class torch.optim.lr_scheduler.OneCycleLR
参考链接: class torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr, total_steps=None, epochs=None, steps_per_epoch=None, pct_start=0.3, anneal_strategy=‘cos’, cycle_momentum=True, base_momentum=0.85, max_momentum=0.95, div_factor=25.0, final_div_factor=10000.0, last_epoch=-1, verbose=False)
配套代码下载链接: 测试学习率调度器.zip
实验代码展示:
# torch.optim.lr_scheduler.OneCycleLR
import matplotlib.pyplot as plt
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
from torch import nn
from torch.autograd import Function
import random
import os
seed = 20200910
os.environ['PYTHONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed) # if you are using multi-GPU.
np.random.seed(seed) # Numpy module.
random.seed(seed) # Python random module.
torch.manual_seed(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
class Dataset4cxq(Dataset):
def __init__(self, length):
self.length = length
def __len__(self):
return self.length
def __getitem__(self, index):
if type(index) != type(2) and type(index) != (slice):
raise TypeError('索引类型错误,程序退出...')
# index 是单个数
if type(index) == type(2):
if index >= self.length or index < -1 * self.length:
# print("索引越界,程序退出...")
raise IndexError("索引越界,程序退出...")
elif index < 0:
index = index + self.length
Celsius = torch.randn(1,1,dtype=torch.float).item()
Fahrenheit = 32.0 + 1.8 * Celsius
return Celsius, Fahrenheit
def collate_fn4cxq(batch):
list_c = []
list_f = []
for c, f in batch:
list_c.append(c)
list_f.append(f)
list_c = torch.tensor(list_c)
list_f = torch.tensor(list_f)
return list_c, list_f
my_dataset_val = Dataset4cxq(16)
dataloader4cxq_val = torch.utils.data.DataLoader(
dataset=my_dataset_val,
batch_size=8,
# batch_size=2,
drop_last=True,
# drop_last=False,
shuffle=True, # True False
# shuffle=False, # True False
collate_fn=collate_fn4cxq,
# collate_fn=None,
)
def validate():
total_loss_val = 0.0
for cnt, data in enumerate(dataloader4cxq_val, 0):
Celsius, Fahrenheit = data
Celsius, Fahrenheit = Celsius.cuda().view(-1,1), Fahrenheit.cuda().view(-1,1)
output = model(Celsius)
loss = cost_function(output, Fahrenheit)
total_loss_val += loss.item()
return total_loss_val
if __name__ == "__main__":
my_dataset = Dataset4cxq(32)
# for c,f in my_dataset:
# print(type(c),type(f))
dataloader4cxq = torch.utils.data.DataLoader(
dataset=my_dataset,
batch_size=8,
# batch_size=2,
drop_last=True,
# drop_last=False,
shuffle=True, # True False
# shuffle=False, # True False
collate_fn=collate_fn4cxq,
# collate_fn=None,
)
# for cnt, data in enumerate(dataloader4cxq, 0):
# # pass
# sample4cxq, label4cxq = data
# print('sample4cxq的类型: ',type(sample4cxq),'\tlabel4cxq的类型: ',type(label4cxq))
# print('迭代次数:', cnt, ' sample4cxq:', sample4cxq, ' label4cxq:', label4cxq)
print('开始创建模型'.center(80,'-'))
model = torch.nn.Linear(in_features=1, out_features=1, bias=True) # True # False
model.cuda()
# optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.01185)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.999)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001, momentum=0.9999)
# 模拟华氏度与摄氏度之间的转换
# Fahrenheit = 32 + 1.8 * Celsius
model.train()
