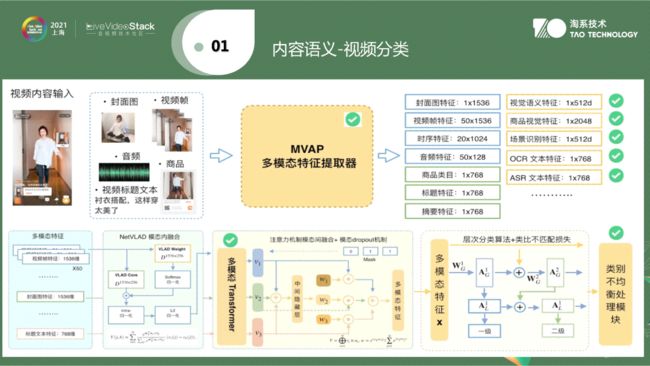
第一个最常用的是视频分类。无论长视频或短视频都要进行分类,这事情说简单也简单,说难也难,是因为有很多视频在分类过程中,不一定是视觉可分。因此整个分类过程中是跨模态的,会把ASR信息或整个OCR信息联合去做分类。往往分类不是分一级类目(搞笑、美食),一级类目下还有二级类目(美食下有潮汕美食、浙江美食、上海美食),在整个分类过程中,一级类目与二级类目联合进行分类,借助两个分类之间的相关性,尽量减少不一致性。如果一级分类与二级分类相差过大,认为这是有问题的,则会重新调整。通过两级分类联合相互监督使之准确率更高。
▐ 视频标签
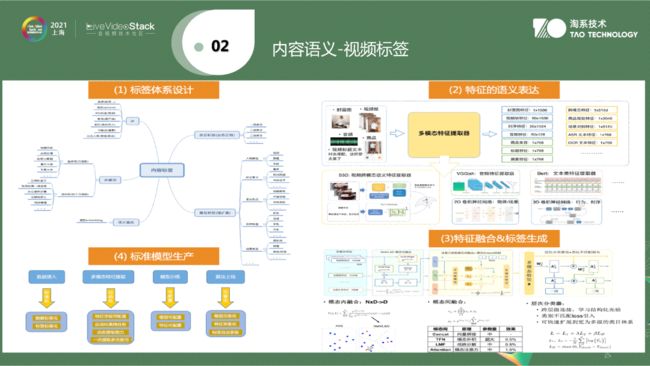
第二个是视频标签。在整个视频中分类比较有限,一般来说一级类目几十种,二级类目一两百种,除了分类信息,还可以打大量标签。这些标签如何产生,判别什么样的标签是有意义的需要与各自业务结合起来(比如说说视频中有一瓶水,里面有两个人。打这样的标签不一定是有意义的)。这需要和各自业务域结合产出有意义的标签。如果是安防产品,会对人或刀具或打架行为关心;如果是电商,则会对商品和出现的人比较关心。这里会有业务上的设计,而有了业务上的设计,跨模态理解最终会把想要的标签生产出来。
▐ 内容向量化
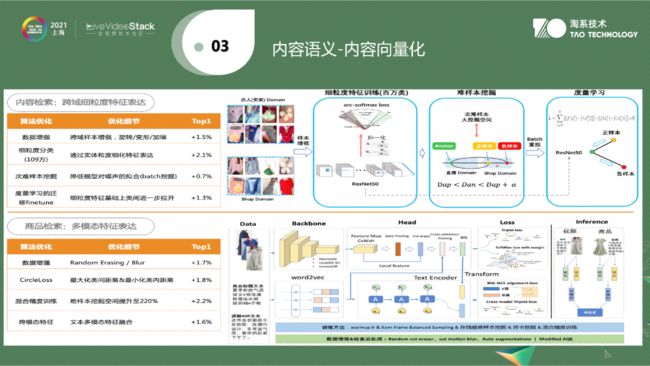
第三个是内容向量化。把语义理解后,需要与最终的搜索推荐系统结合,在结合时会有很多结合点。第一步将类目信息或Face ID整个传输给搜推,让其做后续推荐。推荐时那一页不可能都是你喜欢的那件商品,例如我喜欢手机,但我打开搜推系统这一页,不可能一屏全是手机或是我喜欢某个信息。这样做的原因是搜推的需要有多样性和新颖性。如果用户搜了一个洗衣机,那么如何将推荐打散?比如视觉方面,当用户输入文本信息时,会将视频中的洗衣机标签提取,使洗衣机类目打散。
▐ 兴趣图谱

第四部分是兴趣图谱。每个视频独立成体系,这些海量视频之间标签的关联性是维度,可以汇集成视频与视频标签之间的关联关系,是标签图谱。另外一方面,一个人看了许多视频,中间的关联性和共通性可以通过标签、属性形成基于个人内容兴趣图谱。针对这一方面,由单个视频上升到群体行为构成整个视频之间的标签图谱或兴趣图谱,上述就是做兴趣图谱的事情。
▐ 认识推理

第五部分是认识推理。兴趣图谱构建是个体与群体行为,群体行为分为两个方面,看过的视频与看视频人之间的关系。
训练体系
逛逛算法模型不少。第五部分来分享一下训练体系。
▐ 训练体系
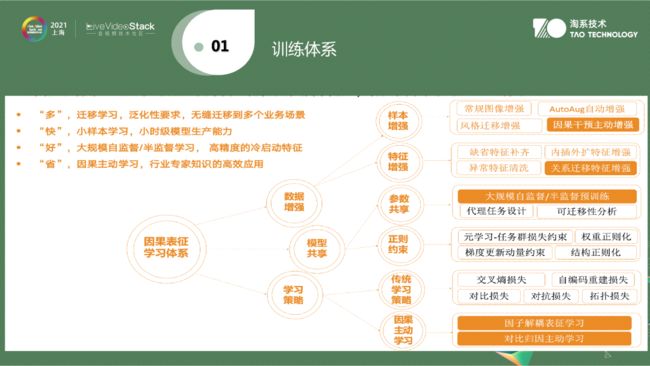
讲训练体系的原因是在做标签、内容时,如果类别上到千万级别,会遇到长尾问题,解决现有数据问题时会遇到小样本问题。举个例子,手淘中最不缺的是商品样本;逛逛是做内容的,不一定是商品。我们会发现内容生产者为了点击率生产软色情内容,在手淘中属于小样本。如果要做软色情的识别分类器,会发现手淘中没有很多样本(因为我们不是社区)。所以我们需要有一套体系根据样本分布,如果有海量样本,就需要用监督学习来解决。把所有样本花钱进行标注,标的样本越多,越精准。但另一方面如果标注的都是简单的样本,不一定可以随着样本量上升,精度会线性增长。找出难样本有主动学习方式,同时也能节省标注的经费。长尾的东西多半是小样本,会有半监督、自监督方法、无监督方法做体系,将整体分布训练做起来,会形成自己的训练体系去解决整个在逛逛中遇到的各种问题。
✿ 拓展阅读




作者|李晓波(篱悠)
编辑|橙子君
出品|阿里巴巴新零售淘系技术