cost_function = torch.nn.MSELoss()
epochs = 100001 # 100001
epochs = 101 # 100001
print('\n')
print('开始训练模型'.center(80,'-'))
list4delta = list()
list4epoch = list()
# scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=(lambda epoch: 0.99 ** (epoch//1000)))
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.001, steps_per_epoch=len(dataloader4cxq), epochs=epochs)
for epoch in range(epochs):
# with torch.no_grad():
# Celsius = torch.randn(10,1,dtype=torch.float).cuda()
# Fahrenheit = 32.0 + 1.8 * Celsius
# Fahrenheit = Fahrenheit.cuda()
# Celsius = torch.randn(1,1,dtype=torch.float,requires_grad=False).cuda() # requires_grad=False True
# Fahrenheit = 32.0 + 1.8 * Celsius
# Fahrenheit = Fahrenheit.cuda() # requires_grad=False
total_loss = 0.0
for cnt, data in enumerate(dataloader4cxq, 0):
Celsius, Fahrenheit = data
Celsius, Fahrenheit = Celsius.cuda().view(-1,1), Fahrenheit.cuda().view(-1,1)
output = model(Celsius)
loss = cost_function(output, Fahrenheit)
total_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
scheduler.step()
if epoch % 1 == 0: # if epoch % 1000 == 0:
list4delta.append(total_loss)
list4epoch.append(epoch)
if epoch % 10 == 0:
info = '\nepoch:{0:>6}/{1:<6}\t'.format(epoch,epochs)
for k, v in model.state_dict().items():
info += str(k)+ ':' + '{0:<.18f}'.format(v.item()) + '\t'
# info += str(k)+ ':' + str(v.item()) + '\t'
print(info)
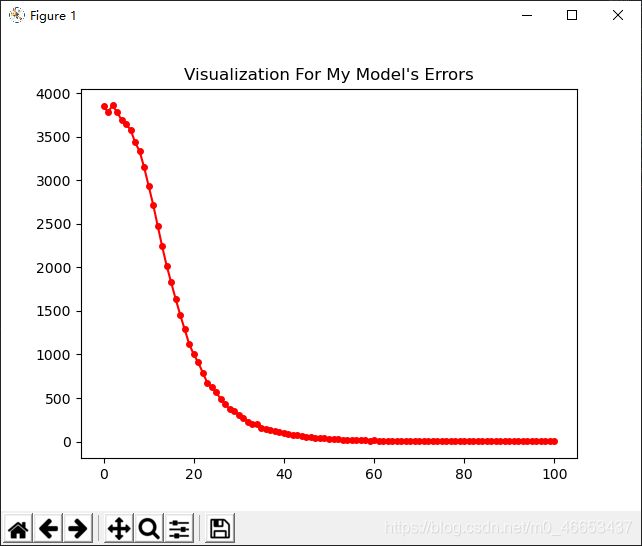
fig, ax = plt.subplots()
# ax.plot(10*np.random.randn(100),10*np.random.randn(100),'o')
ax.plot(list4epoch, list4delta, 'r.-', markersize=8)
ax.set_title("Visualization For My Model's Errors")
plt.show()
控制台下结果输出:
Windows PowerShell
版权所有 (C) Microsoft Corporation。保留所有权利。
尝试新的跨平台 PowerShell https://aka.ms/pscore6
加载个人及系统配置文件用了 945 毫秒。
(base) PS C:\Users\chenxuqi\Desktop\News4cxq\测试学习率调度器> conda activate pytorch_1.7.1_cu102
(pytorch_1.7.1_cu102) PS C:\Users\chenxuqi\Desktop\News4cxq\测试学习率调度器> & 'D:\Anaconda3\envs\pytorch_1.7.1_cu102\python.exe' 'c:\Users\chenxuqi\.vscode\extensions\ms-python.python-2021.1.502429796\pythonFiles\lib\python\debugpy\launcher' '53057' '--' 'c:\Users\chenxuqi\Desktop\News4cxq\测试学习率调度器\test14.py'
-------------------------------------开始创建模型-------------------------------------
-------------------------------------开始训练模型-------------------------------------
epoch: 0/101 weight:0.962908029556274414 bias:1.000067472457885742
epoch: 10/101 weight:1.150201916694641113 bias:5.657925605773925781
epoch: 20/101 weight:1.109996080398559570 bias:16.684816360473632812
epoch: 30/101 weight:1.121294498443603516 bias:23.647979736328125000
epoch: 40/101 weight:1.325981259346008301 bias:27.321170806884765625
epoch: 50/101 weight:1.521384119987487793 bias:29.311891555786132812
epoch: 60/101 weight:1.621088981628417969 bias:30.372066497802734375
epoch: 70/101 weight:1.658141970634460449 bias:30.924274444580078125
epoch: 80/101 weight:1.678284883499145508 bias:31.194002151489257812
epoch: 90/101 weight:1.691896319389343262 bias:31.297739028930664062
epoch: 100/101 weight:1.693937063217163086 bias:31.313619613647460938
运行结果截图: